1. ARM Neon Intrinsics 编程
1.入门:基本能上手写Intrinsics
1.1 Neon介绍、简明案例与编程惯例
1.2 如何检索Intrinsics
1.3 优化效果案例
1.4 如何在Android应用Neon
2. 进阶:注意细节处理,学习常用算子的实现
2.1 与Neon相关的ARM体系结构
2.2 对非整数倍元素个数(leftovers)的处理技巧
2.3 算子源码学习(ncnn库,AI方向)
2.4 算子源码学习(Nvidia carotene库,图像处理方向 )
3. 学个通透:了解原理
3.1 SIMD加速原理
3.2 了解硬件决定的速度极限:Software Optimization Guide
3.3 反汇编分析生成代码质量
4. 其他:相关的研讨会视频、库、文档等
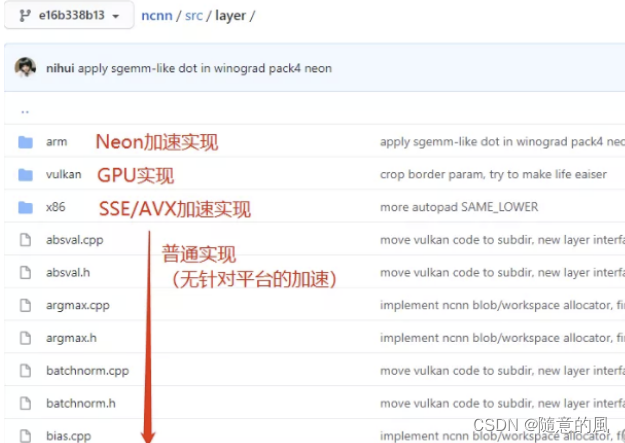
ncnn是腾讯开源,nihui维护的AI推理引擎。由于Neon实现往往跟循环展开等技巧一起使用,代码往往比较长。可以先阅读普通实现的代码实现了解顶层逻辑,再阅读Neon实现的代码。例如,我们希望学习全连接层(innerproduct)的Neon实现,其普通实现的位置在ncnn/src/layer/innerproduct.cpp,对应的Neon加速实现的位置在ncnn/src/layer/arm/innerproduct_arm.cpp。
2. ARMv8 中的 SIMD 运算
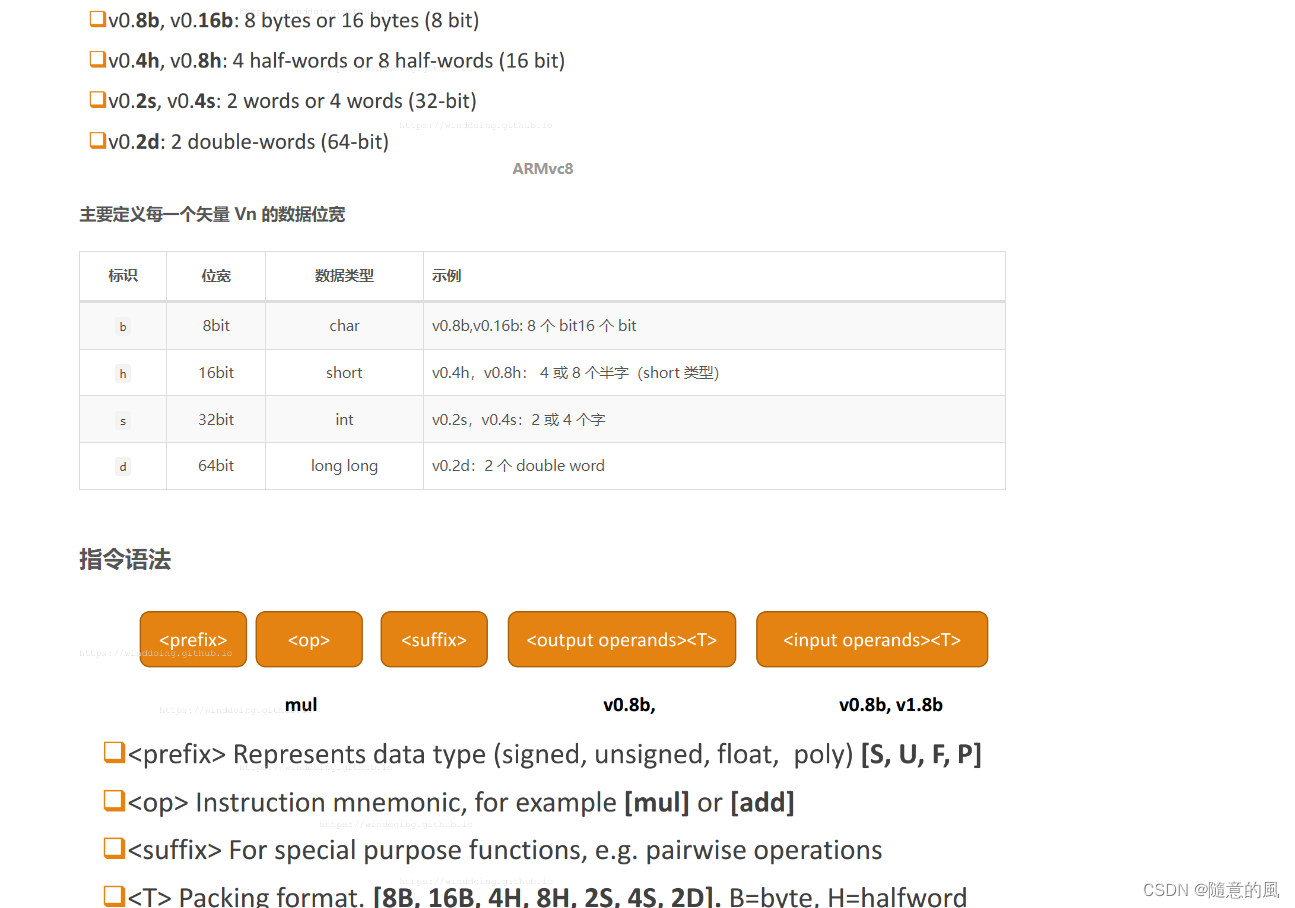
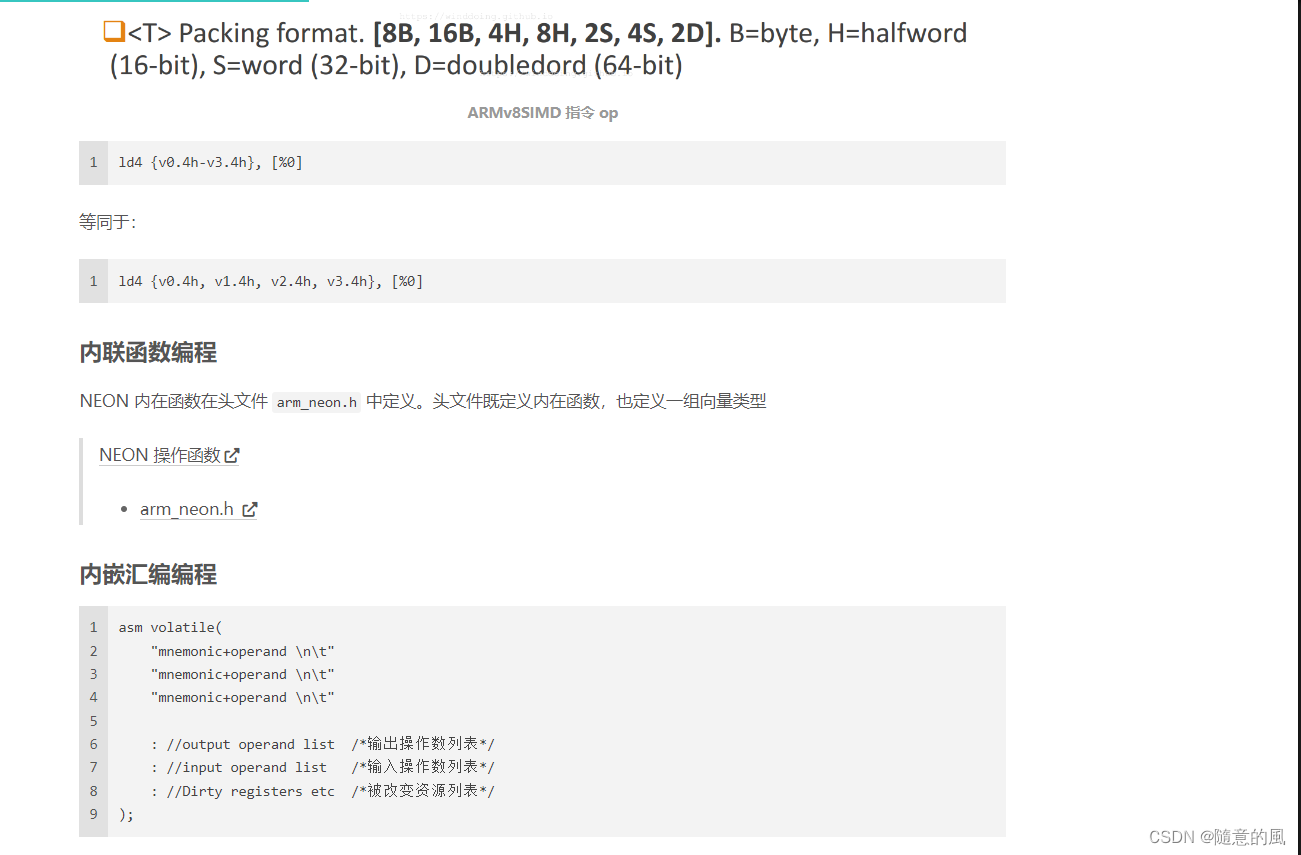
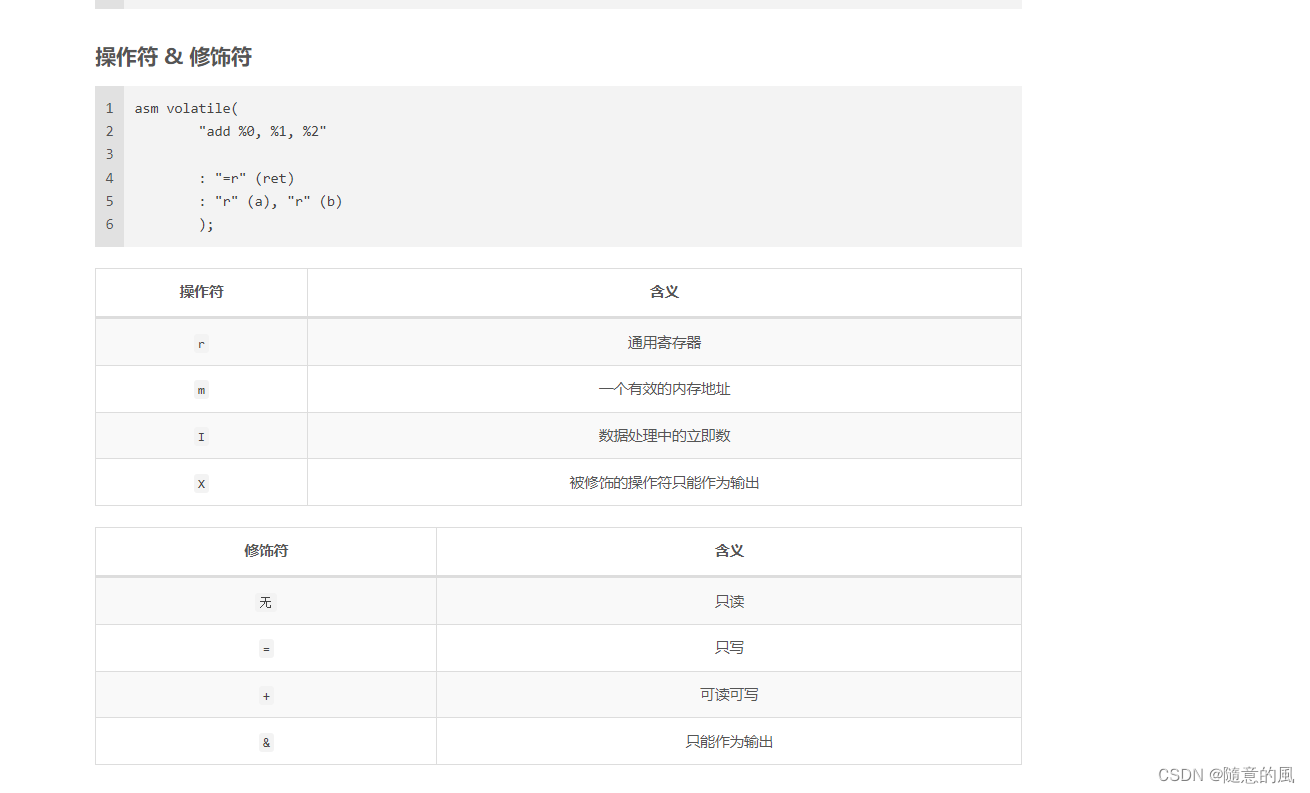
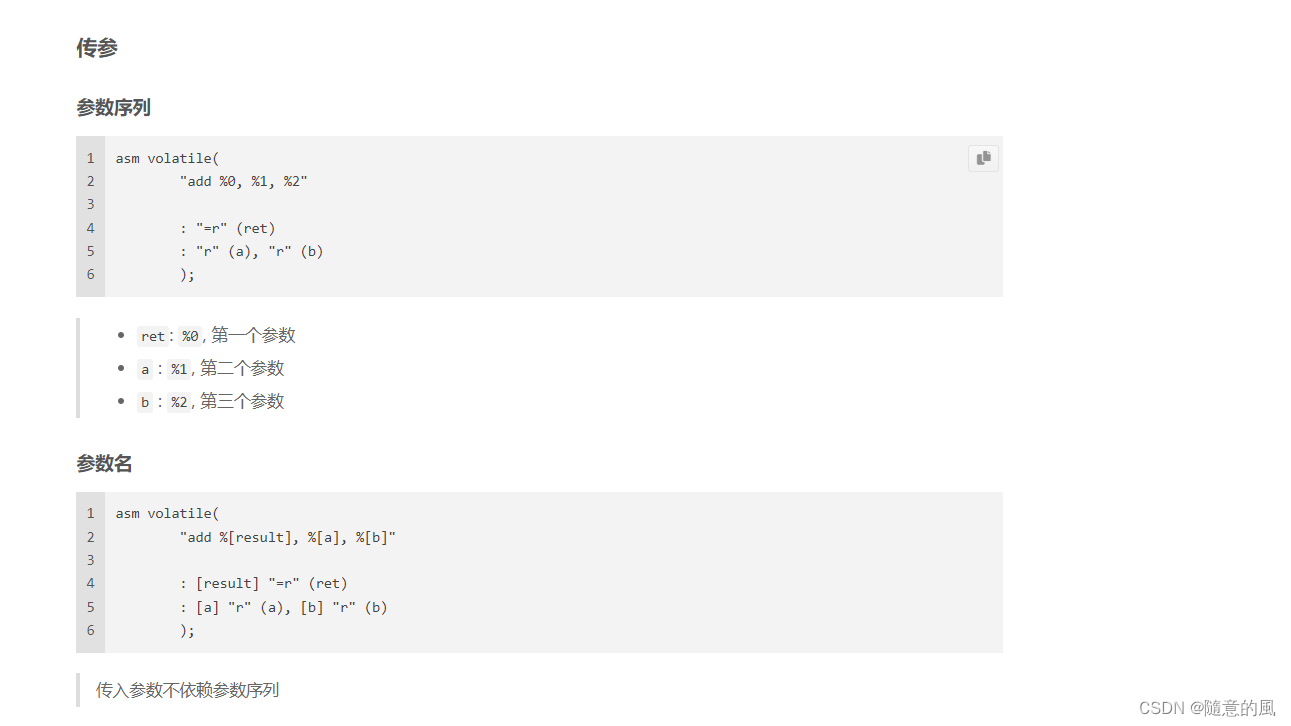
SIMD
什么是SIMD呢?就是一条指令处理多个数据,可以算作是一种并行计算。比如我们要做一个4维向量的加法,用一般的指令完成必须使用4次加法指令才行,而用SIMD指令可能只需要一次加法,而且花费的时间和一般指令做一次加法的时间相同。很显然,SIMD可以大大提高一些计算密集型任务的执行效率。这种SIMD指令功能,主流的体系结构一般都用一组特殊的指令子集给予支持,比如x86的SSE,还比如本文讲的ARM的NEON。
NEON
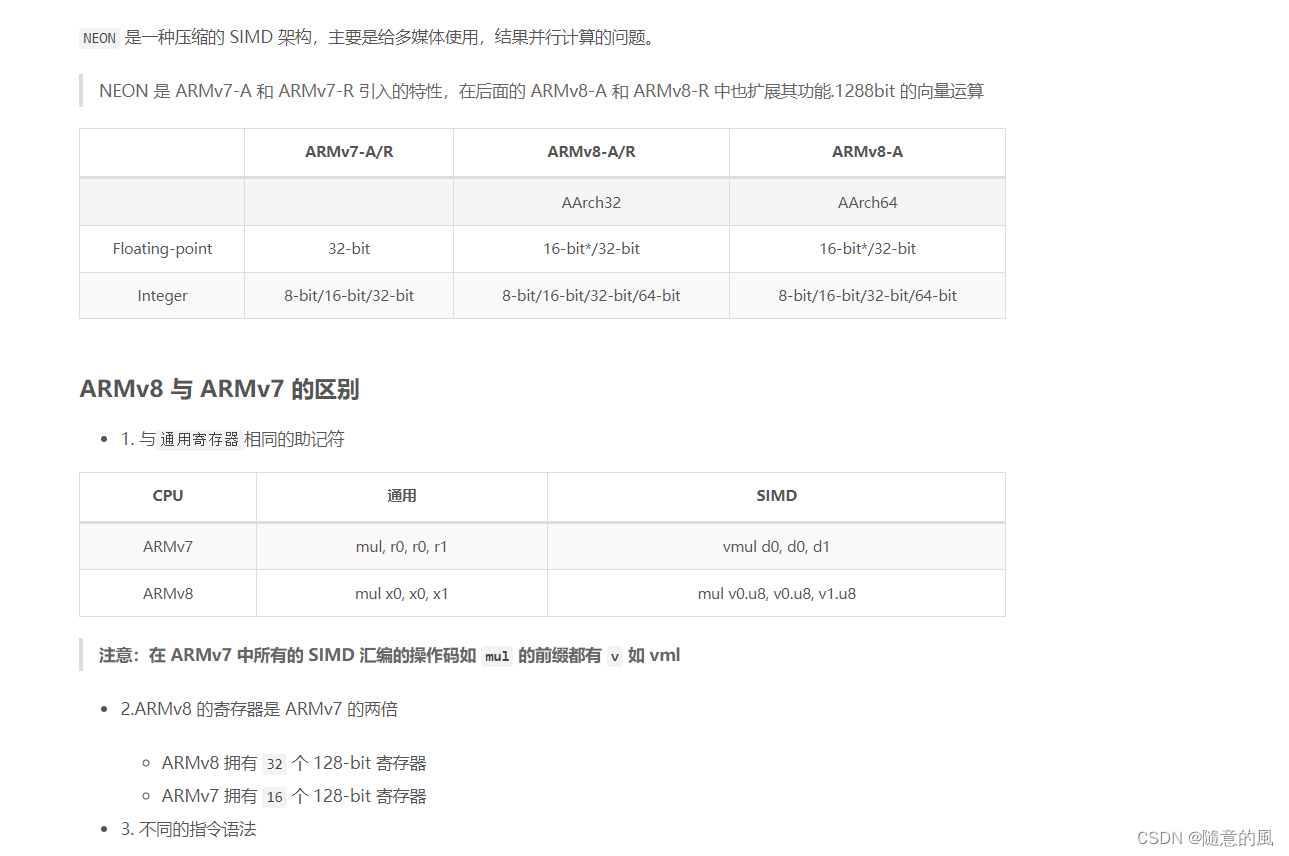
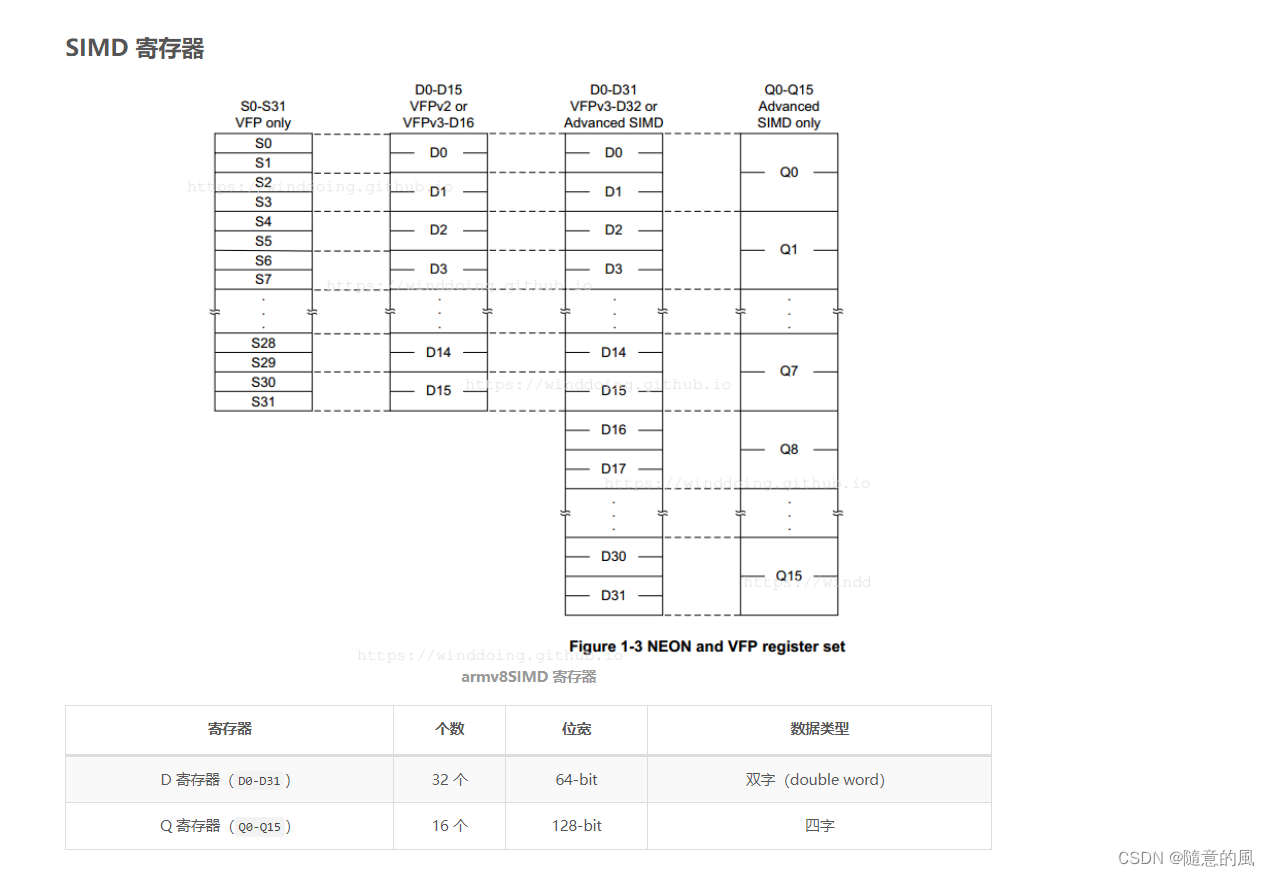
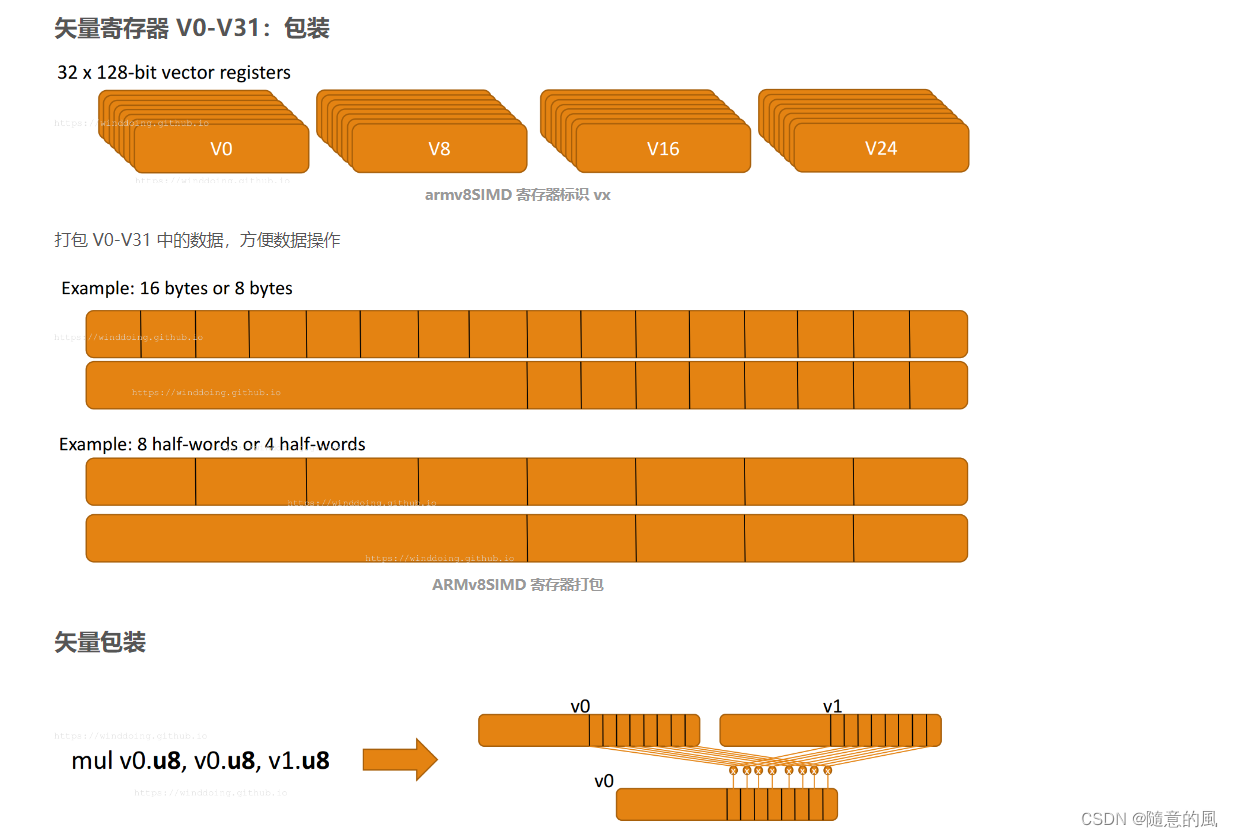
NEON是ARM下的一个SIMD指令集合。可实现64位/128位的并行计算。64位/128位并行怎么理解呢?举例说,在128位并行的情况下,如果是8位整数,可以并行进行16对整数的加法;如果是16位整数,就可以并行进行8对整数的加法;以此类推。
指令集合自然也离不开寄存器。NEON寄存器分两种。一种寄存器以D开头,共32个,每个64位;另一种寄存器以Q开头,共16个,每个128位。Q0与D0,D1重合(共用128比特),Q1与D2,D3重合,以此类推。因此用D寄存器可并行8个8位整数加法,而用Q寄存器可并行16个8位整数加法。
NEON intrinsics
如果直接用汇编写NEON固然可以,但是coding的效率不会很高。C编译器支持将NEON指令封装成内置函数供程序员直接使用,这样一来无疑会大大提高开发效率和代码可维护性。
同时,执行效率也并不会降低很多,因为使用NEON intrinsics时,虽然像是在调用各种结构体和函数,但将生成的代码反汇编后可以发现,其实没有调用函数,只是在使用NEON寄存器和指令罢了。
即便目的是写汇编代码,使用intrinsics也有好处。比如先用intrinsics写好代码编译后在反汇编,在此基础上进行优化,可能比较省力。
数据类型
<基本类型>x<lane个数>x<向量个数>_t,向量个数如果省略表示只有一个。如int8x8_t,uint8x8x3_t。
基本类型int8,int16,int32,int64,uint8,uint16,uint32,uint64,float16,float32
lane个数表示并行处理的基本类型数据的个数。
对于多个向量的类型实际上是结构体
typedef struct {
uint8x8_t val[3];
} uint8x8x3_t;
指令命名
<指令名>[后缀]_<数据基本类型简写>
其中后缀如果没有,表示64位并行;如果后缀是q,表示128位并行。
如果后缀是l,表示长指令,输出数据的基本类型位数是输入的2倍;如果后缀是n,表示窄指令,输出数据的基本类型位数是输入的一半。
数据基本类型简写:s8,s16,s32,s64,u8,u16,u32,u64,f16,f32
例如:
vadd_u16:两个uint16x4相加为一个uint16x4
vaddq_u16:两个uint16x8相加为一个uint16x8
vaddl_u16:两个uint8x8相加为一个uint16x8
指令分类说明
算术和位运算指令
vadd,vsub,vmul,vand,vorr,vshl,vshr等。
但是NEON不直接提供除法和开平方指令,而是提供了对于倒数1/x和开方的倒数1/x0.5的近似指令。这样一来除法a/b可以表示为a*(1/b),开方a0.5可以表示为a*(1/a^0.5)。
示例:
//近似求倒数
inline static float32x4_t vrecp(float32x4_t v) {
float32x4_t r = vrecpeq_f32(v); //求得初始估计值
r = vmulq_f32(vrecpsq_f32(v, r), r); //逼近
r = vmulq_f32(vrecpsq_f32(v, r), r); //再次逼近
return r;
}
//近似求开方
inline float32x4_t vsqrt(float32x4_t v) {
float32x4_t r = vrsqrteq_f32(v); //求得开方倒数的初始估计值
r = vmulq_f32(vrsqrtsq_f32(v, r), r); //逼近
return vmulq_f32(v, r); //通过乘法转为开方
}
数据移动指令
实际编程中经常要在不同NEON数据类型间转移数据,有时还要按lane来get/set向量值,NEON intrinsics也提供了这类操作。
vdup[后缀]n<数据基本类型简写>:用同一个标量值初始化一个向量全部的lane;
vset[后缀]lane<数据基本类型简写>:对指定的一个lane进行设置
vget[后缀]lane<数据基本类型简写>:获取指定的一个lane的值
vmov[后缀]_<数据基本类型简写>:数据间移动
访存指令
NEON访存指令可以将内存读到NEON数据类型中去,或者将NEON数据类型写进内存。可以支持一次读写多向量数据类型。
vld<向量数>[后缀]_<数据基本类型简写>:读内存
vst<向量数>[后缀]_<数据基本类型简写>:写内存
例如,vld1_u8从内存读取一个uint8x8_t数据,vst3q_u8写入一个u8x16x3_t数据。
需要注意的是,默认情况下对多个向量数据的读写使用了interleave模式,可以理解为向多向量数据读入或从其写出时外层按照lane循环,内层再按照向量循环。
例如将一个16像素的RGB图片解析成R,G,B三个plane的时候,可以写如下代码:
void split(uint8_t *rgb, uint8_t *r, uint8_t *g, uint8_t *b) {
uint8x16x3_t v = vld3q_u8(rgb);
vst1q_u8(r, v.val[0]);
vst1q_u8(g, v.val[1]);
vst1q_u8(b, v.val[2]);
}
条件指令
如同非SIMD程序需要分支语句一样,NEON程序有时候需要对一个向量的各个lane的值的情况来判断另一个向量对应的lane如何进行处理。
vce[后缀]_<数据基本类型简写>:v[n] = v1[n] == v2[n] ? 全0 : 全1
vcle[后缀]_<数据基本类型简写>:v[n] = v1[n] <= v2[n] ? 全0 : 全1
vclt[后缀]_<数据基本类型简写>:v[n] = v1[n] < v2[n] ? 全0 : 全1
vcge[后缀]_<数据基本类型简写>:v[n] = v1[n] >= v2[n] ? 全0 : 全1
vcgt[后缀]_<数据基本类型简写>:v[n] = v1[n] > v2[n] ? 全0 : 全1
得出的结果结合位运算即可实现条件判断。
注意事项
NEON intrinsics的注意事项同时也是NEON汇编的注意事项。
处理数组时要注意数组元素个数不能被NEON向量lane个数整除的情况,多出的元素应补齐或者通过非SIMD方式处理。
NEON不是万能的,比如把地址放在向量里让内存同时读写就办不到。设计算法时应尽量避免这种情况。
对cache友好仍然是最重要的。有时一个算法看上去似乎访存次数和计算次数都比另一个算法少,但是由于其访存方式对cache不友好,导致其运行效率不如后者。
示例
- 4x4 矩阵乘法
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#include <sys/time.h>
#if __aarch64__
#include <arm_neon.h>
#endif
static void dump(uint16_t **x)
{
int i, j;
uint16_t *xx = (uint16_t *)x;
printf("%s:n", __func__);
for(i = 0; i < 4; i++) {
for(j = 0; j < 4; j++) {
printf("%3d ", *(xx + (i << 2) + j));
}
printf("n");
}
}
static void matrix_mul_c(uint16_t aa[][4], uint16_t bb[][4], uint16_t cc[][4])
{
int i = 0, j = 0;
printf("===> func: %s, line: %dn", __func__, __LINE__);
for(i = 0; i < 4; i++) {
for(j = 0; j < 4; j++) {
cc[i][j] = aa[i][j] * bb[i][j];
}
}
}
#if __aarch64__
static void matrix_mul_neon(uint16_t **aa, uint16_t **bb, uint16_t **cc)
{
printf("===> func: %s, line: %dn", __func__, __LINE__);
#if 1
uint16_t (*a)[4] = (uint16_t (*)[4])aa;
uint16_t (*b)[4] = (uint16_t (*)[4])bb;
uint16_t (*c)[4] = (uint16_t (*)[4])cc;
printf("aaaaaaaan");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
uint16x4_t _cc0;
uint16x4_t _cc1;
uint16x4_t _cc2;
uint16x4_t _cc3;
uint16x4_t _aa0 = vld1_u16((uint16_t*)a[0]);
uint16x4_t _aa1 = vld1_u16((uint16_t*)a[1]);
uint16x4_t _aa2 = vld1_u16((uint16_t*)a[2]);
uint16x4_t _aa3 = vld1_u16((uint16_t*)a[3]);
uint16x4_t _bb0 = vld1_u16((uint16_t*)b[0]);
uint16x4_t _bb1 = vld1_u16((uint16_t*)b[1]);
uint16x4_t _bb2 = vld1_u16((uint16_t*)b[2]);
uint16x4_t _bb3 = vld1_u16((uint16_t*)b[3]);
_cc0 = vmul_u16(_aa0, _bb0);
_cc1 = vmul_u16(_aa1, _bb1);
_cc2 = vmul_u16(_aa2, _bb2);
_cc3 = vmul_u16(_aa3, _bb3);
vst1_u16((uint16_t*)c[0], _cc0);
vst1_u16((uint16_t*)c[1], _cc1);
vst1_u16((uint16_t*)c[2], _cc2);
vst1_u16((uint16_t*)c[3], _cc3);
asm("nop");
asm("nop");
asm("nop");
asm("nop");
#else
printf("bbbbbbbbn");
int i = 0;
uint16x4_t _aa[4], _bb[4], _cc[4];
uint16_t *a = (uint16_t*)aa;
uint16_t *b = (uint16_t*)bb;
uint16_t *c = (uint16_t*)cc;
for(i = 0; i < 4; i++) {
_aa[i] = vld1_u16(a + (i << 2));
_bb[i] = vld1_u16(b + (i << 2));
_cc[i] = vmul_u16(_aa[i], _bb[i]);
vst1_u16(c + (i << 2), _cc[i]);
}
#endif
}
static void matrix_mul_asm(uint16_t **aa, uint16_t **bb, uint16_t **cc)
{
printf("===> func: %s, line: %dn", __func__, __LINE__);
uint16_t *a = (uint16_t*)aa;
uint16_t *b = (uint16_t*)bb;
uint16_t *c = (uint16_t*)cc;
#if 0
asm volatile(
"ldr d3, [%0, #0] nt"
"ldr d2, [%0, #8] nt"
"ldr d1, [%0, #16] nt"
"ldr d0, [%0, #24] nt"
"ldr d7, [%1, #0] nt"
"ldr d6, [%1, #8] nt"
"ldr d5, [%1, #16] nt"
"ldr d4, [%1, #24] nt"
"mul v3.4h, v3.4h, v7.4h nt"
"mul v2.4h, v2.4h, v6.4h nt"
"mul v1.4h, v1.4h, v5.4h nt"
"mul v0.4h, v0.4h, v4.4h nt"
//"add v3.4h, v3.4h, v7.4h nt"
//"add v2.4h, v2.4h, v6.4h nt"
//"add v1.4h, v1.4h, v5.4h nt"
//"add v0.4h, v0.4h, v4.4h nt"
"str d3, [%2,#0] nt"
"str d2, [%2,#8] nt"
"str d1, [%2,#16] nt"
"str d0, [%2,#24] nt"
: "+r"(a), //%0
"+r"(b), //%1
"+r"(c) //%2
:
: "cc", "memory", "d0", "d1", "d2", "d3", "d4", "d5", "d6", "d7"
);
#else
// test, OK
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm volatile(
//"ld4 {v0.4h, v1.4h, v2.4h, v3.4h}, [%0] nt"
"ld4 {v0.4h-v3.4h}, [%0] nt"
"ld4 {v4.4h, v5.4h, v6.4h, v7.4h}, [%1] nt"
"mul v3.4h, v3.4h, v7.4h nt"
"mul v2.4h, v2.4h, v6.4h nt"
"mul v1.4h, v1.4h, v5.4h nt"
"mul v0.4h, v0.4h, v4.4h nt"
"st4 {v0.4h, v1.4h, v2.4h, v3.4h}, [%2] nt"
: "+r"(a), //%0
"+r"(b), //%1
"+r"(c) //%2
:
: "cc", "memory", "v0", "v1", "v2", "v3", "v4", "v5", "v6", "v7"
);
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
#endif
}
#endif
int main(int argc, const char *argv[])
{
uint16_t aa[4][4] = {
{1, 2, 3, 4},
{5, 6, 7, 8},
{3, 6, 8, 1},
{2, 6, 7, 1}
};
uint16_t bb[4][4] = {
{1, 3, 5, 7},
{2, 4, 6, 8},
{2, 5, 7, 9},
{5, 2, 7, 1}
};
uint16_t cc[4][4] = {0};
int i, j;
struct timeval tv;
long long start_us = 0, end_us = 0;
dump((uint16_t **)aa);
dump((uint16_t **)bb);
dump((uint16_t **)cc);
/* ******** C **********/
gettimeofday(&tv, NULL);
start_us = tv.tv_sec + tv.tv_usec;
matrix_mul_c(aa, bb, cc);
gettimeofday(&tv, NULL);
end_us = tv.tv_sec + tv.tv_usec;
printf("aa[][]*bb[][] C time %lld usn", end_us - start_us);
dump((uint16_t **)cc);
#if __aarch64__
/* ******** NEON **********/
memset(cc, 0, sizeof(uint16_t) * 4 * 4);
gettimeofday(&tv, NULL);
start_us = tv.tv_sec + tv.tv_usec;
matrix_mul_neon((uint16_t **)aa, (uint16_t **)bb, (uint16_t **)cc);
gettimeofday(&tv, NULL);
end_us = tv.tv_sec + tv.tv_usec;
printf("aa[][]*bb[][] neon time %lld usn", end_us - start_us);
dump((uint16_t **)cc);
/* ******** asm **********/
memset(cc, 0, sizeof(uint16_t) * 4 * 4);
gettimeofday(&tv, NULL);
start_us = tv.tv_sec + tv.tv_usec;
matrix_mul_asm((uint16_t **)aa, (uint16_t **)bb, (uint16_t **)cc);
gettimeofday(&tv, NULL);
end_us = tv.tv_sec + tv.tv_usec;
printf("aa[][]*bb[][] asm time %lld usn", end_us - start_us);
dump((uint16_t **)cc);
#endif
return 0;
}
aarch64-linux-gcc -O3 matrix_4x4_mul.c
gcc –march=armv8-a [input file] -o [output file]
8x8 矩阵乘法
static void matrix_mul_asm(uint16_t **aa, uint16_t **bb, uint16_t **cc)
{
printf("===> func: %s, line: %dn", __func__, __LINE__);
uint16_t *a = (uint16_t*)aa;
uint16_t *b = (uint16_t*)bb;
uint16_t *c = (uint16_t*)cc;
asm volatile(
"ld4 {v0.8h, v1.8h, v2.8h, v3.8h}, [%0] nt"
"ld4 {v8.8h, v9.8h, v10.8h, v11.8h}, [%1] nt"
"mul v0.8h, v0.8h, v8.8h nt"
"mul v1.8h, v1.8h, v9.8h nt"
"mul v2.8h, v2.8h, v10.8h nt"
"mul v3.8h, v3.8h, v11.8h nt"
"st4 {v0.8h, v1.8h, v2.8h, v3.8h}, [%2] nt"
"add x1, %0, #64 nt"
"add x2, %1, #64 nt"
"add x3, %2, #64 nt"
//"ld4 {v4.8h-v7.8h}, [x1] nt"
"ld4 {v4.8h, v5.8h, v6.8h, v7.8h}, [x1] nt"
"ld4 {v12.8h, v13.8h, v14.8h, v15.8h}, [x2] nt"
"mul v4.8h, v4.8h, v12.8h nt"
"mul v5.8h, v5.8h, v13.8h nt"
"mul v6.8h, v6.8h, v14.8h nt"
"mul v7.8h, v7.8h, v15.8h nt"
"st4 {v4.8h, v5.8h, v6.8h, v7.8h}, [x3] nt"
: "+r"(a), //%0
"+r"(b), //%1
"+r"(c) //%2
:
: "cc", "memory", "x1", "x2", "x3", "v0", "v1", "v2", "v3", "v4", "v5", "v6", "v7",
"v8", "v9", "v10", "v11", "v12", "v13", "v14", "v15"
);
}
3. NEON编程, 优化心得及内联汇编使用心得
Very thanks to Orchid (Orchid Blog).
NEON intrinsics
提供了一个连接NEON操作的C函数接口,编译器会自动生成相关的NEON指令,支持ARMv7-A或ARMv8-A平台。
所有的intrinsics函数都在GNU官方说明文档。
一个简单的例子:
//add for int array. assumed that count is multiple of 4
#include<arm_neon.h>
// C version void add_int_c(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i++)
dst[i] = src1[i] + src2[i];
}
}
// NEON version void add_float_neon1(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i += 4)
{
int32x4_t in1, in2, out;
in1 = vld1q_s32(src1);
src1 += 4;
in2 = vld1q_s32(src2);
src2 += 4;
out = vaddq_s32(in1, in2);
vst1q_s32(dst, out);
dst += 4;
}
}
代码中的vld1q_s32会被编译器转换成vld1.32 {d0, d1}, [r0]指令,同理vaddq_s32和vst1q_s32被转换成vadd.i32 q0, q0, q0,vst1.32 {d0, d1}, [r0]。若不清楚指令意义,请参见ARM® Compiler armasm User Guide - Chapter 12 NEON and VFP Instructions。

参考
ARMv8 Neon Programming
Introducing NEON
Coding for NEON - Part 1: Load and Stores
ARM® Cortex®-A72 MPCore Processor Technical Reference Manual
最后
以上就是积极钢笔最近收集整理的关于【genius_platform软件平台开发】第八十二讲:ARM Neon指令集一(ARM NEON Intrinsics, SIMD运算, 优化心得)1. ARM Neon Intrinsics 编程2. ARMv8 中的 SIMD 运算SIMDNEONNEON intrinsics数据类型指令命名指令分类说明数据移动指令访存指令条件指令注意事项示例8x8 矩阵乘法3. NEON编程, 优化心得及内联汇编使用心得的全部内容,更多相关【genius_platform软件平台开发】第八十二讲:ARM内容请搜索靠谱客的其他文章。








发表评论 取消回复