目录
一、why PyTorch
二、安装
三、PyTorch基础概念
1. 张量(Tensor)
1.1 创建一个未初始化的5*3的矩阵:
1.2 获取tensor的属性(形状大小、维度个数、数据类型、元素个数)
1.3 构建一个初始化矩阵
1.4 从数据中直接构建一个tensor:
1.5 根据已有的tensor建立新的tensor:
2. tensor上的运算
2.1 加法的3种形式
2.2 原地操作(in-place)
2.3 可以使用像标准的NumPy一样的各种索引操作
2.4 改变形状
2.5 如果是仅包含一个元素的tensor,可以使用.item()来得到对应的python数值
2.6 稍后阅读
3. NumPy桥
3.1 把Torch张量转换为numpy数组
3.2 把numpy数组转换为torch张量
3.3 CUDA张量
一、why PyTorch
Tensorflow 自己说自己在分布式训练上下了很大的功夫, 那我就默认 Tensorflow 在这一点上要超出 PyTorch, 但是 Tensorflow 的静态计算图使得他在 RNN 上有一点点被动 (虽然它用其他途径解决了), 不过用 PyTorch 的时候, 你会对这种动态的 RNN 有更好的理解.
二、安装
PyTorch上找到对应的安装命令,安装 PyTorch 会安装两个模块, 一个是 torch, 一个 torchvision, torch 是主模块, 用来搭建神经网络的, torchvision 是辅模块, 有数据库, 还有一些已经训练好的神经网络等着你直接用, 比如 (VGG, AlexNet, ResNet).
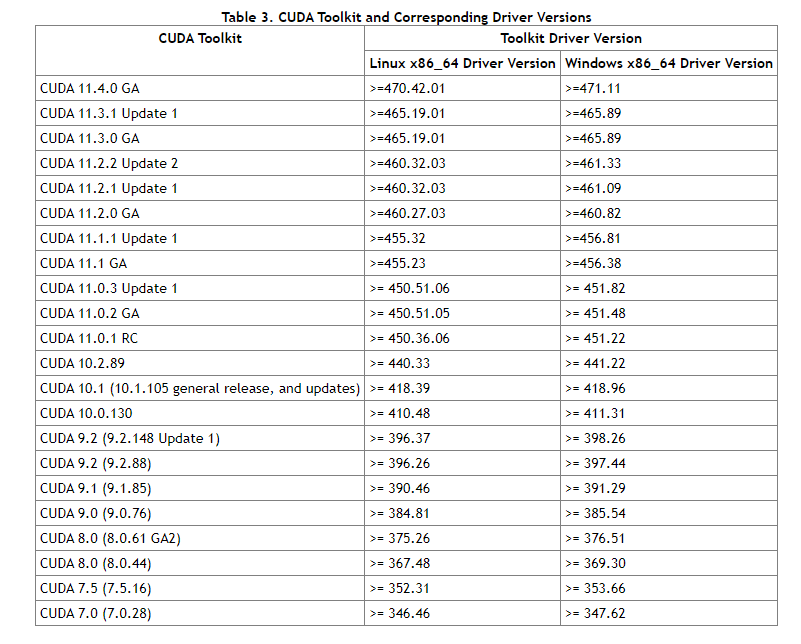
安装cuda版本时对应版本号:
三、PyTorch基础概念
1. 张量(Tensor)
tensor于numpy的ndarrays,不同之处在于tensor可以使用GPU来加快计算。
1.1 创建一个未初始化的5*3的矩阵:
In [46]:
x = torch.Tensor(5, 3)
print(x)
print('x.dtype=',x.dtype)
tensor([[ 0.0000e+00, 0.0000e+00, 1.2163e-42],
[ 0.0000e+00, 7.0065e-45, 0.0000e+00],
[-2.6090e+09, 5.0587e-43, 0.0000e+00],
[ 0.0000e+00, 7.0065e-45, 0.0000e+00],
[-3.0255e+09, 5.0587e-43, 0.0000e+00]])
x.dtype= torch.float321.2 获取tensor的属性(形状大小、维度个数、数据类型、元素个数)
In [50]:
# 获取形状大小的两种方法:
print('法①:x.size()=',x.size())
print('torch.Size()返回的实际上是一个元组,所以它支持元组的所有操作。')
print('法②:x.shape=',x.shape)
print()
# 获取维度个数
print('x.dim()=',x.dim())
print()
# 获取数据类型
print('x.dtype=',x.dtype)
print()
# 获取元素个数
print('x.numel()=',x.numel())
法①:x.size()= torch.Size([5, 3])
torch.Size()返回的实际上是一个元组,所以它支持元组的所有操作。
法②:x.shape= torch.Size([5, 3])
x.dim()= 2
x.dtype= torch.float32
x.numel()= 151.3 构建一个初始化矩阵
- 0初始化,使用long的类型
- 1初始化
- 随机[0, 1)初始化
- 等差数列初始化
- 标准正态分布初始化
- eye初始化
In [58]:
x = torch.zeros(5, 3, dtype=torch.long)
# 1初始化
# x = torch.ones(5, 3, dtype=torch.long)
# [0,1)初始化
# x = torch.rand(5,3)
# 等差数列初始化
# x = torch.arange(10,20,2)
# 标准正态分布初始化
# x =torch.randn(5,3)
# eye初始化:para1决定张量的形状,比如3,就是三行三列,para2决定张量输出的列数,比如2,输出列数则为2。
# x=torch.eye(5,3)
print(x)
tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])1.4 从数据中直接构建一个tensor:
In [10]:
x = torch.tensor([5.5, 3])
print(x)
tensor([5.5000, 3.0000])1.5 根据已有的tensor建立新的tensor:
除非用户提供新值,这些方法将重用输入张量(tensor)的属性,例如dtype
In [11]:
x = x.new_zeros(5, 3, dtype=torch.double) # 打印:tensor([[0,0,0],[0,0,0],...])
print(x)
x = x.new_ones(5, 3, dtype=torch.double) # new_* methods take in sizes
print(x)
x = torch.randn_like(x, dtype=torch.float) # 覆盖类型! result 的size相同,数据变为随机值。
print(x)
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]], dtype=torch.float64)
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64)
tensor([[ 0.7542, -0.1806, -0.7456],
[-0.3787, 1.2365, 1.0395],
[ 0.8733, -2.2402, -0.8755],
[ 0.9496, 1.5125, 0.0083],
[-0.5588, -0.5435, 0.0065]])2. tensor上的运算
一种运算有多种语法。在下面的示例中,我们将研究加法运算。
2.1 加法的3种形式
In [23]:
# 加法的2种形式
# 法①
y = torch.rand(5, 3)
c=x + y
print(c)
# 法②
print(torch.add(x, y))
# 法③
result = torch.empty(5, 2)
#print(result)
torch.add(x,y,out=result)
print(result)
tensor([[ 1.6529, 0.4947, 0.2033],
[ 0.5041, 1.5942, 1.9702],
[ 1.5319, -1.7636, 0.0310],
[ 1.6111, 1.5339, 0.7098],
[ 0.4113, -0.5045, 0.7432]])
tensor([[ 1.6529, 0.4947, 0.2033],
[ 0.5041, 1.5942, 1.9702],
[ 1.5319, -1.7636, 0.0310],
[ 1.6111, 1.5339, 0.7098],
[ 0.4113, -0.5045, 0.7432]])
tensor([[ 1.6529, 0.4947, 0.2033],
[ 0.5041, 1.5942, 1.9702],
[ 1.5319, -1.7636, 0.0310],
[ 1.6111, 1.5339, 0.7098],
[ 0.4113, -0.5045, 0.7432]])2.2 原地操作(in-place)
注意: 任何一个改变张量的操作后面都固定一个_。例如x.copy_(y)、x.t_()将更改x
In [24]:
# 把x加到y上
y.add_(x)
print(y)
tensor([[ 1.6529, 0.4947, 0.2033],
[ 0.5041, 1.5942, 1.9702],
[ 1.5319, -1.7636, 0.0310],
[ 1.6111, 1.5339, 0.7098],
[ 0.4113, -0.5045, 0.7432]])2.3 可以使用像标准的NumPy一样的各种索引操作
In [25]:
print(x)
print(x[:, 1])
tensor([[ 0.7542, -0.1806, -0.7456],
[-0.3787, 1.2365, 1.0395],
[ 0.8733, -2.2402, -0.8755],
[ 0.9496, 1.5125, 0.0083],
[-0.5588, -0.5435, 0.0065]])
tensor([-0.1806, 1.2365, -2.2402, 1.5125, -0.5435])2.4 改变形状
如果想改变形状,可以使用torch.view
In [28]:
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) # -1的意思是没有指定维度
print(x.size(), y.size(), z.size())
print(x)
print(y)
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
tensor([[ 1.1834, -0.4473, -1.4750, -1.4320],
[ 0.1730, 0.0911, -1.2494, 1.0530],
[ 0.6912, 1.1631, -1.0222, 1.0408],
[ 0.1931, -1.0624, -1.0157, 0.4932]])
tensor([ 1.1834, -0.4473, -1.4750, -1.4320, 0.1730, 0.0911, -1.2494, 1.0530,
0.6912, 1.1631, -1.0222, 1.0408, 0.1931, -1.0624, -1.0157, 0.4932])2.5 如果是仅包含一个元素的tensor,可以使用.item()来得到对应的python数值
In [29]:
x = torch.randn(1)
print(x)
print(x.item())
tensor([-2.8661])
-2.8660628795623782.6 稍后阅读
这里描述了一百多种张量操作,包括转置,索引,数学运算,线性代数,随机数等。
3. NumPy桥
把一个torch张量转换为numpy数组或者反过来都是很简单的。
Torch张量和NumPy数组将共享它们的底层内存位置,更改一个将更改另一个。
3.1 把Torch张量转换为numpy数组
二者共享内存
In [36]:
a = torch.ones(5)
print(a,a.dtype)
print(type(a))
print()
# 把Torch张量a转换为numpy数组b
b = a.numpy()
print(b,b.dtype)
print(type(b))
tensor([1., 1., 1., 1., 1.]) torch.float32
<class 'torch.Tensor'>
[1. 1. 1. 1. 1.] float32
<class 'numpy.ndarray'>
In [37]:
a.add_(1)
print(a)
print(b)
tensor([2., 2., 2., 2., 2.])
[2. 2. 2. 2. 2.]3.2 把numpy数组转换为torch张量
二者共享内存
In [39]:
a = np.ones(5)
print(a)
b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a)
print(b)
[1. 1. 1. 1. 1.]
[2. 2. 2. 2. 2.]
tensor([2., 2., 2., 2., 2.], dtype=torch.float64)3.3 CUDA张量
可以使用.to方法将张量移动到任何设备上。
In [44]:
# let us run this cell only if CUDA is available
# We will use ``torch.device`` objects to move tensors in and out of GPU
if torch.cuda.is_available():
device = torch.device("cuda") # a CUDA device object
y = torch.ones_like(x, device=device) # directly create a tensor on GPU
x = x.to(device) # or just use strings ``.to("cuda")``
z = x + y
print(z)
print(z.to("cpu", torch.double)) # ``.to`` can also change dtype together!最后
以上就是玩命纸鹤最近收集整理的关于Pytorch初识——安装及使用一、why PyTorch二、安装三、PyTorch基础概念的全部内容,更多相关Pytorch初识——安装及使用一、why内容请搜索靠谱客的其他文章。








发表评论 取消回复