- 对于多分类的标签(即教师信号),从本质上看,通过One-hot操作,就是把具体的标签(Label)空间,变换到一个概率测度空间(设为 p),如[1,0,0](表示它是第一个品类)。可以这样理解这个概率,如果标签分类的标量输出为1(即概率为100%),其它值为0(即概率为0%)。
- 而对于多分类问题,在Softmax函数的“加工”下,它的实际输出值就是一个概率向量,如[0.96, 0.04, 0],设其概率分布为q。
现在我们想衡量p和q之间的差异(即损失),一种简单粗暴的方式,自然是可以比较p和q的差值,如MSE(不过效果不好而已)。但一种更好的方式是衡量这二者的概率分布的差异,就是交叉熵,它的设计初衷就是要衡量两个概率分布之间的差异。
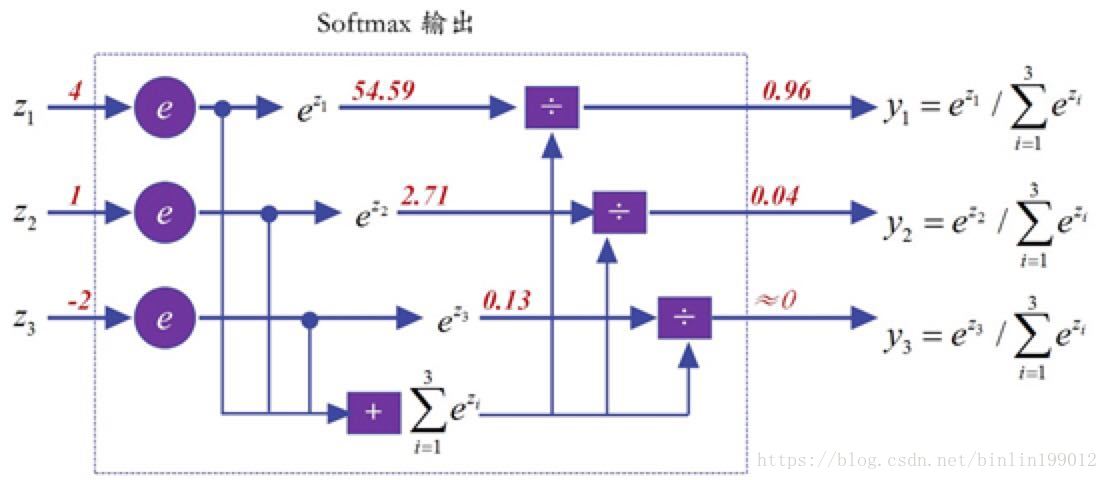
- 为什么要用softmax一下呢?exp函数是单调递增的,它能很好地模拟max的行为,而且它能让“大者更大”。其背后的潜台词则是让“小者更小”,这个有点类似“马太效应”,强者愈强、弱者愈弱。这个特性,对于分类来说尤为重要,它能让学习效率更高。
这样一来,分类标签可以看做是概率分布(由one-hot变换而来),神经网络输出也是一个概率分布,现在想衡量二者的差异(即损失),自然用交叉熵最好了。
本文摘自AI群
最后
以上就是贪玩项链最近收集整理的关于训练分类器为什么要用cross entropy loss而不能用mean square error loss?的全部内容,更多相关训练分类器为什么要用cross内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复