Byte Streams
Programs use byte streams to perform input and output of 8-bit bytes. All byte stream classes are descended from InputStream and OutputStream.
There are many byte stream classes. To demonstrate how byte streams work, we'll focus on the file I/O byte streams, FileInputStream and FileOutputStream. Other kinds of byte streams are used in much the same way; they differ mainly in the way they are constructed.
Using Byte Streams
We'll explore FileInputStream and FileOutputStream by examining an example program named CopyBytes, which uses byte streams to copy xanadu.txt, one byte at a time.
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyBytes {
public static void main(String[] args) throws IOException {
FileInputStream in = null;
FileOutputStream out = null;
try {
in = new FileInputStream("xanadu.txt");
out = new FileOutputStream("outagain.txt");
int c;
while ((c = in.read()) != -1) {
out.write(c);
}
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
}
}
}
CopyBytes spends most of its time in a simple loop that reads the input stream and writes the output stream, one byte at a time, as shown in the following figure.
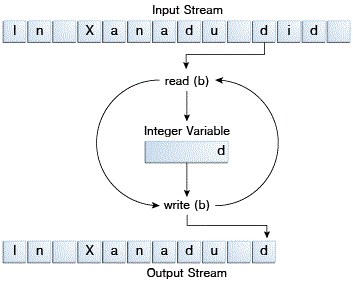
Simple byte stream input and output.
Always Close Streams
Closing a stream when it's no longer needed is very important — so important that CopyBytes uses a finally block to guarantee that both streams will be closed even if an error occurs. This practice helps avoid serious resource leaks.
One possible error is that CopyBytes was unable to open one or both files. When that happens, the stream variable corresponding to the file never changes from its initial null value. That's why CopyBytes makes sure that each stream variable contains an object reference before invoking close.
When Not to Use Byte Streams
CopyBytes seems like a normal program, but it actually represents a kind of low-level I/O that you should avoid. Since xanadu.txt contains character data, the best approach is to use character streams, as discussed in the next section. There are also streams for more complicated data types. Byte streams should only be used for the most primitive I/O.
So why talk about byte streams? Because all other stream types are built on byte streams.
Buffered Streams
Most of the examples we've seen so far use unbuffered I/O. This means each read or write request is handled directly by the underlying OS. This can make a program much less efficient, since each such request often triggers disk access, network activity, or some other operation that is relatively expensive.
To reduce this kind of overhead, the Java platform implements buffered I/O streams. Buffered input streams read data from a memory area known as a buffer; the native input API is called only when the buffer is empty. Similarly, buffered output streams write data to a buffer, and the native output API is called only when the buffer is full.
A program can convert an unbuffered stream into a buffered stream using the wrapping idiom we've used several times now, where the unbuffered stream object is passed to the constructor for a buffered stream class. Here's how you might modify the constructor invocations in the CopyCharacters example to use buffered I/O:
inputStream = new BufferedReader(new FileReader("xanadu.txt"));
outputStream = new BufferedWriter(new FileWriter("characteroutput.txt"));
There are four buffered stream classes used to wrap unbuffered streams: BufferedInputStream and BufferedOutputStream create buffered byte streams, while BufferedReader and BufferedWriter create buffered character streams.
Flushing Buffered Streams
It often makes sense to write out a buffer at critical points, without waiting for it to fill. This is known as flushing the buffer.
Some buffered output classes support autoflush, specified by an optional constructor argument. When autoflush is enabled, certain key events cause the buffer to be flushed. For example, an autoflush PrintWriter object flushes the buffer on every invocation of println or format. See Formatting for more on these methods.
To flush a stream manually, invoke its flush method. The flush method is valid on any output stream, but has no effect unless the stream is buffered.
The format Method
The format method formats multiple arguments based on a format string. The format string consists of static text embedded with format specifiers; except for the format specifiers, the format string is output unchanged.
Format strings support many features. In this tutorial, we'll just cover some basics. For a complete description, see format string syntax in the API specification.
The Root2 example formats two values with a single format invocation:
public class Root2 {
public static void main(String[] args) {
int i = 2;
double r = Math.sqrt(i);
System.out.format("The square root of %d is %f.%n", i, r);
}
}
Here is the output:
The square root of 2 is 1.414214.
Like the three used in this example, all format specifiers begin with a % and end with a 1- or 2-character conversion that specifies the kind of formatted output being generated. The three conversions used here are:
dformats an integer value as a decimal value.fformats a floating point value as a decimal value.noutputs a platform-specific line terminator.
Here are some other conversions:
xformats an integer as a hexadecimal value.sformats any value as a string.tBformats an integer as a locale-specific month name.
There are many other conversions.
Note:
Except for %% and %n, all format specifiers must match an argument. If they don't, an exception is thrown.
In the Java programming language, the n escape always generates the linefeed character (u000A). Don't use n unless you specifically want a linefeed character. To get the correct line separator for the local platform, use %n.
In addition to the conversion, a format specifier can contain several additional elements that further customize the formatted output. Here's an example, Format, that uses every possible kind of element.
public class Format {
public static void main(String[] args) {
System.out.format("%f, %1$+020.10f %n", Math.PI);
}
}
Here's the output:
3.141593, +00000003.1415926536
The additional elements are all optional. The following figure shows how the longer specifier breaks down into elements.
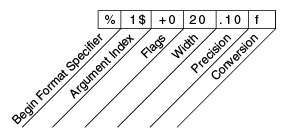
Elements of a Format Specifier.
The elements must appear in the order shown. Working from the right, the optional elements are:
- Precision. For floating point values, this is the mathematical precision of the formatted value. For
sand other general conversions, this is the maximum width of the formatted value; the value is right-truncated if necessary. - Width. The minimum width of the formatted value; the value is padded if necessary. By default the value is left-padded with blanks.
- Flags specify additional formatting options. In the
Formatexample, the+flag specifies that the number should always be formatted with a sign, and the0flag specifies that0is the padding character. Other flags include-(pad on the right) and,(format number with locale-specific thousands separators). Note that some flags cannot be used with certain other flags or with certain conversions. - The Argument Index allows you to explicitly match a designated argument. You can also specify
<to match the same argument as the previous specifier. Thus the example could have said:System.out.format("%f, %<+020.10f %n", Math.PI);
Object Streams
-
Just as data streams support I/O of primitive data types, object streams support I/O of objects. Most, but not all, standard classes support serialization of their objects. Those that do implement the marker interface
Serializable.The object stream classes are
ObjectInputStreamandObjectOutputStream. These classes implementObjectInputandObjectOutput, which are subinterfaces ofDataInputandDataOutput. That means that all the primitive data I/O methods covered in Data Streams are also implemented in object streams. So an object stream can contain a mixture of primitive and object values. TheObjectStreamsexample illustrates this.ObjectStreamscreates the same application asDataStreams, with a couple of changes. First, prices are nowBigDecimalobjects, to better represent fractional values. Second, aCalendarobject is written to the data file, indicating an invoice date.If
readObject()doesn't return the object type expected, attempting to cast it to the correct type may throw aClassNotFoundException. In this simple example, that can't happen, so we don't try to catch the exception. Instead, we notify the compiler that we're aware of the issue by addingClassNotFoundExceptionto themainmethod'sthrowsclause.Output and Input of Complex Objects
The
writeObjectandreadObjectmethods are simple to use, but they contain some very sophisticated object management logic. This isn't important for a class like Calendar, which just encapsulates primitive values. But many objects contain references to other objects. IfreadObjectis to reconstitute an object from a stream, it has to be able to reconstitute all of the objects the original object referred to. These additional objects might have their own references, and so on. In this situation,writeObjecttraverses the entire web of object references and writes all objects in that web onto the stream. Thus a single invocation ofwriteObjectcan cause a large number of objects to be written to the stream.This is demonstrated in the following figure, where
writeObjectis invoked to write a single object named a. This object contains references to objects b and c, while b contains references to d and e. Invokingwriteobject(a)writes not just a, but all the objects necessary to reconstitute a, so the other four objects in this web are written also. When a is read back byreadObject, the other four objects are read back as well, and all the original object references are preserved.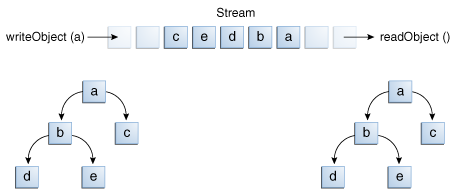
I/O of multiple referred-to objects
You might wonder what happens if two objects on the same stream both contain references to a single object. Will they both refer to a single object when they're read back? The answer is "yes." A stream can only contain one copy of an object, though it can contain any number of references to it. Thus if you explicitly write an object to a stream twice, you're really writing only the reference twice. For example, if the following code writes an object
obtwice to a stream:Object ob = new Object(); out.writeObject(ob); out.writeObject(ob);
Each
writeObjecthas to be matched by areadObject, so the code that reads the stream back will look something like this:Object ob1 = in.readObject(); Object ob2 = in.readObject();
This results in two variables,
ob1andob2, that are references to a single object.However, if a single object is written to two different streams, it is effectively duplicated — a single program reading both streams back will see two distinct objects.
File I/O (Featuring NIO.2)
Note: This tutorial reflects the file I/O mechanism introduced in the JDK 7 release. The Java SE 6 version of the File I/O tutorial was brief, but you can download the Java SE Tutorial 2008-03-14 version of the tutorial which contains the earlier File I/O content.
The java.nio.file package and its related package, java.nio.file.attribute, provide comprehensive support for file I/O and for accessing the default file system. Though the API has many classes, you need to focus on only a few entry points. You will see that this API is very intuitive and easy to use.
The tutorial starts by asking what is a path? Then, the Path class, the primary entry point for the package, is introduced. Methods in the Path class relating to syntactic operations are explained. The tutorial then moves on to the other primary class in the package, the Files class, which contains methods that deal with file operations. First, some concepts common to many file operations are introduced. The tutorial then covers methods for checking, deleting, copying, and moving files.
The tutorial shows how metadata is managed, before moving on to file I/O and directory I/O. Random access files are explained and issues specific to symbolic and hard links are examined.
Next, some of the very powerful, but more advanced, topics are covered. First, the capability to recursively walk the file tree is demonstrated, followed by information about how to search for files using wild cards. Next, how to watch a directory for changesis explained and demonstrated. Then, methods that didn't fit elsewhere are given some attention.
Finally, if you have file I/O code written prior to the Java SE 7 release, there is a map from the old API to the new API, as well as important information about the File.toPath method for developers who would like to leverage the new API without rewriting existing code.
最后
以上就是简单未来最近收集整理的关于重温Java经典教程(The Java™ Tutorials)第三篇-Java语言-第三章-基本I/OByte StreamsBuffered StreamsObject StreamsFile I/O (Featuring NIO.2)的全部内容,更多相关重温Java经典教程(The内容请搜索靠谱客的其他文章。








发表评论 取消回复