视频人物交互检测,首先利用图卷积网络学习空间特征,然后利用RNN学习帧间时间线索,接着利用注意力从帧间时间线索中学习片段间时间线索,最后细化回归人的活动和物体的启示。
ACM Multimedia-2020
1. 总述
由于多方面的原因,学习视频中的人-物交互是一个挑战性的问题。首先,该模型需要考虑场景中物体相对于人的方向变化。这使得基于图像的方法很难将人与物结合的RoI特征扩展到视频场景中。其次,大规模视频数据集(除了CAD-120)的难获取性使得很难训练出一个通用的、在现实场景视频中表现良好的HOI模型。最后,视频中的交互定义往往比较混乱,例如,placing vs. moving vs. reaching, opening a jar vs. closing a jar等。虽然存在这些挑战,但是视频允许利用图像中不存在的时间视觉线索。
本文提出了一个由三个阶段组成的流水线:(i)空间子网,(ii)帧级时间子网,和(iii)段级时间子网。
2. 网络结构
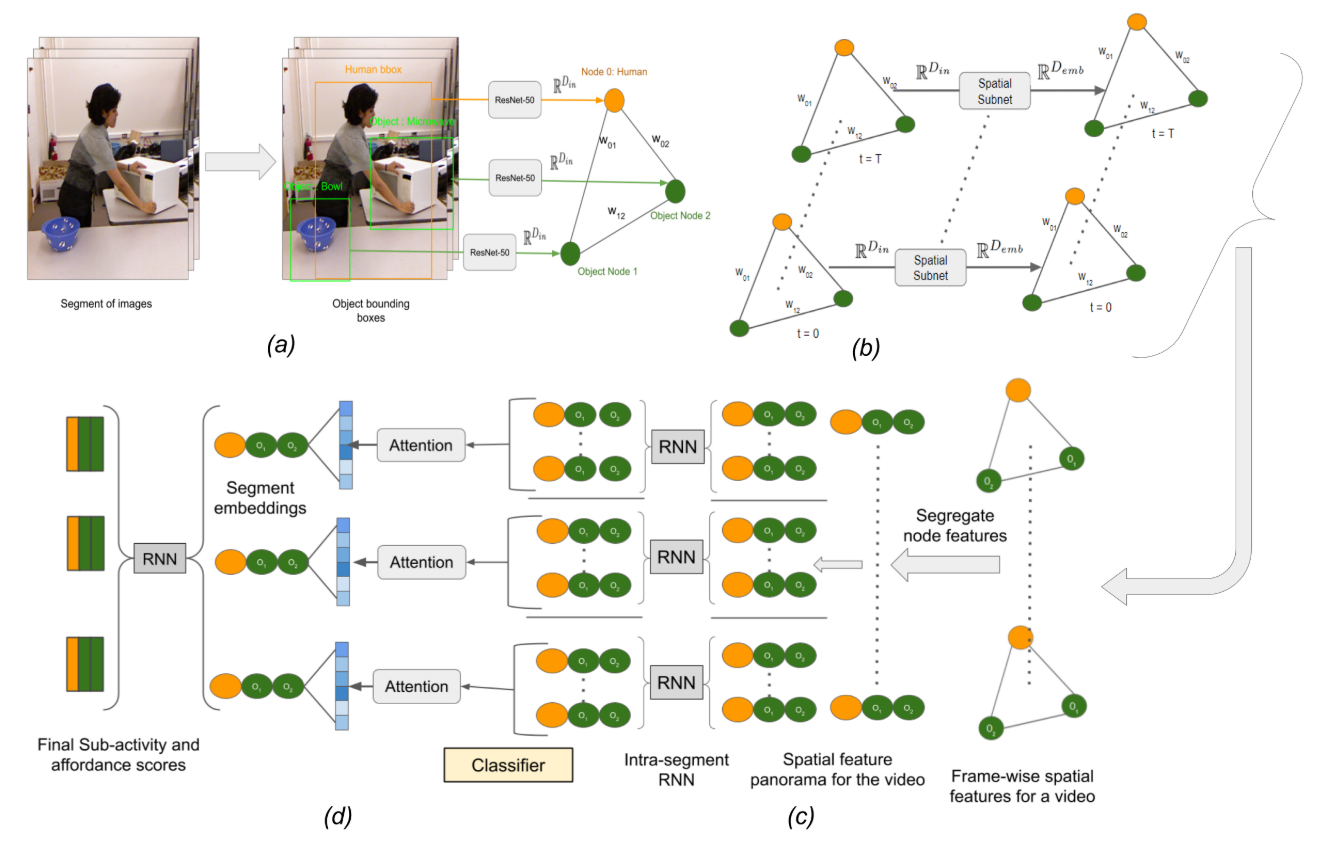
- (a)给定一段T帧的输入视频,每一帧都有人与物的边界框坐标。首先从ResNet-50中提取视觉特征。
- (b) 这些特征然后由空间子网(图神经网络)以每帧的方式进行处理得到空间特征。
- (c) 从空间特征中分离图结构,以及学习该片段中帧间的时间线索。
- (d) 利用注意机制将帧间特征归纳为片段嵌入,并利用片段间的关系对其进行细化,以回归人的子活动(拿)和物体启示(被拿)。
3. 数据集及实验
数据集为CAD-120,CAD-120数据集是一个视频数据集,包含4名受试者的120个RGB-D视频,他们每天进行10次室内活动(例如,制作谷类食品、加热食品)。每个活动都是一系列视频片段,涉及更精细的活动。在每个视频片段中,使用来自一组10个子活动类(例如,到达、浇注)的活动标签对人进行注释,并且使用来自一组12个子活动类(例如,浇注、可移动)的供给标签对每个物体进行注释。每段的帧长从22帧到150帧多一点。
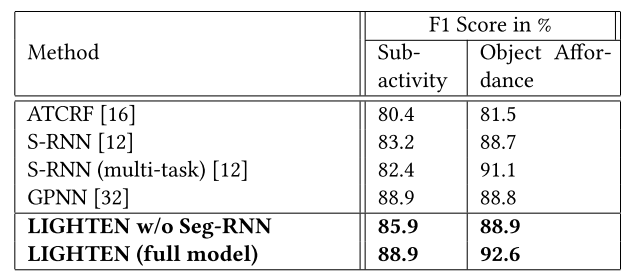
实验结果为:
最后
以上就是动人云朵最近收集整理的关于论文笔记之LIGHTEN: Learning Interactions with Graph and Hierarchical TEmporal Networks for HOI in videos1. 总述2. 网络结构3. 数据集及实验的全部内容,更多相关论文笔记之LIGHTEN:内容请搜索靠谱客的其他文章。








发表评论 取消回复