一、准备工作
以Apache 的 Ambari 2.0.1 为例
1.SSH 的无密码登录
Ambari 的 Server 会 SSH 到 Agent 的机器,拷贝并执行一些命令。因此我们需要配置 Ambari Server 到 Agent 的 SSH 无密码登录。在这个例子里,zwshen37 可以 SSH 无密码登录 zwshen38 和 zwshen39。
2.确保 Yum 可以正常工作
通过公共库(public repository),安装 Hadoop 这些软件,背后其实就是应用 Yum 在安装公共库里面的 rpm 包。所以这里需要您的机器都能访问 Internet。
3.确保 home 目录的写权限
Ambari 会创建一些 OS 用户。
4.确保机器的 Python 版本大于或等于 2.6.(Redhat6.6,默认就是 2.6 的)。
二、安装
AmbariServer
1.
取 Ambari 的公共库文件
wget
http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.0.1/ambari.repo
将下载的 ambari.repo 文件拷贝到 Linux 的系统目录/etc/yum.repos.d/
然后 依次执行以下命令:
yum clean all
yum list|grep ambari

如果可以看到 Ambari 的对应版本的安装包列表,说明公共库已配置成功
2.安装AmbariServer
yum install ambari-server
安装完成后配置:amari-server setup
在这个交互式的设置中,采用默认配置即可。Ambari 会使用 Postgres 数据库,默认会安装并使用 Oracle 的 JDK。默认设置了 Ambari GUI 的登录用户为 admin/admin。并且指定 Ambari Server 的运行用户为 root
3.启动
AmbariServer
ambari-server start
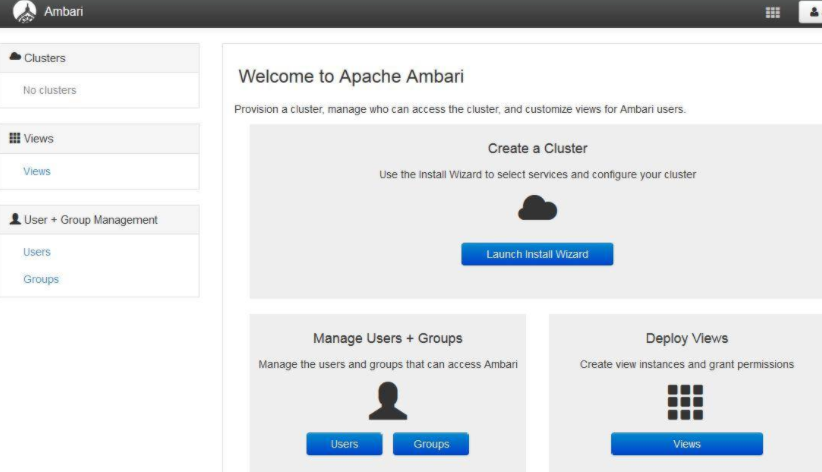
启动 Ambari Server 之后,便可以从浏览器登录,默认的端口为 8080。以本文环境为例,在浏览器的地址栏输入 http://ip:8080,登录密码为 admin/admin。登入 Ambari 之后的页面如下图
三、部署hadoop2.x集群
1.
命名集群的名字。本环境为 bigdata
登录 Ambari 之后,点击按钮”Launch Install Wizard”,就可以开始创建属于自己的大数据平台
2.
选择一个 Stack,这个 Stack 相当于一个 Hadoop 生态圈软件的集合。
Stack 的版本越高,里面的软件版本也就越高。这里我们选择 HDP2.2,里面的对应的 Hadoop 版本为 2.6.x
3.
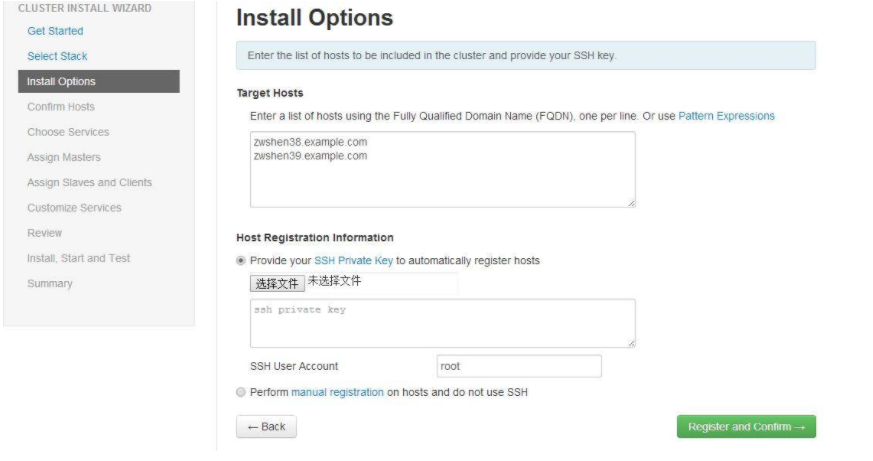
指定 Agent 机器 (如果配置了域,必须包含完整域名,例如本文环境的域为
example.com)
这些机器会被安装 Hadoop 等软件包, 需要指定当时在 Ambari Server 机器生成的私钥, 不要选择 “Perform
manual registration) on hosts and do not use SSH”。因为我们需要 Ambari Server 自动去安装 Ambari Agent
安装页面
4. Ambari Server 会自动安装 Ambari Agent 到刚才指定的机器列表。安装完成后,Agent 会向 Ambari Server 注册。成功注册后,就可以继续 Next 到下一步
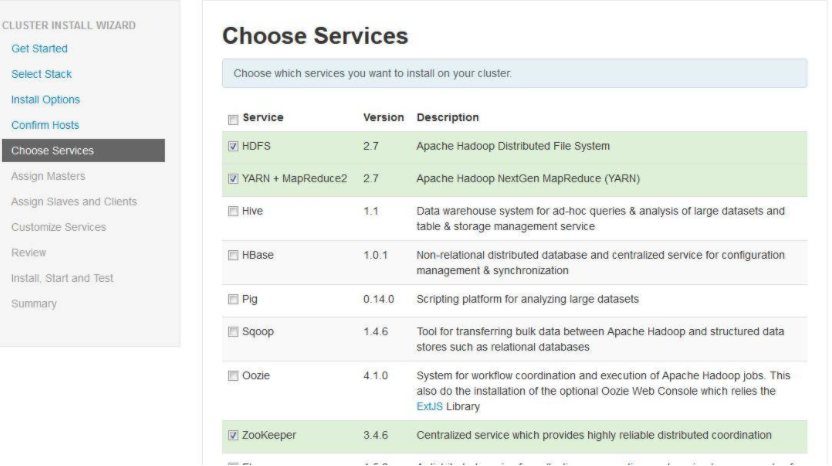
5. 选择要安装的软件名称。本文环境选择了 HDFS,YARN + MapReduce2,Zoopkeeper,Storm 以及 Spark。选的越多,就会需要越多的机器内存。选择之后就可以继续下一步了
选择页面
6. 分别是选择安装软件所指定的 Master 机器和 Slave 机器,以及 Client 机器
7. Service 的配置
绝大部分配置已经有默认值,不需要修改, 如果不需要进行调优是可以直接使用默认配置的。有些 Service 会有一些必须的手工配置项,则必须手动输入,才可以下一步
8. Ambari 会总结一个安装列表,供用户审阅。这里没问题,就直接下一步
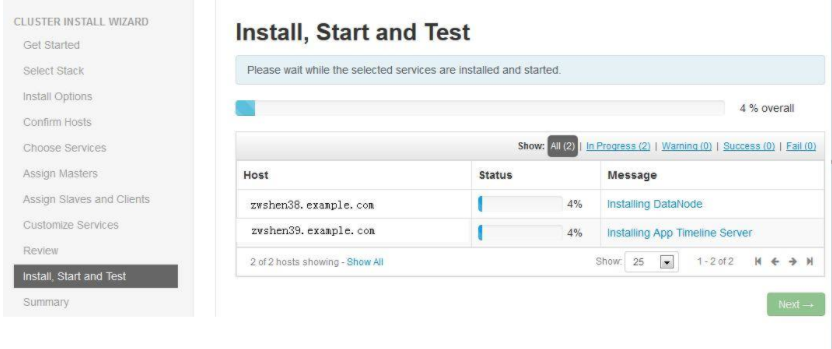
9.等待安装完成
安装进度
10.ambari的dashboard页面
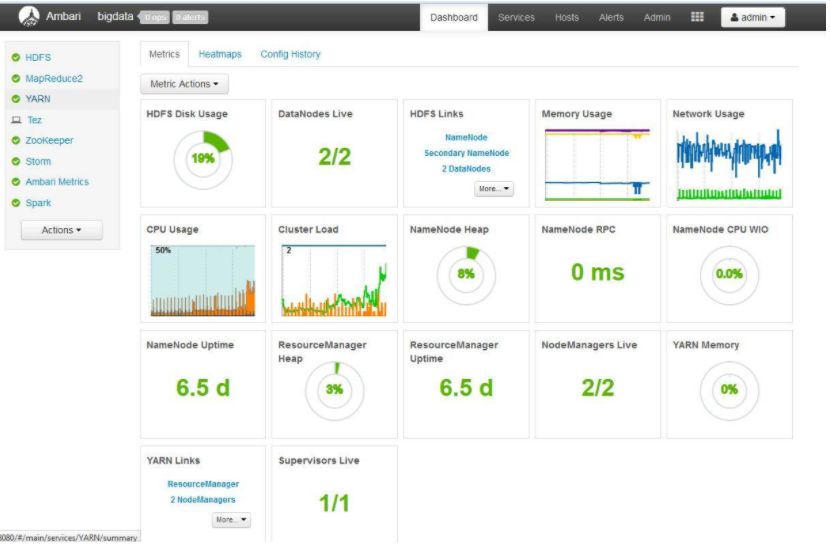
利用 Ambari 管理 Hadoop 集群
1.
Service Level Action(服务级别的操作)
左侧的 Service 列表,
点击任何一个您想要操作的 Service,
以 MapReduce2 为例,
当点击 MapReduce2 后,就会看到该 Service 的相关信息,如下图
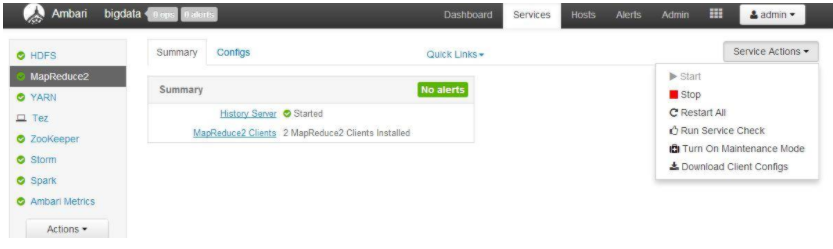
装完 Hadoop 的集群后,并不知道这个集群是不是可用。这时候我们就可以运行一个 “Run Service Check”。点击这个命令后,就会出现下图的进度显示

2.
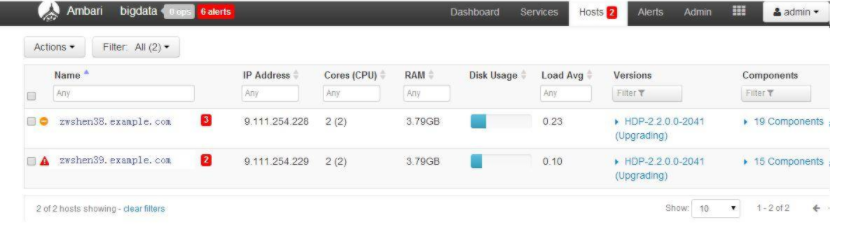
Host Level Action(机器级别的操作)
机器列表
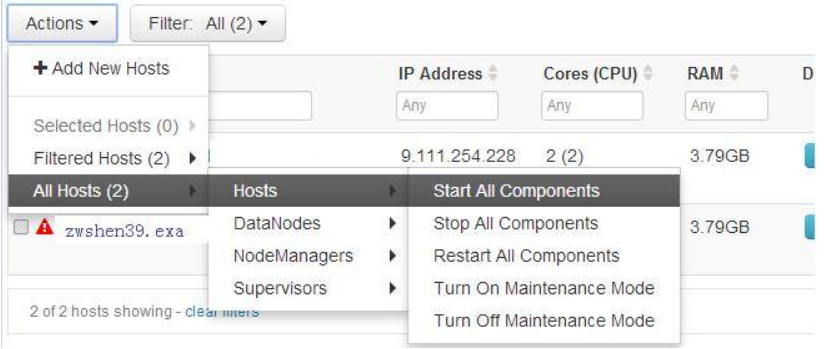
All Hosts -> Hosts -> Start All Components,Ambari 就会将所有 Service 的所有模块启动
All Hosts-> DataNodes -> Stop,Ambari 就会把所有机器的 DataNode 这个模块关闭
3.模块级别操作
点击机器名,我们就会进入到该机器的 Component 页面
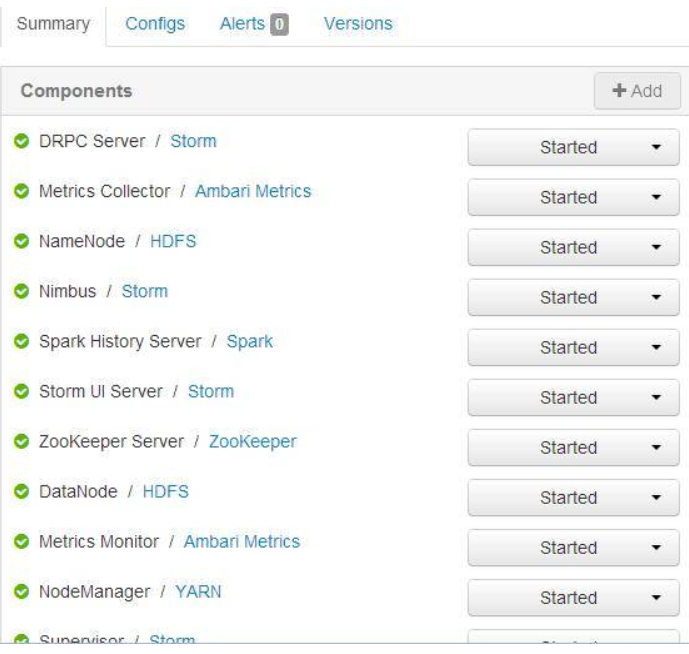
点击每个 Component(模块)后面的按钮,就可以看到该模块的操作命令了
最后
以上就是单薄钢笔最近收集整理的关于基于Ambari搭建大数据平台的全部内容,更多相关基于Ambari搭建大数据平台内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复