前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:CDA数据分析师
地摊经济火了!微博微热点数据
我们先看到微博微热点的数据:
全网热度指数趋势
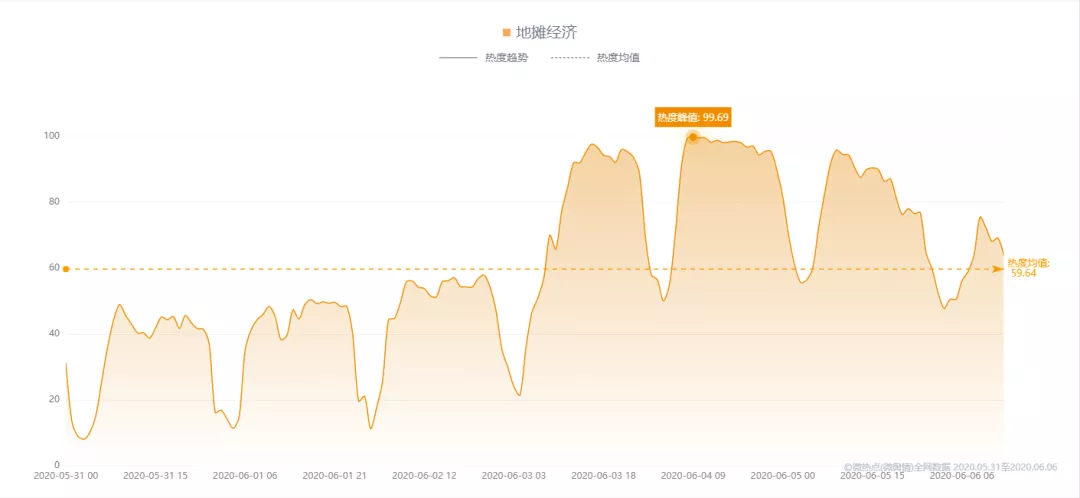
从全网热度指数的变化趋势来看,地摊经济的热度在6月3日起逐步升温,6月4日9时达到了99.69的峰值。
全网关键词云图

再看到全网关键词云图,在与地摊经济相关的全部信息中, 提及频次最高的词语依次为"地摊经济"、“摆摊"和"全员”。
B站视频弹幕数据
目前在B站上也涌现出许多关于地摊经济的视频。
我们看到其中这个关于成都地摊经济与文化的视频,目前该个视频在B站上播放量达到14.1万,收获了3856条弹幕。

地址:https://www.bilibili.com/video/BV1Ft4y1y7iG?from=search&seid=12113765873623399312
那么这些弹幕中大家都在谈论些什么呢?我们对这些弹幕进行分析整理,让我们看到词云图。
弹幕词云图

可以看到大家讨论最多的就是除了"地摊"、“成都”,还有就是"卫生"、“城管”、“利润"等内容。其中地摊"美食”、“小吃”、“烧烤”、"干净"也是大家十分关注的问题。
是否支持地摊经济弹幕投票
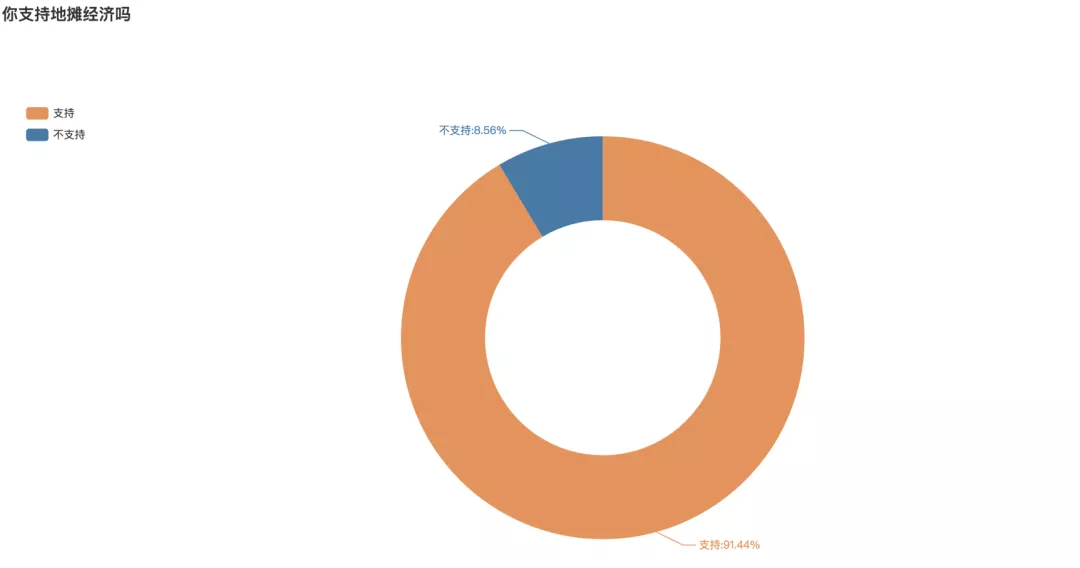
在视频结尾,也发起了你是否支持地摊经济的弹幕投票,支持的打数字1,不支持的打数字2,据统计共有1869条弹幕参与投票,其中91.44%的弹幕表示支持,不支持的仅占8.56%。
微博评论话题数据
再让我们看到对地摊经济讨论呼声最高的微博。
首先看到微博话题:#你会考虑摆地摊吗# 我们共分析整理了3436条评论数据:

可以看到在考虑是否摆地摊时,大家考虑最多的就是"城管"的问题了,曾经的城管不让摆,到今天的城管喊你来摆摊,真是活久见啊。其次"经济"、“营业额”、"收入"等也是大家特别关心的焦点。
下面是 #如果摆地摊你会卖什么# 这个话题,目前该话题共有408.6万的阅读,共3934条讨论, 去重后我们得到3657条数据。

评论词云

通过分析词云可以发现,“贴膜"是许多人都想尝试的地摊项目。其次"烧烤”、“烤冷面”、"煎饼果子"等街头美食是许多人的选择。除了吃的,“卖花”、“饰品”、"袜子"等商品也是很多人想尝试的。有意思的是,"算命"也被多次提到。
再看到 #你的专业摆地摊儿能干啥# 我们共获取1641条讨论数据。

这里就比较有意思了:
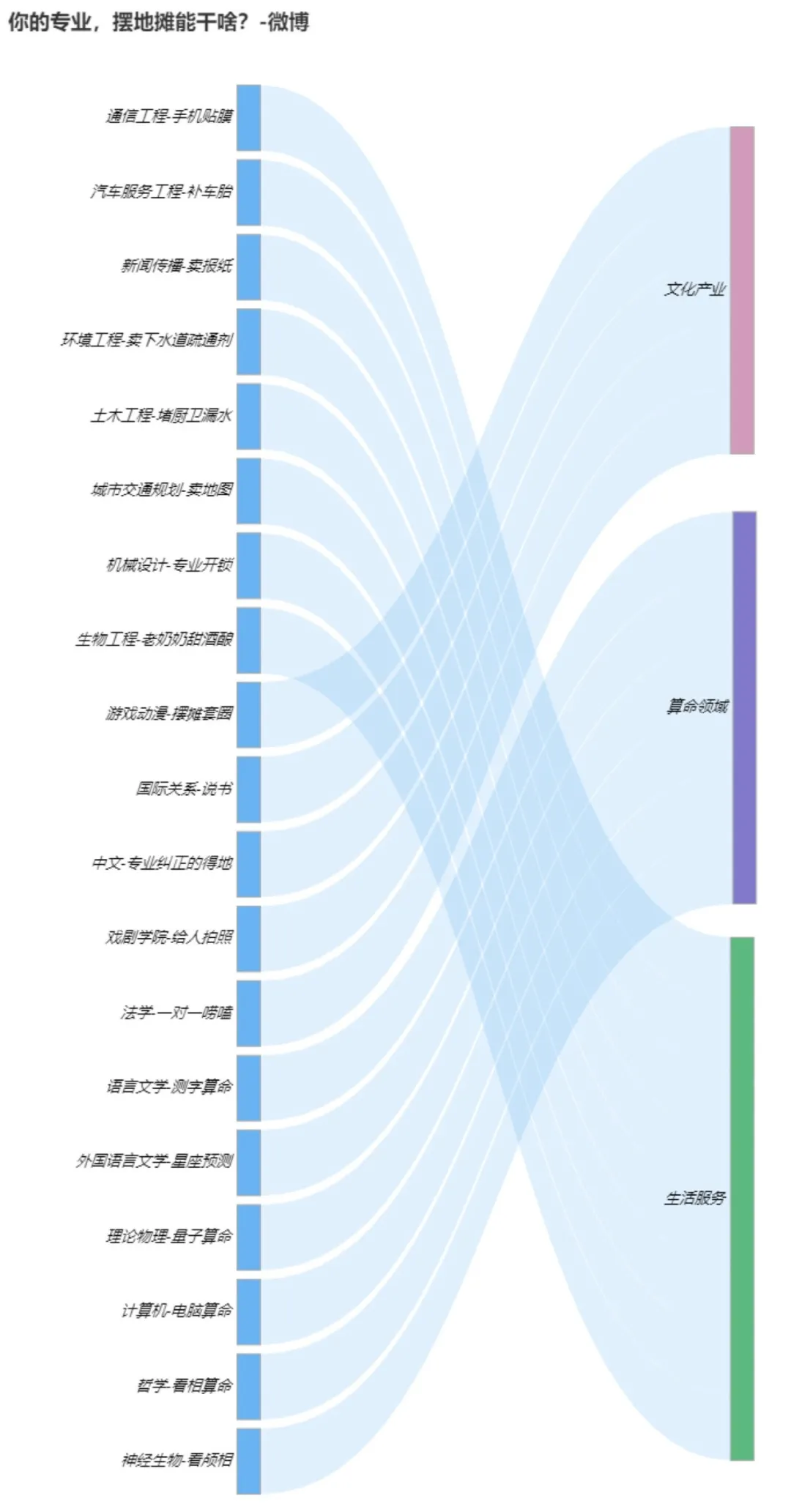
我们可以看到比如新闻传播专业的小伙伴选择卖报纸、机械专业选择专业开锁、哲学专业选择看相算命等魔幻操作。

都是哪些人在参与地摊话题的讨论呢?我们对参与话题的微博用户进行了分析,共获得4875条条数据。
微博评论用户性别占比
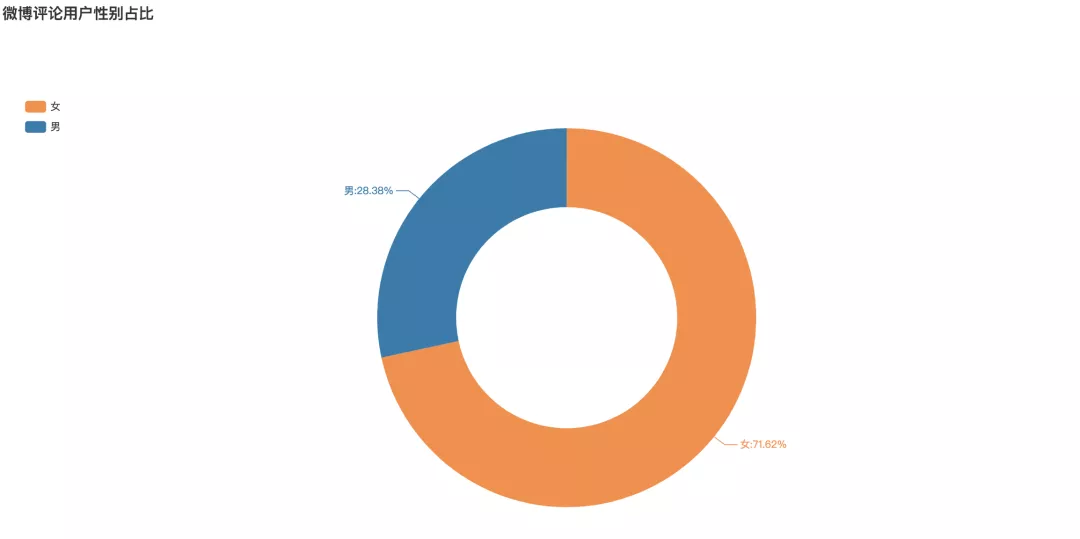
可以看到,在参与话题的用户中,女性用户占比达到了71.62%,而男性用户仅占28.38%。在地摊经济的话题中,女性用户参与比例远超男性用户。
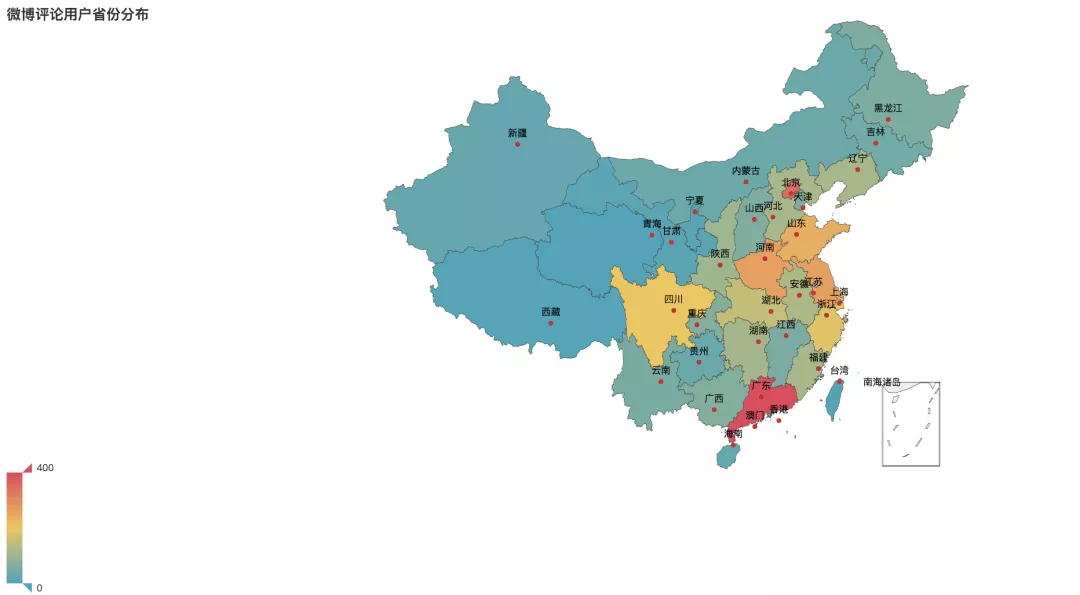
评论用户地区分布
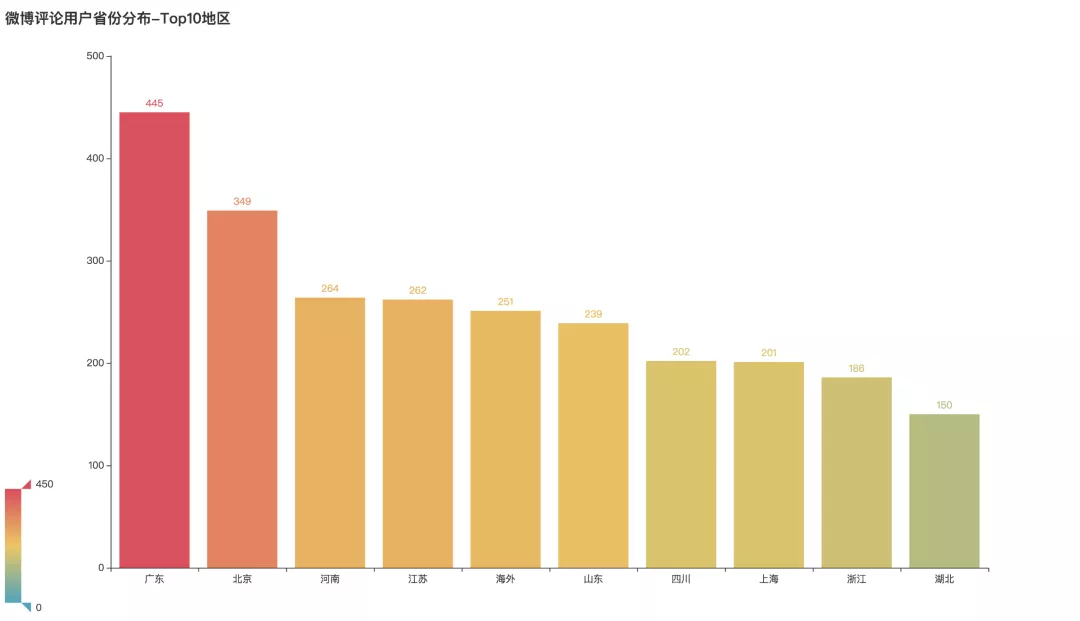
参与话题的用户都来自哪些地区呢?经过分析整理可以看到,广东、北京、河南地区参与度最高,分布位居前三名。其次是江苏、也有不少参与话题的海外用户。
评论用户年龄分布
地摊经济的话题评论中,用户年龄分布又是怎样的呢?经过分析可见,90后的参与度最高,占比高达70.56%。其次是00后,占比12.58%。然后80后位居第三,占比为9.15%。
摆摊吧 后浪!教你用Python分析微博数据
微博评论数据分析
我们使用Python获取了微博地摊经济话题的热门评论数据和B站热门视频弹幕数据,进行了处理和分析。B站弹幕的爬虫之前已经展示过,此处放上微博评论爬虫关键代码。
01 数据获取
微博分为:微博网页端、微博手机端、以及微博移动端,此次我们选择手机端(https://m.weibo.cn/)进行数据的抓取。
我们要演示的网址如下:
https://weibo.com/5382520929/J4UtmkJUJ?type=comment#_rnd1591495913796
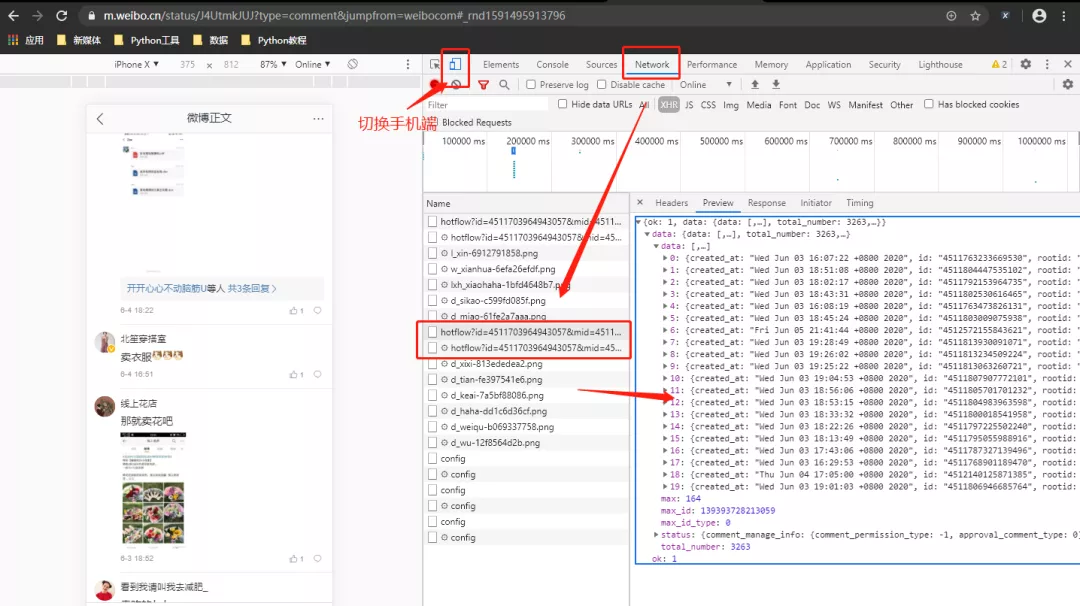
打开上面的网址之后,使用谷歌浏览器的抓包工具,将设备切换到手机端并再次刷新网页。
通过分析网页可以发现,评论的数据是通过动态js进行加载的,分析得到真实的数据请求地址:
https://m.weibo.cn/comments/hotflow?id=4511703964943057&mid=4511703964943057&max_id=140218361800408&max_id_type=0
参数说明如下:
id/mid:评论ID,抓包获取。
max_id/max_id_type: 前一页返回的response数据中。
我们使用requests获取数据,使用json进行解析并提取数据,关键代码如下:
# 导入包
import requests
import numpy as np
import pandas as pd
import re
import time
import json
from faker import Factory
def get_weibo_comment(ids, mid, max_page, max_id=0, max_id_type=0):
"""
功能:获取指定微博的评论数据,数据接口由chrome切换到手机端抓包获取。
注意事项:此程序每次获取的数量有限制,每次获取之后隔5分钟再抓取即可
"""
max_id = max_id
max_id_type = max_id_type
# 存储数据
df_all = pd.DataFrame()
for i in range(1, max_page):
# 打印进度
print('我正在获取第{}页的评论信息'.format(i))
# 获取URL
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id={}&max_id_type={}'.format(ids, mid, max_id, max_id_type)
# 添加headers
headers = {
'User-Agent': Factory().create().user_agent(),
'Referer': 'https://m.weibo.cn/detail/1591254045309',
'cookie': '复制cookie信息',
'X-Requested-With': 'XMLHttpRequest',
}
# 发起请求
try:
r = requests.get(url, headers=headers, timeout=3)
except Exception as e:
print(e)
r = requests.get(url, headers=headers, timeout=3)
if r.status_code==200:
# 解析数据
json_data = json.loads(r.text)
# 获取数据
comment_data = json_data['data']['data']
created_time = [i.get('created_at') for i in comment_data]
text = [i.get('text') for i in comment_data]
user_id = [i['user'].get('id') for i in comment_data]
screen_name = [i['user'].get('screen_name') for i in comment_data]
reply_num = [i.get('total_number') for i in comment_data]
like_count = [i.get('like_count') for i in comment_data]
# max_id
max_id = json_data['data']['max_id']
# max_id_type
max_id_type = json_data['data']['max_id_type']
# 存储数据
df_one = pd.DataFrame({
'created_time': created_time,
'text': text,
'user_id': user_id,
'screen_name': screen_name,
'reply_num': reply_num,
'like_count': like_count
})
# 追加
df_all = df_all.append(df_one, ignore_index=True)
# 休眠一秒
time.sleep(np.random.uniform(2))
else:
print('解析出错!打印最后一次的值', max_id, max_id_type)
continue
return df_all
# 运行函数
if __name__ == '__main__':
# 获取一条微博评论
df = get_weibo_comment(ids='4511703964943057', mid='4511703964943057', max_page=200)
获取到的数据以数据框的形式存储,包含评论时间、评论文本、评论用户id,回复数和点赞数。格式如下所示:
df.head()
02 数据预处理
我们对获取的数据进行初步的处理,主要包含:
- 重复值处理
- created_time:提取时间信息
- text:初步清洗
- user_id:根据用户ID获取用户相关信息,步骤暂略。
# 重复值
df = df.drop_duplicates()
# 转换字典
week_transform = {
'Mon': '星期一',
'Tue': '星期二',
'Wed': '星期三',
'Thu': '星期四',
'Fri': '星期五',
'Sat': '星期六',
'Sun': '星期日'
}
# 提取星期
df['day_week'] = df['created_time'].str.split(' ').apply(lambda x:x[0])
df['day_week'] = df['day_week'].map(week_transform)
# 提取日期时间
df['time'] = df['created_time'].str.split(' ').map(lambda x:x[-1]+'-'+x[1]+'-'+x[2]+' '+x[3])
df['time'] = df.time.str.replace('May', '05').str.replace('Jun', '06')
# text 字段处理
pattern = '<span.*?</span>|<a.*?</a>'
df['text'] = [re.sub(pattern, '', i) for i in df['text']]
# 删除列
df = df.drop(['created_time', 'user_id', 'screen_name'], axis=1)
经过清洗之后的数据格式如下:
df.head()
03 数据可视化分析
我们使用pyecharts和stylecloud进行可视化分析,此处只展示部分代码。
#如果去摆地摊该做什么生意?
def get_cut_words(content_series):
# 读入停用词表
stop_words = []
with open("stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加关键词
my_words = ['胸口碎大石', '烤冷面', '贴膜', '卖衣服', '套大鹅']
for i in my_words:
jieba.add_word(i)
# 定义停用词
my_stop_words = ['信公号', '摆地摊', '摆摊', '地摊', '哈哈哈哈', '手机',
'这是', '这是哪', '哈哈哈', '真的', '一千', '专业',
'有人', '我要', '那种', '只能', '好吃', '喜欢', '城管',
'评论', '卖点', '有没有', '秘籍',
]
stop_words.extend(my_stop_words)
# 分词
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
# 分词
text = get_cut_words(content_series=df.text)
# 获取top10
shengyi_num = pd.Series(text)
num_top10 = shengyi_num.value_counts()[:10]
# 条形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(num_top10.index.tolist())
bar1.add_yaxis('', num_top10.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='如果去摆地摊该做什么生意-Top10'),
visualmap_opts=opts.VisualMapOpts(max_=150)
)
bar1.render()
# 绘制词云图
stylecloud.gen_stylecloud(text=' '.join(text),
collocations=False,
font_path=r'C:WindowsFontsmsyh.ttc', # 更换为本机的字体
icon_name='fas fa-pie-chart',
size=768,
output_name='如果去摆地摊该做什么生意.png')
Image(filename='如果去摆地摊该做什么生意.png')
最后
以上就是彩色歌曲最近收集整理的关于地摊经济的时代真的到来了吗?今天我们就带你用数据盘一盘。你想好摆摊去卖什么了吗?前言地摊经济火了!微博微热点数据B站视频弹幕数据微博评论话题数据摆摊吧 后浪!教你用Python分析微博数据的全部内容,更多相关地摊经济的时代真的到来了吗?今天我们就带你用数据盘一盘。你想好摆摊去卖什么了吗?前言地摊经济火了!微博微热点数据B站视频弹幕数据微博评论话题数据摆摊吧内容请搜索靠谱客的其他文章。








发表评论 取消回复