1.Jupyter Notebook
1.1什么是Jupyter Notebook?
简介
Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过编码开发、文档编写、运行代码和展示结果。——Jupyter Notebook官方介绍
简而言之,Jupyter Notebook是以网页的形式打开,可以在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
1.2Jupyter Notebook的主要特点
1.编程时具有语法高亮、缩进、tab补全的功能。
2.可直接通过浏览器运行代码,同时在代码块下方展示运行结果。
3.对代码编写说明文档或语句时,支持Markdown语法。
1.3安装
① 安装前提
安装Jupyter Notebook的前提是需要安装了Python(3.3版本及以上,或2.7版本)。
② 使用Anaconda安装
建议大家通过安装Anaconda来解决Jupyter Notebook的安装问题,因为Anaconda已经自动为你安装了Jupter Notebook及其他工具,还有python中超过180个科学包及其依赖项。
你可以通过进入Anaconda的 https://www.anaconda.com/download 自行选择下载;
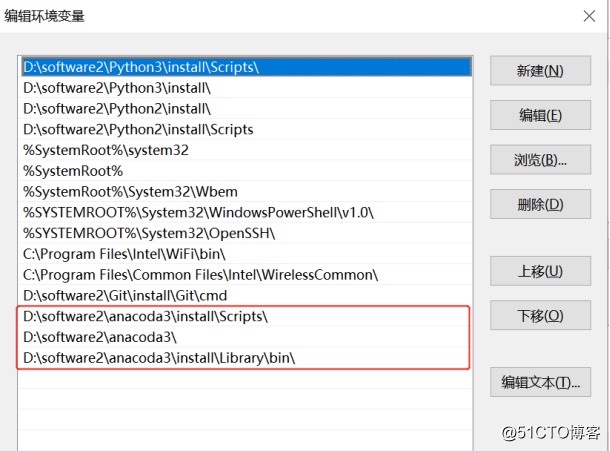
安装过程中我是一路默认,点击下一步,所以需要设置操作系统的环境变量
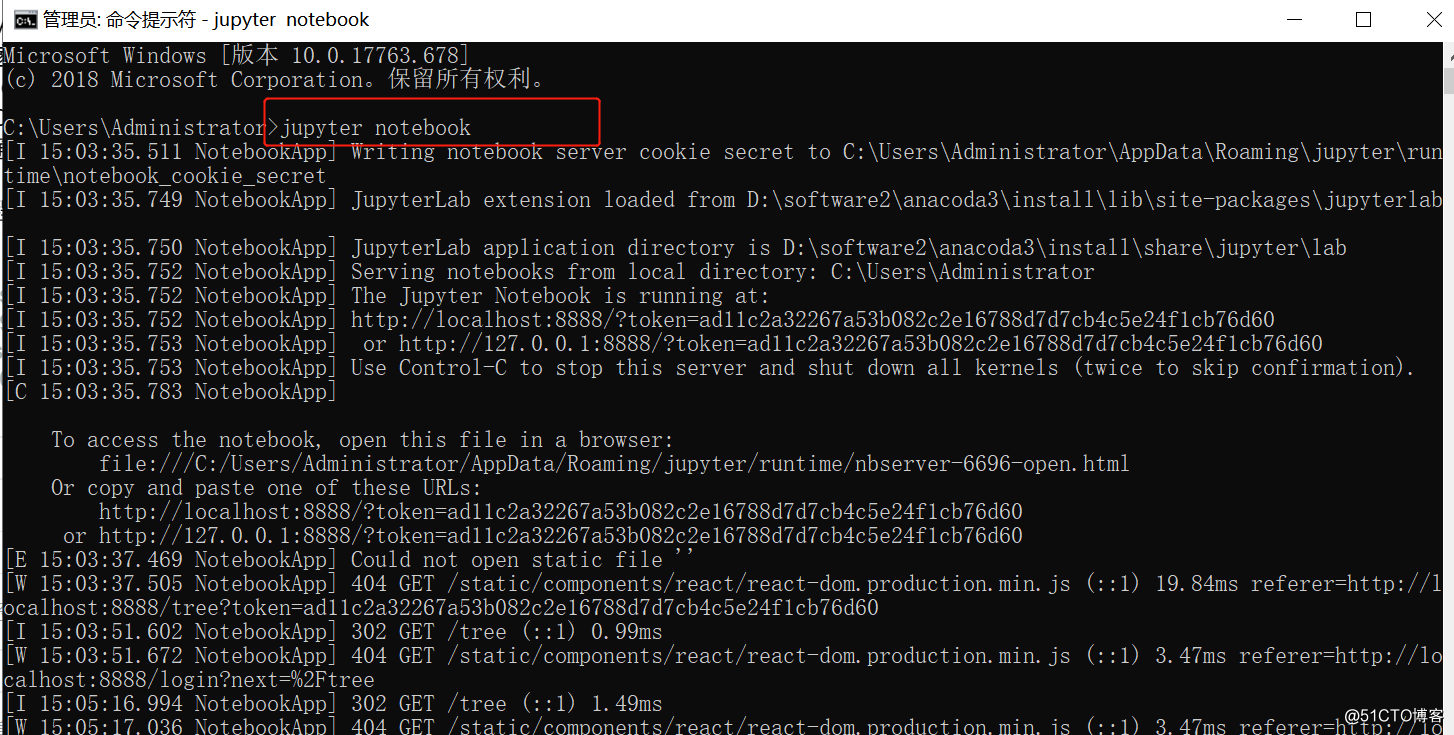
1.3使用介绍:
快捷键:
b:向下插入一个cell
a:向上插入一个cell
m:将cell的类型切换成markdown类型
y:将cell的类型切换成code类型
shift+enter:执行cell
shift+tab:查看模块的帮助文档
tab:自动补全
2.urllib模块
2.1urllib介绍
- python中自带的一个基于爬虫的模块。
- 作用:可以使用代码模拟浏览器发起请求。request parse
- 使用流程:
- 指定url
- 发起请求
- 获取页面数据
- 持久化存储2.2 爬取搜狗首页的页面数据
# 需求:爬取搜狗首页的页面数据
import urllib.request
#1.指定url
url = 'https://www.sogou.com/'
#2.发起请求:urlopen可以根据指定的url发起请求,切返回一个响应对象
response = urllib.request.urlopen(url=url)
#3.获取页面数据:read函数返回的就是响应对象中存储的页面数据(byte)
page_text = response.read()
#4.持久化存储
with open('./sougou.html','wb') as fp:
fp.write(page_text)
print('写入数据成功')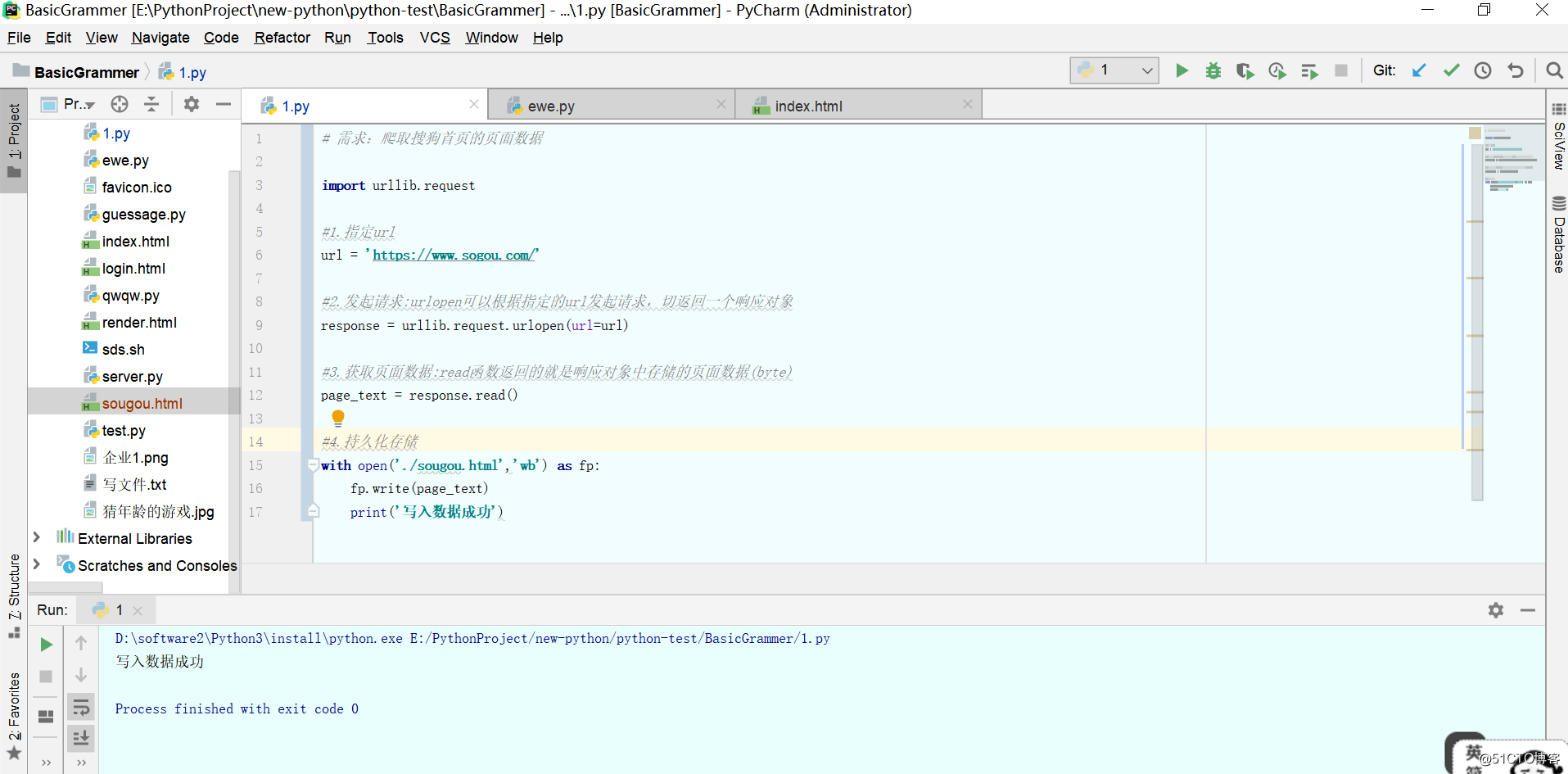
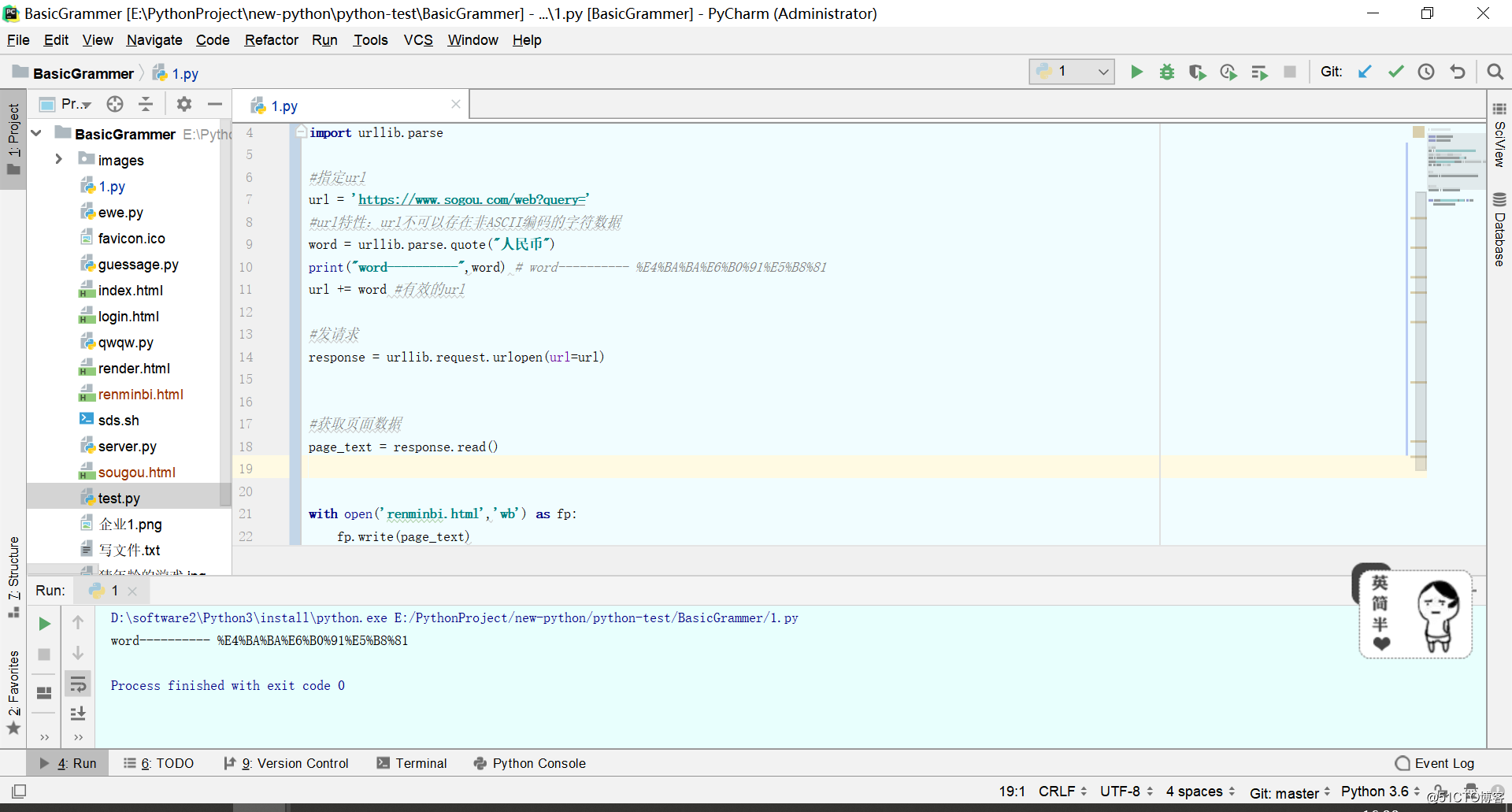
2.3爬取指定词条所对应的页面数据
# 需求:爬取指定词条所对应的页面数据
import urllib.request
import urllib.parse
#指定url
url = 'https://www.sogou.com/web?query='
#url特性:url不可以存在非ASCII编码的字符数据
word = urllib.parse.quote("人民币")
print("word----------",word) # word---------- %E4%BA%BA%E6%B0%91%E5%B8%81
url += word #有效的url
#发请求
response = urllib.request.urlopen(url=url)
#获取页面数据
page_text = response.read()
with open('renminbi.html','wb') as fp:
fp.write(page_text)
2.4UA伪装
- 反爬机制:网站检查请求的UA,如果发现UA是爬虫程序,则拒绝提供网站数据。
- User-Agent(UA):请求载体的身份标识.
- 反反爬机制:伪装爬虫程序请求的UA
import urllib.request
url = 'https://www.baidu.com/'
#UA伪装
#1.子制定一个请求对象
headers = {
#存储任意的请求头信息
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
}
#该请求对象的UA进行了成功的伪装
request = urllib.request.Request(url=url,headers=headers)
#2.针对自制定的请求对象发起请求
response = urllib.request.urlopen(request)
print(response.read())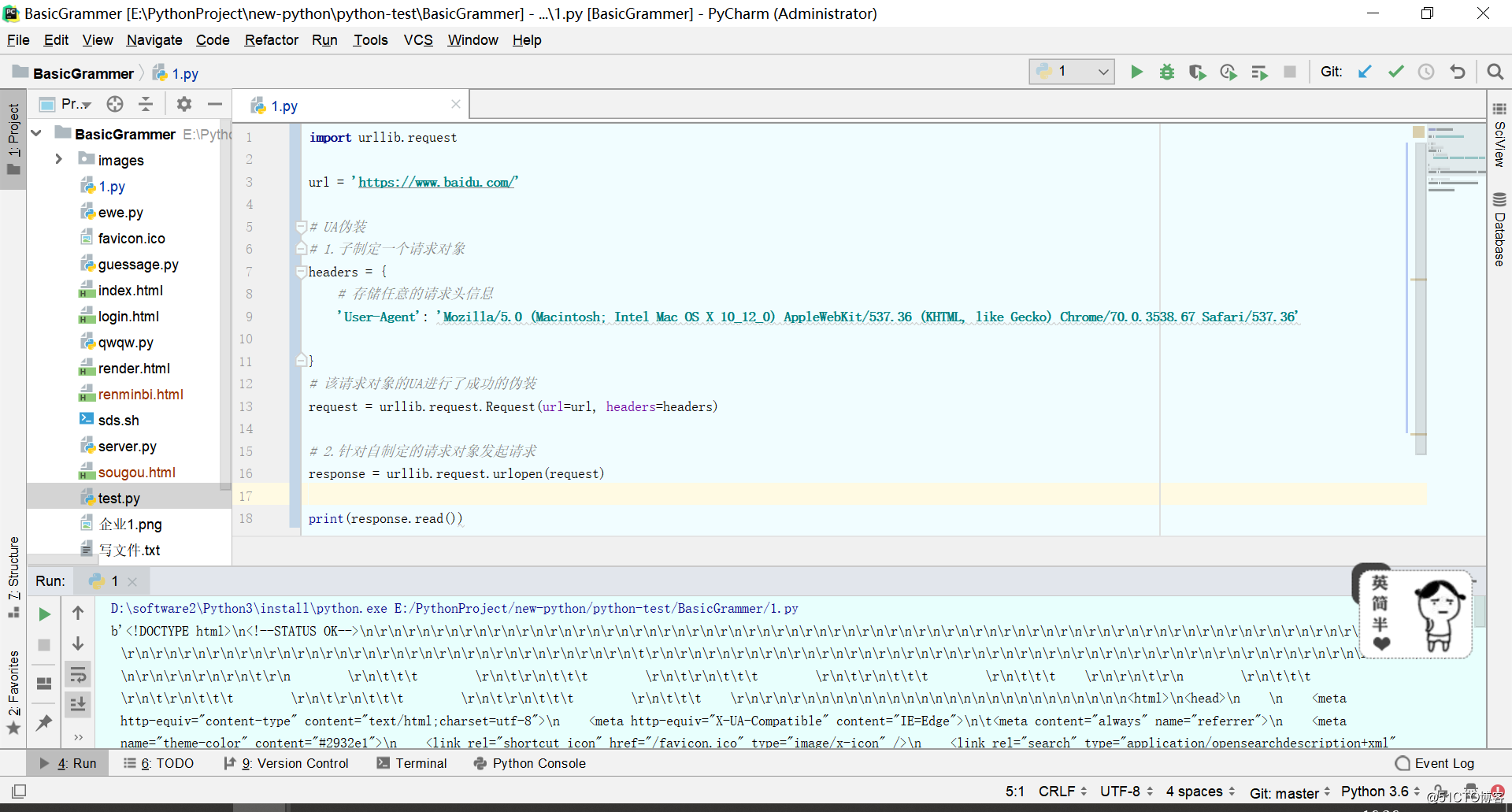
2.5urlib模块发起的post请求
◾需求:爬取百度翻译的翻译结果
import urllib.request
import urllib.parse
#1.指定url
url = 'https://fanyi.baidu.com/v2transapi'
#post请求携带的参数进行处理 流程:
#1.将post请求参数封装到字典
# from: zh
# to: en
# query: 西瓜
# transtype: translang
# simple_means_flag: 3
# sign: 550632.820697
# token: a11964798a7300c4f0f505e81cd5ae87
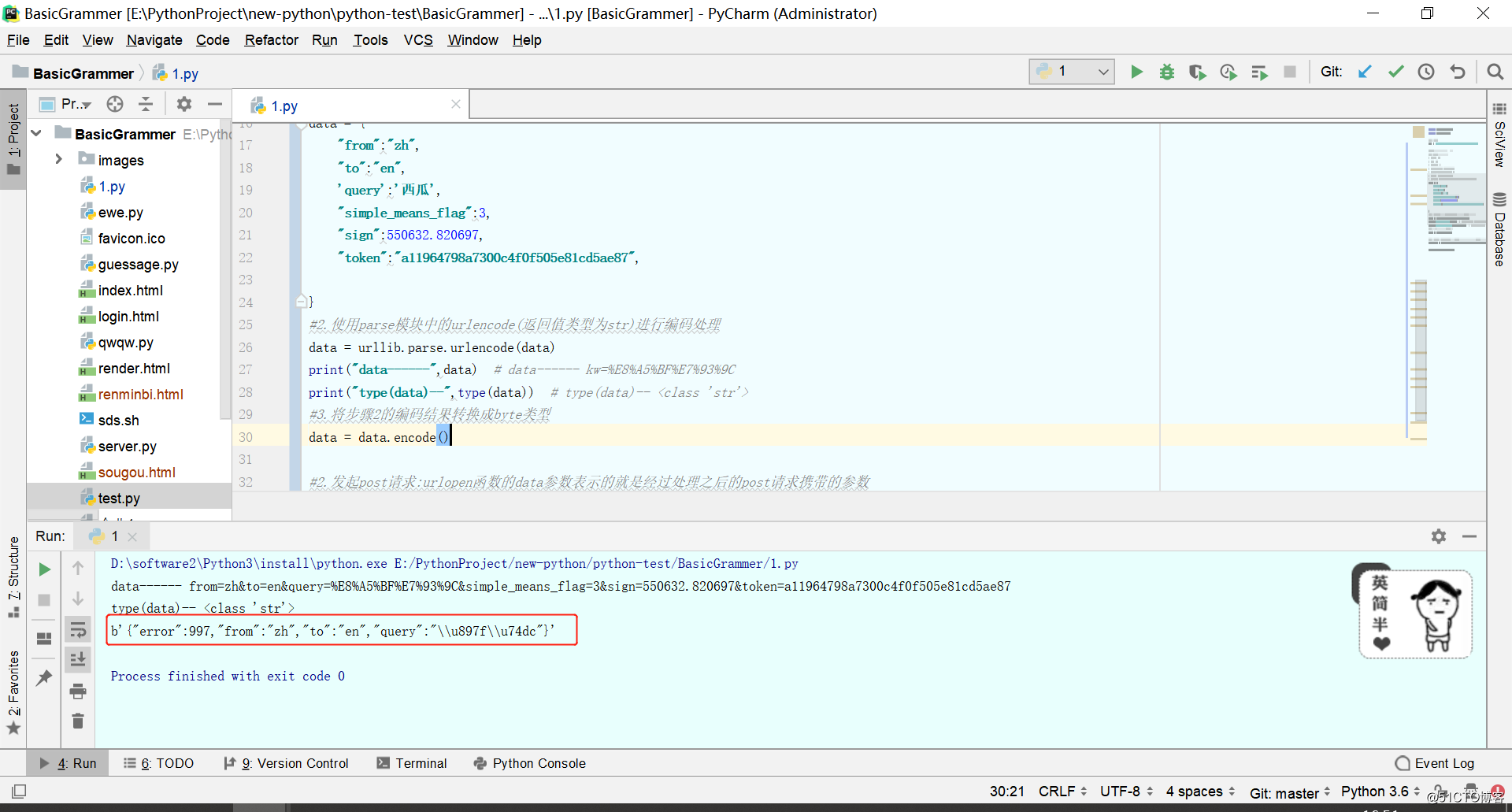
data = {
"from":"zh",
"to":"en",
'query':'西瓜',
"simple_means_flag":3,
"sign":550632.820697,
"token":"a11964798a7300c4f0f505e81cd5ae87",
}
#2.使用parse模块中的urlencode(返回值类型为str)进行编码处理
data = urllib.parse.urlencode(data)
print("data------",data) # data------ kw=%E8%A5%BF%E7%93%9C
print("type(data)--",type(data)) # type(data)-- <class 'str'>
#3.将步骤2的编码结果转换成byte类型
data = data.encode()
#2.发起post请求:urlopen函数的data参数表示的就是经过处理之后的post请求携带的参数
response = urllib.request.urlopen(url=url,data=data)
print(response.read())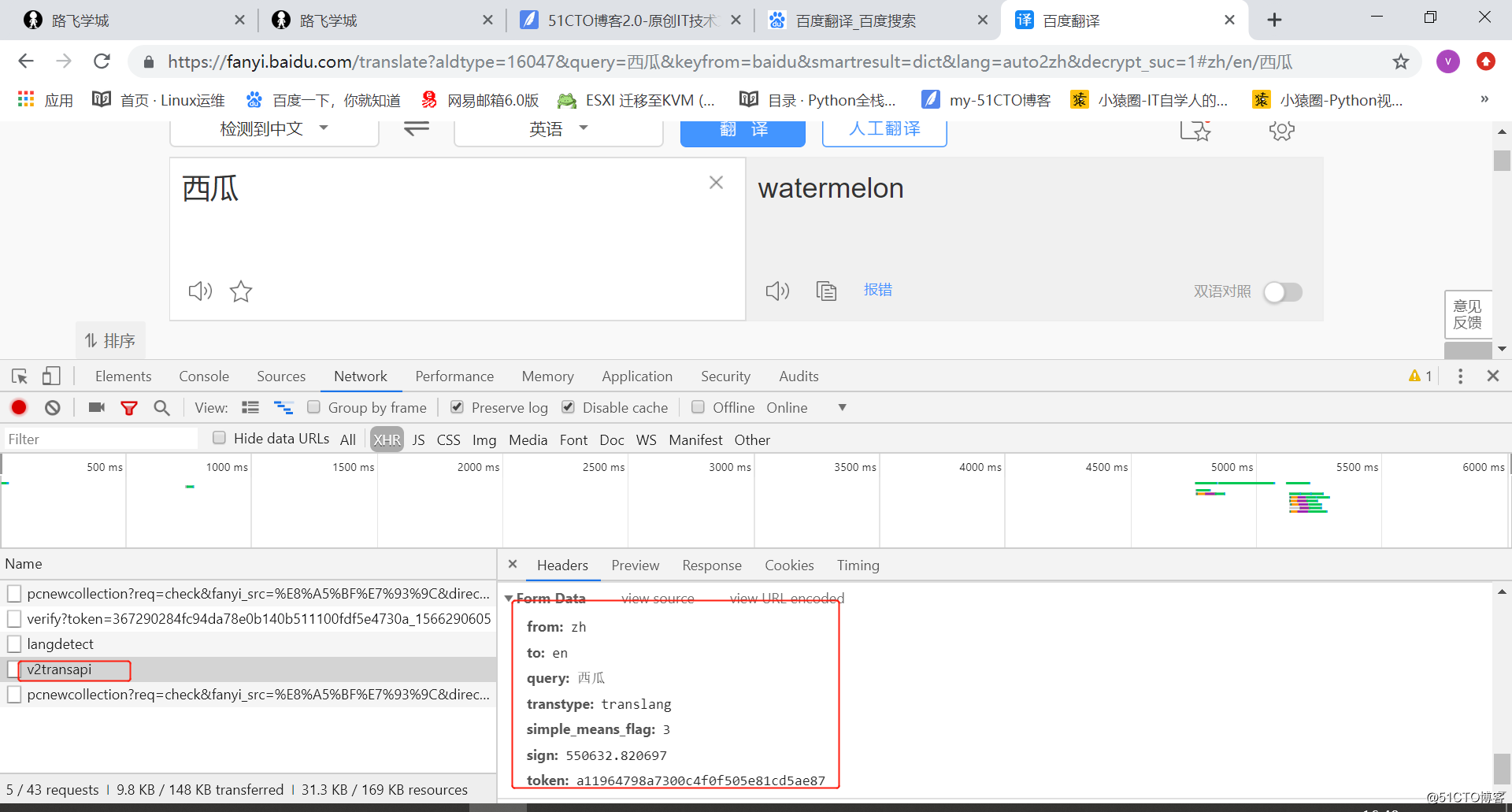
3.request模块
3.1介绍
- 1.什么是requests模块
- python原生一个基于网络请求的模块,模拟浏览器发起请求。
- 2.为什么要使用requests模块
- 1.自动处理url编码
- 2.自动处理post请求的参数
- 3.简化cookie的代理的操作:
cookie操作:
- 创建一个cookiejar对象
- 创建一个handler对象
- 创建一个operner
代理操作:
- 创建handler对象,代理ip和端口封装到该对象
- 创建openner对象
- 3.requests如何被使用
- 安装:pip install requests
- 使用流程:
- 1.指定url
- 2.使用requests模块发起请求
- 3.获取响应数据
- 4.进行持久化存储
- 4.通过5个基于requests模块的爬虫项目对该模块进行系统学习和巩固
- get请求
- post请求
- ajax的get
- ajax的post
- 综合3.2爬取搜狗首页的页面数据
- 需求:爬取搜狗首页的页面数据
-
import requests
#指定url
url = 'https://www.sogou.com/'
#发起get请求:get方法会返回请求成功的相应对象
response = requests.get(url=url)
#获取响应中的数据值:text可以获取响应对象中字符串形式的页面数据
page_data = response.text
print(page_data)
#持久化操作
with open('./sougou.html','w',encoding='utf-8') as fp:
fp.write(page_data)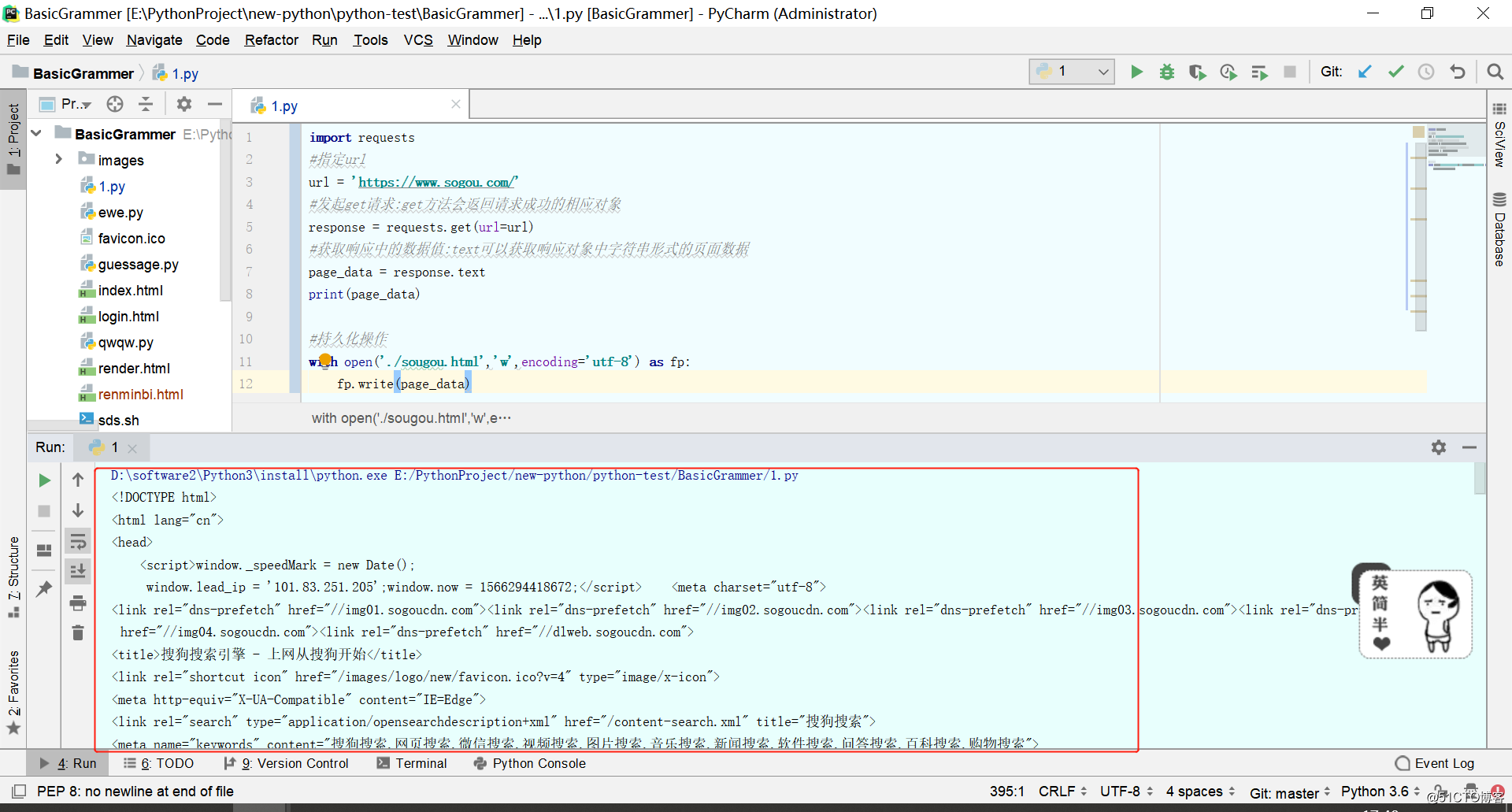
3.3response对象中其他重要的属性
#response对象中其他重要的属性
import requests
#指定url
url = 'https://www.sogou.com/'
#发起get请求:get方法会返回请求成功的相应对象
response = requests.get(url=url)
#content获取的是response对象中二进制(byte)类型的页面数据
print("response.content----------",response.content) # b'<!DOCTYPE html>rn<html lang="cn">rn<head>rn
#返回一个响应状态码
print("response.status_code------",response.status_code) # 200
#返回响应头信息
print(response.headers)
# {'Server': 'nginx', 'Date': 'Tue, 20 Aug 2019 09:53:00 GMT', 'Content-Type': 'text/html; charset=UTF-8', 'Content-Encoding': 'gzip'}
#获取请求的url
print(response.url) # https://www.sogou.com/3.4requests模块如何处理携带参数的get请求
◾需求:指定一个词条,获取搜狗搜索结果所对应的页面数据
方式一:
import requests
url = 'https://www.sogou.com/web?query=周杰伦&ie=utf-8'
response = requests.get(url=url)
page_text = response.text
print(page_text)
with open('./zhou.html','w',encoding='utf-8') as fp:
fp.write(page_text)方式二:
import requests
#自定义请求头信息
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
#指定url
url = 'https://www.sogou.com/web'
#封装get请求参数
prams = {
'query':'周杰伦',
'ie':'utf-8'
}
#发起请求
response = requests.get(url=url,params=param)
response.status_code
方式三:
# 自定义请求头信息
import requests
url = 'https://www.sogou.com/web'
#将参数封装到字典中
params = {
'query':'周杰伦',
'ie':'utf-8'
}
#自定义请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
response = requests.get(url=url,params=params,headers=headers)
response.status_code3.5基于requests模块发起的post请求
- 需求:登录豆瓣网,获取登录成功后的页面数据
import requests
#1.指定post请求的url
url = 'https://accounts.douban.com/j/mobile/login/basic'
#封装post请求的参数
data = {
"ck":"",
"name": "13764739092",
"password": "你的账户密码",
"remember": "false",
"ticket":""
}
#自定义请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
#2.发起post请求
response = requests.post(url=url,data=data,headers=headers)
#3.获取响应对象中的页面数据
page_text = response.text
print(page_text)
#4.持久化操作
with open('./douban.html','w',encoding='utf-8') as fp:
fp.write(page_text)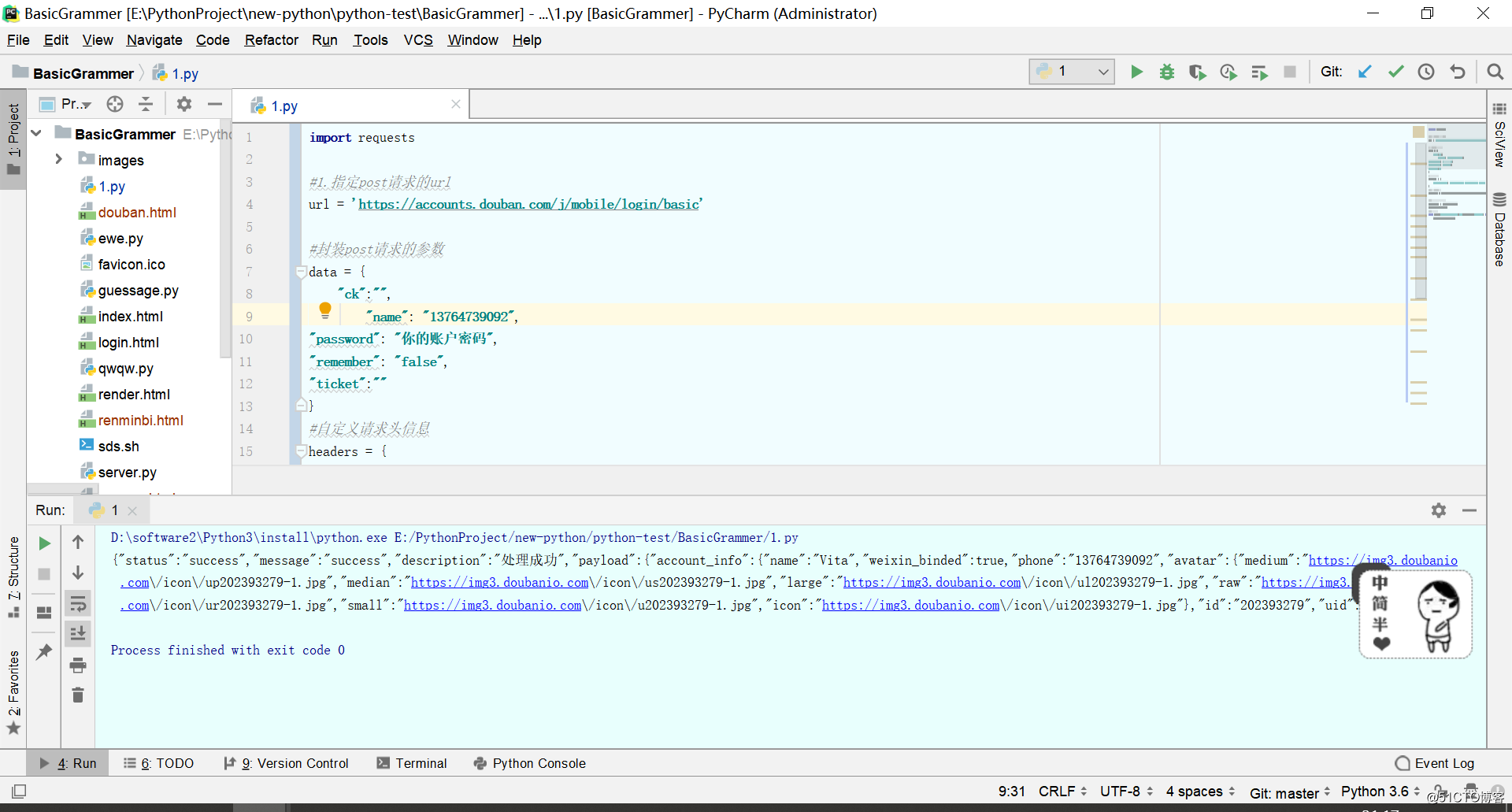
3.6基于ajax的get请求
-需求:抓取豆瓣电影上电影详情的数据
import requests
url = 'https://movie.douban.com/j/chart/top_list?'
#封装ajax的get请求中携带的参数
params = {
'type':'5',
'interval_id':'100:90',
'action':'',
'start':'100',
'limit':'20'
}
#自定义请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
response = requests.get(url=url,params=params,headers=headers)
print(response.text)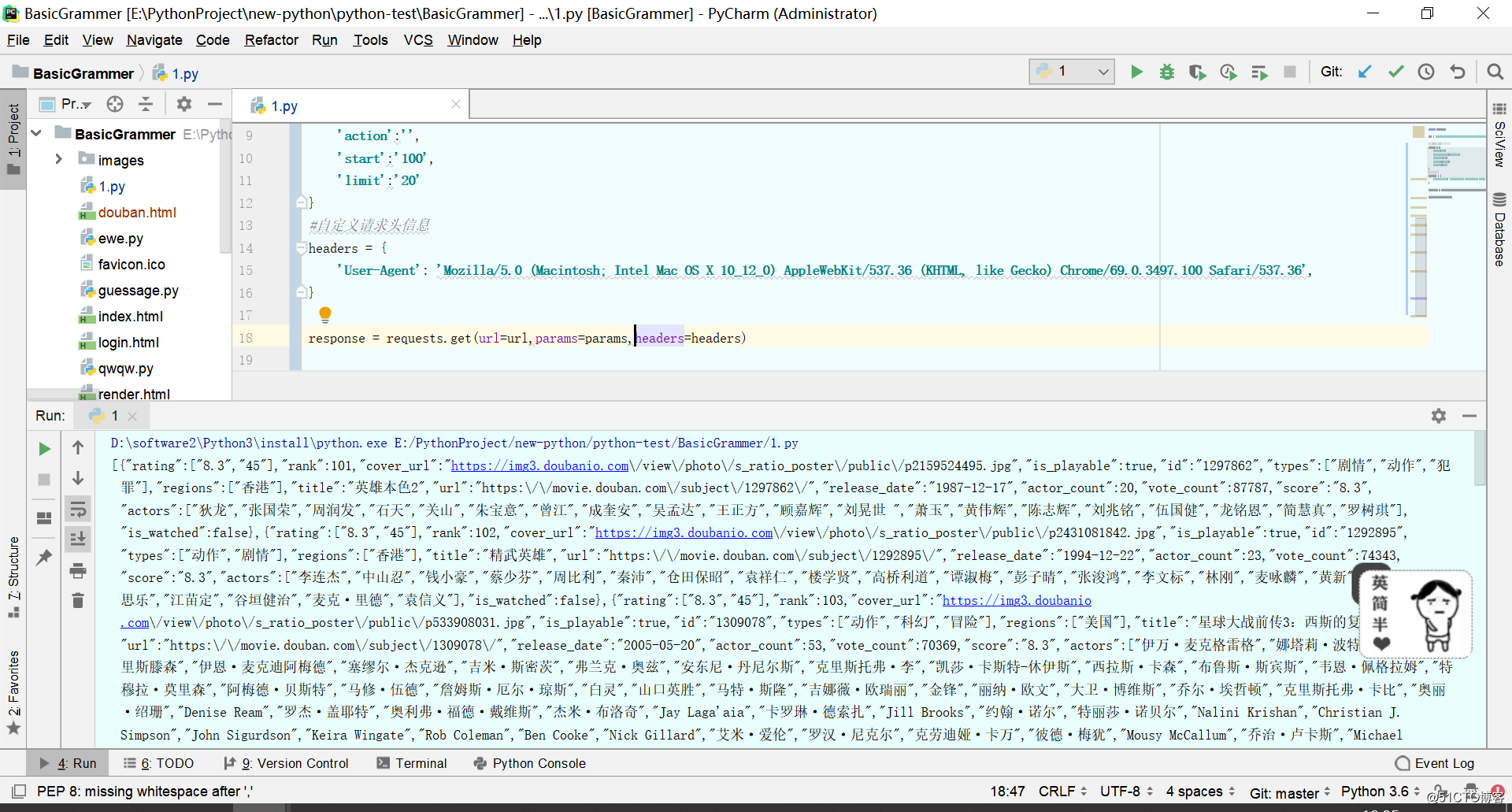
3.7基于ajax的post请求
- 需求:爬去肯德基城市餐厅位置数据
import requests
#1指定url
post_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
#处理post请求的参数
data = {
"cname": "",
"pid": "",
"keyword": "上海",
"pageIndex": "1",
"pageSize": "10",
}
#自定义请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
#2发起基于ajax的post请求
response = requests.post(url=post_url,headers=headers,data=data)
print(response.text)
3.8综合应用
- 需求:爬取搜狗知乎某一个词条对应一定范围页码表示的页面数据
#前三页页面数据(1,2,3)
import requests
import os
#创建一个文件夹
if not os.path.exists('./pages'):
os.mkdir('./pages')
word = input('enter a word:')
#动态指定页码的范围
start_pageNum = int(input('enter a start pageNum:'))
end_pageNum = int(input('enter a end pageNum:'))
#自定义请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
#1.指定url:设计成一个具有通用的url
url = 'https://zhihu.sogou.com/zhihu'
for page in range(start_pageNum,end_pageNum+1):
param = {
'query':word,
'page':page,
'ie':'utf-8'
}
response = requests.get(url=url,params=param,headers=headers)
#获取响应中的页面数据(指定页码(page))
page_text = response.text
#进行持久化存储
fileName = word+str(page)+'.html'
filePath = 'pages/'+fileName
with open(filePath,'w',encoding='utf-8') as fp:
fp.write(page_text)
print('第%d页数据写入成功'%page)
最后
以上就是称心八宝粥最近收集整理的关于爬虫1.Jupyter Notebook2.urllib模块3.request模块的全部内容,更多相关爬虫1.Jupyter内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复