我要解析的网址是:http://browse.renren.com/sAjax.do?ajax=1&q=&p=[{%22t%22:%22age%22,%22range%22:%221%22}]&s=0&u=874525581&act=search&offset=0&sort=0
貌似是需要人人账号才能登陆。
我想要得到这个页面一共十个用户的id。从chrome开发者工具的Element中可以看到–>
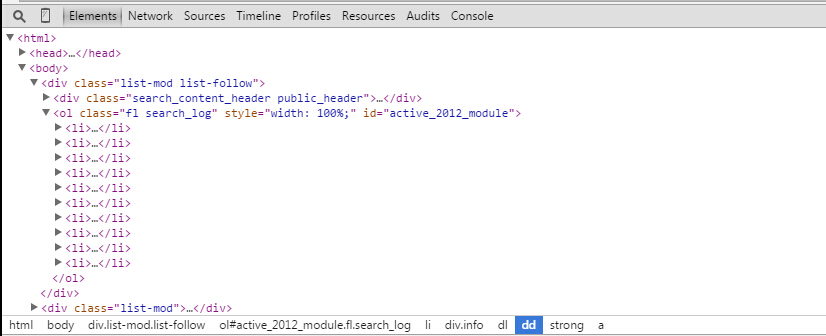
先找到 ol class=”fl search_log”等等等 这个标签,再去找他的直接子孩子,10个 li 标签(ol和li标签在源代码中也是有的,不用担心在Element中有,在查看网页源代码中没有)。
于是我在python2中:
ageUrl = 'http://browse.renren.com/sAjax.do?ajax=1&q=&p=[{"t":"age","range":"1"}]&s=0&u=874525581&act=search&offset=%0&sort=0'
agePage = urllib2.urlopen(ageUrl).read()
liList = BeautifulSoup(agePage).find(class_=['f1', 'search_log']).find_all('li', recursive=False)可以得到:

是10个
再看 ol class=f1 search_log… 标签的孩子吧:
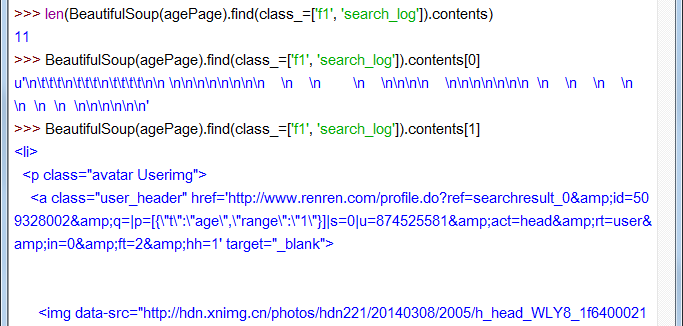
11个孩子,contents[1]显示不全,是一个用户的 li
我再用python3:

可以去看liList,它把所有10个li都作为列表的一项了(这里就不放图了)
再看 ol class=f1 search_log… 标签的孩子吧
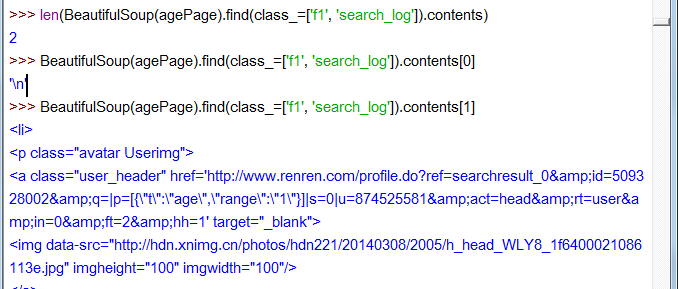
两个孩子。contents[1]显示不全,好长一溜儿呢,是10个用户的 li
我不知道为什么网页结构解析的都不一样
stackoverflow上有个问题Python3, BeautifulSoup dropping a paragraph tag,人家那是BeautifulSoup解析前后网页结构不一样,和我的还是有点差别的。
里面有说到,对于网页结构不好的页面来说,使用不同的解析器结果是不同的。参见BeautifulSoup文档中的代码诊断:
如果想知道Beautiful Soup到底怎样处理一份文档,可以将文档传入 diagnose() 方法(Beautiful Soup 4.2.0中新增),Beautiful Soup会输出一份报告,说明不同的解析器会怎样处理这段文档,并标出当前的解析过程会使用哪种解析器:
from bs4.diagnose import diagnose
data = open("bad.html").read()
diagnose(data)
# Diagnostic running on Beautiful Soup 4.2.0
# Python version 2.7.3 (default, Aug 1 2012, 05:16:07)
# I noticed that html5lib is not installed. Installing it may help.
# Found lxml version 2.3.2.0
#
# Trying to parse your data with html.parser
# Here's what html.parser did with the document:
# ...那我就在python2,3中分别试下,看他们用的是什么解析器

可以看到python2是html.parser。
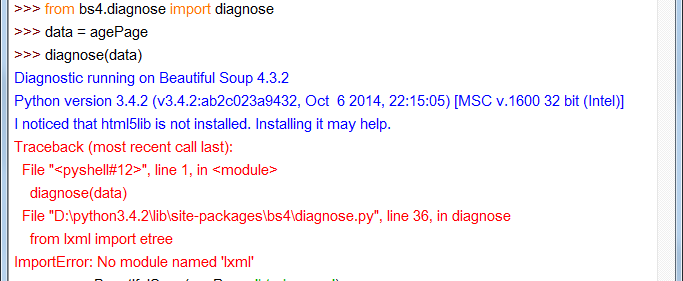
非常悲剧的看到,python3是先试了html5lib(不是说lxml最优先的么?),再去找lxml,没有居然报错了,奇怪。算了,两个都没有,我想他也是用的html.parser咯。
所以py2和py3用的都是html.parser,然后结果不一样。
我不知道怎么解决。
最后
以上就是紧张翅膀最近收集整理的关于【问题】使用BeautifulSoup解析在python2和python3下表现不一样?的全部内容,更多相关【问题】使用BeautifulSoup解析在python2和python3下表现不一样内容请搜索靠谱客的其他文章。








发表评论 取消回复