我们平时使用浏览器上网,浏览器会把服务器返回来的HTML源代码翻译为我们能看懂的样子,之后我们才能在网页上做各种操作。
BeautifulSoup怎么用

*第1个参数是要被解析的文本,注意了,它必须必须必须是字符串
*括号中的第2个参数用来标识解析器,我们要用的是一个Python内置库:html.parser。(它不是唯一的解析器,却是简单的那个)
我们看看具体的用法。仍然以网站这个书苑不太冷为例(url:这个书苑不太冷5.0),假设我们想爬取网页中的书籍类型、书名、链接、和书籍介绍。
根据之前所学的requests.get(),我们可以先获取到一个Response对象,并确认自己获取成功:
# 调用requests库
import requests
# 获取网页源代码,得到的res是response对象
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 检查请求是否正确响应
print(res.status_code)
# 把res的内容以字符串的形式返回
html = res.text
# 打印html
print(html)
上面的代码是html基础学过的内容,好,接下来就轮到BeautifulSoup登场解析数据了,请特别留意第3行和第6行新增的代码。
import requests
# 引入BS库,下面的bs4就是beautifulsoup4
from bs4 import BeautifulSoup
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 把网页解析为BeautifulSoup对象
soup = BeautifulSoup(res.text,'html.parser')
第3行是引入BeautifulSoup库。
这就是解析数据的用法
接下来,我们来打印看看soup的数据类型,和soup本身(第5行开始为新增代码)。
import requests
from bs4 import BeautifulSoup
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
soup = BeautifulSoup( res.text,'html.parser')
# 查看soup的类型
print(type(soup))
# 打印soup
print(soup)
看看运行结果,soup的数据类型是<class 'bs4.BeautifulSoup'>,说明soup是一个BeautifulSoup对象。
细心的同学会发现跟使用response.text显示的结果相同。虽然response.text和soup打印出的内容表面上看长得一模一样,却有着不同的内心,它们属于不同的类:<class 'str'> 与<class 'bs4.BeautifulSoup'>。前者是字符串,后者是已经被解析过的BeautifulSoup对象。之所以打印出来的是一样的文本,是因为BeautifulSoup对象在直接打印它的时候会调用该对象内的str方法,所以直接打印 bs 对象显示字符串是str的返回结果。
我们之后还会用BeautifulSoup库来提取数据,如果这不是一个BeautifulSoup对象,我们是没法调用相关的属性和方法的,所以,我们刚才写的代码是非常有用的,并不是重复劳动、
到这里,你就学会了使用BeautifulSoup去解析数据:
from bs4 import BeautifulSoup soup = BeautifulSoup(字符串,'html.parser')
提取数据
我们仍然使用BeautifulSoup来提取数据
*知识点:find()与find_all(),以及Tag对象(标签对象)
find()与find_all()是BeautifulSoup对象的两个方法,它们可以匹配html的标签和属性,把BeautifulSoup对象里符合要求的数据都提取出来。

看下例子:
import requests
from bs4 import BeautifulSoup
url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html'
res = requests.get (url)
print(res.status_code)
soup = BeautifulSoup(res.text,'html.parser')
# 使用find()方法提取首个<div>元素,并放到变量item里。
item = soup.find('div')
# 打印item的数据类型
print(type(item))
# 打印item
print(item)
看,运行结果正是首个div元素吧!我们还打印了它的数据类型:<class 'bs4.element.Tag'>,说明这是一个Tag类标签对象。
再来试试find_all()吧,它可以提取出网页中的全部div元素(3个),然后点击运行。
运行结果是那三个div元素,它们一起组成了一个列表结构。打印items的类型,显示的是<class 'bs4.element.ResultSet'>,是一个ResultSet类的对象。其实是Tag对象以列表结构储存了起来,可以把它当做列表来处理。
情看上述图片:首先,请看举例中括号里的class_,这里有一个下划线,是为了和python语法中的类 class区分,避免程序冲突。当然,除了用class属性去匹配,还可以使用其它属性,比如style属性等。
其次,括号中的参数:标签和属性可以任选其一,也可以两个一起使用,这取决于我们要在网页中提取的内容。
如果只用其中一个参数就可以准确定位的话,就只用一个参数检索。如果需要标签和属性同时满足的情况下才能准确定位到我们想找的内容,那就两个参数一起使用。
看下上述网址的源代码:
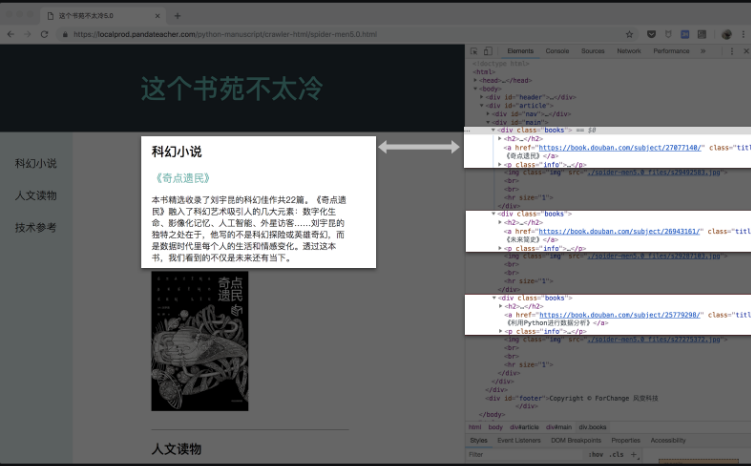
我们用属性class="books"搜索看看,果然,整个HTML源代码中,只有我们要找的三个元素的属性满足,因此,我们这次就可以只使用这个属性来提取。
代码如下:
# 调用requests库
import requests
# 调用BeautifulSoup库
from bs4 import BeautifulSoup
# 返回一个Response对象,赋值给res
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 把Response对象的内容以字符串的形式返回
html = res.text
# 把网页解析为BeautifulSoup对象
soup = BeautifulSoup( html,'html.parser')
# 通过匹配标签和属性提取我们想要的数据
items = soup.find_all(class_='books')
# 打印items
print(items)
# 打印items的数据类型
print(type(items))
不过,列表并不是我们最终想要的东西,我们想要的是列表中的值,所以要想办法提取出列表中的每一个值。接下来我们将用到Tag对象
这个时候,我们一般会选择用type()函数查看一下数据类型,因为Python是一门面向对象编程的语言,只有知道是什么对象,才能调用相关的对象属性和方法。
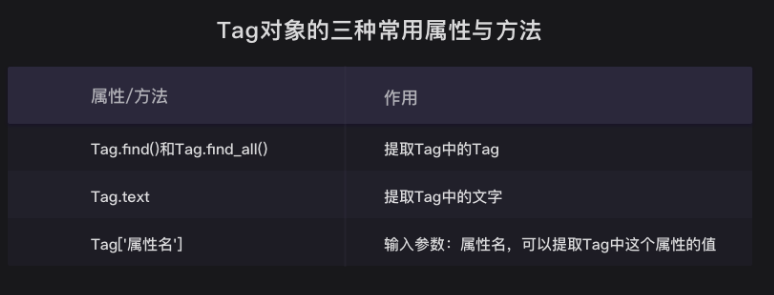
接下来要做的,就是把Tag对象中的文本内容提出来。
可以用到Tag对象的另外两种属性——Tag.text(获得标签中的值),和Tag['属性名'](获得属性值)。
代码如下:
# 调用requests库
import requests
# 调用BeautifulSoup库
from bs4 import BeautifulSoup
# 返回一个response对象,赋值给res
res =requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 把res解析为字符串
html=res.text
# 把网页解析为BeautifulSoup对象
soup = BeautifulSoup( html,'html.parser')
# 通过匹配属性class='books'提取出我们想要的元素
items = soup.find_all(class_='books')
# 遍历列表items
for item in items:
# 在列表中的每个元素里,匹配标签<h2>提取出数据
kind = item.find('h2')
# 在列表中的每个元素里,匹配属性class_='title'提取出数据
title = item.find(class_='title')
# 在列表中的每个元素里,匹配属性class_='info'提取出数据
brief = item.find(class_='info')
# 打印书籍的类型、名字、链接和简介的文字
print(kind.text,'n',title.text,'n',title['href'],'n',brief.text)
总结: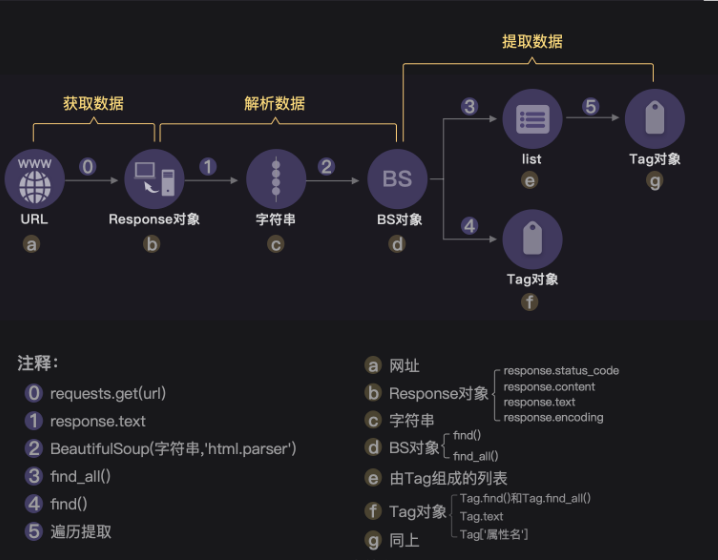
最后
以上就是成就钥匙最近收集整理的关于BeautifulSoup初级实践提取数据的全部内容,更多相关BeautifulSoup初级实践提取数据内容请搜索靠谱客的其他文章。








发表评论 取消回复