文章目录
- 一、NumPy
- 1.1 创建数组
- 1.2 结构数组
- 1.3 连续数组
- 1.4 算数运算
- 1.5 统计函数
- 1.6 排序
- 1.7 实战
- 1.8 FAQ
- 1.8.1 axis
- 1.8.2 数据类型
- 1.8.3 Pycharm 引入 NumPy 等库
- 二、Pandas
- 2.1 Series
- 2.2 DataFrame
- 2.3 数据导入和输出
- 2.3.1 读写 xlsx
- 2.3.2 数据清洗
- 2.3.3 apply 函数
- 2.4 数据统计
- 2.5 数据表合并
- 2.5.1 基于指定列连接
- 2.5.2 inner 内连接
- 2.5.3 left 左连接
- 2.5.4 right 右连接
- 2.5.4 outer 外连接
- 2.6 用 SQL 操作 pandas
- 2.7 实战
- 三、爬虫采集
- 3.1 数据源与工具
- 3.1.1 数据源
- 3.1.2 简易爬虫工具
- 3.1.3 日志与埋点
- 3.2 Request 和 XPath
- 3.3 ChromeDriver
- 3.3.1 selenium API
- 3.3.2 爬虫登录
- 3.3.3 爬电影海报
- 3.3.4 关注、评论、自动发微博
- 四、ETL
- 五、数据变换
- 5.1 用 SciKit-Learn 实现规范化
- 5.1.1 MinMax 规范化
- 5.1.2 Z-Score 规范化
- 5.1.3 小数定标规范化
- 六、可视化
- 6.1 工具与组件库
- 6.2 维度与效果
- 6.2.1 散点图
- 6.2.2 折线图
- 6.2.3 直方图
- 6.2.4 条形图
- 6.2.5 箱线图
- 6.2.6 饼图
- 6.2.7 热力图
- 6.2.8 蜘蛛图
- 6.2.9 二元变量分布
- 6.2.10 成对关系
- 6.3 词云展示
NumPy、SciPy、Pandas 等是数据科学的基础库,可以高效、高级的处理数据。
一、NumPy
NumPy 所提供的数据结构是 Python 数据分析的基础。
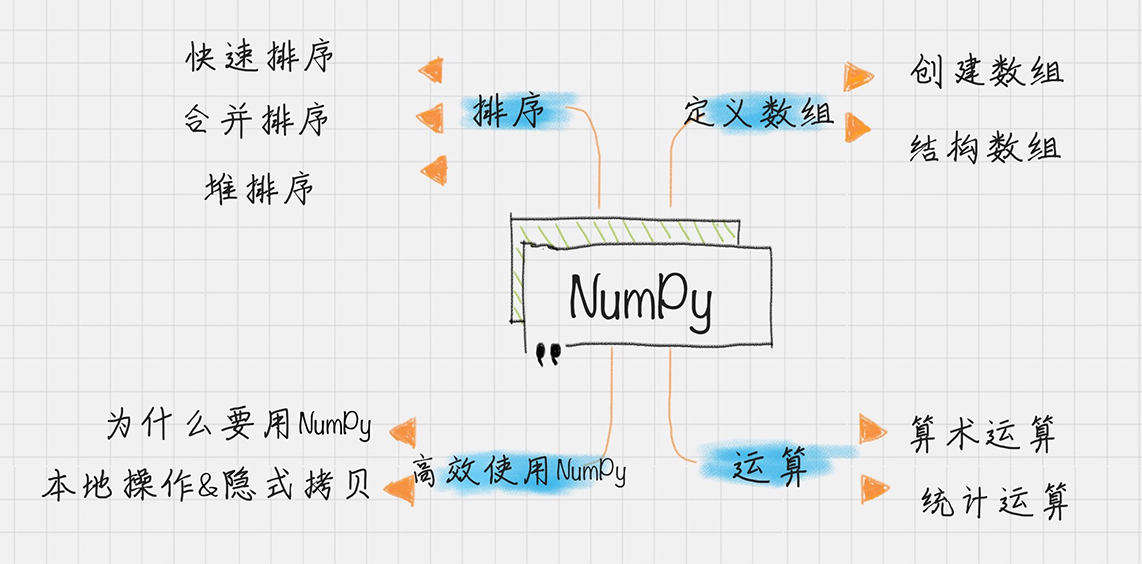
ndarray 是核心数据结构,其表示多维数组。在 NumPy 数组中,维数称为秩(rank),一维数组的秩为 1,二维数组的秩为 2,以此类推。在 NumPy 中,每一个线性的数组称为一个轴(axis),其实秩就是描述轴的数量。
1.1 创建数组
import numpy as np
a = np.array([1, 2, 3])
b = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b[1,1]=10
print a.shape
print b.shape
print a.dtype
print b
# 运行结果:
(3L,)
(3L, 3L)
int32
[[ 1 2 3]
[ 4 10 6]
[ 7 8 9]]
1.2 结构数组
如果你想统计一个班级里面学生的姓名、年龄,以及语文、英语、数学成绩该怎么办?当然你可以用数组的下标来代表不同的字段,比如下标为 0 的是姓名、下标为 1 的是年龄等,但是这样不显性。
实际上在 C 语言里,可以定义结构数组,也就是通过 struct 定义结构类型,结构中的字段占据连续的内存空间,每个结构体占用的内存大小都相同。
import numpy as np
persontype = np.dtype({
'names': ['name', 'age', 'chinese', 'math', 'english'],
'formats': ['S32', 'i', 'i', 'i', 'f']})
peoples = np.array([("ZhangFei", 32, 75, 100, 90), ("GuanYu", 24, 85, 96, 88.5),
("ZhaoYun", 28, 85, 92, 96.5), ("HuangZhong", 29, 65, 85, 100)],
dtype=persontype)
ages = peoples[:]['age']
chineses = peoples[:]['chinese']
maths = peoples[:]['math']
englishs = peoples[:]['english']
print(np.mean(ages))
print(np.mean(chineses))
print(np.mean(maths))
print(np.mean(englishs))
1.3 连续数组
np.arange 和 np.linspace 起到的作用是一样的,都是创建等差数组。这两个数组的结果 x1,x2 都是 [1 3 5 7 9]。结果相同,但是你能看出来创建的方式是不同的。
arange() 类似内置函数 range(),通过指定初始值、终值、步长来创建等差数列的一维数组,默认是不包括终值的。
linspace 是 linear space 的缩写,代表线性等分向量的含义。linspace() 通过指定初始值、终值、元素个数来创建等差数列的一维数组,默认是包括终值的。
x1 = np.arange(1,11,2)
x2 = np.linspace(1,9,5)
1.4 算数运算
通过 NumPy 可以自由地创建等差数组,同时也可以进行加、减、乘、除、求 n 次方和取余数。
x1 = np.arange(1, 11, 2)
x2 = np.linspace(1, 9, 5)
print(np.add(x1, x2))
print(np.subtract(x1, x2))
print(np.divide(x1, x2))
print(np.power(x1, x2))
print(np.remainder(x1, x2))
1.5 统计函数
如果想要对一堆数据有更清晰的认识,就需要对这些数据进行描述性的统计分析,比如了解这些数据中的最大值、最小值、平均值,是否符合正态分布,方差、标准差多少等等。
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(np.amin(a))
print(np.amin(a, 0))
print(np.amin(a, 1))
print(np.amin(a, 2))
# peak to peak: 最大值与最小值之差
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(np.ptp(a))
print(np.ptp(a, 0))
print(np.ptp(a, 1))
# 分位数:
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(np.percentile(a, 50))
print(np.percentile(a, 50, axis=0))
print(np.percentile(a, 50, axis=1))
# 加权平均
a = np.array([1, 2, 3, 4])
wts = np.array([1, 2, 3, 4])
print(np.average(a))
print(np.average(a, weights=wts))
# 标准差方差
a = np.array([1, 2, 3, 4])
print(np.std(a))
print(np.var(a))
1.6 排序
a = np.array([[4, 3, 2], [2, 4, 1]])
print(np.sort(a))
print(np.sort(a, axis=None))
print(np.sort(a, axis=0))
print(np.sort(a, axis=1))
1.7 实战
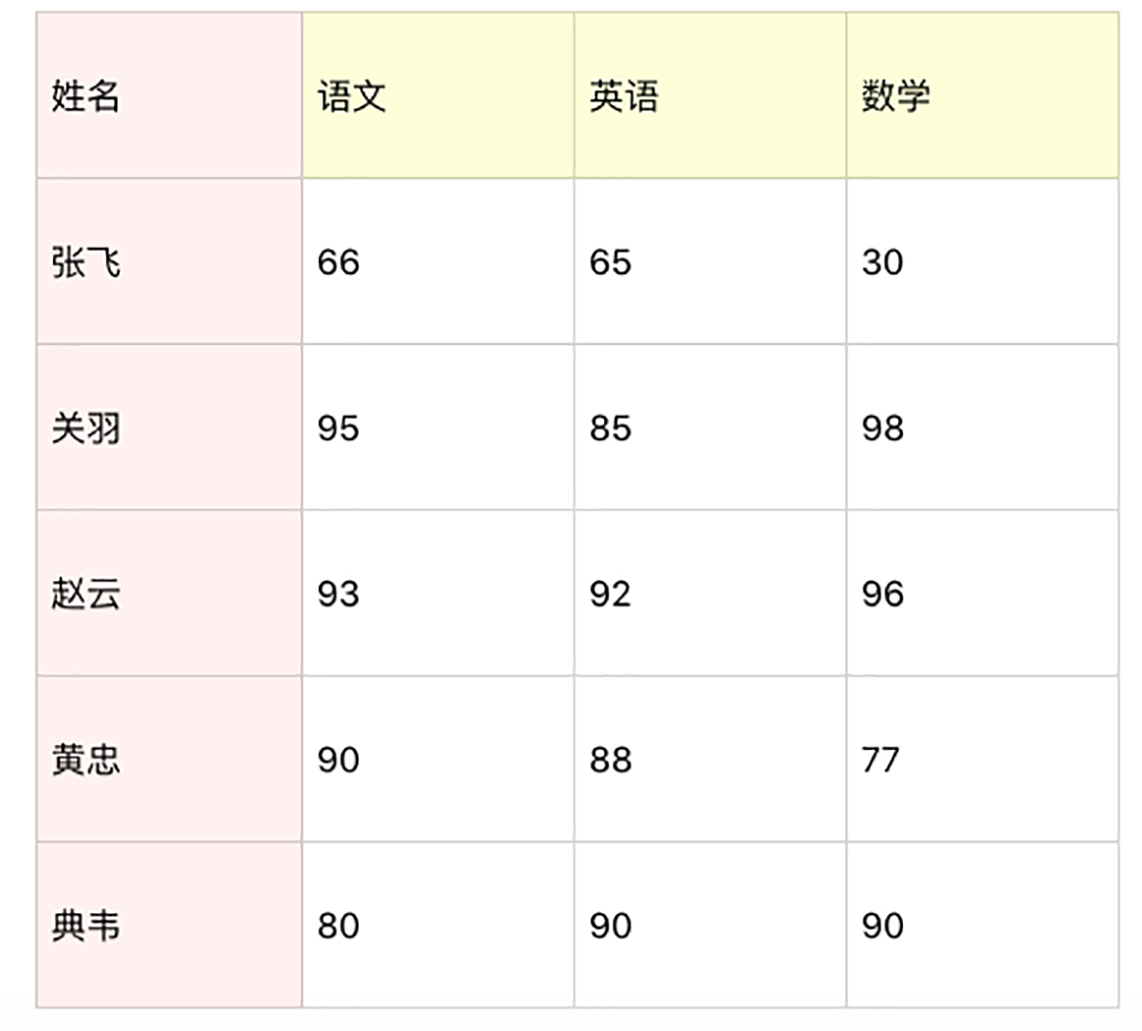
假设一个团队里有 5 名学员,成绩如下表所示。你可以用 NumPy 统计下这些人在语文、英语、数学中的平均成绩、最小成绩、最大成绩、方差、标准差。然后把这些人的总成绩排序,得出名次进行成绩输出。
if __name__ == '__main__':
persontype = np.dtype({
'names': ['name', 'chinese', 'english', 'math', 'total'],
'formats': ['S32', 'i', 'i', 'i', 'i']
})
peoples = np.array(
[
("zhangfei", 66, 65, 30, 0),
("guanyu", 95, 85, 98, 0),
("zhaoyun", 93, 92, 96, 0),
("huangzhong", 90, 88, 77, 0),
("dianwei", 80, 90, 90, 0),
],
dtype=persontype
)
chinese = peoples[:]['chinese']
english = peoples[:]['english']
math = peoples[:]['math']
print("平均成绩如下:")
print("语文", np.mean(chinese))
print("英语", np.mean(english))
print("数学", np.mean(math))
print("最小成绩如下:")
print("语文", np.min(chinese))
print("英语", np.min(english))
print("数学", np.min(math))
print("最大成绩如下:")
print("语文", np.max(chinese))
print("英语", np.max(english))
print("数学", np.max(math))
print("方差如下:")
print("语文", np.var(chinese))
print("英语", np.var(english))
print("数学", np.var(math))
print("标准差如下:")
print("语文", np.std(chinese))
print("英语", np.std(english))
print("数学", np.std(math))
# 输出如下:
平均成绩如下:
语文 84.8
英语 84.0
数学 78.2
最小成绩如下:
语文 66
英语 65
数学 30
最大成绩如下:
语文 95
英语 92
数学 98
方差如下:
语文 114.96000000000001
英语 95.6
数学 634.56
标准差如下:
语文 10.721940122944169
英语 9.777525249264253
数学 25.19047439013406
1.8 FAQ
1.8.1 axis
axis=0 代表跨行(实际上就是按列),axis=1 代表跨列(实际上就是按行)。
如果排序的时候,没有指定 axis,默认 axis=-1,代表就是按照数组最后一个轴来排序。如果 axis=None,代表以扁平化的方式作为一个向量进行排序。
可通过下文排序的 demo 验证:
a = np.array([[4,3,2],[2,4,1]])
print np.sort(a)
[[2 3 4]
[1 2 4]]
print np.sort(a, axis=None)
[1 2 2 3 4 4]
print np.sort(a, axis=0) # axis=0 代表的是跨行(跨行就是按照列),所以实际上是对 [4, 2] [3, 4] [2, 1] 来进行排序,排序结果是 [2, 4] [3, 4] [1, 2],对应的是每一列的排序结果。还原到矩阵中也就是 [[2 3 1], [4, 4, 2]]。
[[2 3 1]
[4 4 2]]
print np.sort(a, axis=1)
[[2 3 4]
[1 2 4]]
1.8.2 数据类型
numpy 中的字符编码来表示数据类型的定义:比如 i 代表整数,f 代表单精度浮点数,S 代表字符串,S32 代表的是 32 个字符的字符串。

如果数据中使用了中文,可以把类型设置为 U32,比如:
import numpy as np
persontype = np.dtype({
'names':['name', 'age', 'chinese', 'math', 'english'],
'formats':['U32','i', 'i', 'i', 'f']})
peoples = np.array([(" 张飞 ",32,75,100, 90),(" 关羽 ",24,85,96,88.5), (" 赵云 ",28,85,92,96.5),(" 黄忠 ",29,65,85,100)], dtype=persontype)
1.8.3 Pycharm 引入 NumPy 等库
二、Pandas
和 NumPy 一样,Pandas 有两个非常重要的数据结构:Series 和 DataFrame。使用 Pandas 可以直接从 csv 或 xlsx 等文件中导入数据,以及最终输出到 excel 表中。包括数据清洗和统计函数,也可以用 SQL 操作。

2.1 Series
x1 = Series([1, 2, 3, 4])
x2 = Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
print(x1)
print(x2)
# 输出如下:
0 1
1 2
2 3
3 4
dtype: int64
a 1
b 2
c 3
d 4
dtype: int64
d = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
x3 = Series(d)
print(x3)
2.2 DataFrame
DataFrame 类型,类似「数据库表」,其包括行索引和列索引,可以将 DataFrame 看成「由相同索引的 Series 构成」的「字典类型」。
我们虚构一个王者荣耀考试的场景,希望输出个英雄的考试成绩。以 df2 为例,其列索引是 [‘English’, ‘Math’, ‘Chinese’],行索引是 [‘ZhangFei’, ‘GuanYu’, ‘ZhaoYun’, ‘HuangZhong’, ‘DianWei’],所以其输出效果如下:
if __name__ == '__main__':
data = {'Chinese': [66, 95, 93, 90, 80], 'English': [65, 85, 92, 88, 90], 'Math': [30, 98, 96, 77, 90]}
df1 = DataFrame(data)
df2 = DataFrame(data,
index=['ZhangFei', 'GuanYu', 'ZhaoYun', 'HuangZhong', 'DianWei'],
columns=['English', 'Math', 'Chinese'])
print(df1)
print(df2)
# 输出结果如下:
Chinese English Math
0 66 65 30
1 95 85 98
2 93 92 96
3 90 88 77
4 80 90 90
English Math Chinese
ZhangFei 65 30 66
GuanYu 85 98 95
ZhaoYun 92 96 93
HuangZhong 88 77 90
DianWei 90 90 80
2.3 数据导入和输出
在了解了 Series 和 DataFrame 这两个数据结构后,我们就从数据处理的流程角度,来看下他们的使用方法。
2.3.1 读写 xlsx
Pandas 允许直接从 xlsx、csv 中导入数据,也可以输出到 xlsx、csv 中,非常方便。
准备一个测试 xlsx 文件如下:
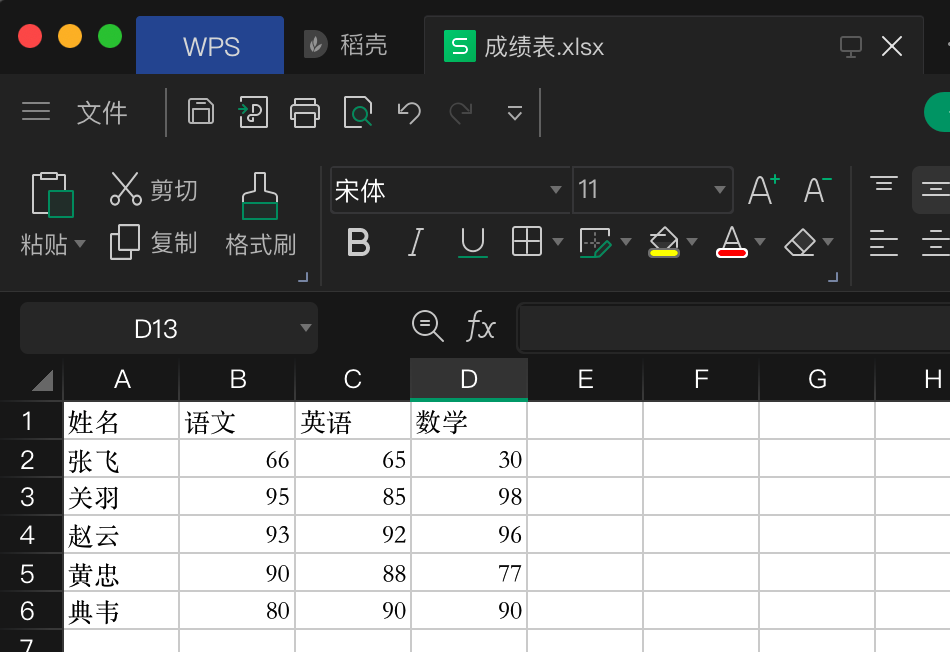
通过 read_excel() 读取,并操作,再通过 to_excel() 写入,代码如下:
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
score.to_excel('输出.xlsx')
print(score)
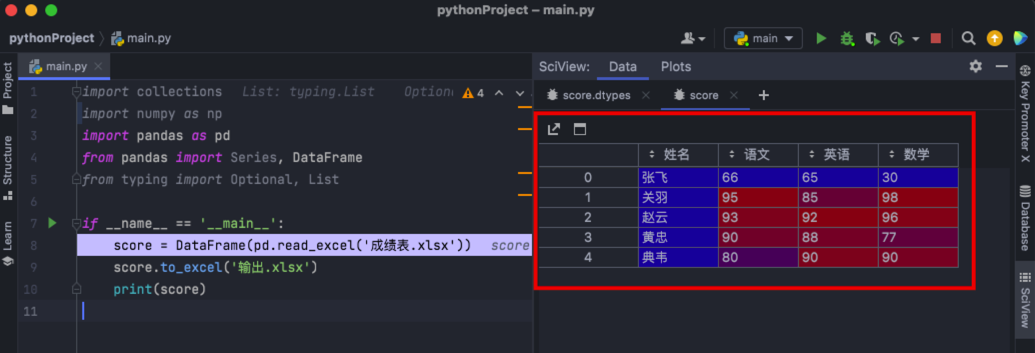
通过 Pycharm 的断点,可以方便的看到 DataFrame 的内容,如下图:
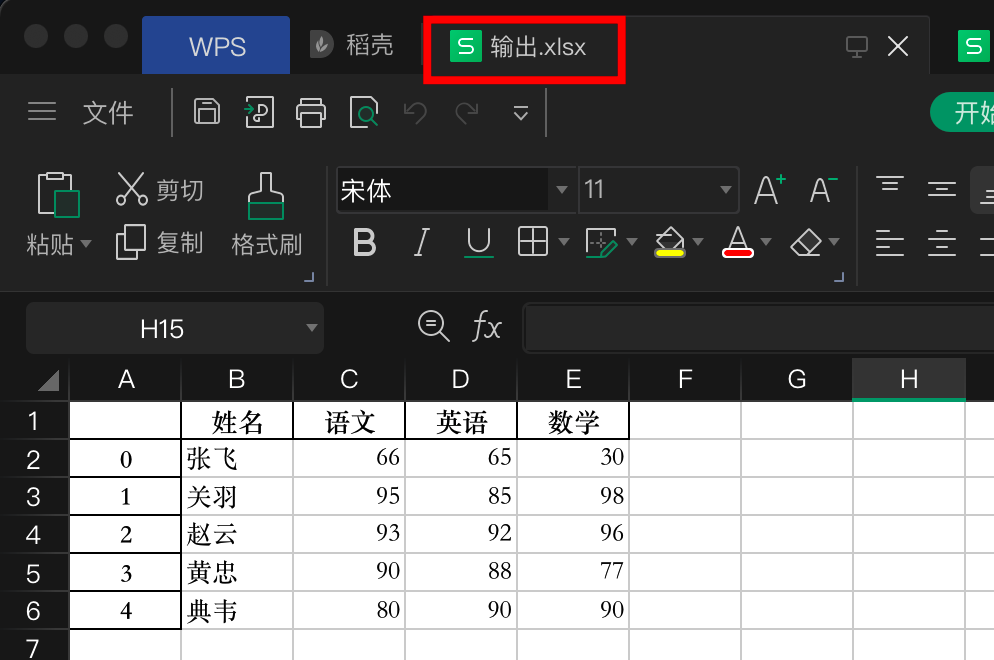
最终,写入新的 excel 如下图:
2.3.2 数据清洗
Pandas 也为我们提供了数据清洗的工具,有如下几种情况:
- 删除 DataFrame 中不必要的行或列:
drop() 函数
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
score = score.drop(columns=['语文']) # 删除语文列
score = score.drop(index=[0]) # 删除张飞行(index=0即第一行)
score.to_excel('输出.xlsx')
print(score)
# 输出结果如下:
姓名 英语 数学
1 关羽 85 98
2 赵云 92 96
3 黄忠 88 77
4 典韦 90 90
- 重命名列名 columns,让列表名更容易识别
rename(columns=new_names, inplace=True):
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
score.rename(columns={'语文': 'Chinese', '英语': 'English'}, inplace=True)
score.to_excel('输出.xlsx')
print(score)
# 输出结果如下:
姓名 Chinese English 数学
0 张飞 66 65 30
1 关羽 95 85 98
2 赵云 93 92 96
3 黄忠 90 88 77
4 典韦 80 90 90
-
去重复的行
drop_duplicates(): -
改数据格式:如果数据合适不规范,可以统一改为某格式
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
score['语文'].astype('str')
score['语文'].astype(np.int64)
print(score)
- 数据间的空格:
有时候我们先把格式转成了 str 类型,是为了方便对数据进行操作,这时想要删除数据间的空格,我们就可以使用 strip 函数:
# 删除左右两边空格
df2['Chinese']=df2['Chinese'].map(str.strip)
# 删除左边空格
df2['Chinese']=df2['Chinese'].map(str.lstrip)
# 删除右边空格
df2['Chinese']=df2['Chinese'].map(str.rstrip)
如果数据里有某个特殊的符号,我们想要删除怎么办?同样可以使用 strip 函数,比如 Chinese 字段里有美元符号,我们想把这个删掉,可以这么写:
df2['Chinese']=df2['Chinese'].str.strip('$')
- 大小写转换
大小写是个比较常见的操作,比如人名、城市名等的统一都可能用到大小写的转换,在 Python 里直接使用 upper(), lower(), title() 函数,方法如下:
# 全部大写
df2.columns = df2.columns.str.upper()
# 全部小写
df2.columns = df2.columns.str.lower()
# 首字母大写
df2.columns = df2.columns.str.title()
- 查找空值
数据量大的情况下,有些字段存在空值 NaN 的可能,这时就需要使用 Pandas 中的 isnull 函数进行查找。比如,我们输入一个数据表如下:
如果我们想看下哪个地方存在空值 NaN,可以针对数据表 df 进行 df.isnull(),结果如下:
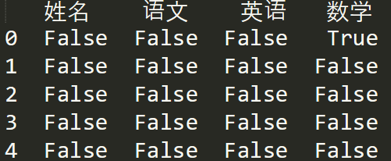
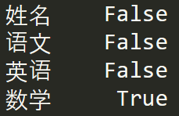
如果我想知道哪列存在空值,可以使用 df.isnull().any(),结果如下:
2.3.3 apply 函数
apply 函数是 Pandas 中自由度非常高的函数,使用频率也非常高。
比如我们想对 name 列的数值都进行大写转化可以用:
df['name'] = df['name'].apply(str.upper)
可以自定义函数,使各项数值 * 2,代码如下:
def double_df(x):
return 2 * x
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
score['语文'] = score['语文'].apply(double_df)
print(score)
# 输出结果如下:
姓名 语文 英语 数学
0 张飞 132 65 30
1 关羽 190 85 98
2 赵云 186 92 96
3 黄忠 180 88 77
4 典韦 160 90 90
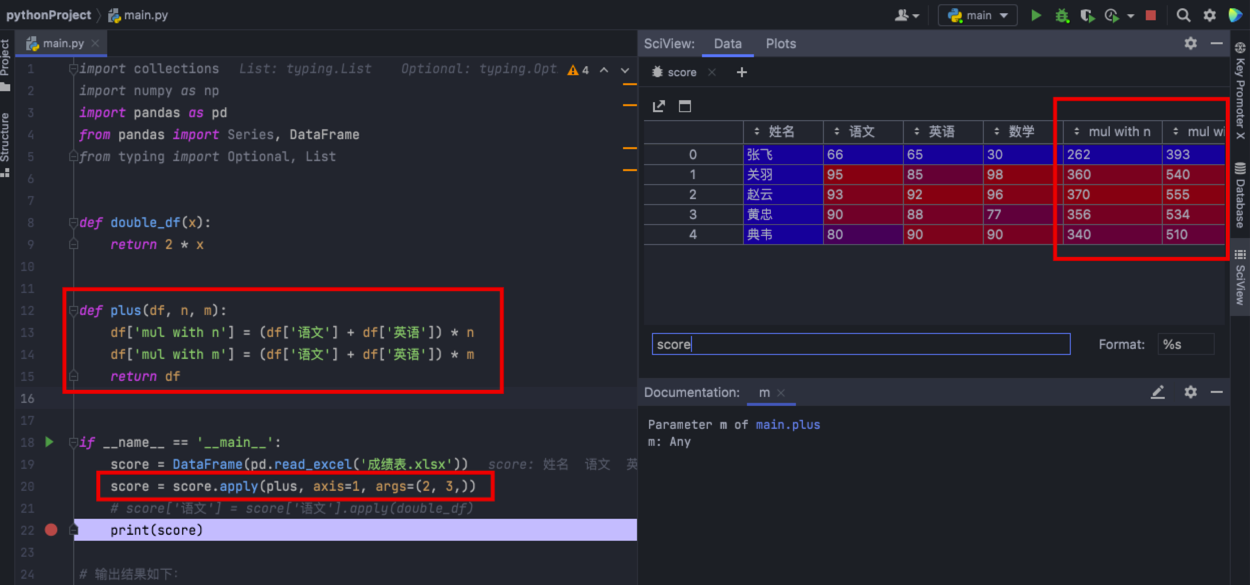
可以自定义更复杂的函数,例如新增两列,其中’new1’列是“语文”和“英语”成绩之和的 m 倍,'new2’列是“语文”和“英语”成绩之和的 n 倍,我们可以这样写:
def plus(df, n, m):
df['mul with n'] = (df['语文'] + df['英语']) * n
df['mul with m'] = (df['语文'] + df['英语']) * m
return df
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
score = score.apply(plus, args=(2, 3,))
print(score)
其中 axis=1 代表按照列为轴进行操作,axis=0 代表按照行为轴进行操作,args 是传递的两个参数,即 n=2, m=3,在 plus 函数中使用到了 n 和 m,从而生成新的 df。运行效果如下:
2.4 数据统计
在数据清洗后,我们就要对数据进行统计了。
Pandas 和 NumPy 一样,都有常用的统计函数,如果遇到空值 NaN,会自动排除。
常用的统计函数包括:

代码如下:
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
print("score原始数据如下:n", score)
print("ncount(axis0)如下:n", score.count(axis=0))
print("ncount(axis1)如下:n", score.count(axis=1))
print("ndescribe如下:n", score.describe())
print("nmin如下:n", score.min())
print("nmax如下:n", score.max())
print("nsum如下:n", score.sum())
print("nmean如下:n", score.mean())
# 输出结果如下:
姓名 语文 英语 数学
0 张飞 66 65 30
1 关羽 95 85 98
2 赵云 93 92 96
3 黄忠 90 88 77
4 典韦 80 90 90
count(axis0)如下:
姓名 5
语文 5
英语 5
数学 5
dtype: int64
count(axis1)如下:
0 4
1 4
2 4
3 4
4 4
dtype: int64
describe如下:
语文 英语 数学
count 5.000000 5.000000 5.000000
mean 84.800000 84.000000 78.200000
std 11.987493 10.931606 28.163807
min 66.000000 65.000000 30.000000
25% 80.000000 85.000000 77.000000
50% 90.000000 88.000000 90.000000
75% 93.000000 90.000000 96.000000
max 95.000000 92.000000 98.000000
min如下:
姓名 关羽
语文 66
英语 65
数学 30
dtype: object
max如下:
姓名 黄忠
语文 95
英语 92
数学 98
dtype: object
sum如下:
姓名 张飞关羽赵云黄忠典韦
语文 424
英语 420
数学 391
dtype: object
mean如下:
语文 84.8
英语 84.0
数学 78.2
dtype: float64
另一个例子如下:
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
print df1.describe()
# 输出结果如下:s
data1
count 5.000000
mean 2.000000
std 1.581139
min 0.000000
25% 1.000000
50% 2.000000
75% 3.000000
max 4.000000
2.5 数据表合并
有时候我们需要将多个渠道源的多个数据表进行合并,一个 DataFrame 相当于一个数据库的数据表,那么多个 DataFrame 数据表的合并就相当于多个数据库的表合并。
比如我要创建两个 DataFrame:
df1 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1': range(5)})
df2 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2': range(5)})
两个 DataFrame 数据表的合并使用的是 merge() 函数,有下面 5 种形式:
2.5.1 基于指定列连接
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
df1 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1': range(5)})
df2 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2': range(5)})
df3 = pd.merge(df1, df2, on='name')
print("ndf1:n", df1)
print("ndf2:n", df2)
print("ndf3:n", df3)
# 输出结果如下:
df1:
name data1
0 ZhangFei 0
1 GuanYu 1
2 a 2
3 b 3
4 c 4
df2:
name data2
0 ZhangFei 0
1 GuanYu 1
2 A 2
3 B 3
4 C 4
df3:
name data1 data2
0 ZhangFei 0 0
1 GuanYu 1 1
2.5.2 inner 内连接
inner 内链接是 merge 合并的默认情况,inner 内连接其实也就是键的交集,在这里 df1, df2 相同的键是 name,所以是基于 name 字段做的连接:
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
df1 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1': range(5)})
df2 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2': range(5)})
# df3 = pd.merge(df1, df2, on='name')
df3 = pd.merge(df1, df2, how='inner')
# print("ndf1:n", df1)
# print("ndf2:n", df2)
print("ndf3:n", df3)
# 输出结果如下:
df3:
name data1 data2
0 ZhangFei 0 0
1 GuanYu 1 1
2.5.3 left 左连接
左连接是以第一个 DataFrame 为主进行的连接,第二个 DataFrame 作为补充。
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
df1 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1': range(5)})
df2 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2': range(5)})
# df3 = pd.merge(df1, df2, on='name')
df3 = pd.merge(df1, df2, how='left')
print("ndf1:n", df1)
print("ndf2:n", df2)
print("ndf3:n", df3)
# 输出结果如下:
df3:
name data1 data2
0 ZhangFei 0 0.0
1 GuanYu 1 1.0
2 a 2 NaN
3 b 3 NaN
4 c 4 NaN
2.5.4 right 右连接
右连接是以第二个 DataFrame 为主进行的连接,第一个 DataFrame 作为补充。
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
df1 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1': range(5)})
df2 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2': range(5)})
# df3 = pd.merge(df1, df2, on='name')
df3 = pd.merge(df1, df2, how='right')
# print("ndf1:n", df1)
# print("ndf2:n", df2)
print("ndf3:n", df3)
# 输出结果如下:
df3:
name data1 data2
0 ZhangFei 0.0 0
1 GuanYu 1.0 1
2 A NaN 2
3 B NaN 3
4 C NaN 4
2.5.4 outer 外连接
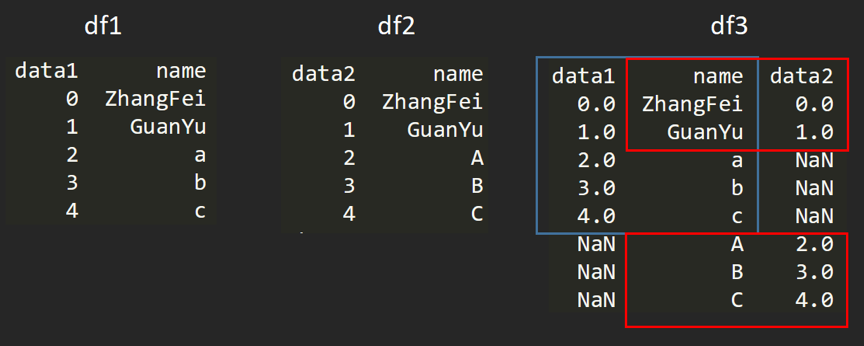
外连接相当于求两个 DataFrame 的并集。
if __name__ == '__main__':
score = DataFrame(pd.read_excel('成绩表.xlsx'))
df1 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1': range(5)})
df2 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2': range(5)})
# df3 = pd.merge(df1, df2, on='name')
df3 = pd.merge(df1, df2, how='outer')
# print("ndf1:n", df1)
# print("ndf2:n", df2)
print("ndf3:n", df3)
# 输出结果如下:
df3:
name data1 data2
0 ZhangFei 0.0 0.0
1 GuanYu 1.0 1.0
2 a 2.0 NaN
3 b 3.0 NaN
4 c 4.0 NaN
5 A NaN 2.0
6 B NaN 3.0
7 C NaN 4.0
外连接的图示如下:
2.6 用 SQL 操作 pandas
Pandas 的 DataFrame 数据类型可以让我们像处理数据表一样进行操作,比如数据表的增删改查,都可以用 Pandas 工具来完成。不过也会有很多人记不住这些 Pandas 的命令,相比之下还是用 SQL 语句更熟练,用 SQL 对数据表进行操作是最方便的,它的语句描述形式更接近我们的自然语言。
事实上,在 Python 里可以直接使用 SQL 语句来操作 Pandas。
这里给你介绍个工具:pandasql。
pandasql 中的主要函数是 sqldf,它接收两个参数:一个 SQL 查询语句,还有一组环境变量 globals() 或 locals()。这样我们就可以在 Python 里,直接用 SQL 语句中对 DataFrame 进行操作,举个例子:
from pandas import DataFrame
from pandasql import sqldf, load_meat, load_births
if __name__ == '__main__':
df1 = DataFrame({'name': ['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1': range(5)})
pysqldf = lambda sql: sqldf(sql, globals())
sql = "select * from df1 where name ='ZhangFei'"
print(pysqldf(sql))
# 输出结果如下:
name data1
0 ZhangFei 0
上例对“name='ZhangFei”“的行进行了输出。其中的 lambda 在 python 中算是使用频率很高的,那 lambda 实际上是用来定义一个匿名函数的,具体的使用形式为: lambda argument_list: expression,其中 argument_list 是参数列表,expression 是关于参数的表达式,会根据 expression 表达式计算结果进行输出返回。
在这个例子里,输入的参数是 sql,返回的结果是 sqldf 对 sql 的运行结果,当然 sqldf 中也输入了 globals 全局参数,因为在 sql 中有对全局参数 df1 的使用。
2.7 实战
对于下表的数据,请使用 Pandas 中的 DataFrame 进行创建,并对数据进行清洗。同时新增一列“总和”计算每个人的三科成绩之和。
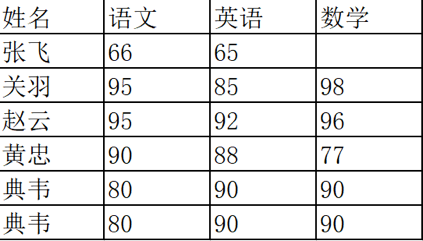
if __name__ == '__main__':
score = pandas.read_excel('成绩表pandas.xlsx')
print('n原始数据n', score)
score = score.drop_duplicates()
print('n去重重复行n', score)
# score = score.fillna(0)
# print('n处理na为0n', score)
score = score.fillna(score.mean()) # 参考 https://zhuanlan.zhihu.com/p/544195498
print('n处理na为该列均值n', score)
score = score.apply(total, axis=1) # axis=1表示逐行apply
print('n添加总和的列n', score)
# 输出结果如下:
原始数据
姓名 语文 英语 数学
0 张飞 66 65 NaN
1 关羽 95 85 98.0
2 赵云 93 92 96.0
3 黄忠 90 88 77.0
4 典韦 80 90 90.0
5 典韦 80 90 90.0
去重重复行
姓名 语文 英语 数学
0 张飞 66 65 NaN
1 关羽 95 85 98.0
2 赵云 93 92 96.0
3 黄忠 90 88 77.0
4 典韦 80 90 90.0
处理na为0
姓名 语文 英语 数学
0 张飞 66 65 0.0
1 关羽 95 85 98.0
2 赵云 93 92 96.0
3 黄忠 90 88 77.0
4 典韦 80 90 90.0
处理na为该列均值
姓名 语文 英语 数学
0 张飞 66 65 90.25
1 关羽 95 85 98.00
2 赵云 93 92 96.00
3 黄忠 90 88 77.00
4 典韦 80 90 90.00
添加总和的列
姓名 语文 英语 数学 总和
0 张飞 66 65 90.25 221.25
1 关羽 95 85 98.00 278.00
2 赵云 93 92 96.00 281.00
3 黄忠 90 88 77.00 255.00
4 典韦 80 90 90.00 260.00
三、爬虫采集

数据源一般分为如下:
- 开放数据源:一般是针对行业的数据库。
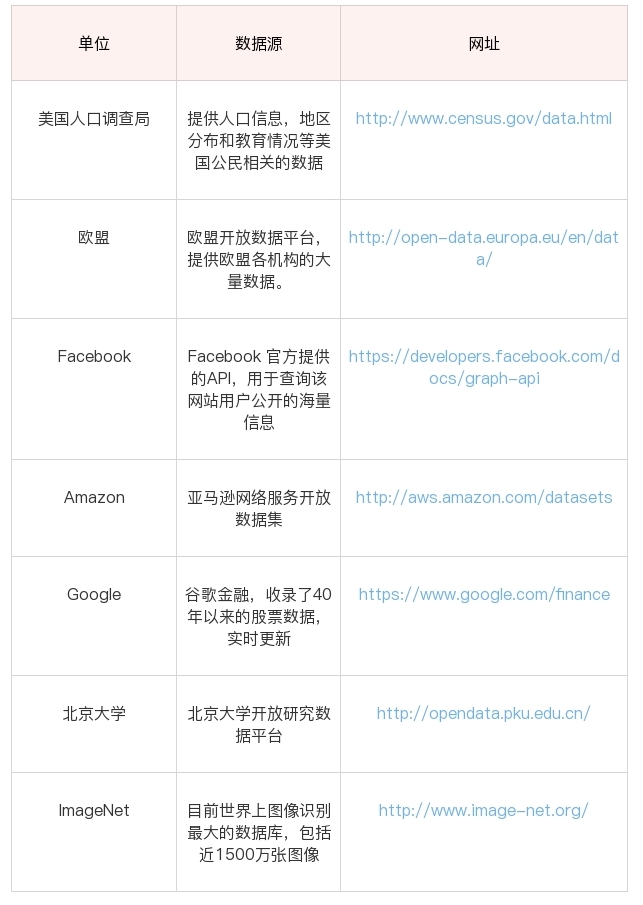
- 比如美国人口调查局开放了美国的人口信息、地区分布和教育情况数据。
- 除了政府外,企业和高校也会开放相应的大数据,这方面北美相对来说做得好一些。
- 国内,贵州做了不少大胆尝试,搭建了云平台,逐年开放了旅游、交通、商务等领域的数据量。
- 爬虫:如果我们想要抓取指定的网站数据,比如购物网站上的购物评价等,就需要我们做特定的爬虫抓取
- 传感器:它基本上采集的是物理信息。比如图像、视频、或者某个物体的速度、热度、压强等。
- 日志采集:这个是统计用户的操作。我们可以在前端进行埋点,在后端进行脚本收集、统计,来分析网站的访问情况,以及使用瓶颈等。
3.1 数据源与工具
3.1.1 数据源
开放数据源可以从两个维度来考虑
- 一个是单位的维度,比如政府、企业、高校
- 一个就是行业维度,比如交通、金融、能源等领域。
这方面,国外的开放数据源比国内做得好一些,当然近些年国内的政府和高校做开放数据源的也越来越多。一方面服务社会,另一方面自己的影响力也会越来越大。
所以如果你想找某个领域的数据源,比如金融领域,你基本上可以看下政府、高校、企业是否有开放的数据源。当然你也可以直接搜索金融开放数据源。
3.1.2 简易爬虫工具
我们可以不编程就抓取到网页信息,主要包括如下工具:
-
火车采集器:已经有 13 年历史了,是老牌的采集工具。它不仅可以做抓取工具,也可以做数据清洗、数据分析、数据挖掘和可视化等工作。数据源适用于绝大部分的网页,网页中能看到的内容都可以通过采集规则进行抓取。
-
八爪鱼与爬虫原理
- 免费的采集模板实际上就是内容采集规则,包括了电商类、生活服务类、社交媒体类和论坛类的网站都可以采集,用起来非常方便。当然你也可以自己来自定义任务。
- 那什么是云采集呢?就是当你配置好采集任务,就可以交给八爪鱼的云端进行采集。八爪鱼一共有 5000 台服务器,通过云端多节点并发采集,采集速度远远超过本地采集。此外还可以自动切换多个 IP,避免 IP 被封,影响采集。
- 做过工程项目的同学应该能体会到,云采集这个功能太方便了,很多时候自动切换 IP 以及云采集才是自动化采集的关键。
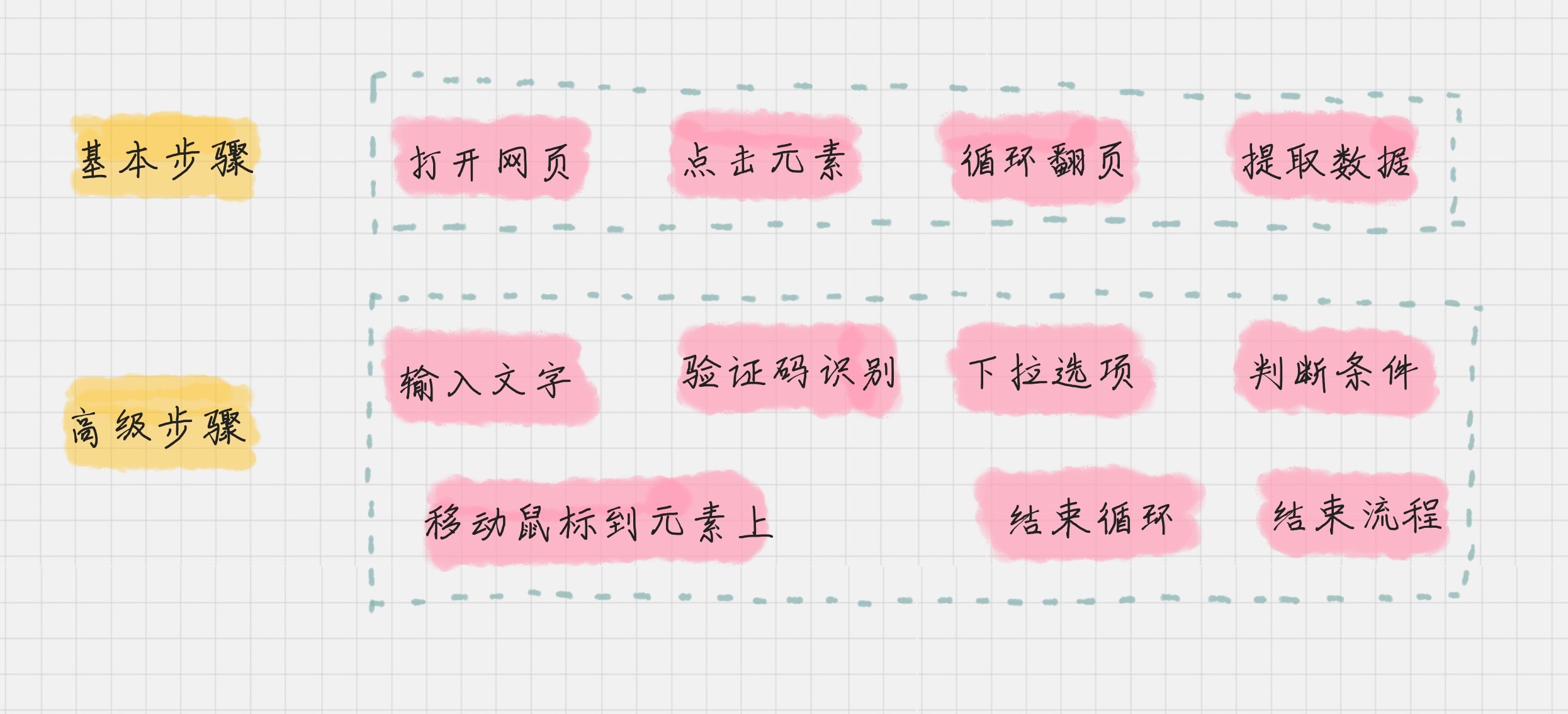
- 八爪鱼的采集共分三步:
- 输入网页:每个采集需要输入你想要采集的网页。在新建任务的时候,这里是必填项。
- 设计流程:这个步骤最为关键,你需要告诉八爪鱼,你是如何操作页面的、想要提取页面上的哪些信息等。因为数据条数比较多,通常你还需要翻页,所以要进行循环翻页的设置。在设计流程中,你可以使用简易采集方式,也就是八爪鱼自带的模板,也可以采用自定义的方式。
- 启动采集:当你设计好采集流程后,就可以启动采集任务了,任务结束后,八爪鱼会提示你保存采集好的数据,通常是 xlsx 或 csv 格式。
-
集搜客 相比于八爪鱼来说,集搜客没有流程的概念,用户只需要关注抓取什么数据,而流程细节完全交给集搜客来处理。没有云采集功能,所有爬虫都是在用户自己电脑上跑的。
-
后羿采集器,支持 mac 端
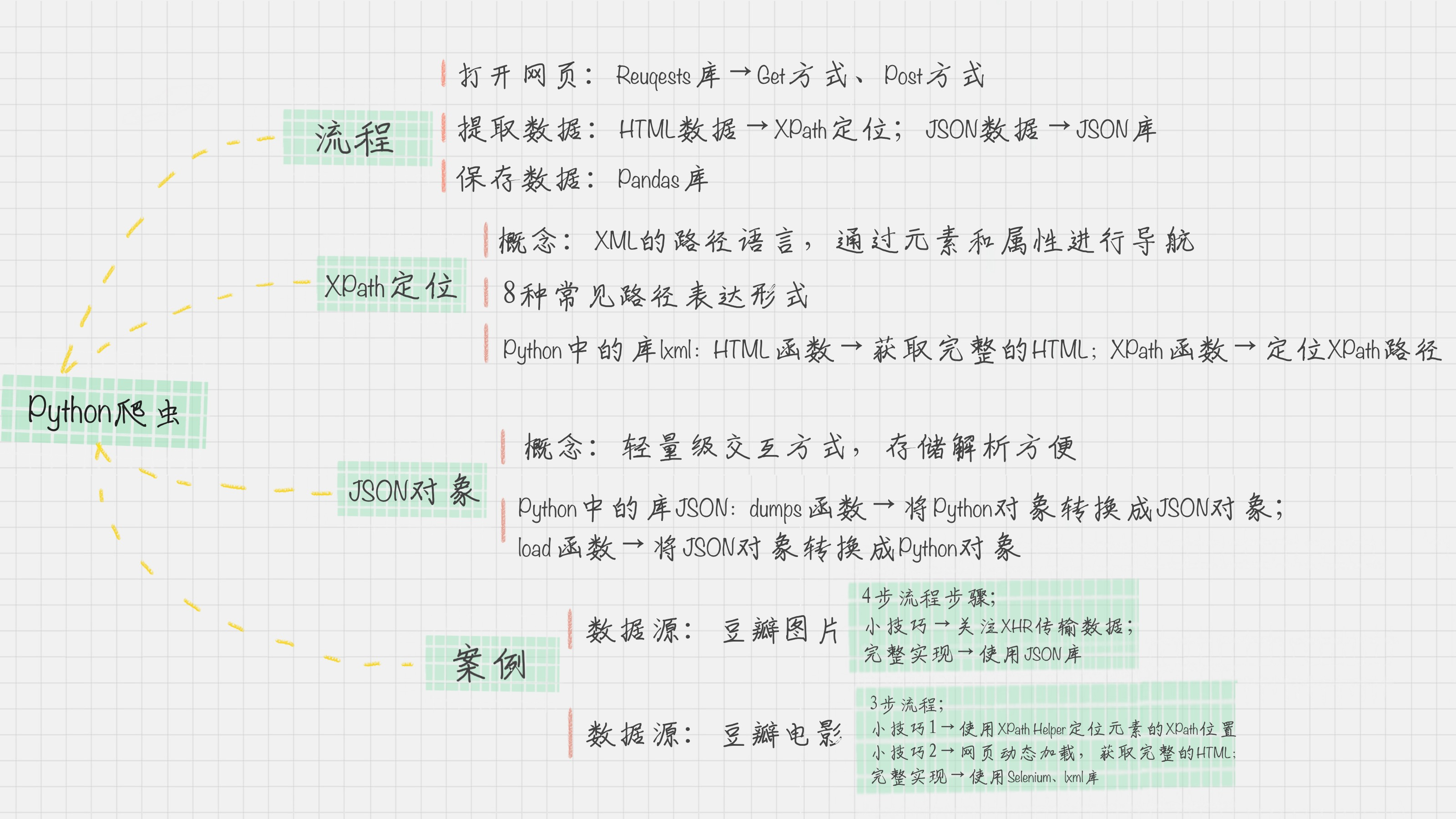
而自定义的爬虫需求则还得用 Python 实现,其整个过程包括打开网页、提取数据和保存数据三个阶段:
- 打开网页:可以使用 Requests 访问页面,得到服务器返回给我们的数据,这里包括 HTML 页面以及 JSON 数据。
- 提取数据:主要用到了两个工具。针对 HTML 页面,可以使用 XPath 进行元素定位,提取数据;针对 JSON 数据,可以使用 JSON 进行解析。
- 保存数据:我们可以使用 Pandas 保存数据,最后导出 CSV 文件。
3.1.3 日志与埋点
分两种形式。
- 通过 Web 服务器采集,例如 httpd、Nginx、Tomcat 都自带日志记录功能。同时很多互联网企业都有自己的海量数据采集工具,多用于系统日志采集,如 Hadoop 的 Chukwa、Cloudera 的 Flume、Facebook 的 Scribe 等,这些工具均采用分布式架构,能够满足每秒数百 MB 的日志数据采集和传输需求。
- 自定义采集用户行为,例如用 JavaScript 代码监听用户的行为、AJAX 异步请求后台记录日志等。
埋点就是在有需要的位置采集相应的信息,进行上报。比如某页面的访问情况,包括用户信息、设备信息;或者用户在页面上的操作行为,包括时间长短等。这就是埋点,每一个埋点就像一台摄像头,采集用户行为数据,将数据进行多维度的交叉分析,可真实还原出用户使用场景,和用户使用需求。
对于埋点这类监测性的工具,市场上已经比较成熟,这里推荐你使用第三方的工具,比如友盟、Google Analysis、Talkingdata 等。他们都是采用前端埋点的方式,然后在第三方工具里就可以看到用户的行为数据。但如果我们想要看到更深层的用户操作行为,就需要进行自定义埋点。
3.2 Request 和 XPath
Requests 是 Python HTTP 的客户端库,它有两种访问方式:Get 和 Post。
r = requests.get('http://www.douban.com') # r就是 Get 请求后的访问结果,可用 r.text 或 r.content 来获取 HTML正文
r = requests.post('http://xxx.com', data = {'key':'value'})
XPath 是 XML 的路径语言,实际上是通过元素和属性进行导航,帮我们定位位置。它有几种常用的路径表达方式。

我们想要定位的节点,几乎都可以使用 XPath 来选择,用法如下:
- xpath(‘node’) 选取了 node 节点的所有子节点;
- xpath(’/div’) 从根节点上选取 div 节点;
- xpath(’//div’) 选取所有的 div 节点;
- xpath(’./div’) 选取当前节点下的 div 节点;
- xpath(’…’) 回到上一个节点;
- xpath(’//@id’) 选取所有的 id 属性;
- xpath(’//book[@id]’) 选取所有拥有名为 id 的属性的 book 元素;
- xpath(’//book[@id=“abc”]’) 选取所有 book 元素,且这些 book 元素拥有 id= "abc"的属性;
- xpath(’//book/title | //book/price’) 选取 book 元素的所有 title 和 price 元素。
Python 的解析库 lxml 可很方便用来解析 XPath:
from lxml import etree
html = etree.HTML(html)
result = html.xpath('//li')
通过 json.dumps() 可把 Python 对象转换为 JSON 对象,通过 json.loads() 可把 JSON 对象转换为 Python 对象。
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
input = json.loads(jsonData)
print input
用 Request 爬虫示例如下:
import requests
import json
query = '王祖贤'
''' 下载图片 '''
def download(src, id):
dir = './' + str(id) + '.jpg'
try:
pic = requests.get(src, timeout=10)
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
except requests.exceptions.ConnectionError:
print('图片无法下载')
''' for 循环 请求全部的 url '''
for i in range(0, 22471, 20):
url = 'https://www.douban.com/j/search_photo?q=' + query + '&limit=20&start=' + str(i)
html = requests.get(url).text # 得到返回结果
response = json.loads(html, encoding='utf-8') # 将 JSON 格式转换成 Python 对象
for image in response['images']:
print(image['src']) # 查看当前下载的图片网址
download(image['src'], image['id']) # 下载一张图片
3.3 ChromeDriver
3.3.1 selenium API
因为动态网页,需要加载并执行 js 后才能看到完整 html,因此可用 selenium 模拟 chrome 的行为,按教程,先在官网下载最新的驱动(例如 chrome 版本是110.0.5481.177,则也下载110.0.5481.xxx版本的),其次放置在本机的 “/Users/abc/Downloads/chromn-download/chromedriver” 中,在代码指定路径或设置环境变量即可使用,示例如下:
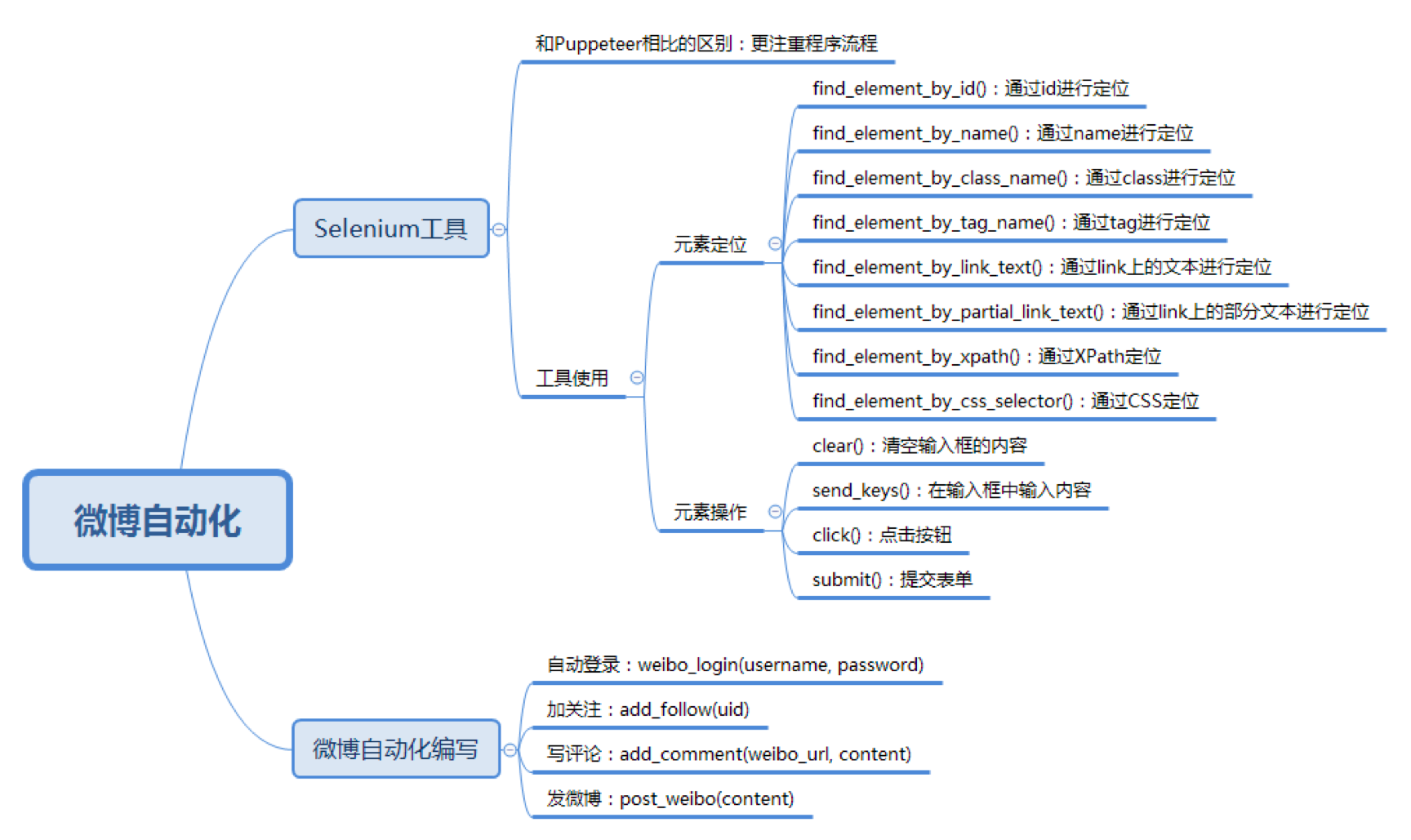
我们可选 Selenium
- Selenium 更关注程序执行的流程本身,比如找到指定的元素,设置相应的值,然后点击操作。
- Puppeteer 是浏览者的视角,比如光标移动到某个元素上,键盘输入某个内容等。
如果我们想定位一个元素,可以通过 id、name、class、tag、链接上的全部文本、链接上的部分文本、XPath 或者 CSS 进行定位,在 Selenium Webdriver 中也提供了这 8 种方法方便我们定位元素。
- 通过 id 定位:我们可以使用 find_element_by_id() 函数。比如我们想定位 id=loginName 的元素,就可以使用 browser.find_element_by_id(“loginName”)。
- 通过 name 定位:我们可以使用 find_element_by_name() 函数,比如我们想要对 name=key_word 的元素进行定位,就可以使用 browser.find_element_by_name(“key_word”)。
- 通过 class 定位:可以使用 find_element_by_class_name() 函数。
- 通过 tag 定位:使用 find_element_by_tag_name() 函数。
- 通过 link 上的完整文本定位:使用 find_element_by_link_text() 函数。
- 通过 link 上的部分文本定位:使用 find_element_by_partial_link_text() 函数。有时候超链接上的文本很长,我们通过查找部分文本内容就可以定位。
- 通过 XPath 定位:使用 find_element_by_xpath() 函数。使用 XPath 定位的通用性比较好,因为当 id、name、class 为多个,或者元素没有这些属性值的时候,XPath 定位可以帮我们完成任务。
- 通过 CSS 定位:使用 find_element_by_css_selector() 函数。CSS 定位也是常用的定位方法,相比于 XPath 来说更简洁。
在我们获取某个元素之后,就可以对这个元素进行操作了,对元素进行的操作包括:
- 清空输入框的内容:使用 clear() 函数;
- 在输入框中输入内容:使用 send_keys(content) 函数传入要输入的文本;
- 点击按钮:使用 click() 函数,如果元素是个按钮或者链接的时候,可以点击操作;
- 提交表单:使用 submit() 函数,元素对象为一个表单的时候,可以提交表单
3.3.2 爬虫登录
如果是需要用户登陆后才能爬取的数据,可以使用 python + selenium 的方式完成账户的自动登录,代码如下:
- 因为selenium是个自动化测试的框架,使用 selenium 的webdriver 就可以模拟浏览器的行为。找到输入用户名密码的地方,输入相应的值,然后模拟点击即可完成登录(没有验证码的情况下)
- 另外也可以使用 cookie 来登录网站,方法是你登录网站时,先保存网站的 cookie,然后用下次访问的时候,加载之前保存的 cookie,放到 request headers 中,这样就不需要再登录网站了
from selenium import webdriver
import time
browser = webdriver.Chrome(executable_path="/Users/abc/Downloads/chromn-download/chromedriver")
# 登录微博
def weibo_login(username, password):
# 打开微博登录页
browser.get('https://passport.weibo.cn/signin/login')
browser.implicitly_wait(5)
time.sleep(1)
# 填写登录信息:用户名、密码
browser.find_element_by_id("loginName").send_keys(username)
browser.find_element_by_id("loginPassword").send_keys(password)
time.sleep(1)
# 点击登录
browser.find_element_by_id("loginAction").click()
time.sleep(1)
# 设置用户名、密码
username = 'XXXX'
password = "XXXX"
weibo_login(username, password)
上述代码效果如下:
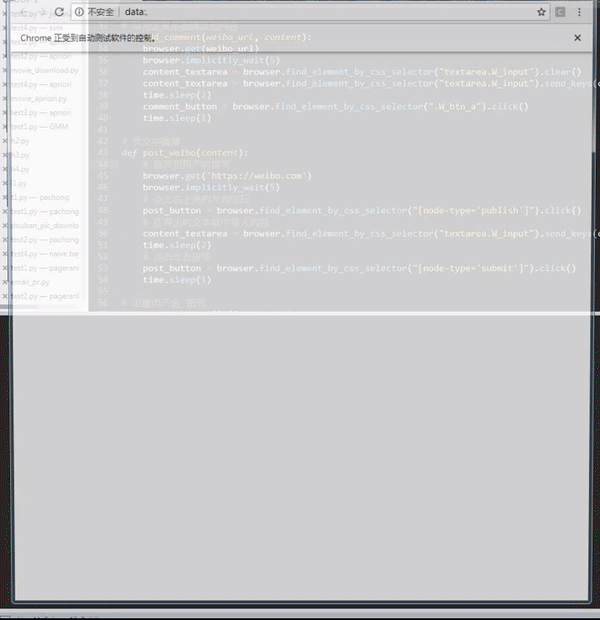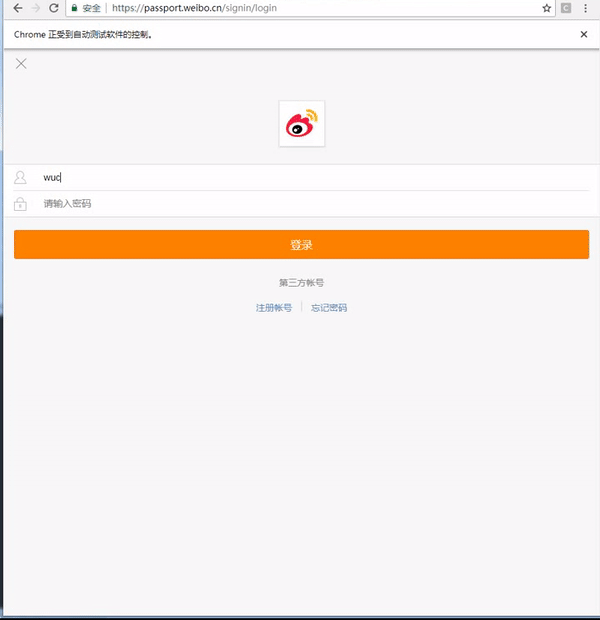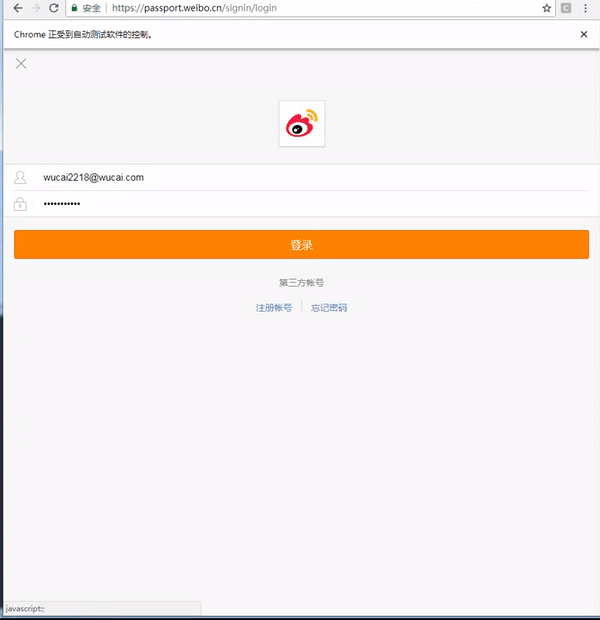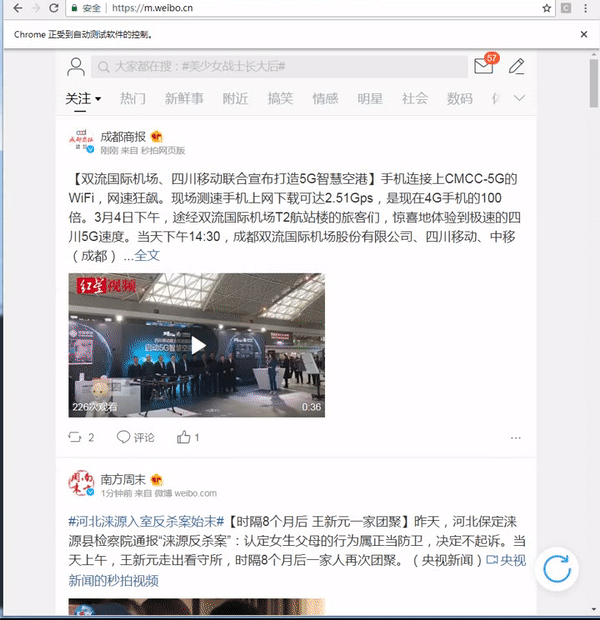
3.3.3 爬电影海报
通过 XPath 可以检索 html 元素:
from selenium import webdriver
driver = webdriver.Chrome(executable_path="/Users/abc/Downloads/chromn-download/chromedriver") # 需安装 ChromeDriver(见上文), 注意前缀要写'/Users/abc'而不要写'~'
driver.get(request_url)
src_xpath = "//div[@class='item-root']/a[@class='cover-link']/img[@class='cover']/@src"
title_xpath = "//div[@class='item-root']/div[@class='detail']/div[@class='title']/a[@class='title-text']"
srcs = html.xpath(src_xpath)
titles = html.xpath(title_path)
for src, title in zip(srcs, titles):
download(src, title.text)
从豆瓣爬电影海报代码如下:
#环境:Mac Python3
#pip install selenium
#下载chromedriver,放到项目路径下(https://npm.taobao.org/mirrors/chromedriver/2.33/)
# coding:utf-8
import requests
import json
import os
from lxml import etree
from selenium import webdriver
query = '张柏芝'
downloadPath = '/Users/ abc/Desktop/Python/xpath/images/'
''' 下载图片 '''
def download(src, id):
dir = downloadPath + str(id) + '.jpg'
try:
pic = requests.get(src, timeout=10)
except requests.exceptions.ConnectionError:
print 'error, %d 当前图片无法下载', %id
if not os.path.exists(downloadPath):
os.mkdir(downloadPath)
if os.path.exists(dir):
print('已存在:'+ id)
return
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
def searchImages():
''' for 循环 请求全部的 url '''
for i in range(0, 22471, 20):
url = 'https://www.douban.com/j/search_photo?q='+query+'&limit=20&start='+str(i)
html = requests.get(url).text # 得到返回结果
print('html:'+html)
response = json.loads(html,encoding='utf-8') # 将 JSON 格式转换成 Python 对象
for image in response['images']:
print(image['src']) # 查看当前下载的图片网址
download(image['src'], image['id']) # 下载一张图片
def getMovieImages():
url = 'https://movie.douban.com/subject_search?search_text='+ query +'&cat=1002'
driver = webdriver.Chrome('/Users/abc/Desktop/Python/xpath/libs/chromedriver')
driver.get(url)
html = etree.HTML(driver.page_source)
# 使用xpath helper, ctrl+shit+x 选中元素,如果要匹配全部,则需要修改query 表达式
src_xpath = "//div[@class='item-root']/a[@class='cover-link']/img[@class='cover']/@src"
title_xpath = "//div[@class='item-root']/div[@class='detail']/div[@class='title']/a[@class='title-text']"
srcs = html.xpath(src_xpath)
titles = html.xpath(title_xpath)
for src, title in zip(srcs, titles):
print('t'.join([str(src),str(title.text)]))
download(src, title.text)
driver.close()
getMovieImages()
3.3.4 关注、评论、自动发微博

浏览器的 F12 开发者工具看到此元素的 div 标签中的 class 属性为 m-add-box m-followBtn,则可通过 find_element_by_xpath(’//div[@class=“m-add-box m-followBtn”]’) 获取这个元素。微博加关注代码如下:
# 添加指定的用户
def add_follow(uid):
browser.get('https://m.weibo.com/u/'+str(uid))
time.sleep(1)
#browser.find_element_by_id("follow").click()
follow_button = browser.find_element_by_xpath('//div[@class="m-add-box m-followBtn"]')
follow_button.click()
time.sleep(1)
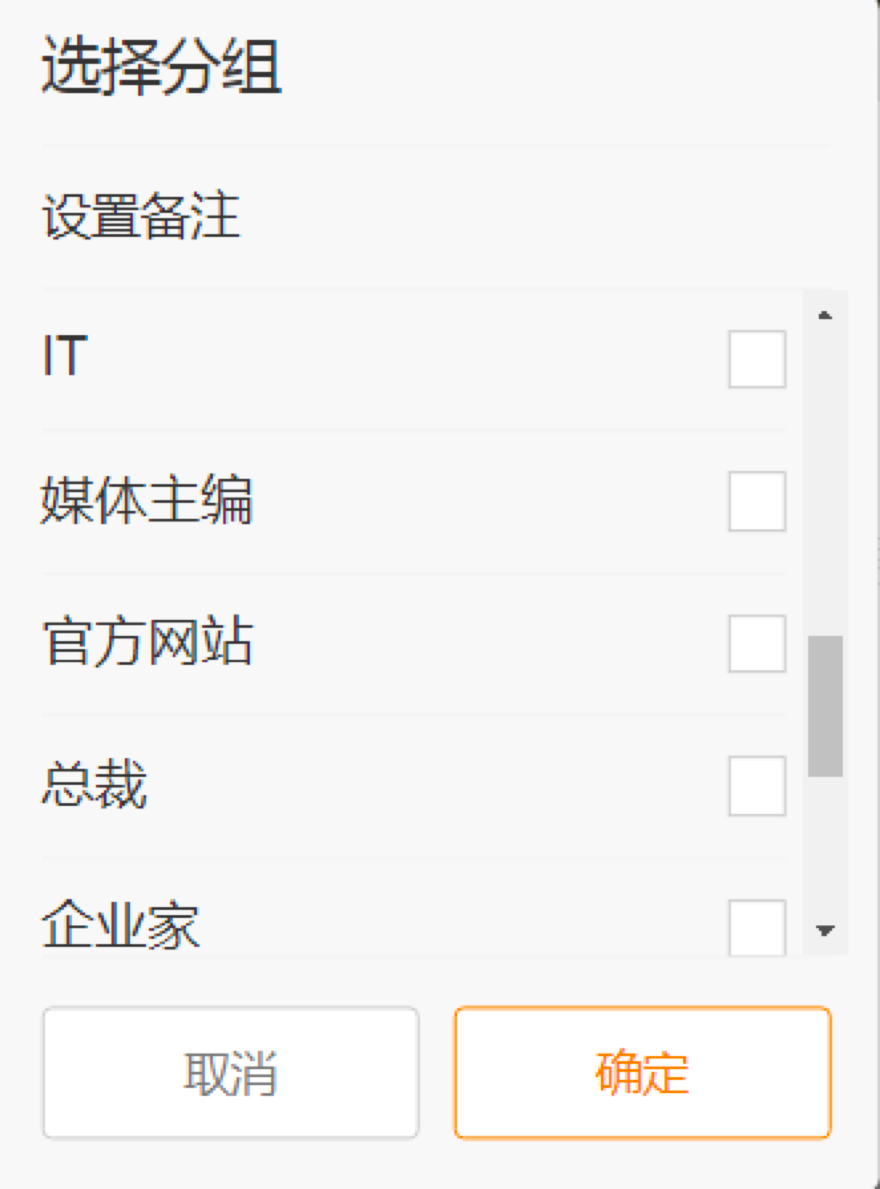
# 选择分组
group_button = browser.find_element_by_xpath('//div[@class="m-btn m-btn-white m-btn-text-black"]')
group_button.click()
time.sleep(1)
# 每天学点心理学 UID
uid = '1890826225'
add_follow(uid)
关注之后,程序会弹出选择分组的页面,如下所示。
接下来,我们继续完成写评论和发微博的模块代码:
# 给指定某条微博添加内容
def add_comment(weibo_url, content):
browser.get(weibo_url)
browser.implicitly_wait(5)
content_textarea = browser.find_element_by_css_selector("textarea.W_input").clear()
content_textarea = browser.find_element_by_css_selector("textarea.W_input").send_keys(content)
time.sleep(2)
comment_button = browser.find_element_by_css_selector(".W_btn_a").click()
time.sleep(1)
# 发文字微博
def post_weibo(content):
# 跳转到用户的首页
browser.get('https://weibo.com')
browser.implicitly_wait(5)
# 点击右上角的发布按钮
post_button = browser.find_element_by_css_selector("[node-type='publish']").click()
# 在弹出的文本框中输入内容
content_textarea = browser.find_element_by_css_selector("textarea.W_input").send_keys(content)
time.sleep(2)
# 点击发布按钮
post_button = browser.find_element_by_css_selector("[node-type='submit']").click()
time.sleep(1)
# 给指定的微博写评论
weibo_url = 'https://weibo.com/1890826225/HjjqSahwl'
content = 'Gook Luck! 好运已上路!'
# 自动发微博
content = '每天学点心理学'
post_weibo(content)
如何找到某条微博的链接呢?你可以在某个用户微博页面中点击时间的链接,这样就可以获取这条微博的链接。
我们将鼠标移动到评论框中,在 Chrome 浏览器中点击右键“查看”,可以看到这个 textarea 的 class 是 W_input,使用 find_element_by_css_selector 函数进行定位,然后通过 send_keys 设置内容。
最后就是发微博的流程。我们可以观察到点击微博页面的右上角的按钮后,会弹出一个发微博的文本框,设置好内容,点击发送即可。发微博的函数和写评论的代码类似,使用 find_element_by_css_selector() 函数定位,通过 send_keys() 设置内容的设置,最后通过 click() 发送。
微博自动化运营是一个系统的工程,需要考虑到各种情况,比如相同的内容发布需要间隔 10 分钟以上;关注了一个用户之后,就无法对他二次关注,可以判断是否已经关注过,再关注操作;因为操作频繁导致需要输入验证码的情况等。
四、ETL
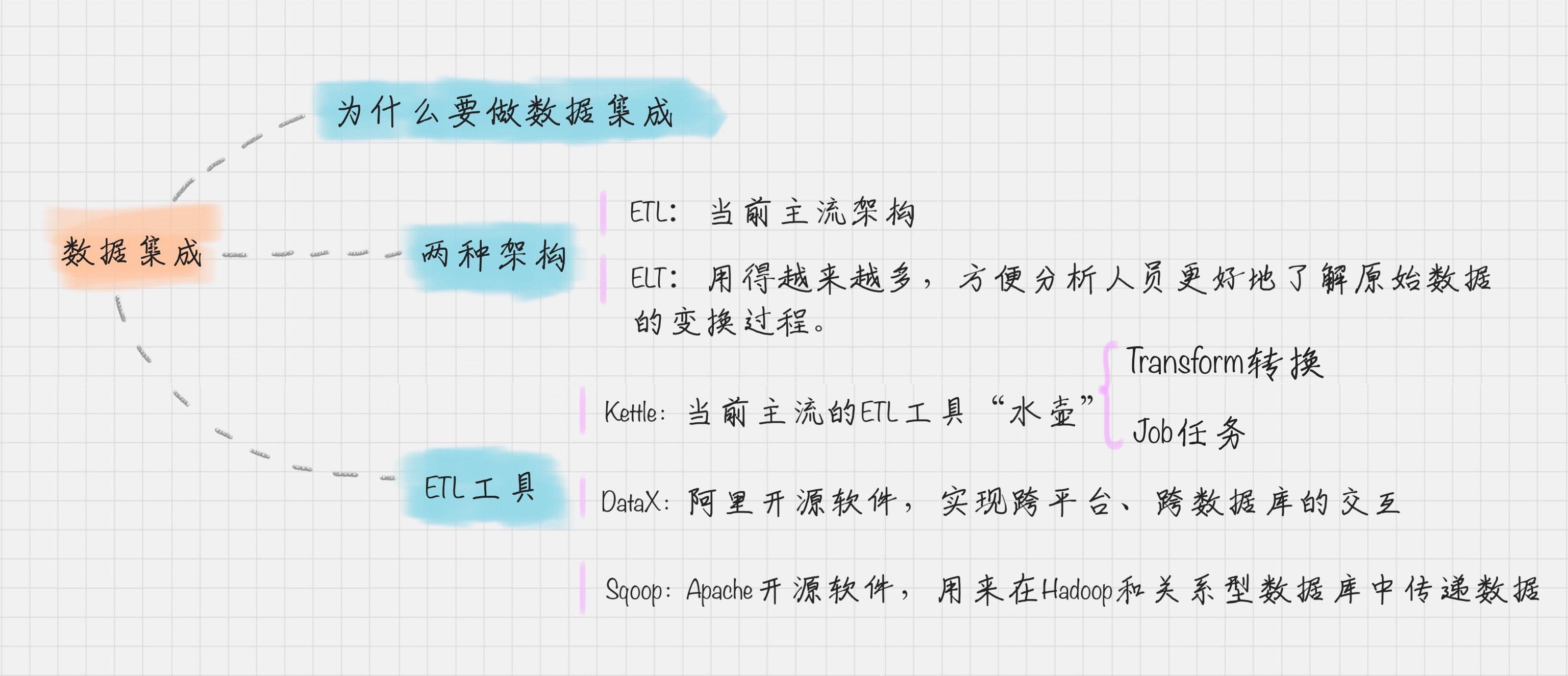
ETL 的过程为提取 (Extract)——转换 (Transform)——加载 (Load),在数据源抽取后首先进行转换,然后将转换的结果写入目的地。开源软件:Kettle、Talend、Apatar、Scriptella、DataX、Sqoop 等
Kettle 是一款国外开源的 ETL 工具,纯 Java 编写,可以在 Window 和 Linux 上运行,不需要安装就可以使用。Kettle 中文名称叫水壶,该项目的目标是将各种数据放到一个壶里,然后以一种指定的格式流出。
五、数据变换
常见的变换方法:
- 数据平滑:去除数据中的噪声,将连续数据离散化。这里可以采用分箱、聚类和回归的方式进行数据平滑,我会在后面给你讲解聚类和回归这两个算法;
- 数据聚集:对数据进行汇总,在 SQL 中有一些聚集函数可以供我们操作,比如 Max() 反馈某个字段的数值最大值,Sum() 返回某个字段的数值总和;
- 数据概化:将数据由较低的概念抽象成为较高的概念,减少数据复杂度,即用更高的概念替代更低的概念。比如说上海、杭州、深圳、北京可以概化为中国。
- 数据规范化:使属性数据按比例缩放,这样就将原来的数值映射到一个新的特定区域中。常用的方法有最小—最大规范化、Z—score 规范化、按小数定标规范化等,我会在后面给你讲到这些方法的使用;
- 属性构造:构造出新的属性并添加到属性集中。这里会用到特征工程的知识,因为通过属性与属性的连接构造新的属性,其实就是特征工程。比如说,数据表中统计每个人的英语、语文和数学成绩,你可以构造一个“总和”这个属性,来作为新属性。这样“总和”这个属性就可以用到后续的数据挖掘计算中。
5.1 用 SciKit-Learn 实现规范化
SciKit-Learn 是 Python 的重要机器学习库,它帮我们封装了大量的机器学习算法,比如分类、聚类、回归、降维等。此外,它还包括了数据变换模块。
归一化的“一”,是让数据在 [0,1] 的范围内。而标准化,目标是让数据呈现标准的正态分布。
- 数据归一化会让数据在一个 [0,1] 或者 [-1,1] 的区间范围内。
- 数据标准化会让规范化的数据呈现正态分布的情况。
在数据挖掘算法中,一般情况下都需要进行数据规范化,尤其是针对距离相关的运算,比如在 K-Means、KNN 以及聚类算法中,我们需要有对距离的定义,所以在做这些算法前,需要对数据进行规范化。
还有一些算法用到了梯度下降作为优化器,这是为了提高迭代收敛的效率,也就是提升找到目标函数最优解的效率。我们也需要进行数据规范化,比如逻辑回归、SVM 和神经网络算法。在这些算法中都有目标函数,需要对目标函数进行求解。梯度下降的目标是寻找到目标函数的最优解,而梯度的方法则指明了最优解的方向,如下图所示。
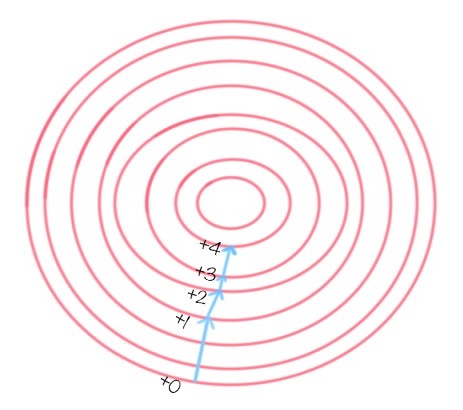
当然不是所有的算法都需要进行数据规范化。在构造决策树的时候,可以不用提前做数据规范化,因为我们不需要关心特征值的大小维度,也没有使用到梯度下降来做优化,所以数据规范化对决策树的构造结果和构造效率影响不大。除此之外,还是建议你在做数据挖掘算法前进行数据规范化。
下文是如何使用 SciKit-Learn 进行数据规范化:
5.1.1 MinMax 规范化
将原始数据变换到 [0,1] 的空间中。用公式表示就是:新数值 =(原数值 - 极小值)/(极大值 - 极小值)。
from sklearn import preprocessing
if __name__ == '__main__':
x = np.array([[0., -3., 1.], [3., 1., 2.], [0., 1., -1.]])
min_max_scaler = preprocessing.MinMaxScaler()
minmax_x = min_max_scaler.fit_transform(x)
print(minmax_x)
# 输出如下:
[[0. 0. 0.66666667]
[1. 1. 1. ]
[0. 1. 0. ]]
原理是,默认各列(即axis=0)分别求 MinMaxScalar,推导如下图:

5.1.2 Z-Score 规范化
实际上就是将每行每列的值减去了平均值,再除以方差的结果,最终数值都符合均值为 0,方差为 1 的正态分布。
假设 A 与 B 的考试成绩都为 80 分,A 的考卷满分是 100 分(及格 60 分),B 的考卷满分是 500 分(及格 300 分)。虽然两个人都考了 80 分,但是 A 的 80 分与 B 的 80 分代表完全不同的含义。
那么如何用相同的标准来比较 A 与 B 的成绩呢?Z-Score 就是用来可以解决这一问题的。
我们定义:新数值 =(原数值 - 均值)/ 标准差。
假设 A 所在的班级平均分为 80,标准差为 10。B 所在的班级平均分为 400,标准差为 100。那么 A 的新数值 =(80-80)/10=0,B 的新数值 =(80-400)/100=-3.2。
那么在 Z-Score 标准下,A 的成绩会比 B 的成绩好。
我们能看到 Z-Score 的优点是算法简单,不受数据量级影响,结果易于比较。不足在于,它需要数据整体的平均值和方差,而且结果没有实际意义,只是用于比较。
from sklearn import preprocessing
if __name__ == '__main__':
x = np.array([[0., -3., 1.], [3., 1., 2.], [0., 1., -1.]])
scaled_x = preprocessing.scale(x)
print(scaled_x)
# 输出结果如下:
[[-0.70710678 -1.41421356 0.26726124]
[ 1.41421356 0.70710678 1.06904497]
[-0.70710678 0.70710678 -1.33630621]]
5.1.3 小数定标规范化
通过移动小数点的位置来进行规范化。小数点移动多少位取决于属性 A 的取值中的最大绝对值。
举个例子,比如属性 A 的取值范围是 -999 到 88,那么最大绝对值为 999,小数点就会移动 3 位,即新数值 = 原数值 /1000。那么 A 的取值范围就被规范化为 -0.999 到 0.088。
if __name__ == '__main__':
x = np.array([[0., -3., 1.], [3., 1., 2.], [0., 1., -1.]])
j = np.ceil(np.log10(np.max(abs(x))))
scaled_x = x / (10**j)
print(scaled_x)
# 输出结果如下:
[[ 0. -0.3 0.1]
[ 0.3 0.1 0.2]
[ 0. 0.1 -0.1]]
六、可视化
当这些可视化的结果呈现在你眼前时,你才能直观地体会到“数据之美”。图片在内容表达上,要远胜于文字,它不仅能体现数据真实性,还能给人很大的想象空间。
常用的可视化视图超过 20 种,分别包括:文本表、热力图、地图、符号地图、饼图、水平条、堆叠条、并排条、树状图、圆视图、并排圆、线、双线、面积图、双组合、散点图、直方图、盒须图、甘特图、靶心图、气泡图等。
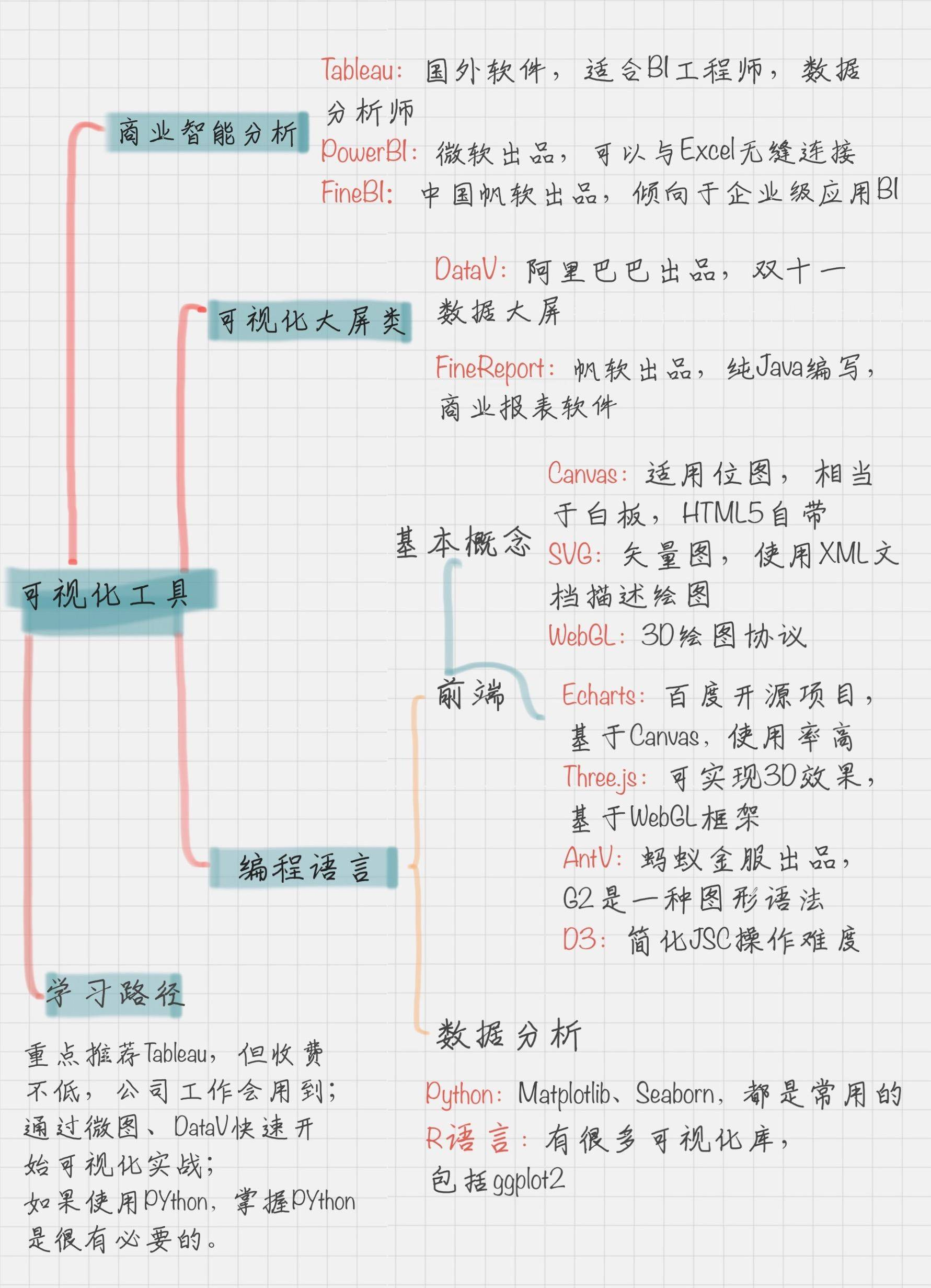
6.1 工具与组件库
智能商业分析:
- Tableau 是国外的商业软件,收费不低。它适合 BI 工程师、数据分析分析师。如果可以熟练掌握 Tableau,那么找到一份数据分析的工作是不难的
- PowerBI 是微软出品的,可以和 Excel 搭配使用,你可以通过 PowerBI 来呈现 Excel 的可视化内容
- FineBI 是中国的帆软出品,针对国内使用更加友好,同时也倾向于企业级应用的 BI
- 阿里的QuickBI,可以无缝对接所有数据源,上手非常简单,不用编程
可视化大屏:
- DataV:是一款可视化的工具,天猫双十一大屏就是用它呈现的。你要做的就是选择相应的控件,配置控件的样式、数据传输和交互效果等。当然 DataV 本身有一些免费的模板,你可以直接通过模板来创建。不过一些特殊的控件和交互效果还是需要购买企业版才行。
- FineReport:可以做数据大屏,也可以做可视化报表,在很多行业都有解决方案,操作起来也很方便。可以实时连接业务数据,对数据进行展示。
前端渲染协议:
- Canvas 适用于位图,也就是给了你一张白板,需要你自己来画点。可以绘制比较复杂的动画,它是 HTML5 自带的。ECharts 就是基于 其实现的。
- SVG:即可缩放矢量图形,它是使用 XML 格式来定义图形的。相当于用点和线来描绘了图形,相比于位图来说文件比较小,而且任意缩放都不会失真。SVG 经常用于图标和图表上。它最大的特点就是支持大部分浏览器,动态交互性实现起来也很方便,比如在 SVG 中插入动画元素等。
- WebGL:一种 3D 绘图协议,能在网页浏览器中呈现 3D 画面技术,并且可以和用户进行交互。你在网页上看到的很多酷炫的 3D 效果,基本上都是用 WebGL 来渲染的。Three.js 就是基于 WebGL 框架的。
前端可视化组件库:
- ECharts 是基于 H5 canvas 的 Javascript 图表库,使用人数较多
- D3 是一个 JavaScript 的函数库,有很多简单易用的函数
- Three.js 是一款 WebGL 框架,封装了大量 WebGL 接口,因为直接用 WebGL API 写 3D 程序太麻烦了
- AntV 是蚂蚁金服出品的一套数据可视化组件,包括了 G2、G6、F2 和 L7 一共 4 个组件。
- 其中 G2 应该是最知名的,它的意思是 The grammar Of Graphics,也就是一套图形语法。它集成了大量的统计工具,而且可以让用户通过简单的语法搭建出多种图表
- G6 是一套流程图和关系分析的图表库
- F2 适用于移动端的可视化方案
- L7 提供了地理空间的数据可视化框架
Python可视化库:
- Matplotlib 作图风格和 MATLAB 类似
- Seaborn 是一个基于 Matplotlib 的高级可视化效果库,针对 Matplotlib 做了更高级的封装,让作图变得更加容易
学习哪种可视化工具呢?
- 重点推荐 Tableau
Tableau 在可视化灵活分析上功能强大,主要目标用户更多是较专业的数据分析师。同时在工作场景中使用率高,因此掌握 Tableau 对于晋升和求职都很有帮助。不过 Tableau 是个商业软件,收费不低。而且上手起来有一些门槛,需要一定数据基础。
- 使用微图、DataV
前面我给你讲过八爪鱼的使用,微图和八爪鱼是一家公司的产品,使用起来非常方便,而且免费。当你用八爪鱼采集数据之后,就直接可以用微图进行数据可视化。
DataV 是阿里推出的数字大屏技术,不过它是收费的产品。它最大的好处,就是可以分享链接,让别人可以在线浏览,不需要像 Tableau 一样安装客户端才能看到数据可视化的结果。另外 DataV 有一些模板,你直接可以使用。
你可以先使用微图和 DataV 作为你的数据可视化体验工具,因为成本低,上手起来快。这样你对数据可视化可以有个直观的了解。如果你想从事数据可视化这份工作,你可以花更多的精力去研究和学习 Tableau。
- Python 可视化
Python 是数据分析的首选语言,如果你不进行编程,可以使用我在上文中提到的数据可视化的工具。如果你的目标是个数据挖掘工程师,或者算法工程师,那么最重要的就是要了解,并且熟练掌握 Python 的数据可视化。
6.2 维度与效果
按照数据之间的关系,可以把可视化视图划分为 4 类:
- 比较:比较数据间各类别的关系,或者是它们随着时间的变化趋势,比如折线图;
- 联系:查看两个或两个以上变量之间的关系,比如散点图;
- 构成:每个部分占整体的百分比,或者是随着时间的百分比变化,比如饼图;
- 分布:关注单个变量,或者多个变量的分布情况,比如直方图。
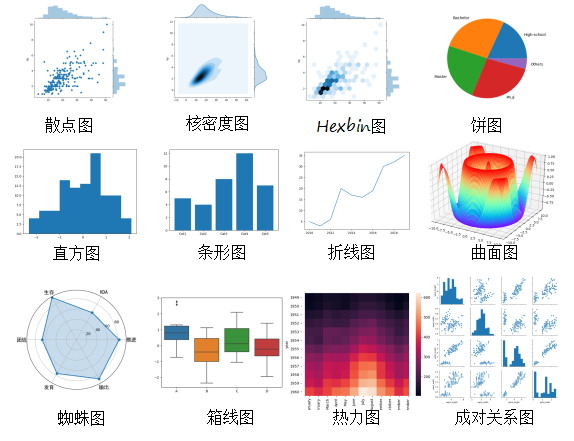
各可视化图介绍如下:
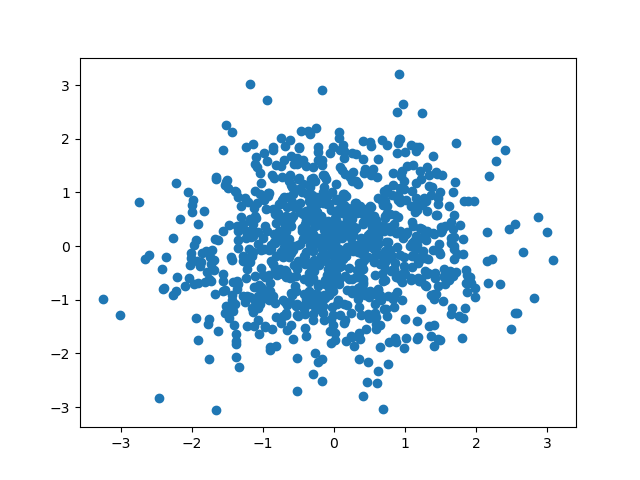
6.2.1 散点图
英文叫做 scatter plot,它将两个变量的值显示在二维坐标中,非常适合展示两个变量之间的关系。除了二维的散点图,还有三维的散点图。
Matplotlib 默认情况下呈现出来的是个长方形:
if __name__ == '__main__':
# 数据准备
N = 1000
x = np.random.randn(N)
y = np.random.randn(N)
# 用 Matplotlib 画散点图
plt.scatter(x, y, marker='o') # marker可选x/o/>表示散点的形状
plt.show()
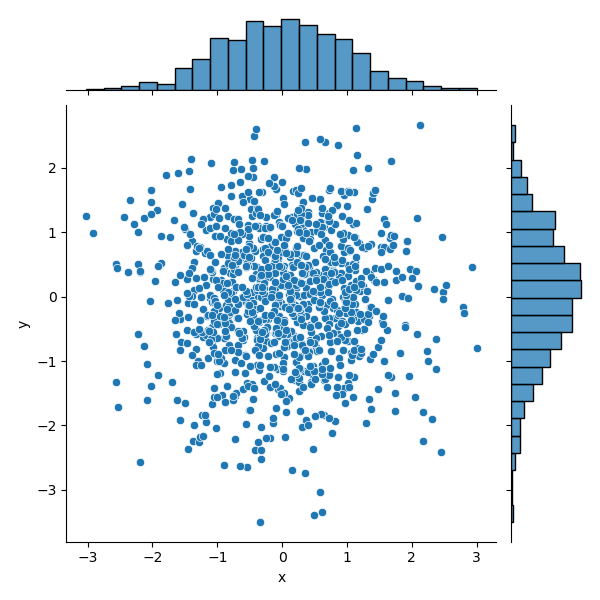
而 Seaborn 呈现的是个正方形,而且不仅显示出了散点图,还给了这两个变量的分布情况:
if __name__ == '__main__':
# 数据准备
N = 1000
x = np.random.randn(N)
y = np.random.randn(N)
# 用 Seaborn 画散点图
df = pd.DataFrame({'x': x, 'y': y})
sns.jointplot(x="x", y="y", data=df, kind='scatter')
plt.show()
6.2.2 折线图
两个库折线图的效果相同,效果如下:
if __name__ == '__main__':
# 数据准备
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35]
# 使用 Matplotlib 画折线图
plt.plot(x, y)
plt.show()
# 使用 Seaborn 画折线图
df = pd.DataFrame({'x': x, 'y': y})
sns.lineplot(x="x", y="y", data=df)
plt.show()
6.2.3 直方图
直方图把横坐标等分成了一定数量的小区间,这个小区间也叫作“箱子”,然后在每个“箱子”内用矩形条(bars)展示该箱子的箱子数(也就是 y 值)。
在 Matplotlib 中,我们使用 plt.hist(x, bins=10) 函数,其中参数 x 是一维数组,bins 代表直方图中的箱子数量,默认是 10。
在 Seaborn 中,我们使用 sns.distplot(x, bins=10, kde=True) 函数。其中参数 x 是一维数组,bins 代表直方图中的箱子数量,kde 代表显示核密度估计,默认是 True,我们也可以把 kde 设置为 False,不进行显示。核密度估计是通过核函数帮我们来估计概率密度的方法。
if __name__ == '__main__':
# 数据准备
a = np.random.randn(100)
s = pd.Series(a)
# 用 Matplotlib 画直方图
plt.hist(s)
plt.show()
# 用 Seaborn 画直方图
sns.distplot(s, kde=False)
plt.show()
sns.distplot(s, kde=True)
plt.show()
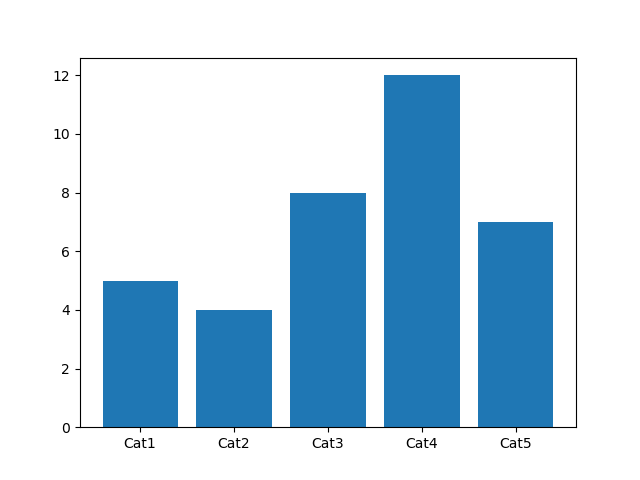
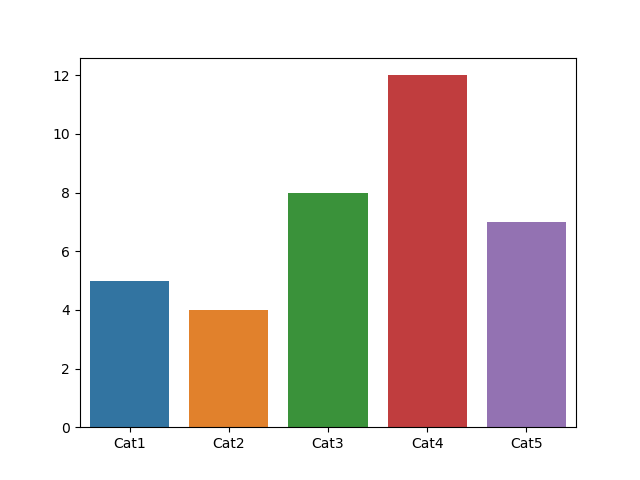
6.2.4 条形图
如果说通过直方图可以看到变量的数值分布,那么条形图可以帮我们查看类别的特征。在条形图中,长条形的长度表示类别的频数,宽度表示类别。
在 Matplotlib 中,我们使用 plt.bar(x, height) 函数,其中参数 x 代表 x 轴的位置序列,height 是 y 轴的数值序列,也就是柱子的高度。
在 Seaborn 中,我们使用 sns.barplot(x=None, y=None, data=None) 函数。其中参数 data 为 DataFrame 类型,x、y 是 data 中的变量。
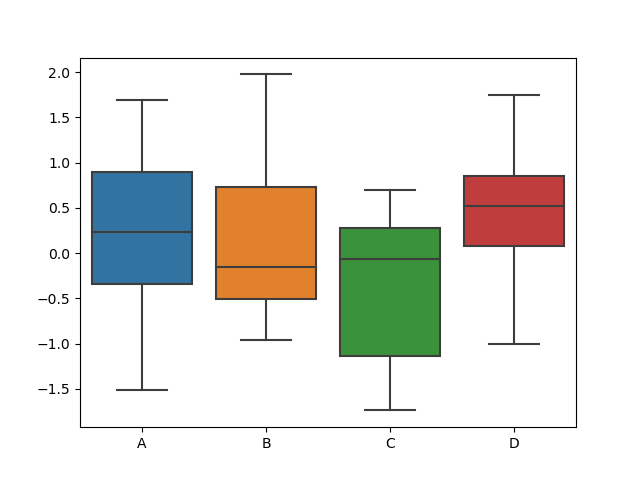
6.2.5 箱线图
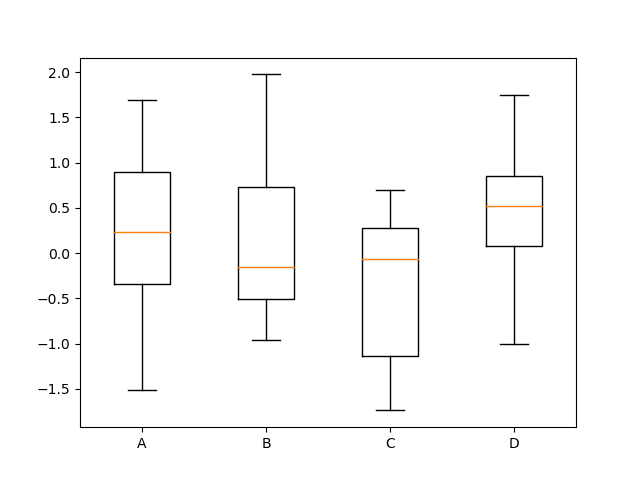
又称盒式图,它是在 1977 年提出的,由五个数值点组成:最大值 (max)、最小值 (min)、中位数 (median) 和上下四分位数 (Q3, Q1)。它可以帮我们分析出数据的差异性、离散程度和异常值等。
在 Matplotlib 中,我们使用 plt.boxplot(x, labels=None) 函数,其中参数 x 代表要绘制箱线图的数据,labels 是缺省值,可以为箱线图添加标签。
在 Seaborn 中,我们使用 sns.boxplot(x=None, y=None, data=None) 函数。其中参数 data 为 DataFrame 类型,x、y 是 data 中的变量。
if __name__ == '__main__':
# 数据准备
# 生成 0-1 之间的 10*4 维度数据
data = np.random.normal(size=(10, 4))
lables = ['A', 'B', 'C', 'D']
# 用 Matplotlib 画箱线图
plt.boxplot(data, labels=lables)
plt.show()
# 用 Seaborn 画箱线图
df = pd.DataFrame(data, columns=lables)
sns.boxplot(data=df)
plt.show()
上述代码中,生成了 0-1 之间的 10*4 维度数据如下:
6.2.6 饼图
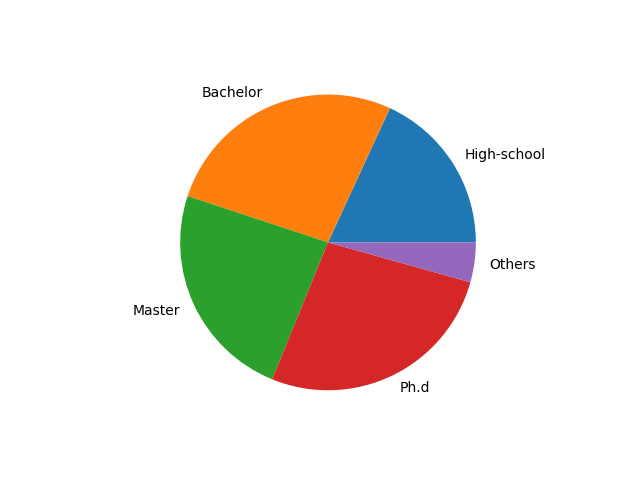
在 Matplotlib 中,我们使用 plt.pie(x, labels=None) 函数,其中参数 x 代表要绘制饼图的数据,labels 是缺省值,可以为饼图添加标签。
这里我设置了 lables 数组,分别代表高中、本科、硕士、博士和其他几种学历的分类标签。nums 代表这些学历对应的人数。
if __name__ == '__main__':
# 数据准备
nums = [25, 37, 33, 37, 6]
labels = ['High-school', 'Bachelor', 'Master', 'Ph.d', 'Others']
# 用 Matplotlib 画饼图
plt.pie(x=nums, labels=labels)
plt.show()
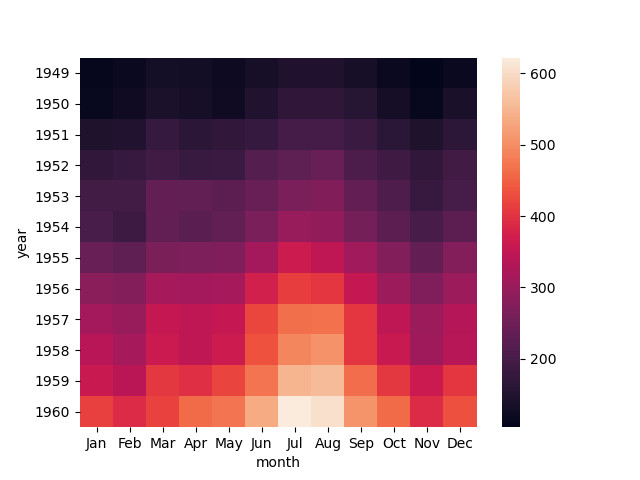
6.2.7 热力图
是一种矩阵表示方法,其中矩阵中的元素值用颜色来代表,不同的颜色代表不同大小的值。通过颜色就能直观地知道某个位置上数值的大小。另外你也可以将这个位置上的颜色,与数据集中的其他位置颜色进行比较。
热力图是一种非常直观的多元变量分析方法。
我们一般使用 Seaborn 中的 sns.heatmap(data) 函数,其中 data 代表需要绘制的热力图数据。
这里我们使用 Seaborn 中自带的数据集 flights,该数据集记录了 1949 年到 1960 年期间,每个月的航班乘客的数量。
if __name__ == '__main__':
# 数据准备
flights = sns.load_dataset("flights")
data = flights.pivot('year', 'month', 'passengers')
# 用 Seaborn 画热力图
sns.heatmap(data)
plt.show()
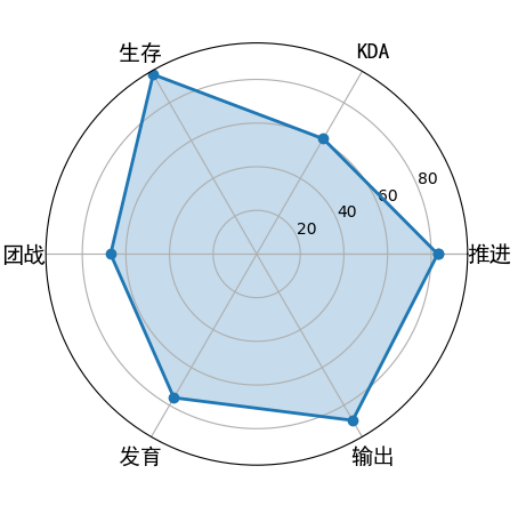
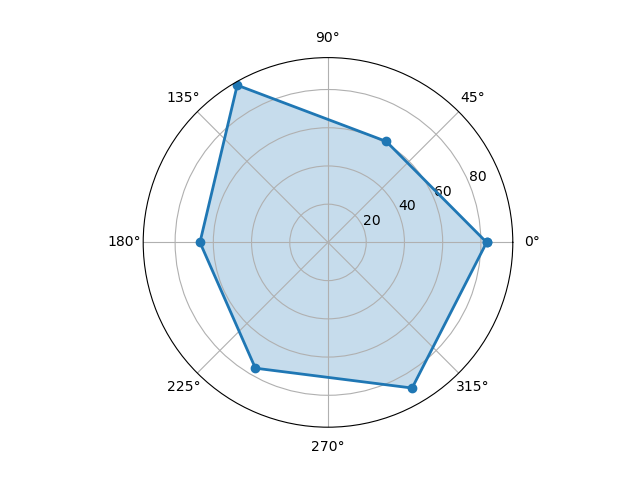
6.2.8 蜘蛛图
蜘蛛图是一种显示一对多关系的方法。在蜘蛛图中,一个变量相对于另一个变量的显著性是清晰可见的。
用 Matplotlib 来进行画图,首先设置两个数组:labels 和 stats。他们分别保存了这些属性的名称和属性值。
因为蜘蛛图是一个圆形,你需要计算每个坐标的角度,然后对这些数值进行设置。当画完最后一个点后,需要与第一个点进行连线。
因为需要计算角度,所以我们要准备 angles 数组;又因为需要设定统计结果的数值,所以我们要设定 stats 数组。并且需要在原有 angles 和 stats 数组上增加一位,也就是添加数组的第一个元素。
if __name__ == '__main__':
from matplotlib.font_manager import FontProperties
# 数据准备
labels = np.array([u" learn ", "code", u" project ", u" talk ", u" x ", u" y "])
stats = [83, 61, 95, 67, 76, 88]
# 画图数据准备,角度、状态值
angles = np.linspace(0, 2 * np.pi, len(labels), endpoint=False)
stats = np.concatenate((stats, [stats[0]]))
angles = np.concatenate((angles, [angles[0]]))
# 用 Matplotlib 画蜘蛛图
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
# 设置中文字体
# font = FontProperties(fname=r"C:WindowsFontssimhei.ttf", size=14)
font = FontProperties(fname="/System/Library/Fonts/STHeiti Medium.ttc", size=14)
ax.set_thetagrids(angles * 180 / np.pi, labels, FontProperties=font)
plt.show()
代码中 flt.figure 是创建一个空白的 figure 对象,这样做的目的相当于画画前先准备一个空白的画板。然后 add_subplot(111) 可以把画板划分成 1 行 1 列。再用 ax.plot 和 ax.fill 进行连线以及给图形上色。最后我们在相应的位置上显示出属性名。这里需要用到中文,Matplotlib 对中文的显示不是很友好,因此我设置了中文的字体 font,这个需要在调用前进行定义。图示如下:
6.2.9 二元变量分布
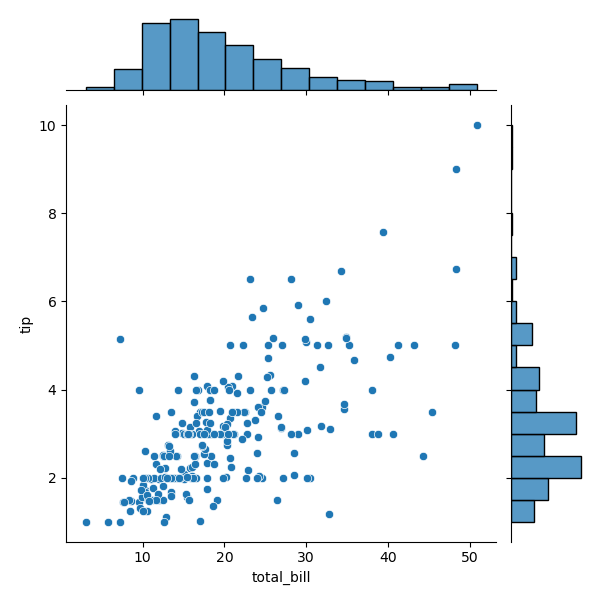
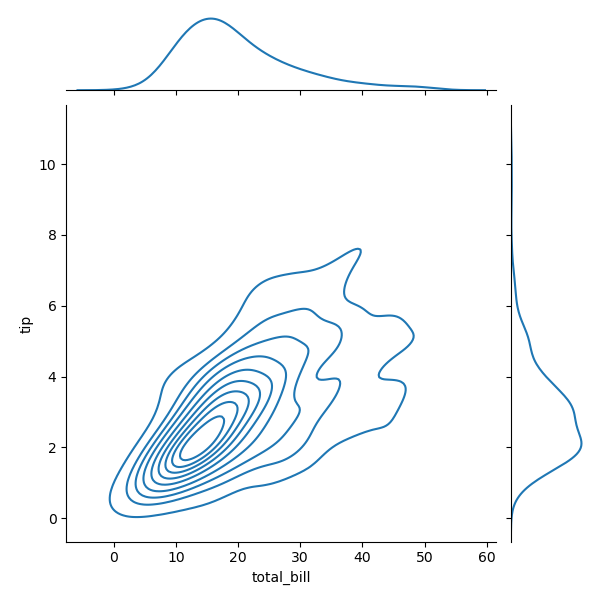
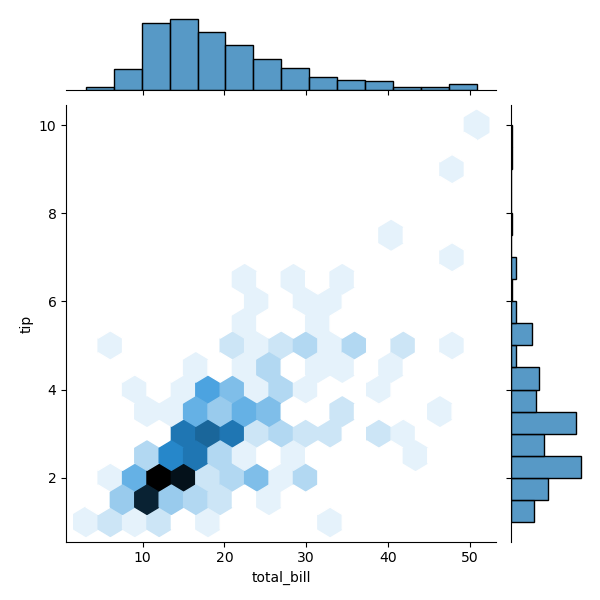
如果我们想要看两个变量之间的关系,就需要用到二元变量分布。当然二元变量分布有多种呈现方式,开头给你介绍的散点图就是一种二元变量分布。
在 Seaborn 里,使用二元变量分布是非常方便的,直接使用 sns.jointplot(x, y, data=None, kind) 函数即可。其中用 kind 表示不同的视图类型:“kind=‘scatter’”代表散点图,“kind=‘kde’”代表核密度图,“kind=‘hex’ ”代表 Hexbin 图,它代表的是直方图的二维模拟。
这里我们使用 Seaborn 中自带的数据集 tips,这个数据集记录了不同顾客在餐厅的消费账单及小费情况。代码中 total_bill 保存了客户的账单金额,tip 是该客户给出的小费金额。我们可以用 Seaborn 中的 jointplot 来探索这两个变量之间的关系。
if __name__ == '__main__':
# 数据准备
tips = sns.load_dataset("tips")
print(tips.head(10))
# 用 Seaborn 画二元变量分布图(散点图,核密度图,Hexbin 图)
sns.jointplot(x="total_bill", y="tip", data=tips, kind='scatter')
sns.jointplot(x="total_bill", y="tip", data=tips, kind='kde')
sns.jointplot(x="total_bill", y="tip", data=tips, kind='hex')
plt.show()
# 数据如下前 10:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
5 25.29 4.71 Male No Sun Dinner 4
6 8.77 2.00 Male No Sun Dinner 2
7 26.88 3.12 Male No Sun Dinner 4
8 15.04 1.96 Male No Sun Dinner 2
9 14.78 3.23 Male No Sun Dinner 2
6.2.10 成对关系
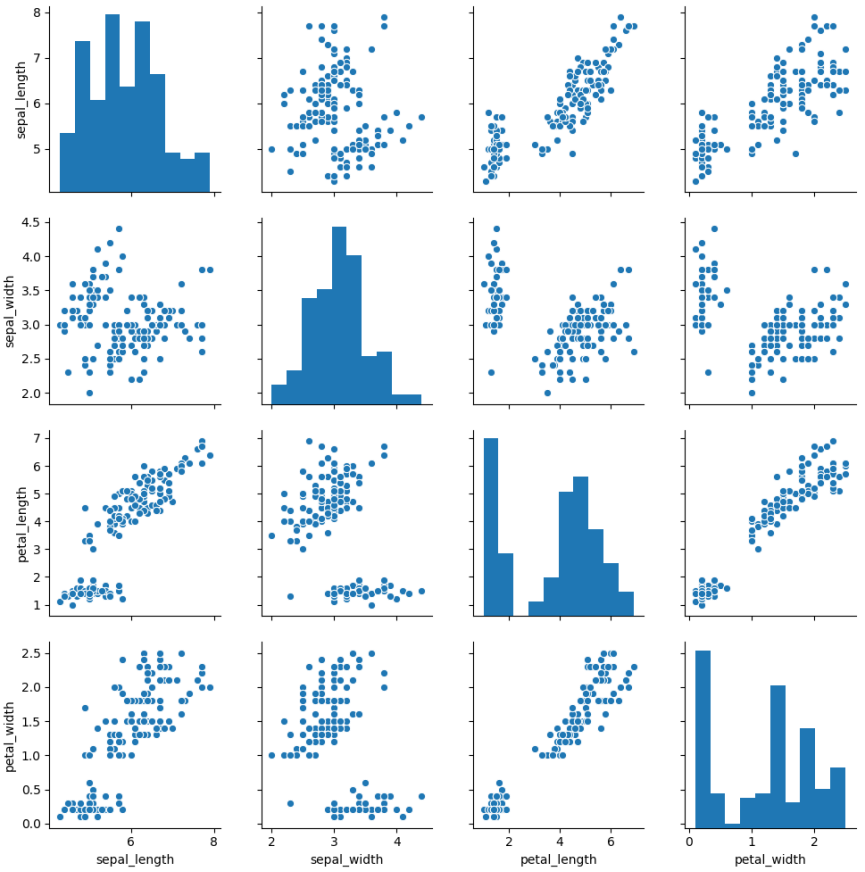
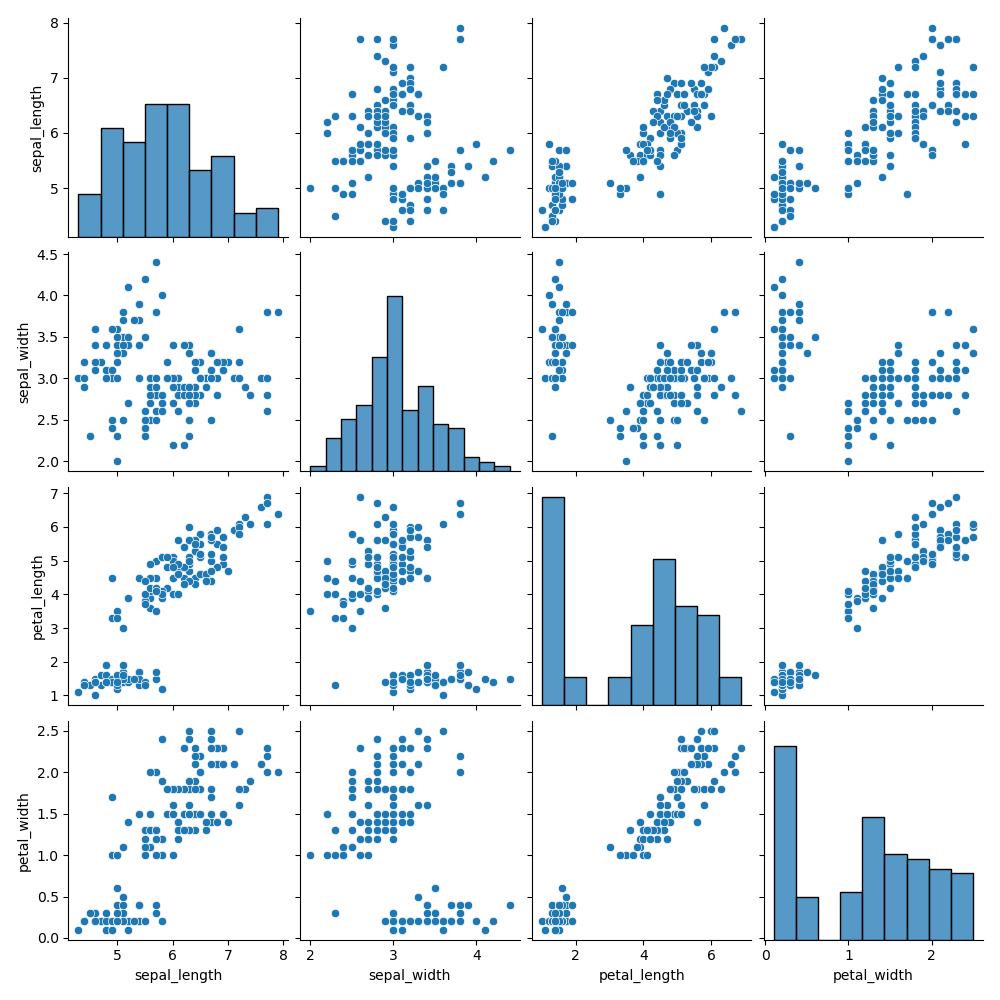
如果想要探索数据集中的多个成对双变量的分布,可以直接采用 sns.pairplot() 函数。它会同时展示出 DataFrame 中每对变量的关系,另外在对角线上,你能看到每个变量自身作为单变量的分布情况。它可以说是探索性分析中的常用函数,可以很快帮我们理解变量对之间的关系。
pairplot 函数的使用,就像在 DataFrame 中使用 describe() 函数一样方便,是数据探索中的常用函数。
这里我们使用 Seaborn 中自带的 iris 数据集,这个数据集也叫鸢尾花数据集。鸢尾花可以分成 Setosa、Versicolour 和 Virginica 三个品种,在这个数据集中,针对每一个品种,都有 50 个数据,每个数据中包括了 4 个属性,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度。通过这些数据,需要你来预测鸢尾花卉属于三个品种中的哪一种。
if __name__ == '__main__':
# 数据准备
iris = sns.load_dataset('iris')
# 用 Seaborn 画成对关系
sns.pairplot(iris)
plt.show()
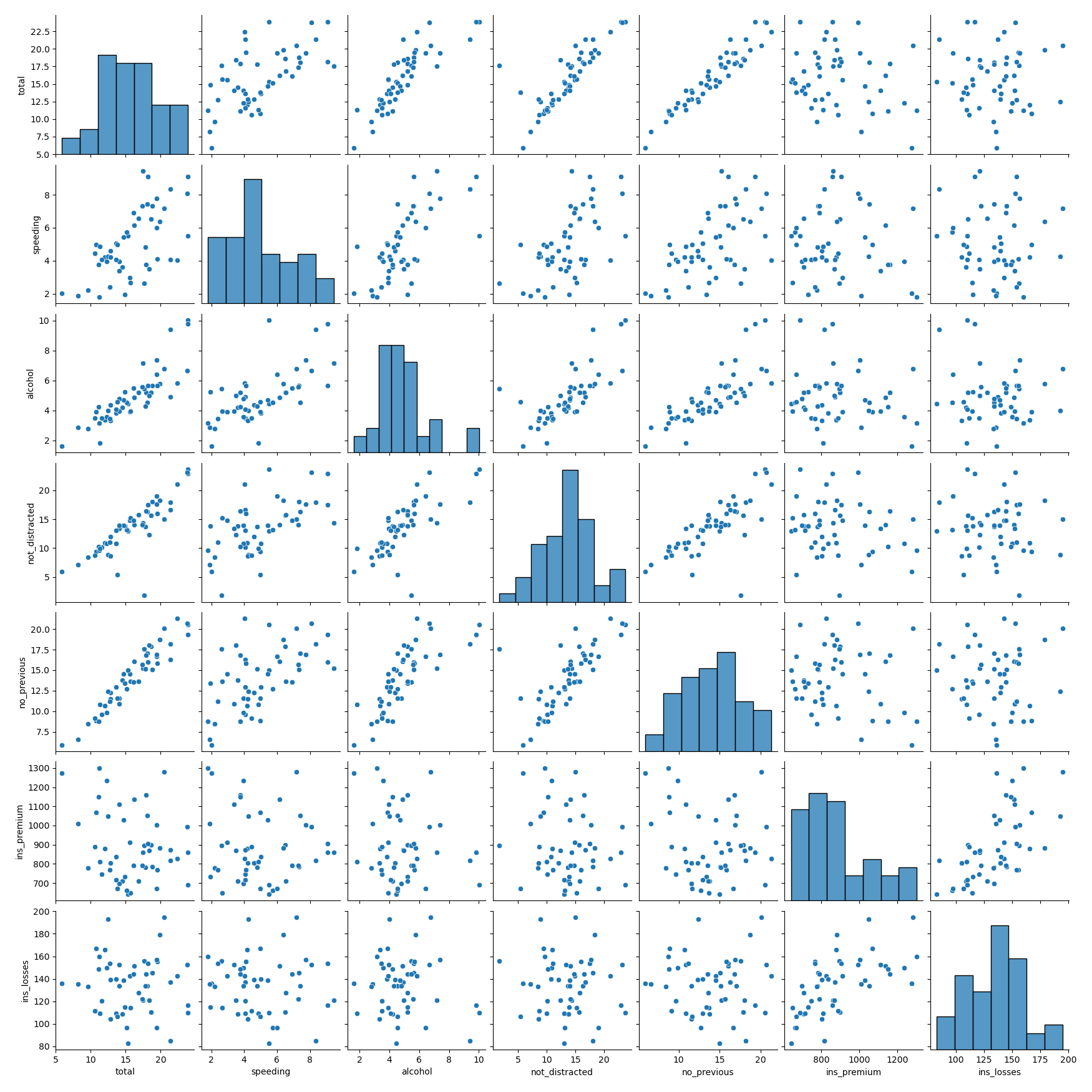
这里我们用 Seaborn 中的 pairplot 函数来对数据集中的多个双变量的关系进行探索,如下图所示。从图上你能看出,一共有 sepal_length、sepal_width、petal_length 和 petal_width4 个变量,它们分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度。
下面这张图相当于这 4 个变量两两之间的关系。比如矩阵中的第一张图代表的就是花萼长度自身的分布图,它右侧的这张图代表的是花萼长度与花萼宽度这两个变量之间的关系。
if __name__ == '__main__':
iris = sns.load_dataset("car_crashes")
sns.pairplot(iris)
plt.show()
# 从上图可以看出酒精和速度由类似线性关系,因此做酒精和速度二元变量的分布图
iris = sns.load_dataset("car_crashes")
print(iris.head(10))
sns.jointplot(x='alcohol', y='speeding', data=iris, kind='scatter')
sns.jointplot(x='alcohol', y='speeding', data=iris, kind='kde')
sns.jointplot(x='alcohol', y='speeding', data=iris, kind='hex')
# 前10条数据如下:
total speeding alcohol ... ins_premium ins_losses abbrev
0 18.8 7.332 5.640 ... 784.55 145.08 AL
1 18.1 7.421 4.525 ... 1053.48 133.93 AK
2 18.6 6.510 5.208 ... 899.47 110.35 AZ
3 22.4 4.032 5.824 ... 827.34 142.39 AR
4 12.0 4.200 3.360 ... 878.41 165.63 CA
5 13.6 5.032 3.808 ... 835.50 139.91 CO
6 10.8 4.968 3.888 ... 1068.73 167.02 CT
7 16.2 6.156 4.860 ... 1137.87 151.48 DE
8 5.9 2.006 1.593 ... 1273.89 136.05 DC
9 17.9 3.759 5.191 ... 1160.13 144.18 FL
6.3 词云展示
词云也叫文字云,它帮助我们统计文本中高频出现的词,过滤掉某些常用词(比如“作曲”“作词”),将文本中的重要关键词进行可视化。
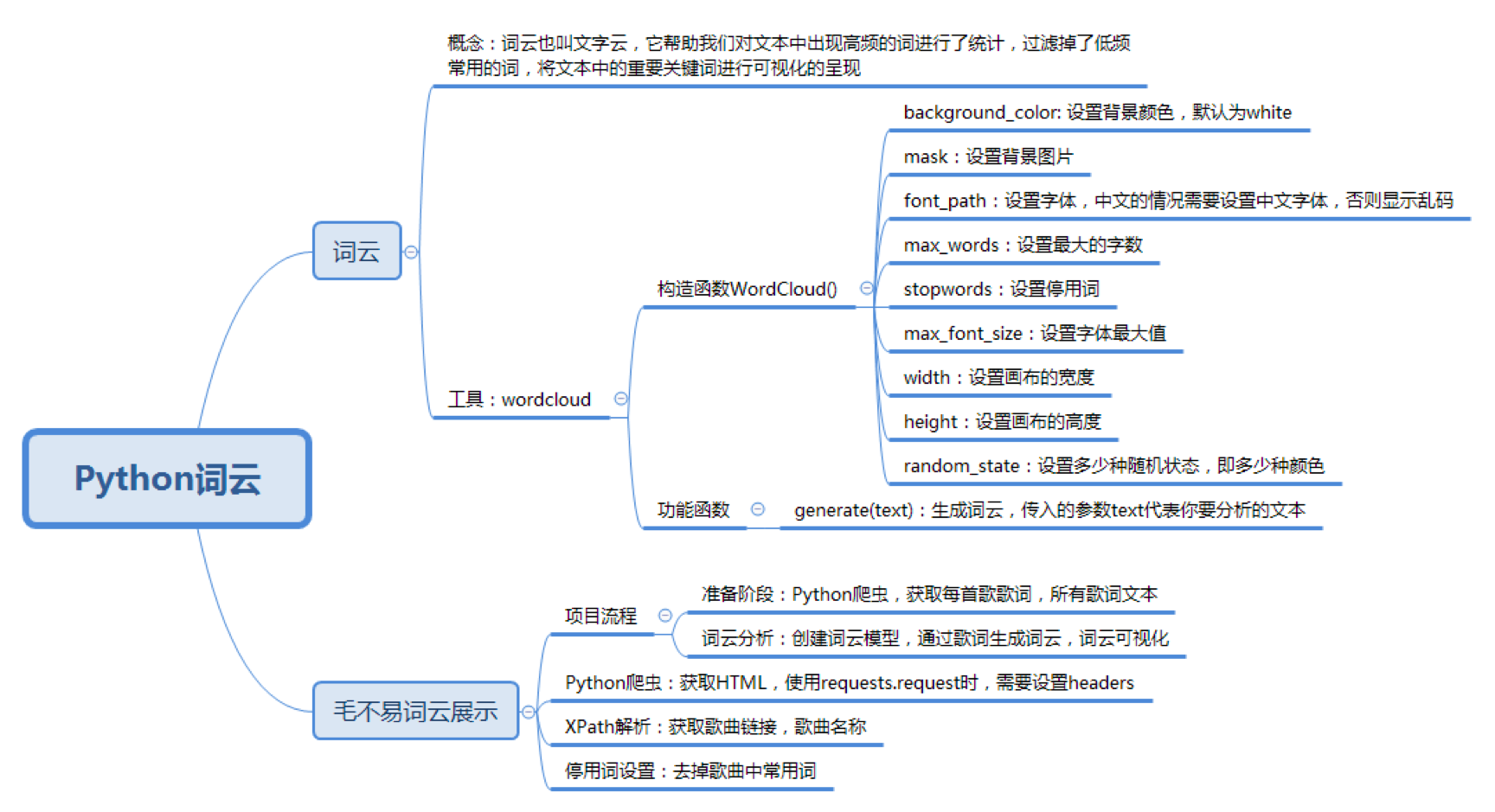
Python 提供了词云工具 WordCloud,使用 pip install wordcloud 安装后,就可以创建一个词云,构造方法如下:
wc = WordCloud(
background_color='white',# 设置背景颜色
mask=backgroud_Image,# 设置背景图片
font_path='./SimHei.ttf', # 设置字体,针对中文的情况需要设置中文字体,否则显示乱码
max_words=100, # 设置最大的字数
stopwords=STOPWORDS,# 设置停用词
max_font_size=150,# 设置字体最大值
width=2000,# 设置画布的宽度
height=1200,# 设置画布的高度
random_state=30# 设置多少种随机状态,即多少种颜色
)
创建好 WordCloud 类之后,就可以使用 wordcloud=generate(text) 方法生成词云,传入的参数 text 代表你要分析的文本,最后使用 wordcloud.tofile(“a.jpg”) 函数,将得到的词云图像直接保存为图片格式文件。也可以使用 Python 的可视化工具 Matplotlib 进行显示,方法如下:
from typing import List
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
from PIL import Image
import numpy as np
# 生成词云
def create_word_cloud(f):
print('根据词频计算词云')
text = " ".join(jieba.cut(f, cut_all=False, HMM=True))
wc = WordCloud(
font_path="./SimHei.ttf", # 字体下载地址是 https://github.com/StellarCN/scp_zh/blob/master/fonts/SimHei.ttf
max_words=100,
width=2000,
height=1200,
)
wordcloud = wc.generate(text)
# 写词云图片
wordcloud.to_file("wordcloud.jpg")
# 显示词云文件
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
f = '数据分析全景图及修炼指南
学习数据挖掘的最佳学习路径是什么?
Python 基础语法:开始你的 Python 之旅
Python 科学计算:NumPy
Python 科学计算:Pandas
学习数据分析要掌握哪些基本概念?
用户画像:标签化就是数据的抽象能力
数据采集:如何自动化采集数据?
数据采集:如何用八爪鱼采集微博上的“D&G”评论?
Python 爬虫:如何自动化下载王祖贤海报?
数据清洗:数据科学家 80% 时间都花费在了这里?
数据集成:这些大号一共 20 亿粉丝?
数据变换:大学成绩要求正态分布合理么?
数据可视化:掌握数据领域的万金油技能
一次学会 Python 数据可视化的 10 种技能'
# 去掉停用词
def remove_stop_words(f):
stop_words = ['学会', '就是', '什么', '要求', '的', '如何']
for stop_word in stop_words:
f = f.replace(stop_word, '')
return f
create_word_cloud(remove_stop_words((f)))
运行效果如下:

网易云歌词 API 获取并生成词云,代码如下:
# -*- coding:utf-8 -*-
# 网易云音乐 通过歌手 ID,生成该歌手的词云
import requests
import sys
import re
import os
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
from PIL import Image
import numpy as np
from lxml import etree
headers = {
'Referer': 'http://music.163.com',
'Host': 'music.163.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'User-Agent': 'Chrome/10'
}
# 得到某一首歌的歌词
def get_song_lyric(headers, lyric_url):
res = requests.request('GET', lyric_url, headers=headers) # 需要传入指定的请求头(headers),否则获取不到完整的信息
if 'lrc' in res.json():
lyric = res.json()['lrc']['lyric']
new_lyric = re.sub(r'[d:.[]]', '', lyric) # 通过正则表达式匹配,将 [] 中数字信息去掉
return new_lyric
else:
return ''
print(res.json())
# 去掉停用词
def remove_stop_words(f):
stop_words = ['作词', '作曲', '编曲', 'Arranger', '录音', '混音', '人声', 'Vocal', '弦乐', 'Keyboard', '键盘', '编辑', '助理',
'Assistants', 'Mixing', 'Editing', 'Recording', '音乐', '制作', 'Producer', '发行', 'produced', 'and',
'distributed']
for stop_word in stop_words:
f = f.replace(stop_word, '')
return f
# 生成词云
def create_word_cloud(f):
print('根据词频,开始生成词云!')
f = remove_stop_words(f)
cut_text = " ".join(jieba.cut(f, cut_all=False, HMM=True))
wc = WordCloud(
font_path="./SimHei.ttf",
max_words=100,
width=2000,
height=1200,
)
print(cut_text)
wordcloud = wc.generate(cut_text)
# 写词云图片
wordcloud.to_file("wordcloud.jpg")
# 显示词云文件
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
# 得到指定歌手页面 热门前 50 的歌曲 ID,歌曲名
def get_songs(artist_id):
page_url = 'https://music.163.com/artist?id=' + artist_id
# 获取网页 HTML
res = requests.request('GET', page_url, headers=headers)
# 用 XPath 解析 前 50 首热门歌曲
html = etree.HTML(res.text)
href_xpath = "//*[@id='hotsong-list']//a/@href" # 通过分析 HTML 代码,能看到一个关键的部分:id=‘hotsong-list’。这个代表热门歌曲列表,本行意为获取这个热门歌曲列表下面所有的链接
name_xpath = "//*[@id='hotsong-list']//a/text()"
hrefs = html.xpath(href_xpath)
names = html.xpath(name_xpath)
# 设置热门歌曲的 ID,歌曲名称
song_ids = []
song_names = []
for href, name in zip(hrefs, names):
song_ids.append(href[9:])
song_names.append(name)
print(href, ' ', name)
return song_ids, song_names
if __name__ == '__main__':
# 设置歌手 ID,毛不易为 12138269
artist_id = '12138269'
[song_ids, song_names] = get_songs(artist_id)
# 所有歌词
all_word = ''
# 获取每首歌歌词
for (song_id, song_name) in zip(song_ids, song_names):
# 歌词 API URL
lyric_url = 'http://music.163.com/api/song/lyric?os=pc&id=' + song_id + '&lv=-1&kv=-1&tv=-1'
lyric = get_song_lyric(headers, lyric_url)
all_word = all_word + ' ' + lyric
print(song_name)
# 根据词频 生成词云
create_word_cloud(all_word)
效果如下:

最后
以上就是会撒娇音响最近收集整理的关于【数据挖掘】3、NumPy与Pandas 清洗、爬虫、 SciKitLearn 变换、可视化一、NumPy二、Pandas三、爬虫采集四、ETL五、数据变换六、可视化的全部内容,更多相关【数据挖掘】3、NumPy与Pandas内容请搜索靠谱客的其他文章。








发表评论 取消回复