一、模板虚拟机配置
1) 设置ip地址
设置ip是保证ip地址与主机名保持一致,如:192.168.10.100 -> hadoop100
2) 设置hostname
修改 /etc/hostname 文件修改
3) 设置hostname 与 ip 地址的映射
映射的配置文件保存在 /etc/hosts 中,网络中的每一台机器都是独立保存这份配置文件的。
4) yum 安装额外的rpm包:yum install -y epel-release (-y表示不需要对逐个包yes) 如果安装的是 最小版的Linux 还需要额外 安装 net-tools 和 vim
5) 关闭防火墙、关闭防火墙开机自动启动:(保证集群之间的稳定连接)
systemctl stop firewalld
systemctl disable firewalld.service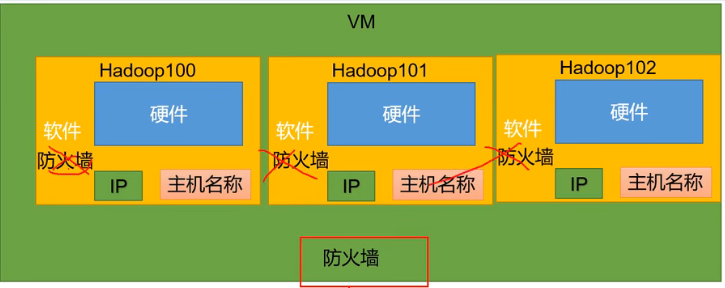
6)添加一个普通用户:atguigu,并修改/etc/sudoers配置文件, 使得sudo 后拥有和root同样的权限,并且不需要使用密码验证
useradd atguigu
vim /etc/sudoers
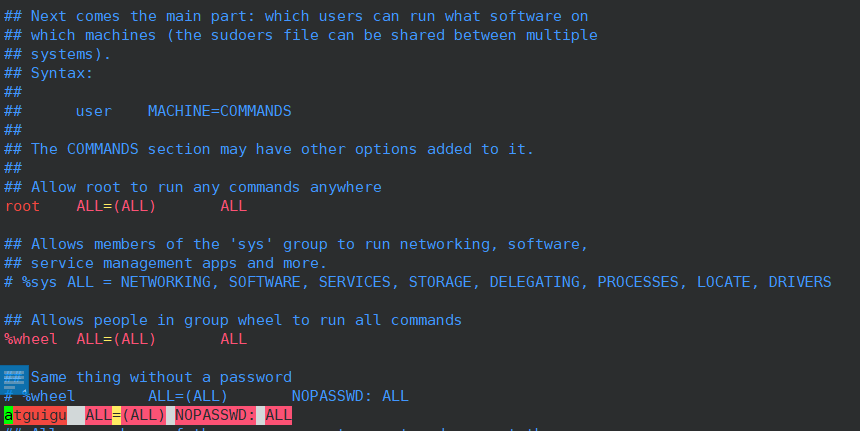
sudo 命令可以使得普通用户获得指定的权限,(限制用户只在某台主机上运行某些命令),可以看做是普通用户向超级管理员申请获取权限。
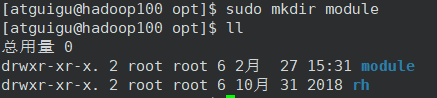
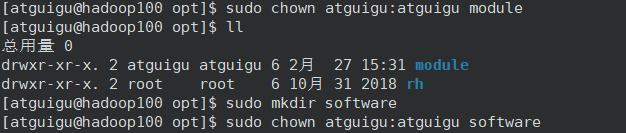
7)在/opt (用于存放第三软件)目录下文件夹module 和 software,并更改所有主和组为atguigu
8)卸载之前安装到的jdk:rpm -qa | grep -i java | xargs -n1 rmp -e --nodeps
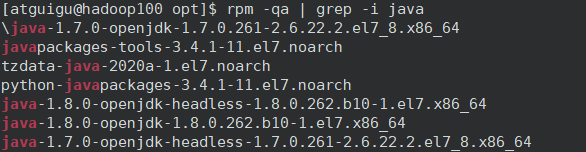
grep -i 忽略大小写
xargs 从 标准 输入 读入 参数. 参数 用 空格(可以 用 双引号 单引号 或 反斜杠 转意) 或者 回车 隔开. 然后 一次 或者 多次 执行 命令: 从标准输入重建并执行命令行
rpm -e 卸载rpm包,–nodeps 忽略依赖检查
9)reboot 重启,模板虚拟机配置完毕
二、虚拟机克隆
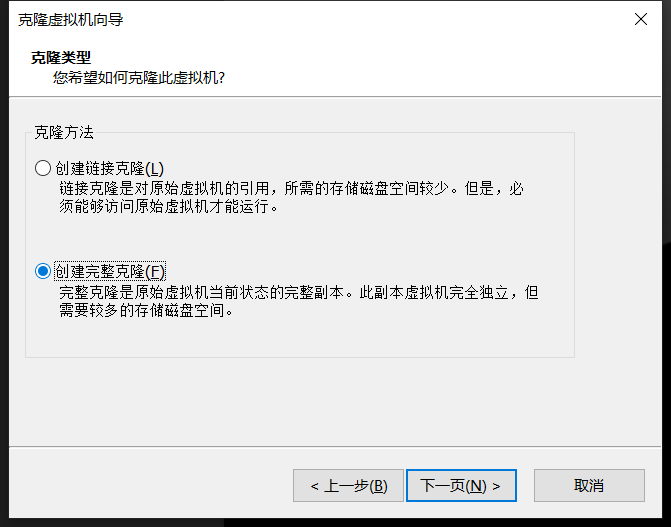
1) 模板机关机后,从VMware中进行完整克隆
2) 每个虚拟机配置ip地址和主机名称
如:hadoop102 ip地址设置为192.168.10.102 hostname 设置为hadoop102
3) 在hadoop 102中安装JDK1.8
将jdk1.8 的linux tar.gz文件传入 之前创建的 software文件夹中
tar -zxvf [解压文件] -C [解压到指定目录] 将jdk安装到module 文件夹
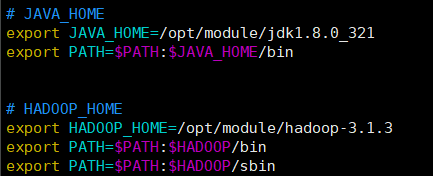
配置环境变量,将JAVA_HOME添加到环境变量中:
Linux环境变量的配置是通过/etc/profile.sh 文件进行配置的。
profile.sh中会对profile.d中的sh文件循环执行
在profile.d中添加新的sh文件,声明全局变量,修改PATH值
sudo vim /etc/profile.d/my_var.sh

重新运行profile: source /etc/profile
4) 在hadoop102上,安装Hadoop
步骤同上,解压、配置环境变量
在配置环境变量中:
三、配置本地运行模式和ssh免密登录
-
将hadoop102上 已经解压过的 hadoop 和 jdk 传输至 hadoop103 和 hadoop 104上:( Secure Copy )
scp — 安全复制(远程文件复制程序)
-r 递归复制整个目录。
scp -r 【本地目录】 【远程用户名@远程主机名:远程目录】反之 pull :
scp -r 【远程用户名@远程主机名:远程目录】【本地目录】
表示从远程主机拉取文件rsync — 远程同步工具(相比于安全复制,只传输差异部分的文件,速度更快,效率更好)
rsync -av 【本地目录】 【远程用户名@远程主机名:远程目录】对于每个服务器都执行rsync 命令显然比较复杂。
创建自己的xsyn.sh ,并将文件所在目录加入PATH即可。
xsyn.sh 执行任务:将参数中的文件 同步到 所有虚拟机下的相同路径中/home/atguigu/bin 是默认加入到$PATH中的,所以在此目录下添加sh文件
# !bin/bash
if [$# -lt 1]
then
echo 请输入参数
exit;
fi
for host in hadoop102 hadoop103 hadoop104
do
echo =================$host====================
for file in $@
do
if [-e $file]
then
#获取文件的完整绝对路径:pwd
pdir=$(cd -P $(dirname $file);pwd)
# -P可以避免软连接目录,跳转到真实目录
#获取文件名称 basename
fname=$(basename $file)
# 在目标服务器下创建相同目录
ssh $host "mkdir -p $pdir"
# ssh命令 远程登录
# -p可以避免目录已经存在
# 将目标文件同步到对应目录下
rsync -av $pdir/$fname $host:$pdir
else
echo $file 不存在
fi
done
done
接下来通过 xsync 将环境变量sh 分发到所有服务器上。
sudo xsync /etc/profile.d/my_var.sh
sudo 后相当于切换为root账户 所以/home/atguigu目录不存在$PATH中
linux中每次的ssh 登录都需要密码验证,接下来设置ssh免密登录:
ssh 加密协议 属于非对称加密通信,原理如下
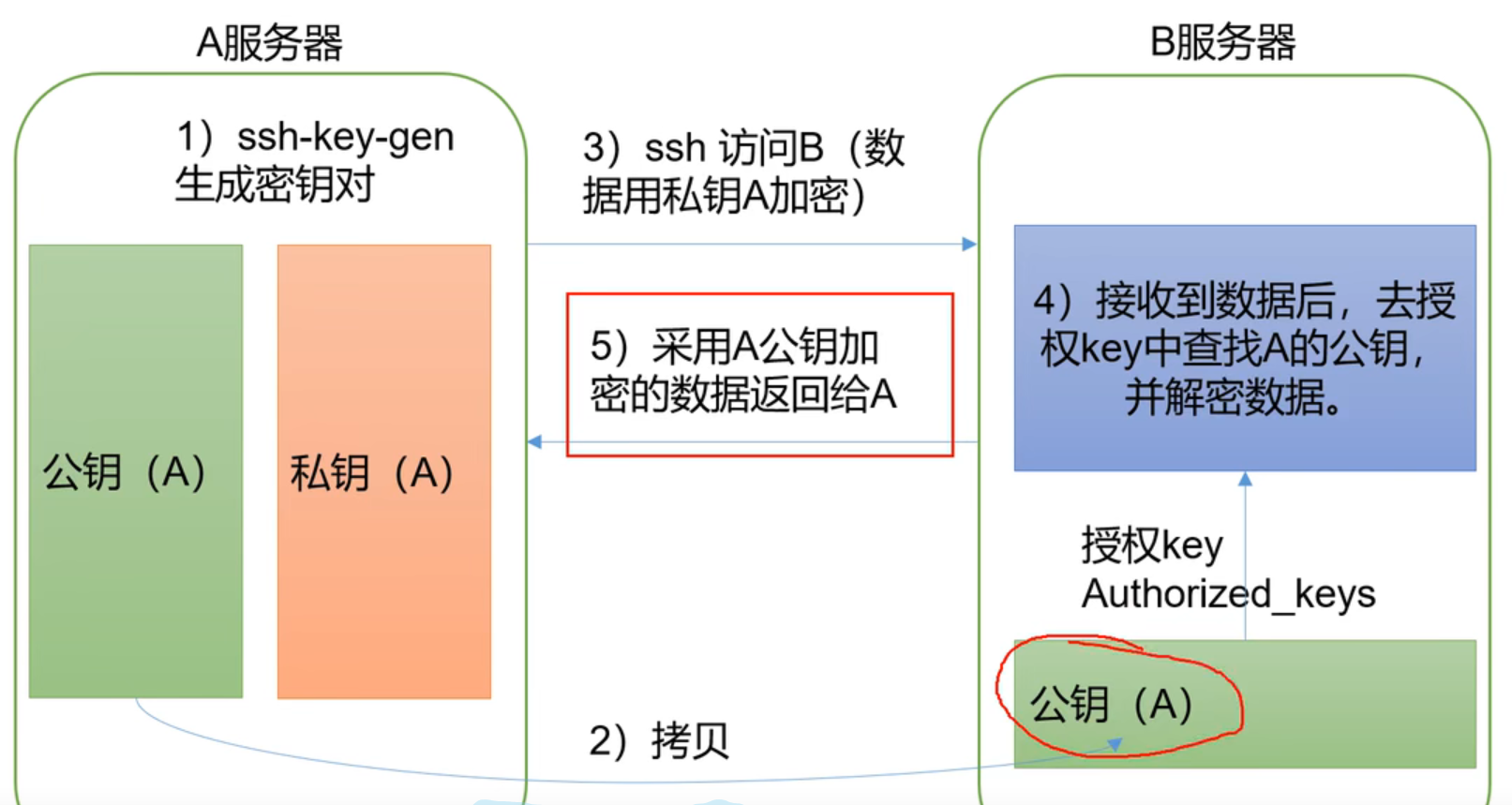
只需要在服务器的.ssh目录下保存公钥,即可实现免密登录。
在/home/atguigu/.ssh目录下执行ssh -keygen -t rsa 会在.ssh/id_rsa 下生成密钥和公钥


将公钥发送给其余服务器:
ssh-copy-id hadoop103
ssh-copy-id hadoop104
免密ssh远程连接设置成功。 接下来在hadoop103和104中同样设置
四、Hadoop集群配置
在配置Hadoop 之前,需要规划好各节点的分工,尽量不要把占用资源量比较大的角色分配到用一个资源上。

Hadoop 的自定义配置文件在 etc/hadoop/etc目录下的四个空的xml文件,将一下配置粘贴到Hadoop102中并下发到所有节点。
1) core-site.xml
<configuration>
<!-- 指定NameNode地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!--指定本地文件存储系统的地址-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!--配置HDFS网页登录的静态用户atguigu-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- snn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
- mapred-site.xml
<configuration>
<!-- 指定MR在yarn运行,默认是本地-->
<property>
<name>mapreduce.framwork.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定MR走Shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ResourceManager地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
</value>
</property>
</configuration>
五、集群的启动
1) 设置workers配置
在etc目录下设置workers参数:
hadoop102
hadoop103
hadoop104
(注意不要加空格 和 空行)
2) 格式化NameNode 节点(第一次运行时):
在hadoop102下执行
hdfs namenode -forma
执行成功的标志:bin目录下出现data 和 logs目录
PS:不要多次格式NameNode节点,每次格式化节点都会产生新的Cluster_ID,导致DataNode节点与NameNode的集群ID不一致,集群不能找到以往数据。如果需要重新格式化NameNode的化,首先停止namenode和datanode进程,并且删除所有节点的data和log目录,然后进行格式化。或者直接修改DataNode的集群ID 使其与NameNode的集群ID一致。
解决办法:https://blog.51cto.com/zyp88/2053031
2)启动Hadoop集群
在hadoop102上(NN) 启动hdfs
start-dfs.sh
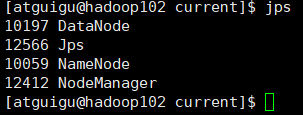
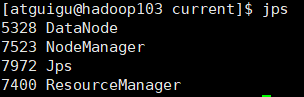
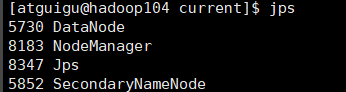
启动成功后在节点 jps,查看角色是否正确(jps 查看java虚拟机线程的工具)
通过浏览器访问192.168.10.102:9870 得到hdfs 的web界面
在hadoop103上(RM)启用yarn
start-yarn.sh
通过浏览器访问192.168.10.103:8088
六、历史服务器配置
mapred.xml
<configuration>
<!-- 指定MR在yarn运行,默认是本地-->
<property>
<name>mapreduce.framwork.name</name>
<value>yarn</value>
</property>
<!-- 指定历史服务器地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 指定历史服务器web地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
</configuration>
重新启用yarn后:
在hadoop102
mapred --daemon start historyserver
七、日志聚集功能的开启
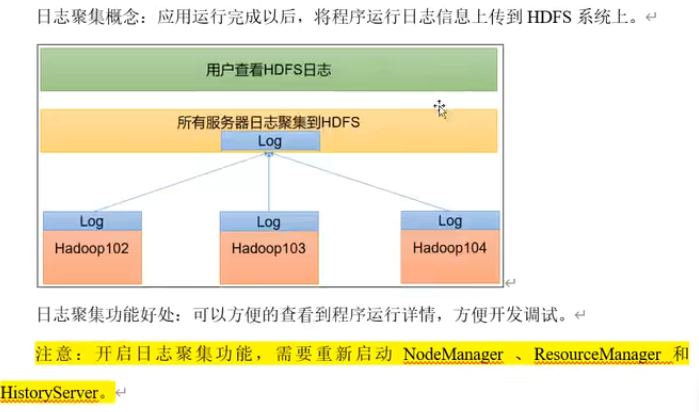
1) 配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定MR走Shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ResourceManager地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
</value>
</property>
<!-- 打开日志聚集-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志服务器地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志七天保留-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
- 分发到所有节点
- 重启历史服务器、yarn
mapred --daemon stop historyserver
stop-yarn.sh
八、Hadoop线程的启动
两种方式启动hadoop 中的线程:
1) 整体启动:start-dfs.sh
2)部分启动:hdfs -daemo start datenode hdfs -daemo stop datenode
脚本一:在项目中,逐个节点的逐个启动线程过于麻烦,可以将启动命令写入到shell脚本中执行
if [ $# -lt 1 ]
then
echo "No Arugument: Please input start/stop"
exit;
fi
case $1 in
"start")
echo "==================Opening Hadoop================"
echo "------------------—Opening HDFS-----------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo "------------------—Opening YARN-----------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo "----------------Opening HistoryServer-----------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo "==================Closing Hadoop================"
echo "----------------Closing HistoryServer-----------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo "------------------—Closing YARN-----------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo "------------------—Closing HDFS-----------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Wrong Arugument"
;;
esac
脚本二:查看所有服务器的jsp
for host in hadoop102 hadoop103 hadoop104
do
echo "=======$host======="
ssh $host "jps"
done
PS : 脚本写完后需要确保脚本的可执行权限,并分发到所有服务器中
九、***Hadoop常用的端口号 与 配置文件
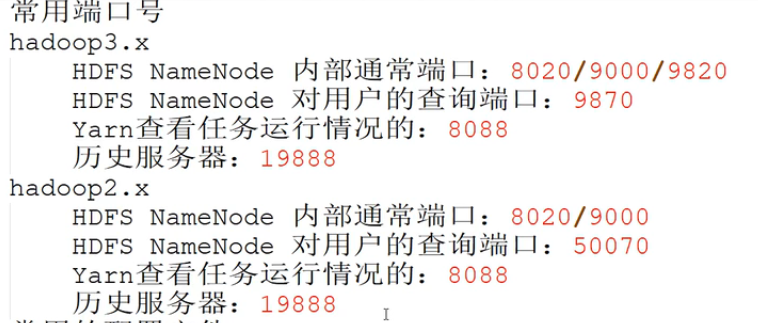

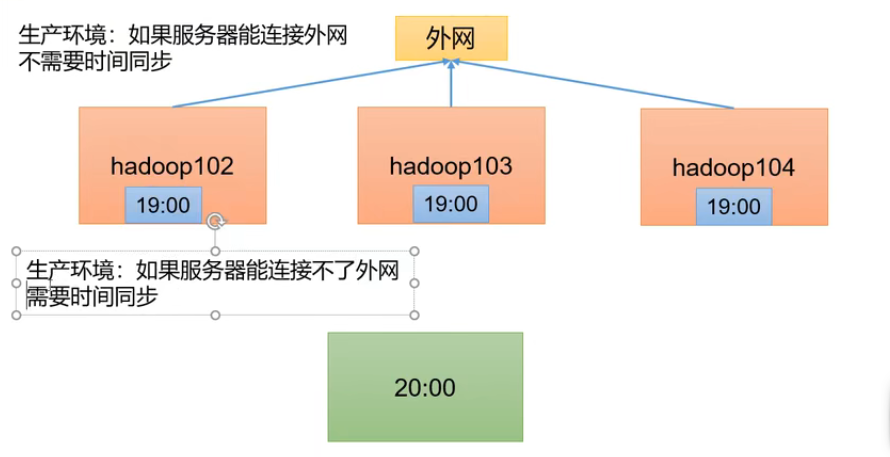
十、集群时间同步 P37
最后
以上就是美好香氛最近收集整理的关于Hadoop 集群搭建二、虚拟机克隆三、配置本地运行模式和ssh免密登录四、Hadoop集群配置五、集群的启动六、历史服务器配置七、日志聚集功能的开启八、Hadoop线程的启动九、***Hadoop常用的端口号 与 配置文件十、集群时间同步 P37的全部内容,更多相关Hadoop内容请搜索靠谱客的其他文章。








发表评论 取消回复