目录
一、MNIST数据集介绍
二、搭建神经网络模型对MNIST手写数据集分类
1.读取数据集
2.数据预处理
3.搭建神经网络
4.测试模型性能
三、报错解决
四、测试运行
一、MNIST数据集介绍
MNIST全称是Mixed National Institute of Standards and Technology database。这是一个非常庞大的手写数字数据库。
这些数据集有两个功能:一个功能是提供了大量的数据作为训练集和验证集,为一些学习人员提供了丰富的样 本信息一一这一点很宝贵,要知道在深度学习领域要想在一个方面有比较深的研究成果, 除了需要具备一定的网络设计和调优能力以外,还有一个就是要有丰富的训练样本。 另一 个功能就是可以形成一个在业内相对有普适性的 Benchmark 比对项目一一既然大家用的数 据集都是一样的,那么每个人设计出来的网络就可以在这些数据集上不断互相比较,从而验证谁家的网络设计得识别率更高。
大多数示例使用手写数字的MNIST数据集[1]。该数据集包含60,000个用于训练的示例和10,000个用于测试的示例。这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28x28像素),其值为0到1。为简单起见,每个图像都被平展并转换为784(28 * 28)个特征的一维numpy数组。

MNIST数据集
二、搭建神经网络模型对MNIST手写数据集分类
搭建神经网络模型对MNIST手写数据集分类并用测试集测试模型性能,详细步骤如下:
1.读取数据集
from scipy.io import loadmat
from keras import models, layers, regularizers
from tensorflow import optimizers
from tensorflow.python.keras.utils.np_utils import to_categorical
test_data = loadmat('python_demo/main/mnist_test.mat') # 读取训练集数据
train_data = loadmat('python_demo/main/mnist_train.mat') # 读取测试集数据
train_x = train_data['train_X']
train_l = train_data['train_labels']
test_x = test_data['test_X']
test_l = test_data['test_labels']2.数据预处理
train_images = train_x.reshape((60000, 28*28)).astype('float') # 训练集图像,二维矩阵压缩成一维向量
train_labels = to_categorical(train_l) # 训练集标签,进行one-hot编码
test_images = test_x.reshape((10000, 28*28)).astype('float')
test_labels = to_categorical(test_l)3.搭建神经网络
# 搭建神经网络
network = models.Sequential() # 训练式模型
network.add(layers.Dense(units=128, activation='relu', input_shape=(28*28, ),
kernel_regularizer=regularizers.l1(0.0001))) # 隐藏层 128个神经元 relu函数 regularizers(正则化 解决过拟合问题)
network.add(layers.Dropout(0.01))
network.add(layers.Dense(units=32, activation='relu', input_shape=(28*28, ),
kernel_regularizer=regularizers.l1(0.0001))) # 增加一个隐藏层优化性能 32个神经元 relu函数
network.add(layers.Dropout(0.01))
network.add(layers.Dense(units=10, activation='softmax')) # 输出层
# 编译步骤
network.compile(optimizer=optimizers.RMSprop(lr=0.001), loss='categorical_crossentropy', metrics=['accuracy'])
# 训练网络 fit函数 epochs表示训练回合 batch_size 每次训练数据的大小
network.fit(train_images, train_labels, epochs=20, batch_size=128, verbose=2)4.测试模型性能
# 测试集测试模型性能
pre = network.predict(test_images[:5])
print(pre, test_labels[:5]) # 测试前5张图片并对比
test_loss, test_accuracy = network.evaluate(test_images, test_labels) # 测试集表现
print("test_loss", test_loss, "test_accuracy", test_accuracy)
三、报错解决
报错解决:ValueError: Shapes (None, 11) and (None, 10) are incompatible
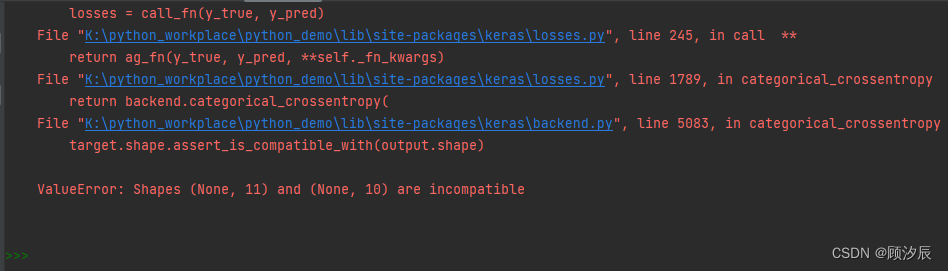
在运行代码时,一直出现这个错误,大意为数据集形状不兼容,即维度不一样,找了很久一直没有找到问题的根源,最后灵机一动,想着打印一下训练集与测试集的标签看看,于是:
print("train_l", train_l)
print("test_l", test_l)发现:
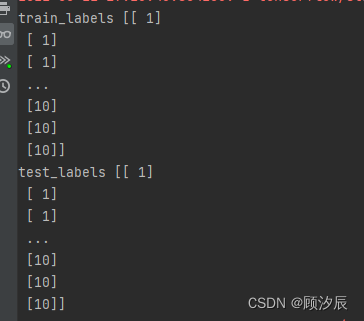
手写数字应该是0-9,为什么会出现10呢?原来是数据集的标签出了问题,0-9的取值变成了了1-10,而将数字1-10进行one-hot编码则会有0至10共11个维度,例如数字1将表示为:[0,1,0,0,0,0,0,0,0,0,0],当然会数据集维度不匹配。提供两种解决方法,
第一种即是更换数据源,可以选择keras的mnist数据集:
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28*28)).astype('float')
train_labels = to_categorical(train_labels)
test_images = test_images.reshape((10000, 28*28)).astype('float')
test_labels = to_categorical(test_labels)第二种则是修改一下数据集标签:
把数字范围改到0-9
for i in range(0, len(train_l)):
train_l[i] = train_l[i]-1
for i in range(0, len(test_l)):
test_l[i] = test_l[i] - 1四、测试运行
run一下,得到如下结果
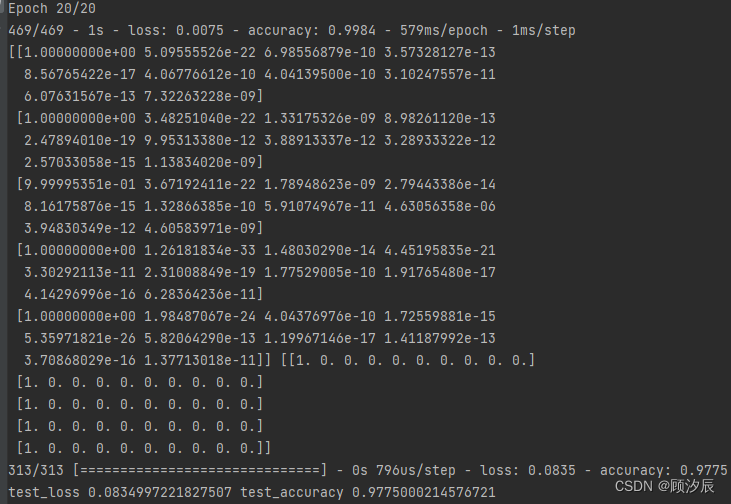
我们可以看到训练集的准确率达到了99.8%,但测试集的准确率只有97左右%,两者之间相差了近3%,出现了明细的过拟合现象,即能够较好地预测训练集数据,但是用来实战效果较差。因此我们需要使用regularizers函数正则化对模型优化一下:
network.add(layers.Dense(units=128, activation='relu', input_shape=(28*28, ),
kernel_regularizer=regularizers.l1(0.0001))) # 隐藏层 128个神经元 relu函数 regularizers(正则化 解决过拟合问题)
network.add(layers.Dropout(0.01))
network.add(layers.Dense(units=32, activation='relu', input_shape=(28*28, ),
kernel_regularizer=regularizers.l1(0.0001))) # 增加一个隐藏层优化性能 32个神经元 relu函数
network.add(layers.Dropout(0.01))
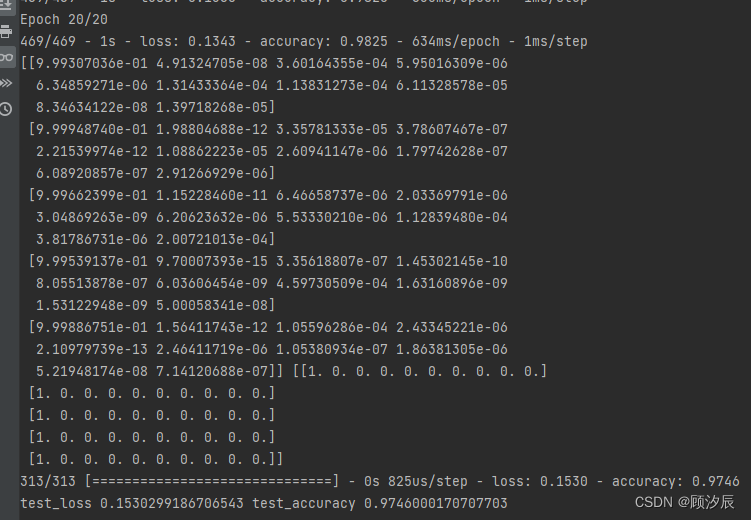
network.add(layers.Dense(units=10, activation='softmax')) # 输出层完成后运行,最后可以得到训练集及测试集的准确率均大概在98%左右:
创作不易,觉得有用的话点个赞吧!

最后
以上就是陶醉魔镜最近收集整理的关于搭建神经网络模型对MNIST手写数字分类并测试模型性能一、MNIST数据集介绍二、搭建神经网络模型对MNIST手写数据集分类三、报错解决四、测试运行的全部内容,更多相关搭建神经网络模型对MNIST手写数字分类并测试模型性能一、MNIST数据集介绍二、搭建神经网络模型对MNIST手写数据集分类三、报错解决四、测试运行内容请搜索靠谱客的其他文章。








发表评论 取消回复