博客作者:凌逆战
博客地址:https://www.cnblogs.com/LXP-Never/p/12774058.html
文章代码:https://github.com/LXP-Never/blog_data/tree/master/tensorflow_model
我一直觉得TensorFlow的深度神经网络代码非常困难且繁琐,对TensorFlow搭建模型也十分困惑,所以我近期阅读了大量的神经网络代码,终于找到了搭建神经网络的规律,各位要是觉得我的文章对你有帮助不妨点个赞,点个关注吧。
我个人把深度学习分为以下步骤:数据处理 --> 模型搭建 --> 构建损失 --> 模型训练 --> 模型评估
我先把代码放出来,然后一点一点来讲


# Author:凌逆战
# -*- encoding:utf-8 -*-
# 修改时间:2020年5月31日
import time
from tensorflow.examples.tutorials.mnist import input_data
from nets.my_alex import alexNet
from ops import *
tf.flags.DEFINE_integer('batch_size', 50, 'batch size, default: 1')
tf.flags.DEFINE_integer('class_num', 10, 'batch size, default: 1')
tf.flags.DEFINE_integer('epochs', 10, 'batch size, default: 1')
tf.flags.DEFINE_float('learning_rate', 1e-4, '初始学习率, 默认: 0.0002')
tf.flags.DEFINE_string('checkpoints_dir', "checkpoints", '保存检查点的地址')
FLAGS = tf.flags.FLAGS
# 从MNIST_data/中读取MNIST数据。当数据不存在时,会自动执行下载
mnist = input_data.read_data_sets('./data', one_hot=True, reshape=False)
# reshape=False (None, 28,28,1) # 用于第一层是卷积层
# reshape=False (None, 784) # 用于第一层是全连接层
# 我们看一下数据的shape
print(mnist.train.images.shape) # 训练数据图片(55000, 28, 28, 1)
print(mnist.train.labels.shape) # 训练数据标签(55000, 10)
print(mnist.test.images.shape) # 测试数据图片(10000, 28, 28, 1)
print(mnist.test.labels.shape) # 测试数据图片(10000, 10)
print(mnist.validation.images.shape) # 验证数据图片(5000, 28, 28, 1)
print(mnist.validation.labels.shape) # 验证数据图片(5000, 784)
def train():
batch_size = FLAGS.batch_size # 一个batch训练多少个样本
batch_nums = mnist.train.images.shape[0] // batch_size # 一个epoch中应该包含多少batch数据
class_num = FLAGS.class_num # 分类类别数
epochs = FLAGS.epochs # 训练周期数
learning_rate = FLAGS.learning_rate # 初始学习率
############ 保存检查点的地址 ############
checkpoints_dir = FLAGS.checkpoints_dir # checkpoints
# 如果检查点不存在,则创建
if not os.path.exists(checkpoints_dir):
os.makedirs(FLAGS.checkpoints_dir)
######################################################
# 创建图 #
######################################################
graph = tf.Graph() # 自定义图
# 在自己的图中定义数据和操作
with graph.as_default():
inputs = tf.placeholder(dtype="float", shape=[None, 28, 28, 1], name='inputs')
labels = tf.placeholder(dtype="float", shape=[None, class_num], name='labels')
# 看个人喜欢,有的人在初始化定义中就定义了learning_rate,有的人喜欢通过feed传learning_rate
learning_rate = tf.placeholder("float", None, name='learning_rate')
# 如果网络结构有dropout层,需要定义keep_probn,如果没有则不需要
# 训练的时候需要,测试的时候需要设置成1
keep_prob = tf.placeholder(dtype="float", name='keep_prob')
############ 搭建模型 ############
logits = alexNet(inputs, class_num, keep_prob=keep_prob) # 使用placeholder搭建模型
############ 损失函数 ############
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits))
tf.add_to_collection('losses', loss)
total_loss = tf.add_n(tf.get_collection("loss")) # total_loss=模型损失+权重正则化损失
############ 模型精度 ############
predict = tf.argmax(logits, 1) # 模型预测结果
accuracy = tf.reduce_mean(tf.cast(tf.equal(predict, tf.argmax(labels, 1)), tf.float32))
############ 优化器 ############
variable_to_train = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES) # 可训练变量列表
# 创建优化器,更新网络参数,最小化loss,
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(learning_rate=learning_rate, # 初始学习率
global_step=global_step,
decay_steps=batch_nums, # 多少步衰减一次
decay_rate=0.1, # 衰减率
staircase=True) # 以阶梯的形式衰减
# 移动平均值更新参数
# train_op = moving_average(loss, learning_rate, global_step)
# adam优化器,adam算法好像会自动衰减学习率,
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss=total_loss,
global_step=global_step,
var_list=variable_to_train)
############ TensorBoard可视化 summary ############
summary_writer = tf.summary.FileWriter(logdir="./logs", graph=graph) # 创建事件文件
tf.summary.scalar(name="losses", tensor=total_loss) # 收集损失值变量
tf.summary.scalar(name="acc", tensor=accuracy) # 收集精度值变量
tf.summary.scalar(name='learning_rate', tensor=learning_rate)
merged_summary_op = tf.summary.merge_all() # 将所有的summary合并为一个op
############ 模型保存和恢复 Saver ############
saver = tf.train.Saver(max_to_keep=5)
######################################################
# 创建会话 #
######################################################
max_acc = 0.
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
with tf.Session(config=config, graph=graph) as sess:
# 加载模型,如果模型存在返回 是否加载成功和训练步数
could_load, checkpoint_step = load_model(sess, saver, FLAGS.checkpoints_dir)
if could_load:
print(" [*] 模型加载成功")
else:
print(" [!] 模型加载失败")
try:
tf.global_variables_initializer().run()
except:
tf.initialize_all_variables().run()
for epoch in range(epochs):
for i in range(batch_nums):
start_time = time.time()
# batch_images = data_X[i * batch_size:(i + 1) * batch_size]
# batch_labels = data_y[i * batch_size:(i + 1) * batch_size]
train_batch_x, train_batch_y = mnist.train.next_batch(batch_size)
# 使用真实数据填充placeholder,运行训练模型和合并变量操作
_, summary, loss, step = sess.run([train_op, merged_summary_op, total_loss, global_step],
feed_dict={inputs: train_batch_x,
labels: train_batch_y,
keep_prob: 0.5})
if step % 100 == 0:
summary_writer.add_summary(summary, step) # 将每次迭代后的变量写入事件文件
summary_writer.flush() # 强制summary_writer将缓存中的数据写入到日志文件中(可选)
############ 可视化打印 ############
print("Epoch:[%2d] [%4d/%4d] time:%4.4f,loss:%.8f" % (
epoch, i, batch_nums, time.time() - start_time, loss))
# 打印一些可视化的数据,损失...
if step % 100 == 0:
acc = sess.run(accuracy, feed_dict={inputs: mnist.validation.images,
labels: mnist.validation.labels,
keep_prob: 1.0})
print("Epoch:[%2d] [%4d/%4d] accuracy:%.8f" % (epoch, i, batch_nums, acc))
############ 保存模型 ############
if acc > max_acc:
max_acc = acc
save_path = saver.save(sess,
save_path=os.path.join(checkpoints_dir, "model.ckpt"),
global_step=step)
tf.logging.info("模型保存在: %s" % save_path)
print("优化完成!")
def main(argv=None):
train()
if __name__ == '__main__':
# logging.basicConfig(level=logging.INFO)
tf.logging.set_verbosity(tf.logging.INFO)
tf.app.run()
# Author:凌逆战
# -*- encoding:utf-8 -*-
# 修改时间:2020年5月31日
import time
from tensorflow.examples.tutorials.mnist import input_data
from nets.my_vgg import VGG16Net
from ops import *
tf.flags.DEFINE_integer('batch_size', 100, 'batch size, default: 1')
tf.flags.DEFINE_integer('class_num', 10, 'batch size, default: 1')
tf.flags.DEFINE_integer('epochs', 10, 'batch size, default: 1')
tf.flags.DEFINE_float('learning_rate', 2e-4, '初始学习率, 默认: 0.0001')
tf.flags.DEFINE_string('checkpoints_dir', "checkpoint", '保存检查点的地址')
FLAGS = tf.flags.FLAGS
# 从MNIST_data/中读取MNIST数据。当数据不存在时,会自动执行下载
mnist = input_data.read_data_sets('./MNIST_data', one_hot=True, reshape=False)
# reshape=False (None, 28,28,1) # 用于第一层是卷积层
# reshape=False (None, 784) # 用于第一层是全连接层
# 我们看一下数据的shape
print(mnist.train.images.shape) # 训练数据图片(55000, 28, 28, 1)
print(mnist.train.labels.shape) # 训练数据标签(55000, 10)
print(mnist.test.images.shape) # 测试数据图片(10000, 28, 28, 1)
print(mnist.test.labels.shape) # 测试数据图片(10000, 10)
print(mnist.validation.images.shape) # 验证数据图片(5000, 28, 28, 1)
print(mnist.validation.labels.shape) # 验证数据图片(5000, 784)
def train():
batch_size = FLAGS.batch_size
batch_nums = mnist.train.images.shape[0] // batch_size # 一个epoch中应该包含多少batch数据
class_num = FLAGS.class_num
epochs = FLAGS.epochs
learning_rate = FLAGS.learning_rate
############ 保存检查点的地址 ############
checkpoints_dir = FLAGS.checkpoints_dir # checkpoints
# 如果检查点不存在,则创建
if not os.path.exists(checkpoints_dir):
os.makedirs(FLAGS.checkpoints_dir)
######################################################
# 创建图 #
######################################################
graph = tf.Graph() # 自定义图
# 在自己的图中定义数据和操作
with graph.as_default():
inputs = tf.placeholder(dtype="float", shape=[None, 28, 28, 1], name='inputs')
labels = tf.placeholder(dtype="float", shape=[None, class_num], name='labels')
############ 搭建模型 ############
logits = VGG16Net(inputs, class_num) # 使用placeholder搭建模型
############ 损失函数 ############
# 计算预测值和真实值之间的误差
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits))
tf.add_to_collection('losses', loss)
total_loss = tf.add_n(tf.get_collection("loss")) # total_loss=模型损失+权重正则化损失
############ 模型精度 ############
predict = tf.argmax(logits, axis=1)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predict, tf.argmax(labels, axis=1)), tf.float32))
############ 优化器 ############
variable_to_train = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES) # 可训练变量列表
# 创建优化器,更新网络参数,最小化loss,
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss=total_loss,
var_list=variable_to_train)
############ TensorBoard可视化 summary ############
summary_writer = tf.summary.FileWriter("./logs", graph=graph) # 创建事件文件
tf.summary.scalar(name="loss", tensor=total_loss) # 收集损失值变量
tf.summary.scalar(name='accuracy', tensor=accuracy) # 收集精度值变量
tf.summary.scalar(name='learning_rate', tensor=learning_rate)
merged_summary_op = tf.summary.merge_all() # 将所有的summary合并为一个op
############ 模型保存和恢复 Saver ############
saver = tf.train.Saver(max_to_keep=5)
######################################################
# 创建会话 #
######################################################
max_acc = 0.
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
with tf.Session(config=config, graph=graph) as sess:
# 加载模型,如果模型存在返回 是否加载成功和训练步数
could_load, checkpoint_step = load_model(sess, saver, FLAGS.checkpoints_dir)
if could_load:
step = checkpoint_step
print(" [*] 模型加载成功")
else:
print(" [!] 模型加载失败")
try:
tf.global_variables_initializer().run()
except:
tf.initialize_all_variables().run()
step = 0
for epoch in range(epochs):
for i in range(batch_nums):
start_time = time.time() # 记录一下开始训练的时间
# batch_images = data_X[i * batch_size:(i + 1) * batch_size]
# batch_labels = data_y[i * batch_size:(i + 1) * batch_size]
train_batch_x, train_batch_y = mnist.train.next_batch(batch_size)
# 使用真实数据填充placeholder,运行训练模型和合并变量操作
_, summary, loss = sess.run([train_op, merged_summary_op, total_loss],
feed_dict={inputs: train_batch_x,
labels: train_batch_y})
if step % 100 == 0:
summary_writer.add_summary(summary, step) # 将每次迭代后的变量写入事件文件
summary_writer.flush() # 强制summary_writer将缓存中的数据写入到日志文件中(可选)
############ 可视化打印 ############
print("Epoch:[%2d] [%4d/%4d] time:%4.4f,loss:%.8f" % (
epoch, i, batch_nums, time.time() - start_time, loss))
# 打印一些可视化的数据,损失...
# if np.mod(step, 100) == 1
if step % 100 == 0:
acc = sess.run(accuracy, {inputs: mnist.validation.images,
labels: mnist.validation.labels})
print("Epoch:[%2d] [%4d/%4d],acc:%.8f" % (epoch, i, batch_nums, acc))
############ 保存模型 ############
if acc > max_acc:
max_acc = acc
save_path = saver.save(sess,
save_path=os.path.join(checkpoints_dir, "model.ckpt"),
global_step=step)
# logging.info("模型保存在: %s" % save_path)
tf.logging.info("模型保存在: %s" % save_path)
step += 1
print("优化完成!")
def main(argv=None):
train()
if __name__ == '__main__':
# logging.basicConfig(level=logging.INFO)
tf.logging.set_verbosity(tf.logging.INFO)
tf.app.run()
数据处理
数据处理因为每个专业领域的原因各不相同,而这不同点也是各位论文创新点的新方向。不同的我没法讲,但我总结了几点相同的地方——batch数据生成。因为深度学习模型需要一个batch一个batch的喂数据进行训练,所以我们的数据必须是batch的形式,这里衍生了三点问题
- 通过代码批量读取数据,
- 如何生成batch数据:由于篇幅过长,实在有很多地方要介绍和详述,我把这一块内容移到了这篇文章《TensorFlow读取数据的三种方法》中
- 数据的shape:我举两个例子让大家理解:图片数据为4维 (batch_size, height,width, channels),序列数据为3维 (batch_size, time_steps, input_size),
- 不同的shape处理方法不同,选择神经网络模型单元也不同。我会在后面细讲
模型搭建
阅读这一节我默认大家已经学会了数据的batch读取了。
模型搭建这一步很像我们小时候玩的搭积木,我这里以经典神经网络模型VGG、Alex、ResNet、Google Inception Net为例讲解,大家看代码看多了也会很简单的就找到,当然我是有一点私心的,我想把这些经典的网络在这篇文章做一个tensorflow实现汇总,我细讲第一个,大家可能看一个例子就懂了,看懂了就直接往下看,看不懂就多看几个。
LeNet5模型
论文:1998_LeNet_Gradient-Based Learning Applied to Document Recognition
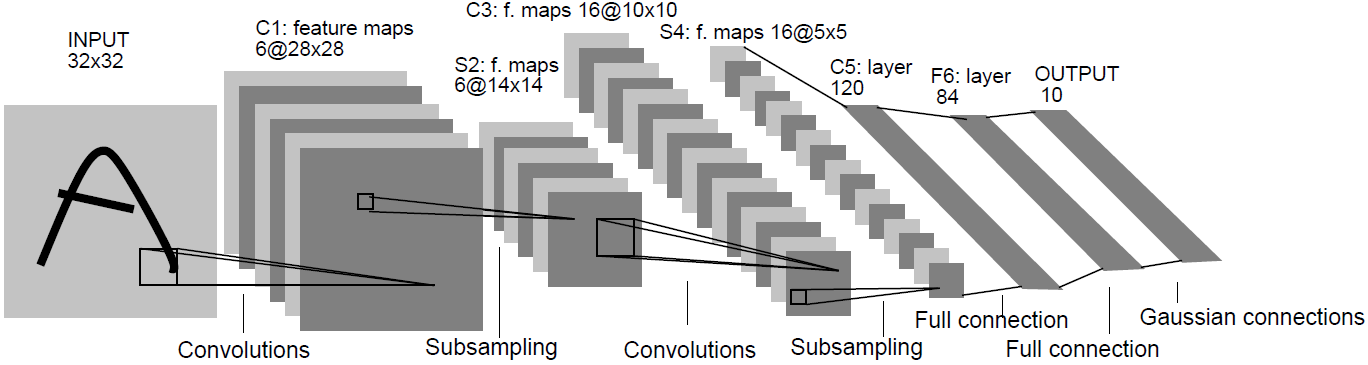
下面我们定义一个LeNet5模型,我们先定义需要用到的神经网络单元,相同的代码尽量封装成函数的形式以节省代码量和简洁代码
def conv(input, kernel_size, output_size, stride, init_bias=0.0, padding="SAME", name=None, wd=None):
input_size = input.shape[-1]
conv_weights = tf.get_variable(name='weights',
shape=[kernel_size, kernel_size, input_size, output_size],
initializer=tf.truncated_normal_initializer(stddev=0.1),
dtype=tf.float32)
conv_biases = tf.get_variable(name='biases',
shape=[output_size],
initializer=tf.constant_initializer(init_bias),
dtype=tf.float32)
if wd is not None:
# wd 0.004
# tf.nn.l2_loss(var)=sum(t**2)/2
weight_decay = tf.multiply(tf.nn.l2_loss(conv_weights), wd, name='weight_loss')
tf.add_to_collection('losses', weight_decay)
conv_layer = tf.nn.conv2d(input, conv_weights, [1, stride, stride, 1], padding=padding, name=name) # 卷积操作
conv_layer = tf.nn.bias_add(conv_layer, conv_biases) # 加上偏置项
conv_layer = tf.nn.relu(conv_layer) # relu激活函数
return conv_layer
def fc(input, output_size, init_bias=0.0, activeation_func=True, wd=None):
input_shape = input.get_shape().as_list()
# 创建 全连接权重 变量
fc_weights = tf.get_variable(name="weights",
shape=[input_shape[-1], output_size],
initializer=tf.truncated_normal_initializer(stddev=0.1),
dtype=tf.float32)
if wd is not None:
# wd 0.004
# tf.nn.l2_loss(var)=sum(t**2)/2
weight_decay = tf.multiply(tf.nn.l2_loss(fc_weights), wd, name='weight_loss')
tf.add_to_collection('losses', weight_decay)
# 创建 全连接偏置 变量
fc_biases = tf.get_variable(name="biases",
shape=[output_size],
initializer=tf.constant_initializer(init_bias),
dtype=tf.float32)
fc_layer = tf.matmul(input, fc_weights) # 全连接计算
fc_layer = tf.nn.bias_add(fc_layer, fc_biases) # 加上偏置项
if activeation_func:
fc_layer = tf.nn.relu(fc_layer) # rele激活函数
return fc_layer
然后利用我们搭建的神经网络单元,搭建LeNet5神经网络模型
# 训练时:keep_prob=0.5
# 测试时:keep_prob=1.0
def leNet(inputs, class_num, keep_prob=0.5):
# 第一层 卷积层 conv1
with tf.variable_scope('layer1-conv1'):
conv1 = conv(input=inputs, kernel_size=5, output_size=32, stride=1, init_bias=0.0, name="layer1-conv1",
padding="SAME")
# 第二层 池化层
with tf.name_scope('layer2-pool1'):
pool1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 第三层 卷积层 conv2
with tf.variable_scope('layer3-conv2'):
conv2 = conv(input=pool1, kernel_size=5, output_size=64, stride=1, init_bias=0.0, name="layer3-conv2",
padding="SAME")
# 第四层 池化层
with tf.name_scope('layer4-pool2'):
pool2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 后面要做全连接,因此要把数据变成2维
# pool_shape = pool2.get_shape().as_list()
pool_shape = pool2.shape
flatten = tf.reshape(pool2, [-1, pool_shape[1] * pool_shape[2] * pool_shape[3]])
with tf.variable_scope('layer5-fcl'):
fc1 = fc(input=flatten, output_size=512, init_bias=0.1, activeation_func=tf.nn.relu, wd=None)
fc1 = tf.nn.dropout(fc1, keep_prob=keep_prob, name="dropout1")
with tf.variable_scope('layer6-fc2'):
logit = fc(input=fc1, output_size=class_num, init_bias=0.1, activeation_func=False, wd=None)
return logit
Alex模型
论文:2012_Alex_ImageNet Classification with Deep Convolutional Neural Networks
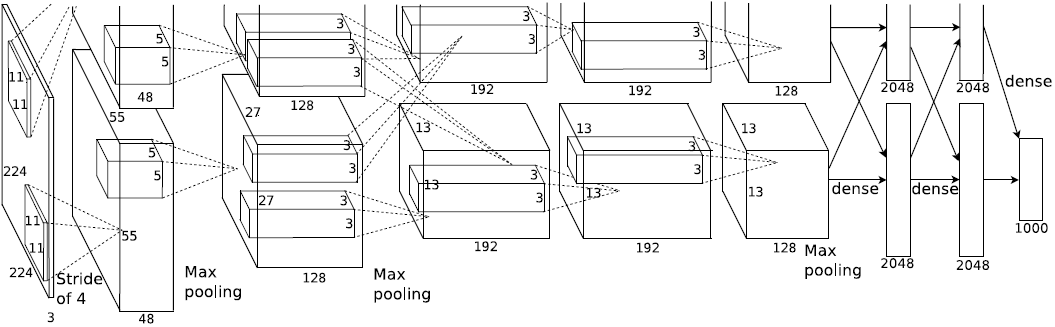
下面我们定义一个Alex模型,我们先定义需要用到的神经网络单元,相同的代码尽量封装成函数的形式以节省代码量和简洁代码
def conv(input, kernel_size, output_size, stride, init_bias=0.0, padding="SAME", name=None, wd=None):
input_size = input.shape[-1]
conv_weights = tf.get_variable(name='weights',
shape=[kernel_size, kernel_size, input_size, output_size],
initializer=tf.random_normal_initializer(mean=0, stddev=0.01),
dtype=tf.float32)
if wd is not None:
# wd 0.004
# tf.nn.l2_loss(var)=sum(t**2)/2
weight_decay = tf.multiply(tf.nn.l2_loss(conv_weights), wd, name='weight_loss')
tf.add_to_collection('losses', weight_decay)
conv_biases = tf.get_variable(name='biases',
shape=[output_size],
initializer=tf.constant_initializer(init_bias),
dtype=tf.float32)
conv_layer = tf.nn.conv2d(input, conv_weights, [1, stride, stride, 1], padding=padding, name=name) # 卷积操作
conv_layer = tf.nn.bias_add(conv_layer, conv_biases) # 加上偏置项
conv_layer = tf.nn.relu(conv_layer) # relu激活函数
return conv_layer
def fc(input, output_size, init_bias=0.0, activeation_func=True, wd=None):
input_shape = input.get_shape().as_list()
# 创建 全连接权重 变量
fc_weights = tf.get_variable(name="weights",
shape=[input_shape[-1], output_size],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.01),
dtype=tf.float32)
if wd is not None:
# wd 0.004
# tf.nn.l2_loss(var)=sum(t**2)/2
weight_decay = tf.multiply(tf.nn.l2_loss(fc_weights), wd, name='weight_loss')
tf.add_to_collection('losses', weight_decay)
# 创建 全连接偏置 变量
fc_biases = tf.get_variable(name="biases",
shape=[output_size],
initializer=tf.constant_initializer(init_bias),
dtype=tf.float32)
fc_layer = tf.matmul(input, fc_weights) # 全连接计算
fc_layer = tf.nn.bias_add(fc_layer, fc_biases) # 加上偏置项
if activeation_func:
fc_layer = tf.nn.relu(fc_layer) # rele激活函数
return fc_layer
def LRN(input, depth_radius=2, alpha=0.0001, beta=0.75, bias=1.0):
"""Local Response Normalization 局部响应归一化"""
return tf.nn.local_response_normalization(input, depth_radius=depth_radius, alpha=alpha,
beta=beta, bias=bias)
然后利用我们搭建的神经网络单元,搭建Alex神经网络模型
def alexNet(inputs, class_num, keep_prob=0.5):
# 第一层卷积层 conv1
with tf.variable_scope("conv1"):
conv1 = conv(input=inputs, kernel_size=7, output_size=96, stride=3, init_bias=0.0, name="conv1", padding="SAME")
conv1 = LRN(conv1)
conv1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name="pool1")
# 第二层卷积层 conv2
with tf.variable_scope("conv2"):
conv2 = conv(input=conv1, kernel_size=7, output_size=96, stride=3, init_bias=1.0, name="conv2", padding="SAME")
conv2 = LRN(conv2)
conv2 = tf.nn.max_pool(conv2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name="pool2")
# 第三层卷积层 conv3
with tf.variable_scope("conv3"):
conv3 = conv(input=conv2, kernel_size=7, output_size=96, stride=3, init_bias=0.0, name="conv3", padding="SAME")
# 第四层卷积层 conv4
with tf.variable_scope("conv4"):
conv4 = conv(input=conv3, kernel_size=7, output_size=96, stride=3, init_bias=1.0, name="conv4", padding="SAME")
# 第五层卷积层 conv5
with tf.variable_scope("conv5"):
conv5 = conv(input=conv4, kernel_size=3, output_size=256, stride=1, init_bias=1.0, name="conv5")
conv5 = tf.nn.max_pool(conv5, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name="pool5")
conv5_shape = conv5.shape # 后面做全连接,所以要把shape改成2维
# shape=[batch, dim]
flatten = tf.reshape(conv5, [-1, conv5_shape[1] * conv5_shape[2] * conv5_shape[3]])
# 第一层全连接层 fc1
with tf.variable_scope("fc1"):
fc1 = fc(input=flatten, output_size=4096, init_bias=1.0, activeation_func=tf.nn.relu, wd=None)
fc1 = tf.nn.dropout(fc1, keep_prob=keep_prob, name="dropout1")
# 第一层全连接层 fc2
with tf.variable_scope("fc2"):
fc2 = fc(input=fc1, output_size=4096, init_bias=1.0, activeation_func=tf.nn.relu, wd=None)
fc2 = tf.nn.dropout(fc2, keep_prob=keep_prob, name="dropout1")
# 第一层全连接层 fc3
with tf.variable_scope("fc3"):
logit = fc(input=fc2, output_size=class_num, init_bias=1.0, activeation_func=False, wd=None)
return logit # 模型输出
VGG模型
论文:2014_VGG_Very Deep Convolutional Networks for Large-Scale Image Recognition
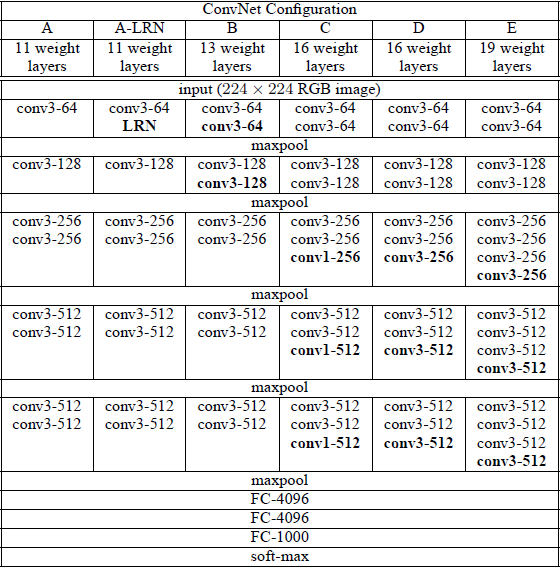
VGG有两个比较有名的网络:VGG16、VGG19,我在这里搭建VGG16,有兴趣的朋友可以按照上面的模型结构自己用TensorFlow搭建VGG19模型
下面我们定义一个VGG16模型,和前面一样,我们先定义需要用到的神经网络单元,相同的代码尽量封装成函数的形式以节省代码量和简洁代码
因为模型中同一个变量域中包含多个卷积操作,因此在卷积函数中套一层变量域
def conv(inputs, scope_name, kernel_size, output_size, stride, init_bias=0.0, padding="SAME", wd=None):
input_size = int(inputs.get_shape()[-1])
with tf.variable_scope(scope_name):
conv_weights = tf.get_variable(name='weights',
shape=[kernel_size, kernel_size, input_size, output_size],
dtype=tf.float32,
initializer=tf.truncated_normal_initializer(mean=0.0, stddev=1e-1))
if wd is not None:
# tf.nn.l2_loss(var)=sum(t**2)/2
weight_decay = tf.multiply(tf.nn.l2_loss(conv_weights), wd, name='weight_loss')
tf.add_to_collection('losses', weight_decay)
conv_biases = tf.get_variable(name='biases',
shape=[output_size],
dtype=tf.float32,
initializer=tf.constant_initializer(init_bias))
conv_layer = tf.nn.conv2d(inputs, conv_weights, [1, stride, stride, 1], padding=padding, name=scope_name)
conv_layer = tf.nn.bias_add(conv_layer, conv_biases)
conv_layer = tf.nn.relu(conv_layer)
return conv_layer
def fc(inputs, scope_name, output_size, init_bias=0.0, activeation_func=True, wd=None):
input_shape = inputs.get_shape().as_list()
with tf.variable_scope(scope_name):
# 创建 全连接权重 变量
fc_weights = tf.get_variable(name="weights",
shape=[input_shape[-1], output_size],
dtype=tf.float32,
initializer=tf.truncated_normal_initializer(mean=0.0, stddev=1e-1))
if wd is not None:
# wd 0.004
# tf.nn.l2_loss(var)=sum(t**2)/2
weight_decay = tf.multiply(tf.nn.l2_loss(fc_weights), wd, name='weight_loss')
tf.add_to_collection('losses', weight_decay)
# 创建 全连接偏置 变量
fc_biases = tf.get_variable(name="biases",
shape=[output_size],
dtype=tf.float32,
initializer=tf.constant_initializer(init_bias),
trainable=True)
fc_layer = tf.matmul(inputs, fc_weights) # 全连接计算
fc_layer = tf.nn.bias_add(fc_layer, fc_biases) # 加上偏置项
if activeation_func:
fc_layer = tf.nn.relu(fc_layer) # rele激活函数
return fc_layer
然后利用我们搭建的神经网络单元,搭建VGG16神经网络模型
def VGG16Net(inputs, class_num):
with tf.variable_scope("conv1"):
# conv1_1 [conv3_64]
conv1_1 = conv(inputs=inputs, scope_name="conv1_1", kernel_size=3, output_size=64, stride=1,
init_bias=0.0, padding="SAME")
# conv1_2 [conv3_64]
conv1_2 = conv(inputs=conv1_1, scope_name="conv1_2", kernel_size=3, output_size=64, stride=1,
init_bias=0.0, padding="SAME")
pool1 = tf.nn.max_pool(conv1_2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool1')
with tf.variable_scope("conv2"):
# conv2_1
conv2_1 = conv(inputs=pool1, scope_name="conv2_1", kernel_size=3, output_size=128, stride=1,
init_bias=0.0, padding="SAME")
# conv2_2
conv2_2 = conv(inputs=conv2_1, scope_name="conv2_2", kernel_size=3, output_size=128, stride=1,
init_bias=0.0, padding="SAME")
pool2 = tf.nn.max_pool(conv2_2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool2')
with tf.variable_scope("conv3"):
# conv3_1
conv3_1 = conv(inputs=pool2, scope_name="conv3_1", kernel_size=3, output_size=256, stride=1,
init_bias=0.0, padding="SAME")
# conv3_2
conv3_2 = conv(inputs=conv3_1, scope_name="conv3_2", kernel_size=3, output_size=256, stride=1,
init_bias=0.0, padding="SAME")
# conv3_3
conv3_3 = conv(inputs=conv3_2, scope_name="conv3_3", kernel_size=3, output_size=256, stride=1,
init_bias=0.0, padding="SAME")
pool3 = tf.nn.max_pool(conv3_3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool3')
with tf.variable_scope("conv4"):
# conv4_1
conv4_1 = conv(inputs=pool3, scope_name="conv4_1", kernel_size=3, output_size=512, stride=1,
init_bias=0.0, padding="SAME")
# conv4_2
conv4_2 = conv(inputs=conv4_1, scope_name="conv4_2", kernel_size=3, output_size=512, stride=1,
init_bias=0.0, padding="SAME")
# conv4_3
conv4_3 = conv(inputs=conv4_2, scope_name="conv4_3", kernel_size=3, output_size=512, stride=1,
init_bias=0.0, padding="SAME")
pool4 = tf.nn.max_pool(conv4_3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool4')
with tf.variable_scope("conv5"):
# conv5_1
conv5_1 = conv(inputs=pool4, scope_name="conv4_1", kernel_size=3, output_size=512, stride=1,
init_bias=0.0, padding="SAME")
# conv5_2
conv5_2 = conv(inputs=conv5_1, scope_name="conv4_2", kernel_size=3, output_size=512, stride=1,
init_bias=0.0, padding="SAME")
# conv5_3
conv5_3 = conv(inputs=conv5_2, scope_name="conv4_3", kernel_size=3, output_size=512, stride=1,
init_bias=0.0, padding="SAME")
pool5 = tf.nn.max_pool(conv5_3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool4')
input_shape = pool5.get_shape().as_list() # 后面做全连接,所以要把shape改成2维
# shape=[batch, dim]
flatten = tf.reshape(pool5, [-1, input_shape[1] * input_shape[2] * input_shape[3]])
fc1 = fc(inputs=flatten, scope_name="fc1", output_size=4096, init_bias=1.0, activeation_func=True)
fc2 = fc(inputs=fc1, scope_name="fc2", output_size=4096, init_bias=1.0, activeation_func=True)
fc3 = fc(inputs=fc2, scope_name="fc3", output_size=class_num, init_bias=1.0, activeation_func=True)
return fc3
上图中有一个softmax层,我们也可以定义出来
class_num = 1000
# placeholder 定义
inputs = tf.placeholder(dtype="float", shape=[None, 28, 28, 3], name='inputs')
labels = tf.placeholder(dtype="float", shape=[None, class_num], name='labels')
learning_rate = tf.placeholder("float", None, name='learning_rate')
logits = VGG16Net(inputs)
probs = tf.nn.softmax(logits)
ResNet模型
论文:
- 2016_ResNet_Deep Residual Learning for Image Recognition
- 2016_ResNet_Identity Mappings in Deep Residual Networks
ResNet的网络结构如下图所示
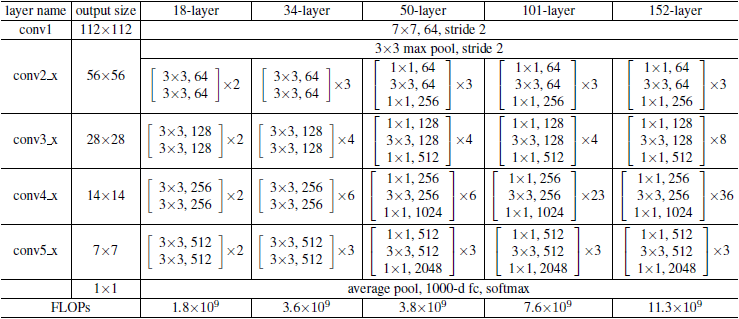
我们先定义需要用到的神经网络单元
def batch_normalization(inputs, output_size):
mean, variance = tf.nn.moments(inputs, axes=[0, 1, 2]) # 计算均值和方差
beta = tf.get_variable('beta', output_size, tf.float32, initializer=tf.zeros_initializer)
gamma = tf.get_variable('gamma', output_size, tf.float32, initializer=tf.ones_initializer)
bn_layer = tf.nn.batch_normalization(inputs, mean, variance, beta, gamma, 0.001)
return bn_layer
def conv(input, kernel_size, output_size, stride, padding="SAME", wd=None):
input_size = input.shape[-1]
conv_weights = tf.get_variable(name='weights',
shape=[kernel_size, kernel_size, input_size, output_size],
dtype=tf.float32,
initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.1),
regularizer=tf.contrib.layers.l2_regularizer(0.00004)) # 正则损失衰减率0.000004
conv_layer = tf.nn.conv2d(input, conv_weights, [1, stride, stride, 1], padding=padding) # 卷积操作
batch_norm = batch_normalization(conv_layer, output_size)
conv_output = tf.nn.relu(batch_norm) # relu激活函数
return conv_output
def fc(input, output_size, activeation_func=True):
input_shape = input.shape[-1]
# 创建 全连接权重 变量
fc_weights = tf.get_variable(name="weights",
shape=[input_shape, output_size],
initializer=tf.truncated_normal_initializer(stddev=0.01),
dtype=tf.float32,
regularizer=tf.contrib.layers.l2_regularizer(0.01))
# 创建 全连接偏置 变量
fc_biases = tf.get_variable(name="biases",
shape=[output_size],
initializer=tf.zeros_initializer,
dtype=tf.float32)
fc_layer = tf.matmul(input, fc_weights) # 全连接计算
fc_layer = tf.nn.bias_add(fc_layer, fc_biases) # 加上偏置项
if activeation_func:
fc_layer = tf.nn.relu(fc_layer) # rele激活函数
return fc_layer
def block(input, n, output_size, change_first_stride, bottleneck):
if n == 0 and change_first_stride:
stride = 2
else:
stride = 1
if bottleneck:
with tf.variable_scope('a'):
conv_a = conv(input=input, kernel_size=1, output_size=output_size, stride=stride, padding="SAME")
conv_a = batch_normalization(conv_a, output_size)
conv_a = tf.nn.relu(conv_a)
with tf.variable_scope('b'):
conv_b = conv(input=conv_a, kernel_size=3, output_size=output_size, stride=1, padding="SAME")
conv_b = batch_normalization(conv_b, output_size)
conv_b = tf.nn.relu(conv_b)
with tf.variable_scope('c'):
conv_c = conv(input=conv_b, kernel_size=1, output_size=output_size * 4, stride=1, padding="SAME")
output = batch_normalization(conv_c, output_size * 4)
else:
with tf.variable_scope('A'):
conv_A = conv(input=input, kernel_size=3, output_size=output_size, stride=stride, padding="SAME")
conv_A = batch_normalization(conv_A, output_size)
conv_A = tf.nn.relu(conv_A)
with tf.variable_scope('B'):
conv_B = conv(input=conv_A, kernel_size=3, output_size=output_size, stride=1, padding="SAME")
output = batch_normalization(conv_B, output_size)
if input.shape == output.shape:
with tf.variable_scope('shortcut'):
shortcut = input # shortcut
else:
with tf.variable_scope('shortcut'):
shortcut = conv(input=input, kernel_size=1, output_size=output_size * 4, stride=1, padding="SAME")
shortcut = batch_normalization(shortcut, output_size * 4)
return tf.nn.relu(output + shortcut)
然后我们定义神经网络框架
def inference(inputs, class_num, num_blocks=[3, 4, 6, 3], bottleneck=True):
# data[1, 224, 224, 3]
# 我们尝试搭建50层ResNet
with tf.variable_scope('conv1'):
conv1 = conv(input=inputs, kernel_size=7, output_size=64, stride=2, padding="SAME")
conv1 = batch_normalization(inputs=conv1, output_size=64)
conv1 = tf.nn.relu(conv1)
with tf.variable_scope('conv2_x'):
conv_output = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME')
for n in range(num_blocks[0]):
with tf.variable_scope('block%d' % (n + 1)):
conv_output = block(conv_output, n, output_size=64, change_first_stride=False, bottleneck=bottleneck)
with tf.variable_scope('conv3_x'):
for n in range(num_blocks[1]):
with tf.variable_scope('block%d' % (n + 1)):
conv_output = block(conv_output, n, output_size=128, change_first_stride=True, bottleneck=bottleneck)
with tf.variable_scope('conv4_x'):
for n in range(num_blocks[2]):
with tf.variable_scope('block%d' % (n + 1)):
conv_output = block(conv_output, n, output_size=256, change_first_stride=True, bottleneck=bottleneck)
with tf.variable_scope('conv5_x'):
for n in range(num_blocks[3]):
with tf.variable_scope('block%d' % (n + 1)):
conv_output = block(conv_output, n, output_size=512, change_first_stride=True, bottleneck=bottleneck)
output = tf.reduce_mean(conv_output, reduction_indices=[1, 2], name="avg_pool")
with tf.variable_scope('fc'):
output = fc(output, class_num, activeation_func=False)
return output
Google Inception Net模型
Inception Net模型 以后再更新吧,如果这篇文章对大家有用,欢迎大家催促我。
RNN模型
Tensorflow中的CNN变数很少,而RNN却丰富多彩,不仅在RNN Cell上有很多种、在实现上也有很多种,在用法上更是花样百出。
五个基本的RNN Cell:RNNCell、BasicRNNCell、LSTMCell、BasicLSTMCell、GRUCell
RNN Cell的封装和变形:MultiRNNCell(多层RNN)、DropoutWrapper、ResidualWrapper、DeviceWrapper
四种架构 (static+dynamic)*(单向+双向)=4:static_rnn(静态RNN)、dynamic_rnn(动态RNN)、static_bidirectional_rnn(静态双向RNN)、bidirectional_dynamic_rnn(动态双向RNN)
五种手法 (one+many)*(one+many) +1=5:
- one to one(1 vs 1):输入一个,输出一个。其实和全连接神经网络并没有什么区别,这一类别算不得是 RNN。
- one to many(1 vs N):输入一个,输出多个。图像标注,输入一个图片,得到对图片的语言描述
- many to one(N vs 1):输入多个,输出一个。序列分类,把序列压缩成一个向量
- many to many(N vs N):输入多个,输出多个。两者长度可以不一样。翻译任务
- many to many(N vs N):输入多个,输出多个。两者长度一样。char RNN
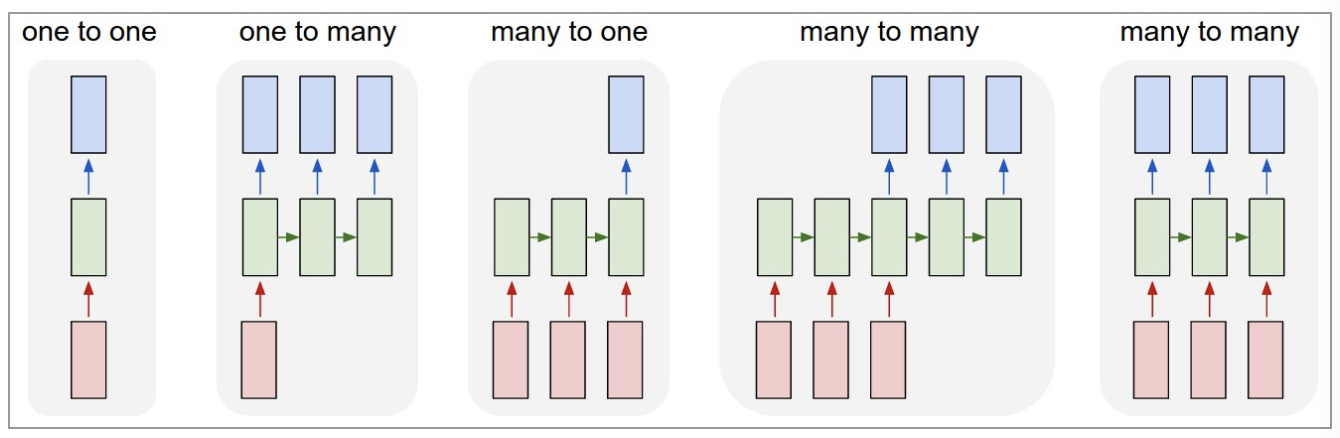
我们先定义需要用到的神经网络单元
全连接层
def fc(input, output_size, activeation_func=tf.nn.relu):
input_shape = input.shape[-1]
# 创建 全连接权重 变量
fc_weights = tf.get_variable(name="weights",
shape=[input_shape, output_size],
initializer=tf.truncated_normal_initializer(stddev=0.01),
dtype=tf.float32,
regularizer=tf.contrib.layers.l2_regularizer(0.01))
# 创建 全连接偏置 变量
fc_biases = tf.get_variable(name="biases",
shape=[output_size],
initializer=tf.zeros_initializer,
dtype=tf.float32)
fc_layer = tf.matmul(input, fc_weights) # 全连接计算
fc_layer = tf.nn.bias_add(fc_layer, fc_biases) # 加上偏置项
if activeation_func:
fc_layer = activeation_func(fc_layer) # rele激活函数
return fc_layer
单层 静态/动态 LSTM/GRU
#######################################
# 单层 静态/动态 LSTM/GRU #
#######################################
# 单层静态LSTM
def single_layer_static_lstm(input_x, time_steps, hidden_size):
"""
:param input_x: 输入张量 形状为[batch_size, n_steps, input_size]
:param n_steps: 时序总数
:param n_hidden: LSTM单元输出的节点个数 即隐藏层节点数
"""
# 把输入input_x按列拆分,并返回一个有n_steps个张量组成的list
# 如batch_sizex28x28的输入拆成[(batch_size,28),((batch_size,28))....]
# 如果是调用的是静态rnn函数,需要这一步处理 即相当于把序列作为第一维度
input_x1 = tf.unstack(input_x, num=time_steps, axis=1)
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units=hidden_size) # 创建LSTM_cell
# 静态rnn函数传入的是一个张量list 每一个元素都是一个(batch_size,input_size)大小的张量
output, states = tf.nn.static_rnn(cell=lstm_cell, inputs=input_x1, dtype=tf.float32) # 通过cell类构建RNN
return output, states
# 单层静态gru
def single_layer_static_gru(input, time_steps, hidden_size):
"""
:param input: 输入张量 形状为[batch_size, n_steps, input_size]
:param n_steps: 时序总数
:param n_hidden: gru单元输出的节点个数 即隐藏层节点数
:return: 返回静态单层GRU单元的输出,以及cell状态
"""
# 把输入input_x按列拆分,并返回一个有n_steps个张量组成的list
# 如batch_sizex28x28的输入拆成[(batch_size,28),((batch_size,28))....]
# 如果是调用的是静态rnn函数,需要这一步处理 即相当于把序列作为第一维度
input_x = tf.unstack(input, num=time_steps, axis=1)
gru_cell = tf.nn.rnn_cell.GRUCell(num_units=hidden_size) # 创建GRU_cell
# 静态rnn函数传入的是一个张量list 每一个元素都是一个(batch_size,input_size)大小的张量
output, states = tf.nn.static_rnn(cell=gru_cell, inputs=input_x, dtype=tf.float32) # 通过cell类构建RNN
return output, states
# 单层动态LSTM
def single_layer_dynamic_lstm(input, time_steps, hidden_size):
"""
:param input_x: 输入张量 形状为[batch_size, time_steps, input_size]
:param time_steps: 时序总数
:param hidden_size: LSTM单元输出的节点个数 即隐藏层节点数
:return: 返回动态单层LSTM单元的输出,以及cell状态
"""
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units=hidden_size) # 创建LSTM_cell
# 动态rnn函数传入的是一个三维张量,[batch_size,time_steps, input_size] 输出也是这种形状
output, states = tf.nn.dynamic_rnn(cell=lstm_cell, inputs=input, dtype=tf.float32) # 通过cell类构建RNN
output = tf.transpose(output, [1, 0, 2]) # 注意这里输出需要转置 转换为时序优先的
return output, states
# 单层动态gru
def single_layer_dynamic_gru(input, time_steps, hidden_size):
"""
:param input: 输入张量 形状为[batch_size, time_steps, input_size]
:param time_steps: 时序总数
:param hidden_size: GRU单元输出的节点个数 即隐藏层节点数
:return: 返回动态单层GRU单元的输出,以及cell状态
"""
gru_cell = tf.nn.rnn_cell.GRUCell(num_units=hidden_size) # 创建GRU_cell
# 动态rnn函数传入的是一个三维张量,[batch_size,n_steps,input_size] 输出也是这种形状
output, states = tf.nn.dynamic_rnn(cell=gru_cell, inputs=input, dtype=tf.float32) # 通过cell类构建RNN
output = tf.transpose(output, [1, 0, 2]) # 注意这里输出需要转置 转换为时序优先的
return output, states
多层 静态/动态 LSTM/GRU
#######################################
# 多层 静态/动态 LSTM/GRU #
#######################################
# 多层静态LSTM网络
def multi_layer_static_lstm(input, time_steps, hidden_size):
"""
:param input: 输入张量 形状为[batch_size,time_steps,input_size]
:param time_steps: 时序总数
:param n_hidden: LSTM单元输出的节点个数 即隐藏层节点数
:return: 返回静态多层LSTM单元的输出,以及cell状态
"""
# 把输入input_x按列拆分,并返回一个有n_steps个张量组成的list
# 如batch_sizex28x28的输入拆成[(batch_size,28),((batch_size,28))....]
# 如果是调用的是静态rnn函数,需要这一步处理 即相当于把序列作为第一维度
input_x1 = tf.unstack(input, num=time_steps, axis=1)
# 多层RNN的实现 例如cells=[cell1,cell2,cell3],则表示一共有三层
mcell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.LSTMCell(num_units=hidden_size) for _ in range(3)])
# 静态rnn函数传入的是一个张量list 每一个元素都是一个(batch_size,input_size)大小的张量
output, states = tf.nn.static_rnn(cell=mcell, inputs=input_x1, dtype=tf.float32)
return output, states
# 多层静态GRU
def multi_layer_static_gru(input, time_steps, hidden_size):
"""
:param input_x: 输入张量 形状为[batch_size,n_steps,input_size]
:param time_steps: 时序总数
:param hidden_size: gru单元输出的节点个数 即隐藏层节点数
:return: 返回静态多层GRU单元的输出,以及cell状态
"""
# 把输入input_x按列拆分,并返回一个有n_steps个张量组成的list
# 如batch_sizex28x28的输入拆成[(batch_size,28),((batch_size,28))....]
# 如果是调用的是静态rnn函数,需要这一步处理 即相当于把序列作为第一维度
input_x = tf.unstack(input, num=time_steps, axis=1)
# 多层RNN的实现 例如cells=[cell1,cell2,cell3],则表示一共有三层
mcell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.GRUCell(num_units=hidden_size) for _ in range(3)])
# 静态rnn函数传入的是一个张量list 每一个元素都是一个(batch_size,input_size)大小的张量
output, states = tf.nn.static_rnn(cell=mcell, inputs=input_x, dtype=tf.float32)
return output, states
# 多层静态GRU和LSTM 混合
def multi_layer_static_mix(input, time_steps, hidden_size):
"""
:param input: 输入张量 形状为[batch_size,n_steps,input_size]
:param time_steps: 时序总数
:param hidden_size: gru单元输出的节点个数 即隐藏层节点数
:return: 返回静态多层GRU和LSTM混合单元的输出,以及cell状态
"""
# 把输入input_x按列拆分,并返回一个有n_steps个张量组成的list
# 如batch_sizex28x28的输入拆成[(batch_size,28),((batch_size,28))....]
# 如果是调用的是静态rnn函数,需要这一步处理 即相当于把序列作为第一维度
input_x = tf.unstack(input, num=time_steps, axis=1)
# 可以看做2个隐藏层
lstm_cell = tf.nn.rnn_cell.LSTMCell(num_units=hidden_size)
gru_cell = tf.nn.rnn_cell.GRUCell(num_units=hidden_size * 2)
# 多层RNN的实现 例如cells=[cell1,cell2],则表示一共有两层,数据经过cell1后还要经过cells
mcell = tf.nn.rnn_cell.MultiRNNCell(cells=[lstm_cell, gru_cell])
# 静态rnn函数传入的是一个张量list 每一个元素都是一个(batch_size,input_size)大小的张量
output, states = tf.nn.static_rnn(cell=mcell, inputs=input_x, dtype=tf.float32)
return output, states
# 多层动态LSTM
def multi_layer_dynamic_lstm(input, time_steps, hidden_size):
"""
:param input: 输入张量 形状为[batch_size,n_steps,input_size]
:param time_steps: 时序总数
:param hidden_size: LSTM单元输出的节点个数 即隐藏层节点数
:return: 返回动态多层LSTM单元的输出,以及cell状态
"""
# 多层RNN的实现 例如cells=[cell1,cell2],则表示一共有两层,数据经过cell1后还要经过cells
mcell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.LSTMCell(num_units=hidden_size) for _ in range(3)])
# 动态rnn函数传入的是一个三维张量,[batch_size,n_steps,input_size] 输出也是这种形状
output, states = tf.nn.dynamic_rnn(cell=mcell, inputs=input, dtype=tf.float32)
# 注意这里输出需要转置 转换为时序优先的
output = tf.transpose(output, [1, 0, 2])
return output, states
# 多层动态GRU
def multi_layer_dynamic_gru(input, time_steps, hidden_size):
"""
:param input: 输入张量 形状为[batch_size,n_steps,input_size]
:param time_steps: 时序总数
:param hidden_size: gru单元输出的节点个数 即隐藏层节点数
:return: 返回动态多层GRU单元的输出,以及cell状态
"""
# 多层RNN的实现 例如cells=[cell1,cell2],则表示一共有两层,数据经过cell1后还要经过cells
mcell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.GRUCell(num_units=hidden_size) for _ in range(3)])
# 动态rnn函数传入的是一个三维张量,[batch_size,n_steps,input_size] 输出也是这种形状
output, states = tf.nn.dynamic_rnn(cell=mcell, inputs=input, dtype=tf.float32)
# 注意这里输出需要转置 转换为时序优先的
output = tf.transpose(output, [1, 0, 2])
return output, states
# 多层动态GRU和LSTM 混合
def multi_layer_dynamic_mix(input, time_steps, hidden_size):
"""
:param input: 输入张量 形状为[batch_size,n_steps,input_size]
:param time_steps: 时序总数
:param hidden_size: gru单元输出的节点个数 即隐藏层节点数
:return: 返回动态多层GRU和LSTM混合单元的输出,以及cell状态
"""
# 可以看做2个隐藏层
gru_cell = tf.nn.rnn_cell.GRUCell(num_units=hidden_size * 2)
lstm_cell = tf.nn.rnn_cell.LSTMCell(num_units=hidden_size)
# 多层RNN的实现 例如cells=[cell1,cell2],则表示一共有两层,数据经过cell1后还要经过cells
mcell = tf.nn.rnn_cell.MultiRNNCell(cells=[lstm_cell, gru_cell])
# 动态rnn函数传入的是一个三维张量,[batch_size,n_steps,input_size] 输出也是这种形状
output, states = tf.nn.dynamic_rnn(cell=mcell, inputs=input, dtype=tf.float32)
# 注意这里输出需要转置 转换为时序优先的
output = tf.transpose(output, [1, 0, 2])
return output, states
单层/多层 双向 静态/动态 LSTM/GRU
#######################################
# 单层/多层 双向 静态/动态 LSTM/GRU #
#######################################
# 单层静态双向LSTM
def single_layer_static_bi_lstm(input, time_steps, hidden_size):
"""
:param input: 输入张量 形状为[batch_size,time_steps,input_size]
:param time_steps: 时序总数
:param hidden_size: LSTM单元输出的节点个数 即隐藏层节点数
:return: 返回单层静态双向LSTM单元的输出,以及cell状态
"""
# 把输入input_x按列拆分,并返回一个有n_steps个张量组成的list
# 如batch_sizex28x28的输入拆成[(batch_size,28),((batch_size,28))....]
# 如果是调用的是静态rnn函数,需要这一步处理 即相当于把序列作为第一维度
input_x = tf.unstack(input, num=time_steps, axis=1)
lstm_fw_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units=hidden_size) # 正向
lstm_bw_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units=hidden_size) # 反向
# 静态rnn函数传入的是一个张量list 每一个元素都是一个(batch_size,input_size)大小的张量
# 这里的输出output是一个list 每一个元素都是前向输出,后向输出的合并
output, fw_state, bw_state = tf.nn.static_bidirectional_rnn(cell_fw=lstm_fw_cell,
cell_bw=lstm_bw_cell,
inputs=input_x,
dtype=tf.float32)
print(type(output)) # <class 'list'>
print(len(output)) # 28
print(output[0].shape) # (?, 256)
return output, fw_state, bw_state
# 单层动态双向LSTM
def single_layer_dynamic_bi_lstm(input, time_steps, hidden_size):
"""
:param input: 输入张量 形状为[batch_size,time_steps,input_size]
:param time_steps: 时序总数
:param hidden_size: gru单元输出的节点个数 即隐藏层节点数
:return: 返回单层动态双向LSTM单元的输出,以及cell状态
"""
lstm_fw_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units=hidden_size) # 正向
lstm_bw_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units=hidden_size) # 反向
# 动态rnn函数传入的是一个三维张量,[batch_size,time_steps,input_size] 输出是一个元组 每一个元素也是这种形状
output, state = tf.nn.bidirectional_dynamic_rnn(cell_fw=lstm_fw_cell,
cell_bw=lstm_bw_cell,
inputs=input,
dtype=tf.float32)
print(type(output)) # <class 'tuple'>
print(len(output)) # 2
print(output[0].shape) # (?, 28, 128)
print(output[1].shape) # (?, 28, 128)
output = tf.concat(output, axis=2) # 按axis=2合并 (?,28,128) (?,28,128)按最后一维合并(?,28,256)
output = tf.transpose(output, [1, 0, 2]) # 注意这里输出需要转置 转换为时序优先的
return output, state
# 多层静态双向LSTM
def multi_layer_static_bi_lstm(input, time_steps, hidden_size):
"""
:param input: 输入张量 形状为[batch_size,time_steps,input_size]
:param time_steps: 时序总数
:param hidden_size: LSTM单元输出的节点个数 即隐藏层节点数
:return: 返回多层静态双向LSTM单元的输出,以及cell状态
"""
# 把输入input_x按列拆分,并返回一个有n_steps个张量组成的list
# 如batch_sizex28x28的输入拆成[(batch_size,28),((batch_size,28))....]
# 如果是调用的是静态rnn函数,需要这一步处理 即相当于把序列作为第一维度
input_x = tf.unstack(input, num=time_steps, axis=1)
stacked_fw_rnn = []
stacked_bw_rnn = []
for i in range(3):
stacked_fw_rnn.append(tf.nn.rnn_cell.BasicLSTMCell(num_units=hidden_size)) # 正向
stacked_bw_rnn.append(tf.nn.rnn_cell.BasicLSTMCell(num_units=hidden_size)) # 反向
# 静态rnn函数传入的是一个张量list 每一个元素都是一个(batch_size,input_size)大小的张量
# 这里的输出output是一个list 每一个元素都是前向输出,后向输出的合并
output, fw_state, bw_state = tf.contrib.rnn.stack_bidirectional_rnn(stacked_fw_rnn,
stacked_bw_rnn,
inputs=input_x,
dtype=tf.float32)
print(type(output)) # <class 'list'>
print(len(output)) # 28
print(output[0].shape) # (?, 256)
return output, fw_state, bw_state
# 多层动态双向LSTM
def multi_layer_dynamic_bi_lstm(input, time_steps, hidden_size):
"""
:param input: 输入张量 形状为[batch_size,n_steps,input_size]
:param time_steps: 时序总数
:param hidden_size: gru单元输出的节点个数 即隐藏层节点数
:return: 返回多层动态双向LSTM单元的输出,以及cell状态
"""
stacked_fw_rnn = []
stacked_bw_rnn = []
for i in range(3):
stacked_fw_rnn.append(tf.nn.rnn_cell.BasicLSTMCell(num_units=hidden_size)) # 正向
stacked_bw_rnn.append(tf.nn.rnn_cell.BasicLSTMCell(num_units=hidden_size)) # 反向
# 动态rnn函数传入的是一个三维张量,[batch_size,n_steps,input_size] 输出也是这种形状,
# input_size变成了正向和反向合并之后的 即input_size*2
output, fw_state, bw_state = tf.contrib.rnn.stack_bidirectional_dynamic_rnn(stacked_fw_rnn,
stacked_bw_rnn,
inputs=input,
dtype=tf.float32)
print(type(output)) # <class 'tensorflow.python.framework.ops.Tensor'>
print(output.shape) # (?, 28, 256)
output = tf.transpose(output, [1, 0, 2]) # 注意这里输出需要转置 转换为时序优先的
return output, fw_state, bw_state
然后我们定义神经网络框架
def RNN_inference(inputs, class_num, time_steps, hidden_size):
"""
:param inputs: [batch_size, n_steps, input_size]
:param class_num: 类别数
:param time_steps: 时序总数
:param n_hidden: LSTM单元输出的节点个数 即隐藏层节点数
"""
#######################################
# 单层 静态/动态 LSTM/GRU #
#######################################
# outputs, states = single_layer_static_lstm(inputs, time_steps, hidden_size) # 单层静态LSTM
# outputs, states = single_layer_static_gru(inputs, time_steps, hidden_size) # 单层静态gru
# outputs, states = single_layer_dynamic_lstm(inputs, time_steps, hidden_size) # 单层动态LSTM
# outputs, states = single_layer_dynamic_gru(inputs, time_steps, hidden_size) # 单层动态gru
#######################################
# 多层 静态/动态 LSTM/GRU #
#######################################
# outputs, states = multi_layer_static_lstm(inputs, time_steps, hidden_size) # 多层静态LSTM网络
# outputs, states = multi_layer_static_gru(inputs, time_steps, hidden_size) # 多层静态GRU
# outputs, states = multi_layer_static_mix(inputs, time_steps, hidden_size) # 多层静态GRU和LSTM 混合
# outputs, states = multi_layer_dynamic_lstm(inputs, time_steps, hidden_size) # 多层动态LSTM
# outputs, states = multi_layer_dynamic_gru(inputs, time_steps, hidden_size) # 多层动态GRU
# outputs, states = multi_layer_dynamic_mix(inputs, time_steps, hidden_size) # 多层动态GRU和LSTM 混合
#######################################
# 单层/多层 双向 静态/动态 LSTM/GRU #
#######################################
# outputs, fw_state, bw_state = single_layer_static_bi_lstm(inputs, time_steps, hidden_size) # 单层静态双向LSTM
# outputs, state = single_layer_dynamic_bi_lstm(inputs, time_steps, hidden_size) # 单层动态双向LSTM
# outputs, fw_state, bw_state = multi_layer_static_bi_lstm(inputs, time_steps, hidden_size) # 多层静态双向LSTM
outputs, fw_state, bw_state = multi_layer_dynamic_bi_lstm(inputs, time_steps, hidden_size) # 多层动态双向LSTM
# output静态是 time_step=28个(batch=128, output=128)组成的列表
# output动态是 (time_step=28, batch=128, output=128)
print('hidden:', outputs[-1].shape) # 最后一个时序的shape(128,128)
# 取LSTM最后一个时序的输出,然后经过全连接网络得到输出值
fc_output = fc(input=outputs[-1], output_size=class_num, activeation_func=tf.nn.relu)
return fc_output
设置全局变量和超参数
在模型训练之前我们首先会定义一些超参数:batch_size、batch_nums、class_num、epochs、learning_rate
batch_size = FLAGS.batch_size batch_nums = mnist.train.images.shape[0] // batch_size # 一个epoch中应该包含多少batch数据 class_num = FLAGS.class_num epochs = FLAGS.epochs learning_rate = FLAGS.learning_rate
保存检查点的地址
############ 保存检查点的地址 ############
checkpoints_dir = FLAGS.checkpoints_dir # checkpoints
# 如果检查点不存在,则创建
if not os.path.exists(checkpoints_dir):
os.makedirs(FLAGS.checkpoints_dir)
创建图
这一步可以不设置,因为tensorflow有一个默认图,我们定义的操作都是在默认图上的,当然我们也可以定义自己的,方便管理。
###################################################### # 创建图 # ###################################################### graph = tf.Graph() # 自定义图 # 在自己的图中定义数据和操作 with graph.as_default():
占位符
一般我们会把input和label做成placeholder,方便我们使用把不同的batch数据传入网络,一些其他的超参数也可以做成placeholder,比如learning_rate、dorpout_keep_prob。一般在搭建模型的时候把placeholder的变量传入模型,在训练模型sess.run(train_op, feed_dict)的时候通过参数feed_dict={input:真实数据,label:真实标签} 把真实的数据传入神经网络。
inputs = tf.placeholder(dtype="float", shape=[None, 28, 28, 1], name='inputs')
labels = tf.placeholder(dtype="float", shape=[None, class_num], name='labels')
# 看个人喜欢,有的人在初始化定义中就定义了learning_rate,有的人喜欢通过feed传learning_rate
learning_rate = tf.placeholder("float", None, name='learning_rate')
# 如果网络结构有dropout层,需要定义keep_probn,如果没有则不需要
# 训练的时候需要,测试的时候需要设置成1
keep_prob = tf.placeholder(dtype="float", name='keep_prob')
搭建模型
传进入的都是placeholder数据,不是我们之前整理好的batch数据。
############ 搭建模型 ############ logits = alexNet(inputs, class_num, keep_prob=keep_prob) # 使用placeholder搭建模型
构建损失
分类任务一般输出的是每个类别的概率向量,因此模型输出最后都要经过softmax转换成概率。一般经过softmax的输出损失函数都是交叉熵损失函数,tensorflow有将以上两步合在一起的现成函数 tf.nn.softmax_cross_entropy_with_logits
############ 损失函数 ############
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits))
tf.add_to_collection('losses', loss)
total_loss = tf.add_n(tf.get_collection("loss")) # total_loss=模型损失+权重正则化损失
自定义损失
以后更新,欢迎大家催我。
模型精度
在测试数据集上的精度
############ 模型精度 ############ predict = tf.argmax(logits, 1) # 模型预测结果 accuracy = tf.reduce_mean(tf.cast(tf.equal(predict, tf.argmax(labels, 1)), tf.float32))
自定义度量
以后更新,欢迎大家催我。
优化器
创建优化器,更新网络参数,最小化loss
优化器的种类有很多种,但是用法都差不多,常用的优化器有:
- tf.train.AdamOptimizer
-
tf.train.GradientDescentOptimizer
- tf.train.RMSPropOptimizer
下面以Adam优化器为例
############ 优化器 ############
variable_to_train = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES) # 可训练变量列表
global_step = tf.Variable(0, trainable=False) # 训练step
# 设置学习率衰减
learning_rate = tf.train.exponential_decay(learning_rate=learning_rate, # 初始学习率
global_step=global_step,
decay_steps=batch_nums, # 多少步衰减一次
decay_rate=0.1, # 衰减率
staircase=True) # 以阶梯的形式衰减
# 创建Adam优化器,更新模型参数,最小化损失函数
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss=total_loss, # 损失函数
global_step=global_step,
var_list=variable_to_train) # 通过训练需要更新的参数列表
讲解:
- variable_to_train:上面的代码定义了可训练变量,我只是把列出了模型默认的可训练变量,这一个步是tensorflow默认的,如果不设置也没有关系。我写出来的原因是,有的大牛会这么写,对不同的可训练变量分别进行不同的优化,希望大家看到我的代码,下次看到别人的不会觉得陌生。
- global_step:大多数人会用step=0,然后在训练的时候step+=1的方式更新step,但是本文介绍的是另一种方式,以tf.Variable的方式定义step,在模型训练的时候传入sess.run,global_step会自动+1更新
- learning_rate:本文还设置了学习率衰减,大家也可以不设置,以固定的学习率训练模型,但是对于大型项目,还是推荐设置。
移动平均值更新参数
采用移动平均值的方式更新损失值和模型参数
def train(total_loss, global_step):
lr = tf.train.exponential_decay(0.01, global_step, decay_steps=350, decay_rate=0.1, staircase=True)
# 采用滑动平均的方法更新损失值
loss_averages = tf.train.ExponentialMovingAverage(decay=0.9, name='avg')
losses = tf.get_collection('losses') # losses的列表
loss_averages_op = loss_averages.apply(losses + [total_loss]) # 计算损失值的影子变量op
# 计算梯度
with tf.control_dependencies([loss_averages_op]): # 控制计算指定,只有执行了括号中的语句才能执行下面的语句
opt = tf.train.GradientDescentOptimizer(lr) # 创建优化器
grads = opt.compute_gradients(total_loss) # 计算梯度
# 应用梯度
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
# 采用滑动平均的方法更新参数
variable_averages = tf.train.ExponentialMovingAverage(0.999, num_updates=global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
with tf.control_dependencies([apply_gradient_op, variables_averages_op]):
# tf.no_op()表示执行完apply_gradient_op, variable_averages_op操作之后什么都不做
train_op = tf.no_op(name='train')
return train_op
TensorBoard可视化 summary
############ TensorBoard可视化 summary ############ summary_writer = tf.summary.FileWriter(logdir="./logs", graph=graph) # 创建事件文件 tf.summary.scalar(name="losses", tensor=total_loss) # 收集损失值变量 tf.summary.scalar(name="acc", tensor=accuracy) # 收集精度值变量 tf.summary.scalar(name='learning_rate', tensor=learning_rate) merged_summary_op = tf.summary.merge_all() # 将所有的summary合并为一个op
模型保存和恢复 Saver
saver = tf.train.Saver(max_to_keep=5) # 保存最新的5个检查点
创建会话
配置会话
在创建会话之前我们一般都要配置会话,比如使用GPU还是CPU,用多少GPU等等。
我们一般使用 tf.ConfigProto()配置Session运行参数&&GPU设备指定
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True) config.gpu_options.per_process_gpu_memory_fraction = 0.4 # 占用40%显存 sess = tf.Session(config=config) # 或者 config = tf.ConfigProto() config.allow_soft_placement = True config.log_device_placement = True with tf.Session(config=config) as sess: # 或者 sess = tf.Session(config=config)
tf.ConfigProto(log_device_placement=True):记录设备指派情况
设置tf.ConfigProto()中参数log_device_placement = True,获取 operations 和 Tensor 被指派到哪个设备(几号CPU或几号GPU)上运行,会在终端打印出各项操作是在哪个设备上运行的。
tf.ConfigProto(allow_soft_placement=True):自动选择运行设备
在TensorFlow中,通过命令 "with tf.device('/cpu:0'):",允许手动设置操作运行的设备。如果手动设置的设备不存在或者不可用,就会导致tf程序等待或异常,为了防止这种情况,可以设置tf.ConfigProto()中参数allow_soft_placement=True,自动选择一个存在并且可用的设备来运行操作。
config.gpu_options.allow_growth = True
当使用GPU时候,Tensorflow运行自动慢慢达到最大GPU的内存
tf.test.is_built_with_cuda():返回是否能够使用GPU进行运算
为了加快运行效率,TensorFlow在初始化时会尝试分配所有可用的GPU显存资源给自己,这在多人使用的服务器上工作就会导致GPU占用,别人无法使用GPU工作的情况。这时我们需要限制GPU资源使用,详细实现方法请参考我的另一篇博客 tensorflow常用函数 Ctrl+F搜索“限制GPU资源使用”
创建会话Session
Session有两种创建方式:
sess = tf.Session(config=config, graph=graph) # 或通过with的方式创建Session with tf.Session(config=config, graph=graph) as sess:
如果我们之前自定义了graph,则在会话中也要配置graph,如果之前没有自定义graph,使用的是tensorflow默认graph,则在会话不用自己去定义,tensorflow会自动找到默认图。
在训练模型之前我们首先要设置一个高级一点的东西,那就是检查是否有之前保存好的模型,如果有着接着前面的继续训练,如果没有则从头开始训练模型。
恢复/重新训练
定义一个检查模型是否存在的函数,为了美观,可以把这个函数放在最上面,或者其他脚本中,通过import导入。
def load_model(sess, saver, checkpoint_dir):
"""加载模型,看看还能不能加一个功能,必须现在的检查检点是1000,但是我的train是100,要报错
还有就是读取之前的模型继续训练的问题
checkpoint_dir = checkpoint"""
# 通过checkpoint找到模型文件名
ckpt = tf.train.get_checkpoint_state(checkpoint_dir=checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path) # 返回最新的chechpoint文件名 model.ckpt-1000
print("新的chechpoint文件名", ckpt_name) # model.ckpt-2
saver.restore(sess, os.path.join(checkpoint_dir, ckpt_name))
# 现在不知道checkpoint文件名时怎样的,因此不知道里面如何运行
counter = int(next(re.finditer("(d+)(?!.*d)", ckpt_name)).group(0)) # 2
print(" [*] 成功模型 {}".format(ckpt_name))
return True, counter
else:
print(" [*] 找不到checkpoint")
return False, 0
如果大家之前用的是global_step = tf.Variable(0, trainable=False),则使用下面diamante
# 加载模型,如果模型存在返回 是否加载成功和训练步数
could_load, checkpoint_step = load_model(sess, saver, "./log")
if could_load:
print(" [*] 加载成功")
else:
print(" [!] 加载失败")
try:
tf.global_variables_initializer().run()
except:
tf.initialize_all_variables().run()
如果大家想使用step=0,step+=1,则可以使用下面代码
# 加载模型,如果模型存在返回 是否加载成功和训练步数
could_load, checkpoint_step = load_model(sess, saver, FLAGS.checkpoints_dir)
if could_load:
step = checkpoint_step
print(" [*] 模型加载成功")
else:
print(" [!] 模型加载失败")
try:
tf.global_variables_initializer().run()
except:
tf.initialize_all_variables().run()
step = 0
开始训练
for epoch in range(epochs):
for i in range(batch_nums):
start_time = time.time()
# batch_images = data_X[i * batch_size:(i + 1) * batch_size]
# batch_labels = data_y[i * batch_size:(i + 1) * batch_size]
train_batch_x, train_batch_y = mnist.train.next_batch(batch_size)
# 使用真实数据填充placeholder,运行训练模型和合并变量操作
_, summary, loss, step = sess.run([train_op, merged_summary_op, total_loss, global_step],
feed_dict={inputs: train_batch_x,
labels: train_batch_y,
keep_prob: 0.5})
if step % 100 == 0:
summary_writer.add_summary(summary, step) # 将每次迭代后的变量写入事件文件
summary_writer.flush() # 强制summary_writer将缓存中的数据写入到日志文件中(可选)
############ 可视化打印 ############
print("Epoch:[%2d] [%4d/%4d] time:%4.4f,loss:%.8f" % (
epoch, i, batch_nums, time.time() - start_time, loss))
# 打印一些可视化的数据,损失...
if step % 100 == 0:
acc = sess.run(accuracy, feed_dict={inputs: mnist.validation.images,
labels: mnist.validation.labels,
keep_prob: 1.0})
print("Epoch:[%2d] [%4d/%4d] accuracy:%.8f" % (epoch, i, batch_nums, acc))
############ 保存模型 ############
if acc > max_acc:
max_acc = acc
save_path = saver.save(sess,
save_path=os.path.join(checkpoints_dir, "model.ckpt"),
global_step=step)
tf.logging.info("模型保存在: %s" % save_path)
print("优化完成!")
模型评估
eval.py
模型评估的代码和模型训练的代码很像,只不过不需要对模型进行训练而已。
from ops import *
import tensorflow as tf
from nets.my_alex import alexNet
from tensorflow.examples.tutorials.mnist import input_data
tf.flags.DEFINE_integer('batch_size', 50, 'batch size, default: 1')
tf.flags.DEFINE_integer('class_num', 10, 'batch size, default: 1')
tf.flags.DEFINE_integer('epochs', 10, 'batch size, default: 1')
tf.flags.DEFINE_string('checkpoints_dir', "checkpoints", '保存检查点的地址')
FLAGS = tf.flags.FLAGS
# 从MNIST_data/中读取MNIST数据。当数据不存在时,会自动执行下载
mnist = input_data.read_data_sets('./data', one_hot=True, reshape=False)
# 将数组张换成图片形式
print(mnist.train.images.shape) # 训练数据图片(55000, 28, 28, 1)
print(mnist.train.labels.shape) # 训练数据标签(55000, 10)
print(mnist.test.images.shape) # 测试数据图片(10000, 28, 28, 1)
print(mnist.test.labels.shape) # 测试数据图片(10000, 10)
print(mnist.validation.images.shape) # 验证数据图片(5000, 28, 28, 1)
print(mnist.validation.labels.shape) # 验证数据图片(5000, 10)
def evaluate():
batch_size = FLAGS.batch_size
batch_nums = mnist.train.images.shape[0] // batch_size # 一个epoch中应该包含多少batch数据
class_num = FLAGS.class_num
test_batch_size = 5000
test_batch_num = mnist.test.images.shape[0] // test_batch_size
############ 保存检查点的地址 ############
checkpoints_dir = FLAGS.checkpoints_dir # checkpoints
# 如果检查点不存在,则创建
if not os.path.exists(checkpoints_dir):
print("模型文件不存在,无法进行评估")
######################################################
# 创建图 #
######################################################
graph = tf.Graph() # 自定义图
# 在自己的图中定义数据和操作
with graph.as_default():
inputs = tf.placeholder(dtype="float", shape=[None, 28, 28, 1], name='inputs')
labels = tf.placeholder(dtype="float", shape=[None, class_num], name='labels')
############ 搭建模型 ############
logits = alexNet(inputs, FLAGS.class_num, keep_prob=1) # 使用placeholder搭建模型
############ 模型精度 ############
predict = tf.argmax(logits, 1)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predict, tf.argmax(labels, 1)), tf.float32))
############ 模型保存和恢复 Saver ############
saver = tf.train.Saver(max_to_keep=5)
######################################################
# 创建会话 #
######################################################
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
with tf.Session(config=config, graph=graph) as sess:
# 加载模型,如果模型存在返回 是否加载成功和训练步数
could_load, checkpoint_step = load_model(sess, saver, FLAGS.checkpoints_dir)
if could_load:
print(" [*] 加载成功")
else:
print(" [!] 加载失败")
raise ValueError("模型文件不存在,无法进行评估")
for i in range(test_batch_num):
test_batch_x, test_batch_y = mnist.test.next_batch(test_batch_num)
acc = sess.run(accuracy, feed_dict={inputs: test_batch_x,
labels: test_batch_y})
print("模型精度为:", acc)
one_image = mnist.test.images[1].reshape(1, 28, 28, 1)
predict_label = sess.run(predict, feed_dict={inputs: one_image})
# print("123", tf.argmax(pre_yyy, 1).eval()) # [7]
# print("123", tf.argmax(yyy, 1).eval()) # 7
def main(argv=None):
evaluate()
if __name__ == '__main__':
tf.app.run()
参考文献
CSDN_AlexNet神经网络结构
CSDN_【深度学习理论3】ALexNet模型的详解
github搜索tensorflow AlexNet
github_finetune_alexnet_with_tensorflow
github_AlexNet_with_tensorflow
github tensorflow vgg
ResNet详解与分析
tensorflow中使用tf.ConfigProto()配置Session运行参数&&GPU设备指定
最后
以上就是谦让乌冬面最近收集整理的关于用TensorFlow搭建一个万能的神经网络框架(持续更新)数据处理模型搭建创建图创建会话模型评估参考文献的全部内容,更多相关用TensorFlow搭建一个万能内容请搜索靠谱客的其他文章。
![vue(16) : leaflet[1] : 入门](https://www.shuijiaxian.com/files_image/reation/bcimg9.png)







发表评论 取消回复