libfacedetection 框架源码解析与扩展心得
- 1. libfacedetection 框架简介
- 2. 源码解析
-
- 2.1 facedetectcnn.h
- 2.2 facedetectcnn.cpp
- 2.3 facedetectcnn-model.cpp
- 3. 其他层的扩展--depthwise convolution
前段时间因为工作需要,对libfacedetection框架做了些扩展,在阅读源码过程中收获良多,做博客记录以加深理解。同时感谢深圳大学于老师团队开源该优秀代码。github地址
1. libfacedetection 框架简介
从名字可以看出来,这个项目是专门为人脸检测而生。其主要优势就是运行速度高,不依赖其他第三方库。运行效率结果对比在作者的github项目上都有介绍,这里就不再赘述了。虽然后来有其他框架号称可以与libfacedetection框架一较高下,甚至更快,但不得不说libfacedetection在当时的前向推理速度还是很值得让人对其代码探索一番的。
为什么可以这么快,作者主要使用了三个策略:1 . 地址分配得当,从而使得conv,pooling等含有大量运算的模块可以做到连续访存。2. arm上的neon加速指令和intel cpu上的avx2加速指令的使用,这两个指令集分别可以使得连续四地址或者连续八地址的内存进行并行计算。1,2策略的结合使得运算速度大大提高。3. 对计算量最大的conv模块进行了量化操作,开发了对应的int类型运算。
下面的内容会以代码和图例的形式详细介绍。当然,因为作者只针对该项目做了特定层的开发,为了不浪费这么好的开源框架和适配我们自己常用的模型,我们需要对该框架进行扩展,所以该篇博客会以两部分展开:源码解析 ,其他层的扩展。
2. 源码解析
libfacedetection的代码量不大,主要有三个文件,一个头文件,两个源文件。我们先看一下头文件里面做了什么。
- facedetection.h
- facedetectcnn.cpp
- facedetectcnn-model.cpp
2.1 facedetectcnn.h
头文件中除了定义了一些结构体,最主要的是做了CDataBlob类定义, 这个类用来模拟caffe中的blobData, 用于层与层传输数据,保存运算结果。这里的CDataBlob是以 C, W, H 的顺序来存储数据的三维数组,并没有实现caffe中 blobData 的 N, C, H, W 里面的N维度,而是用一个 vector<CDataBlob *>类型的变量存储多个CDataBlob类来模拟N (貌似caffe中也是类似的实现方式,没太细看),总之这里想表达的是CDataBlob并不是地址连续的四维数组,层与层的传输数据是vector类型,而vector里面的每个成员是一个地址连续的三维数组,这里拿一张图片作为例子,格子里面的数字用来表示存储地址。可以看见libfacedetection中构造,存储数据的方式。
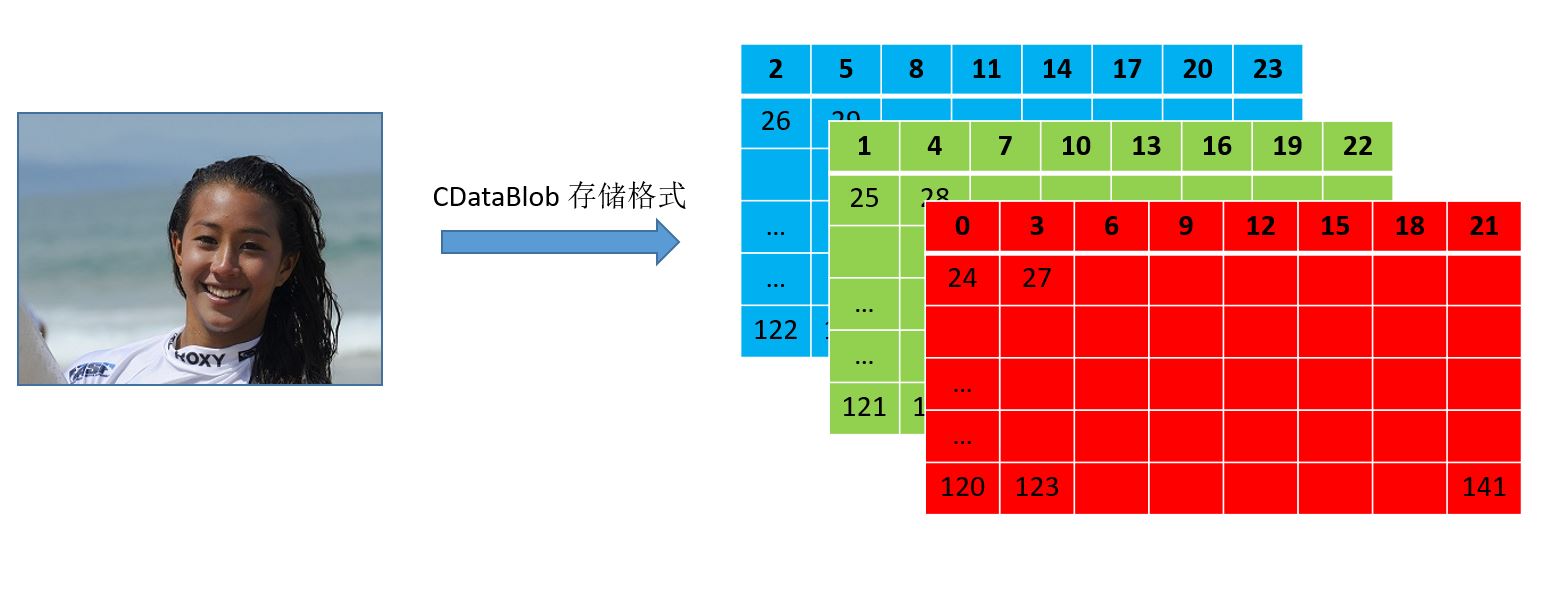
当然,作者为了地址对齐(通道对齐),还做了额外操作。在创造维度是C,W,H大小的CDataBlob类型数据的时候,会对C维度大小进行补齐操作,使其扩展为4或者8的倍数(根据使用neon指令集还是avx2指令集策略有所不同),也就是说上面图例中地址存储顺序其实还不太准确,严格来说会变成以下图示,比如输入是三通道的数据会被多添加一层全是0的数据变成四通道,这样在后续neon指令集加速可以使得四个连续地址并行运算,提高效率。当然avx2指令可以8个连续地址并行运算,所以会补齐一定通道数使得总通道数是8的倍数,比如最开始的3通道的输入会被再补上5个都是0的通道变成8通道输入,方便后续计算。
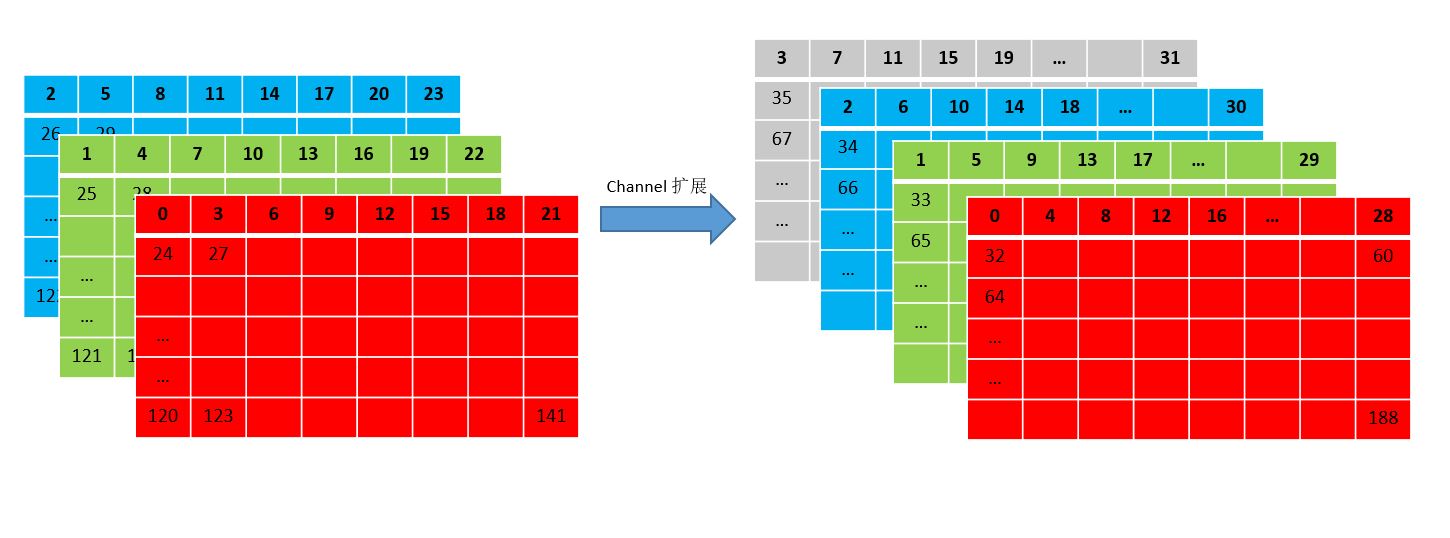
整个.h文件基本上就是做了这么一件事情:定义CDataBlob类和其存储数据的格式。
2.2 facedetectcnn.cpp
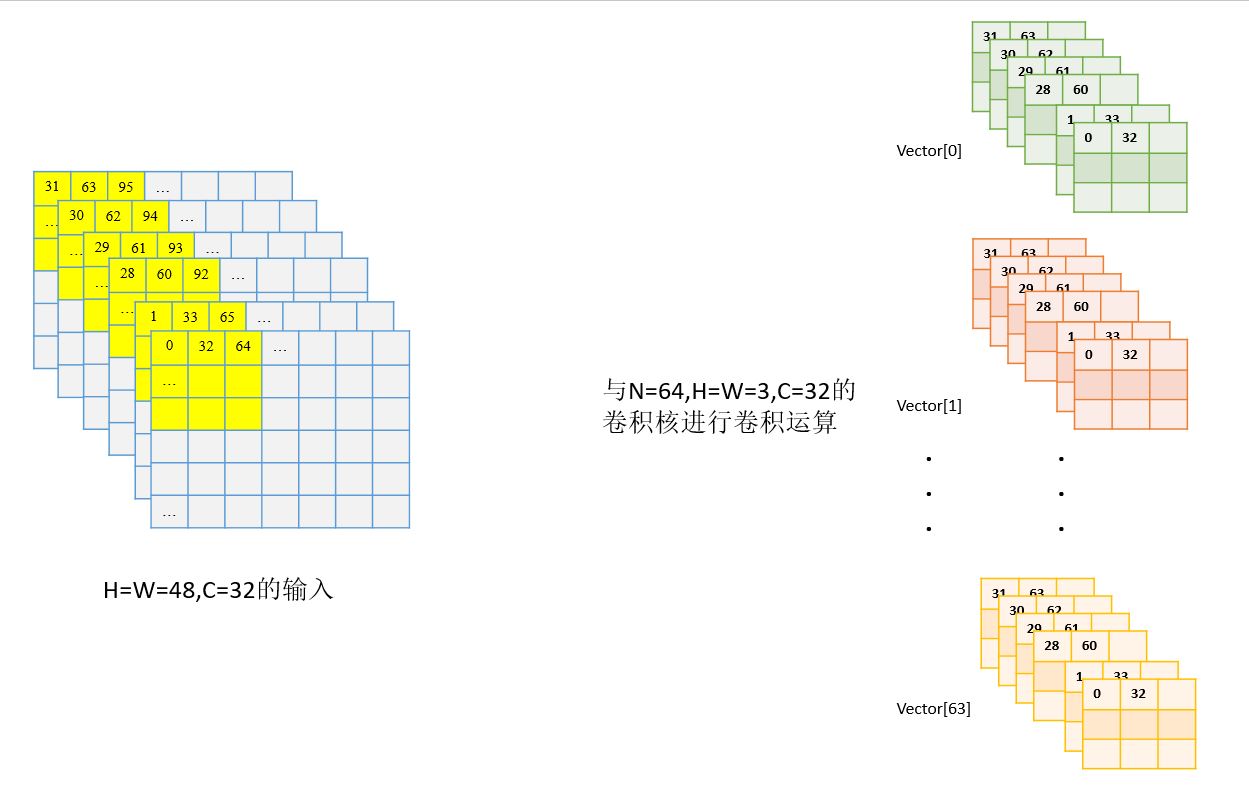
这个源文件就是实现了我们一些常见的运算模块,比如convolution, pooling, relu等,这里不会过多介绍运算原理,太多数学和公式不是本篇博客的重点,举一个3x3卷积的例子来看下作者在层与层之间加速运算的实现和输出数据的存放格式。我们拿48x48x32的输入与64x32x3x3维度大小的权重做卷积运算举例。输入如左边所示,其中用黄色标出的是第一次做卷积时,3x3大小的滑动窗口在输入图像上的位置,右边如上所述用vector< CDataBlob *>类型变量存储64个卷积核,每个卷积核是32x3x3大小,都是按照CDataBlob地址要求存放权重。
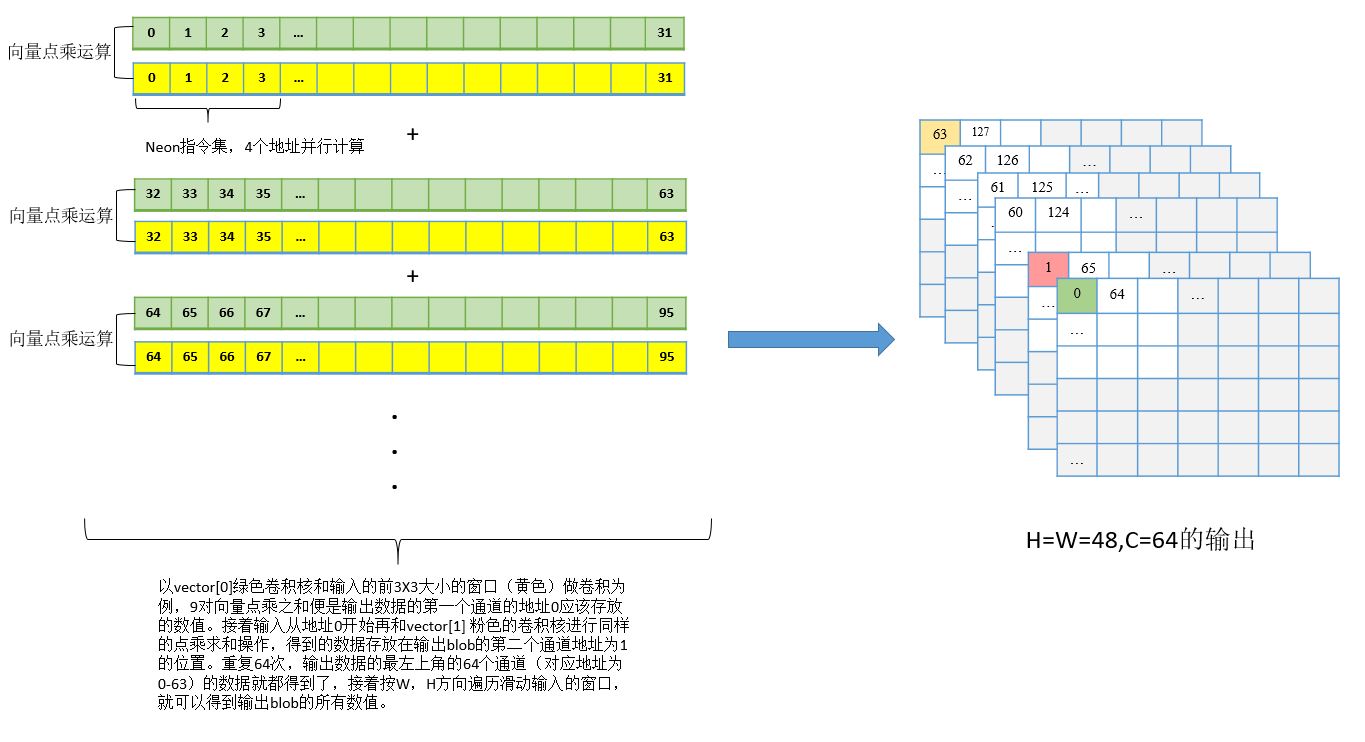
 把向量展开,进行卷积运算,过程如下图所示。以vector[0]绿色卷积核和输入的前3x3大小的窗口(黄色)做卷积为例,9对向量点乘之和便是输出数据的第一个通道的地址0应该存放的数值。接着输入从地址0开始再和vector[1] 粉色的卷积核进行同样的点乘求和操作,得到的数据存放在输出blob的第二个通道地址为1的位置。重复64次,输出数据的最左上角的64个通道(对应地址为0-63)的数据就都得到了,接着按W,H方向遍历滑动输入的窗口,就可以得到输出blob的所有数值。作者在向量点乘函数dotProductFloatChGeneral中对四个连续地址做neon指令集加速,所以conv层加速主要在点乘函数中实现。其中注意9对向量做点乘运算时候,卷积核的9个向量地址一直都是连续的,而输入的9个向量,前三个地址连续,中间三个地址连续,后三个地址连续,所以是分三步调用了向量点乘函数。
把向量展开,进行卷积运算,过程如下图所示。以vector[0]绿色卷积核和输入的前3x3大小的窗口(黄色)做卷积为例,9对向量点乘之和便是输出数据的第一个通道的地址0应该存放的数值。接着输入从地址0开始再和vector[1] 粉色的卷积核进行同样的点乘求和操作,得到的数据存放在输出blob的第二个通道地址为1的位置。重复64次,输出数据的最左上角的64个通道(对应地址为0-63)的数据就都得到了,接着按W,H方向遍历滑动输入的窗口,就可以得到输出blob的所有数值。作者在向量点乘函数dotProductFloatChGeneral中对四个连续地址做neon指令集加速,所以conv层加速主要在点乘函数中实现。其中注意9对向量做点乘运算时候,卷积核的9个向量地址一直都是连续的,而输入的9个向量,前三个地址连续,中间三个地址连续,后三个地址连续,所以是分三步调用了向量点乘函数。
其他层比如maxpooling,Prelu等层的实现思想和这个大同小异,就不多加介绍了。
2.3 facedetectcnn-model.cpp
这个源文件的作用完全类似于caffe中的prototxt的作用–定义网络结构。该源文件可以认为做了三件事情,1. 定义卷积核,偏置项,全连接层等(只要含有权重的)层的维度大小,也就是声明存储这些权重的数组维度大小。2. 将从.caffemodel文件读取的一系列权重值初始化到在第一步中声明的数组中,并构建CDataBlob类和<vector CDataBlob*>类型数据。3. 利用2.2中提到的源文件中定义的各种运算模块,来搭建网络结构。每一步放部分代码块大概看一下:
//1. 声明各参数,比如conv的 kernel_size,stride,padding,number,group大小
ConvInfo param_pConvInfo[NUM_CONV_LAYER] = {
//conv1
{
1, 1, 1, 3</最后
以上就是成就凉面最近收集整理的关于libfacedetection 框架阅读及扩展经验1. libfacedetection 框架简介2. 源码解析3. 其他层的扩展–depthwise convolution的全部内容,更多相关libfacedetection内容请搜索靠谱客的其他文章。








发表评论 取消回复