Spark实现WordCount经典案例
创建数据源
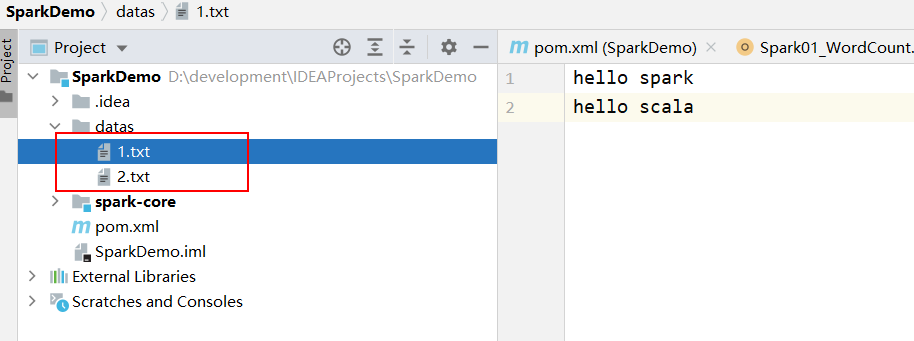
数据源随便弄一下,两份一样即可,数据用空格隔开,换行
仅用spark进行连接,不使用spark提供的方法的两种方法
方法一
package com.kuber.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_WordCount {
def main(args: Array[String]): Unit = {
//Application
//Spark框架
//建立和Spark框架的连接
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
//TODO 业务操作
//1.读取文件,获取一行一行的数据
// hello world
val lines: RDD[String] = sc.textFile("datas")
//2.将一行数据进行拆分,形成一个一个的单词
//扁平化处理,将整体拆分成个体的操作,打散
//{(hello spark),(hello scala)} ==> {hello,spark,hello,scala}
val words: RDD[String] = lines.flatMap(_.split(" "))
//3.将数据根据单词进行分组,便于统计
// (hello,hello,hello),(world,world)
val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word)
//wordGroup.foreach(println)
//4.对分组后的数据进行转换
//{hello->(hello,hello,hello),world->(world,world)}
//(hello,3),(world,2)
val wordToCount: RDD[(String, Int)] = wordGroup.map(word => (word._1, word._2.size))
//5.将转换结果采集到控制台打印出来
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
//TODO 关闭连接
sc.stop()
}
}
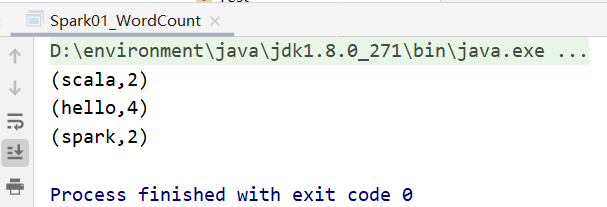
输出:
方法二
package com.kuber.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_WordCount {
def main(args: Array[String]): Unit = {
//Application
//Spark框架
//建立和Spark框架的连接
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
//TODO 业务操作
//1.读取文件,获取一行一行的数据
// hello world
val lines: RDD[String] = sc.textFile("datas")
//2.将一行数据进行拆分,形成一个一个的单词
//扁平化处理,将整体拆分成个体的操作,打散
//{(hello spark),(hello scala)} ==> {hello,spark,hello,scala}
val words: RDD[String] = lines.flatMap(_.split(" "))
//{(hello,1),(spark,1),(hello,1),(scala,1)}
val wordToOne = words.map(word => (word, 1))
//3.将数据根据单词进行分组,便于统计
// ((hello,1),(hello,1),(hello,1)),((world,1),(world,1))
val wordGroup: RDD[(String, Iterable[(String, Int)])] = wordToOne.groupBy(word => word._1)
//wordGroup.foreach(println)
//4.对分组后的数据进行转换
//{hello->((hello,1),(hello,1),(hello,1)),world->((world,1),(world,1)}
//(hello,3),(world,2)
val wordToCount: RDD[(String, Int)] = wordGroup.map({
word => {
word._2.reduce(
(t1, t2) => {
val wordCount: (String, Int) = (t1._1, t1._2 + t2._2)
wordCount
}
)
}
})
//5.将转换结果采集到控制台打印出来
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
//TODO 关闭连接
sc.stop()
}
}
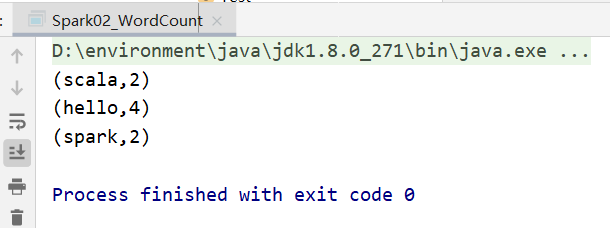
输出:
使用spark提供的reduceByKey方法
package com.kuber.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
//Application
//Spark框架
//建立和Spark框架的连接
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
//TODO 业务操作
//读取一行
val lines: RDD[String] = sc.textFile("datas")
//2.将一行数据进行拆分,形成一个一个的单词
//扁平化处理,将整体拆分成个体的操作,打散
//{(hello spark),(hello scala)} ==> {hello,spark,hello,scala}
val words: RDD[String] = lines.flatMap(_.split(" "))
//{(hello,1),(spark,1),(hello,1),(scala,1)}
val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))
//spark框架提供了更多的功能,可以将分组和聚合使用一个方法实现
//reduceByKey():相同的key的数据,可以对value进行reduce聚合
//val wordToCount: RDD[(String, Int)] = wordToOne.reduceByKey((a, b) => a + b)
val wordToCount: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
//TODO 关闭连接
sc.stop()
}
}
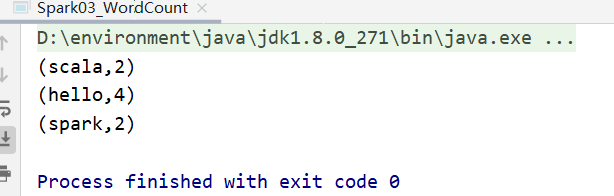
输出:
注意
我这里配了log4j文件,所以控制台没有打印那么多内容
贴一下log4j.properties
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark shell log level to ERROR. When running the spark shell,the
# log level for this clas s is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK 9183: Settings to avoid annoying messages when looking up nonexistent
UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
最后
以上就是坦率康乃馨最近收集整理的关于Spark实现WordCount经典案例Spark实现WordCount经典案例的全部内容,更多相关Spark实现WordCount经典案例Spark实现WordCount经典案例内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复