Spark运行WordCount(案例二)
具体细节参考Spark运行WordCount(案例一):
https://zhangvalue.blog.csdn.net/article/details/122501292 https://zhangvalue.blog.csdn.net/article/details/122501292
https://zhangvalue.blog.csdn.net/article/details/122501292
和前期准备工作:
Mac安装Spark并运行SparkPi_zhangvalue的博客-CSDN博客Mac安装Spark2.4.7https://archive.apache.org/dist/spark/spark-2.4.7/spark-2.4.7-bin-hadoop2.7.tgz解压tgz文件tar xvf spark-2.4.7-bin-hadoop2.7.tgz先创建scala项目并进行编译打成jar包然后就打好成了本地的jar包打包一个jar包通过sparksubmit提交./bin...https://zhangvalue.blog.csdn.net/article/details/122501186
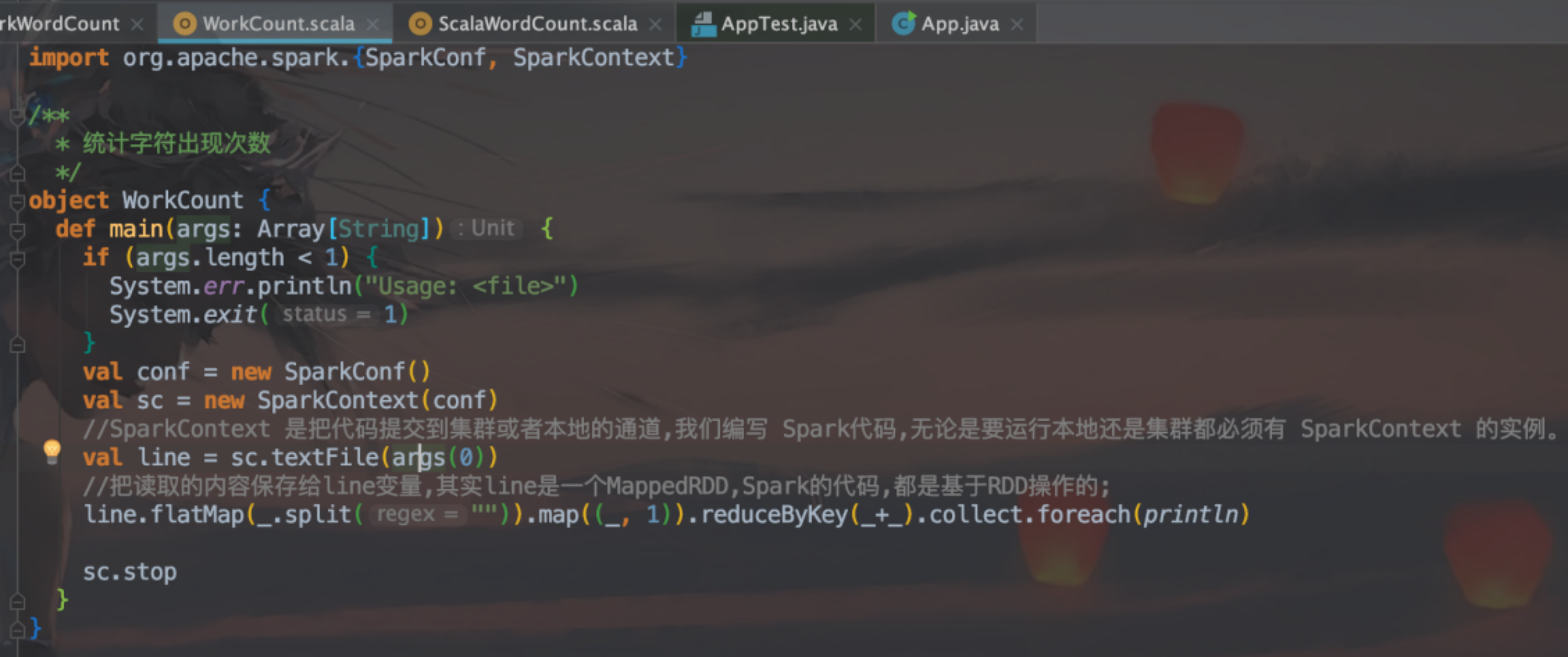
import org.apache.spark.{SparkConf, SparkContext}
/**
* 统计字符出现次数
*/
object WorkCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage: <file>")
System.exit(1)
}
val conf = new SparkConf()
val sc = new SparkContext(conf)
//SparkContext 是把代码提交到集群或者本地的通道,我们编写 Spark代码,无论是要运行本地还是集群都必须有 SparkContext 的实例。
val line = sc.textFile(args(0))
//把读取的内容保存给line变量,其实line是一个MappedRDD,Spark的代码,都是基于RDD操作的;
line.flatMap(_.split("")).map((_, 1)).reduceByKey(_+_).collect.foreach(println)
sc.stop
}
}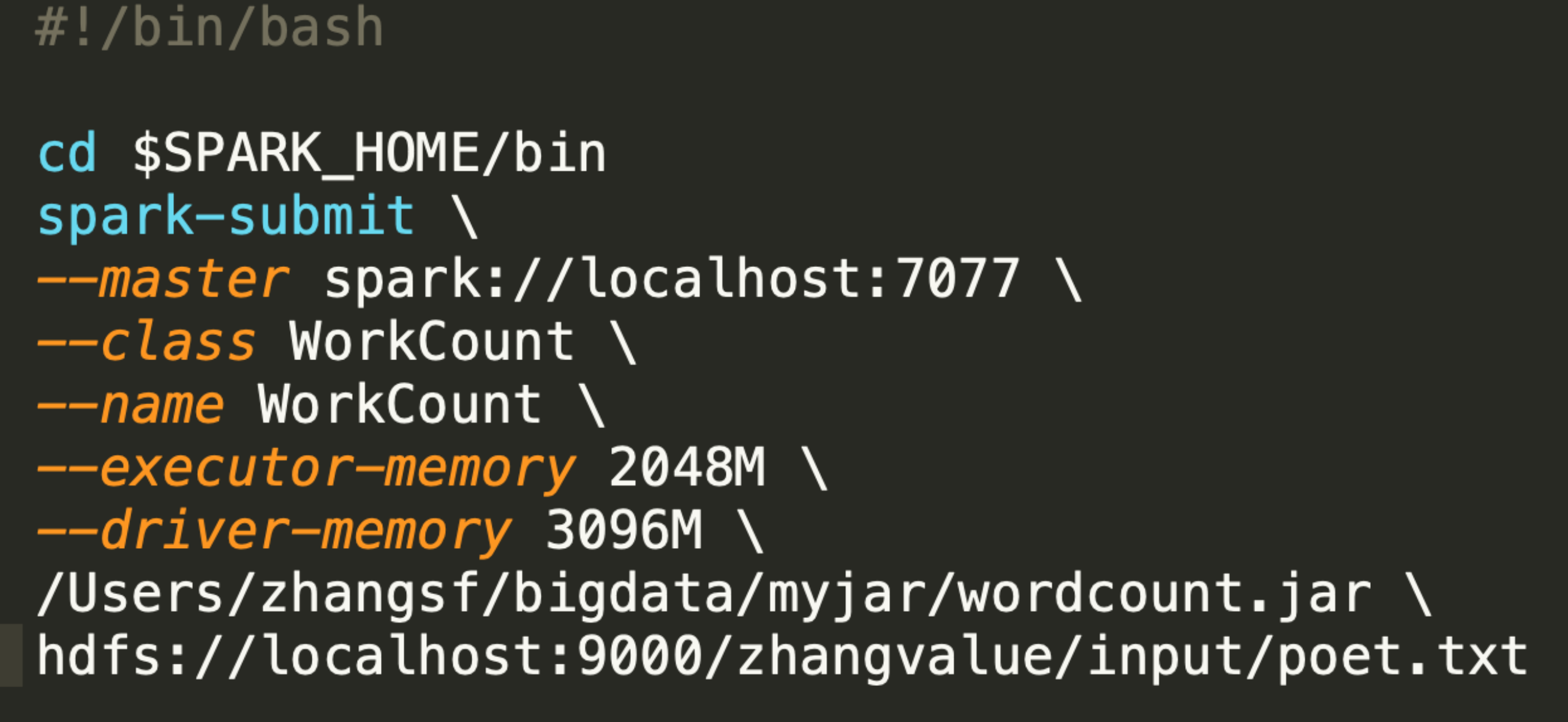
#!/bin/bash
cd $SPARK_HOME/bin
spark-submit
--master spark://localhost:7077
--class WorkCount
--name WorkCount
--executor-memory 2048M
--driver-memory 3096M
/Users/zhangsf/bigdata/myjar/wordcount.jar
hdfs://localhost:9000/zhangvalue/input/poet.txt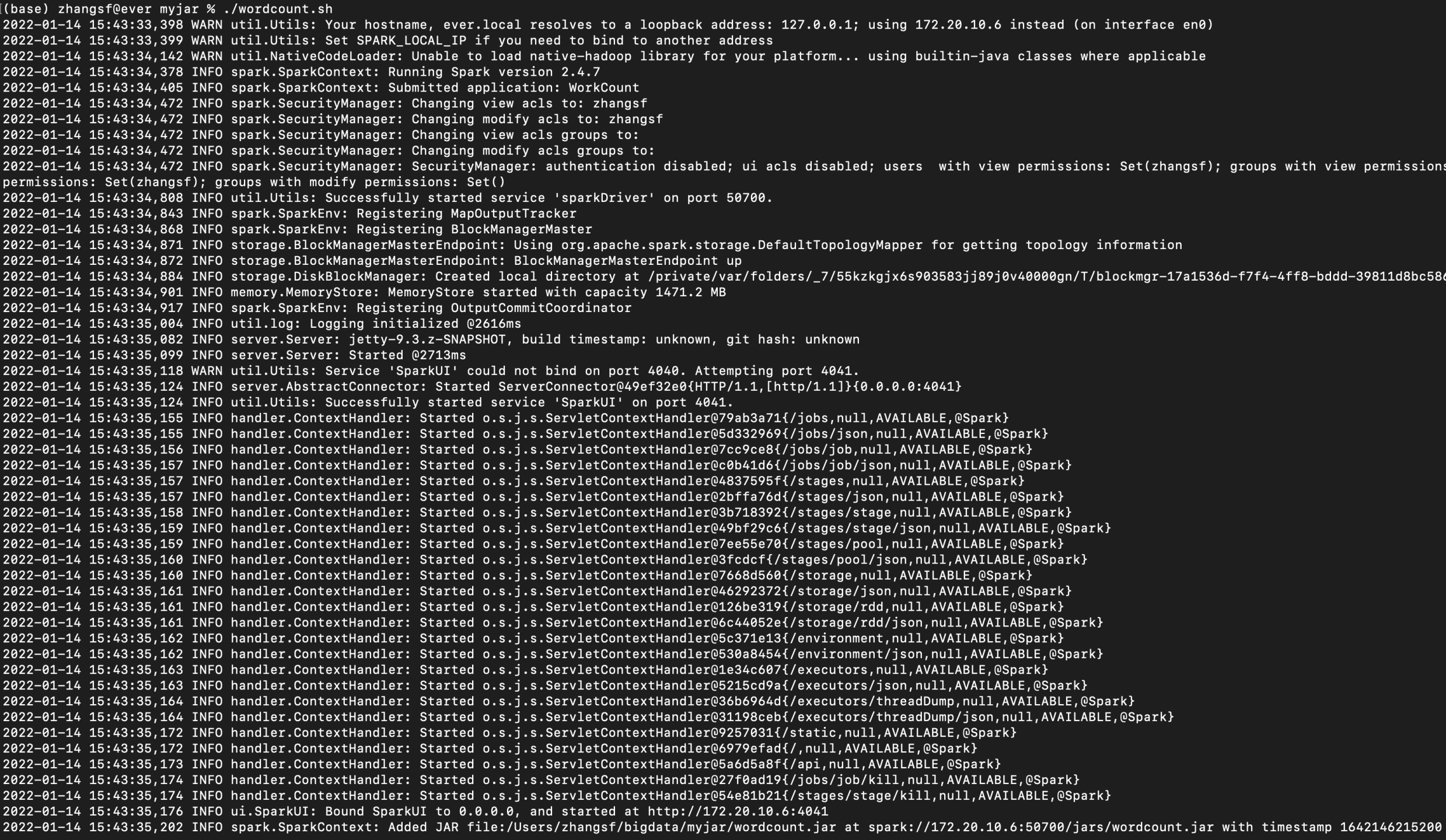
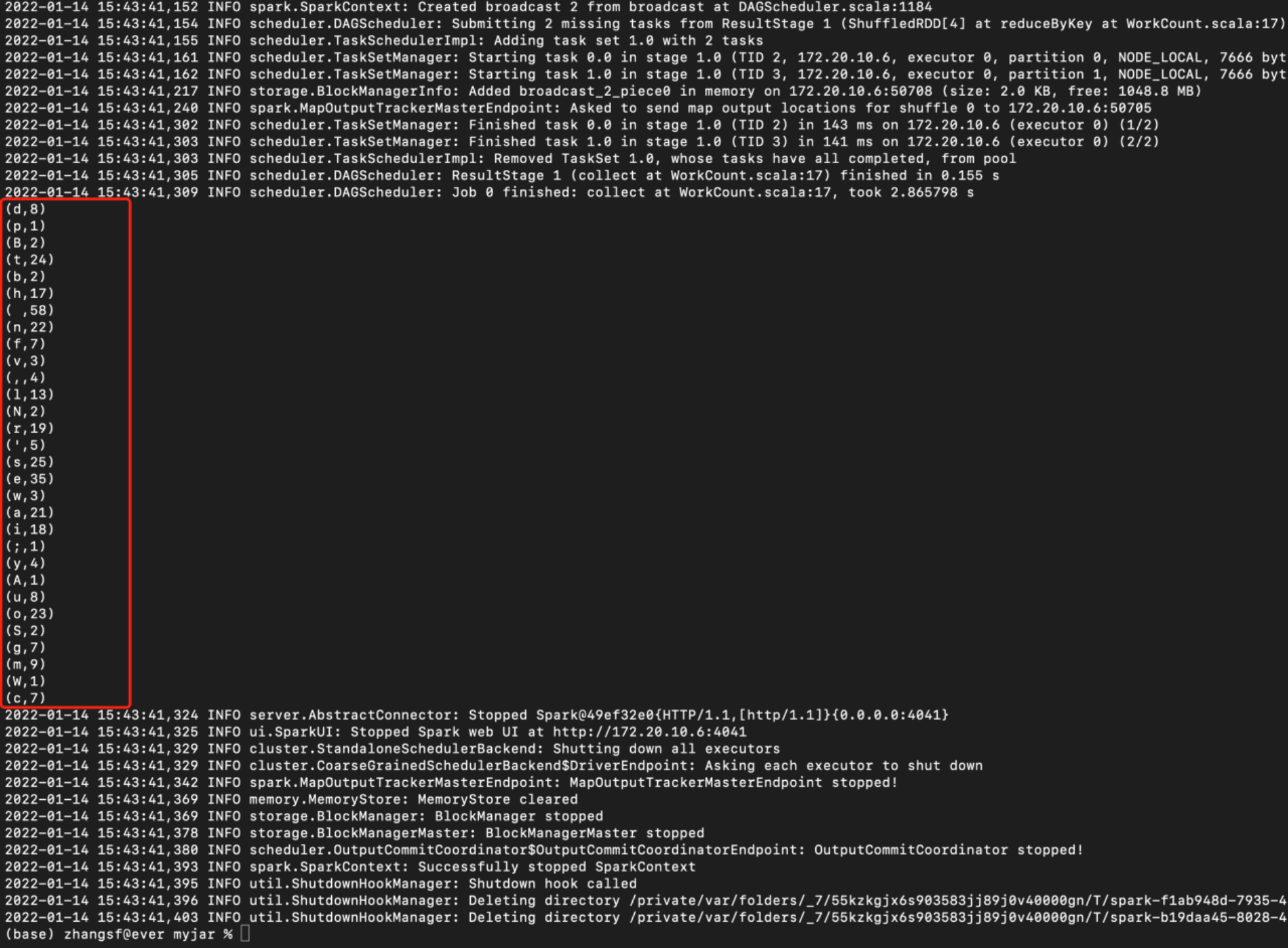
最后
以上就是腼腆方盒最近收集整理的关于Spark运行WordCount(案例二)的全部内容,更多相关Spark运行WordCount(案例二)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复