一、MapReduce1.0运行模型
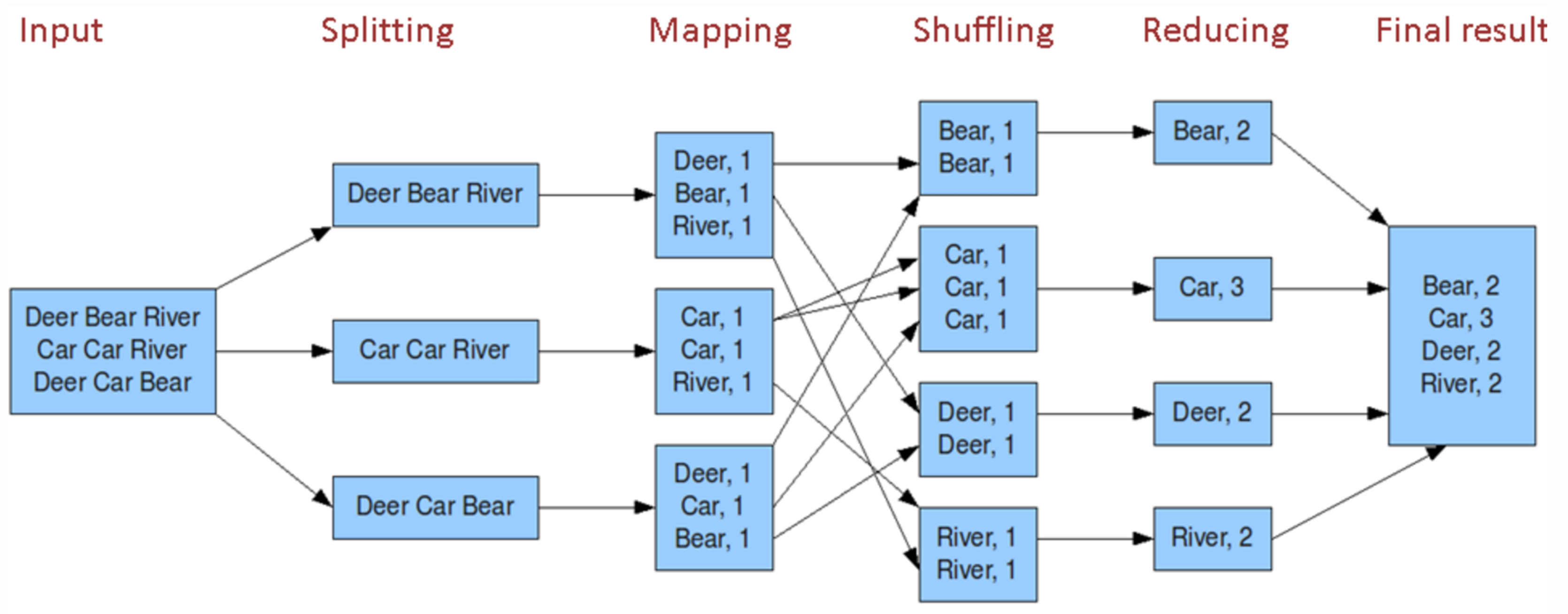
二、MapReduce编程模型之执行步骤
1、准备map处理的输入数据
2、交给Mapper进行处理
3、Shuffle【规则可以自己控制】
4、Reduce处理[合并、归并]
5、输出
MapReduce处理流程
InputFormat读数据,通过Split将数据切片成InputSplit,通过RecordReader读取记录,再交给map处理,处理后输出一个临时的<k,v>键值对,再将结果交给shuffle处理,最终在reduce中将最后处理后的<k,v>键值对结果通过OutputFormat重新写回到HDFS中。
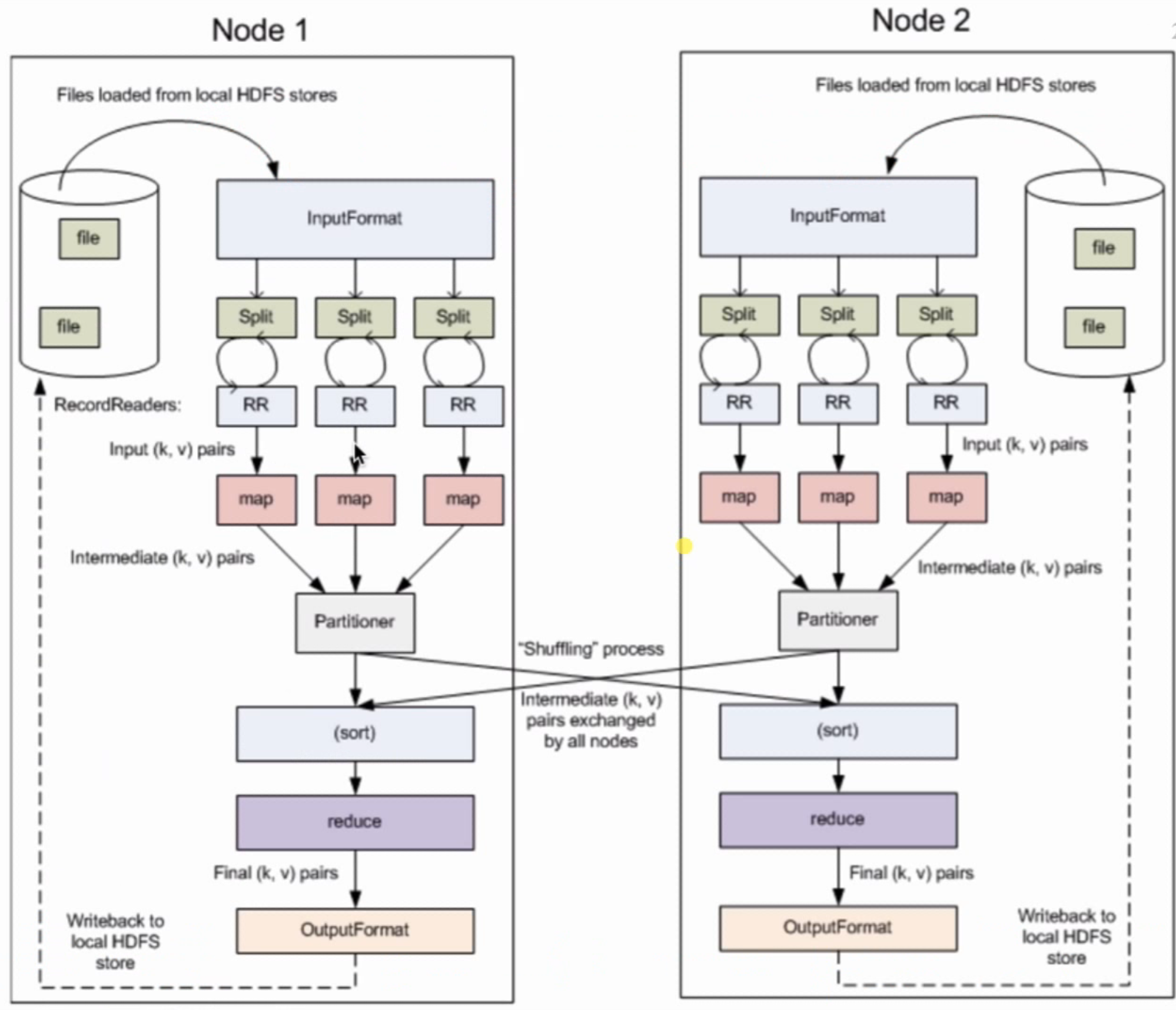
三、词频统计原理图:
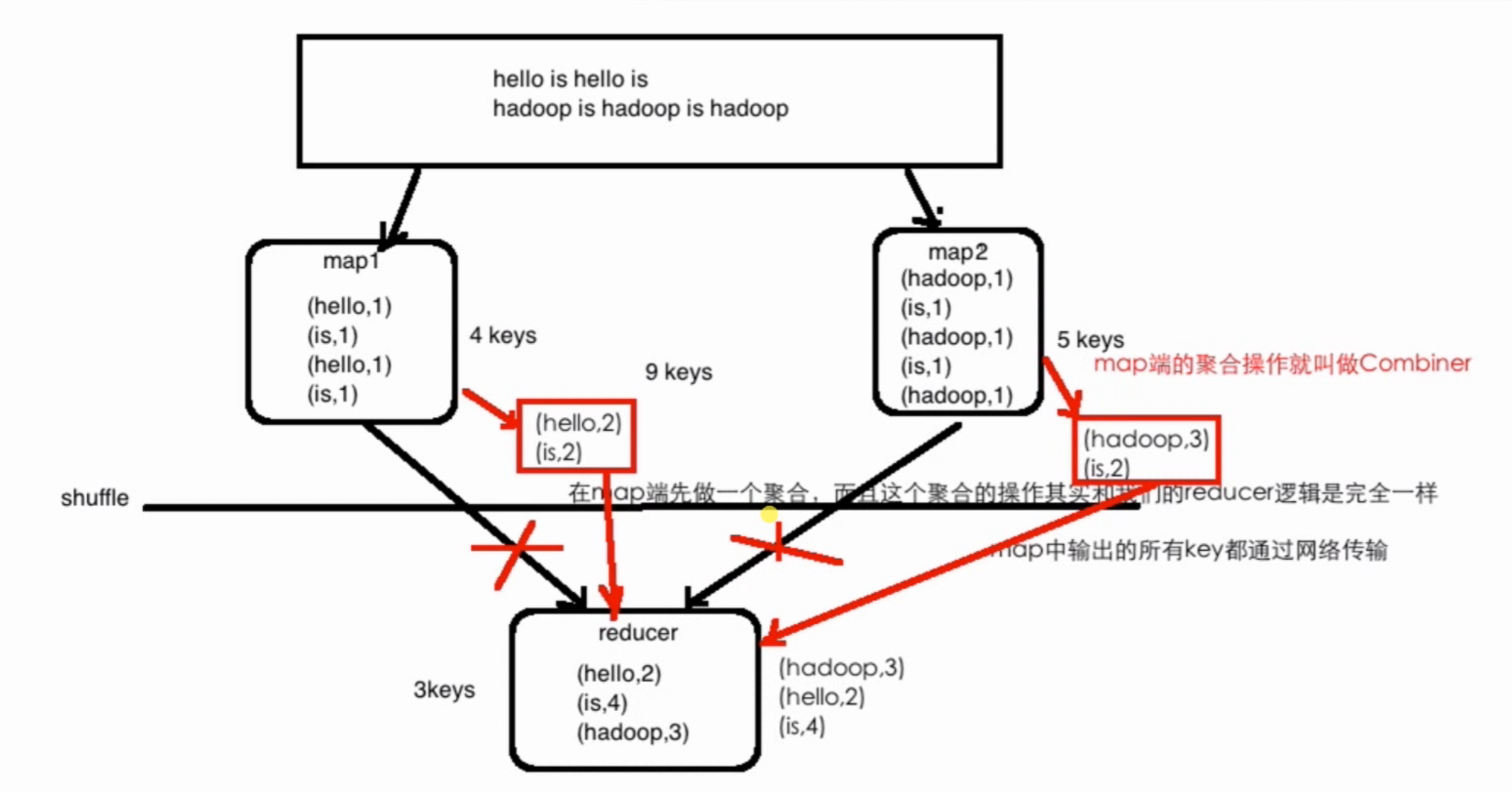
Combiner能减少网络IO、提升作业的性能
Combiner的局限性:求平均数:总数 / 个数 对于含有除法的操作,需要慎重,有可能结果会不正确
四、词频统计具体代码实现[读写在HDFS和本地完成]
0、pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itcats</groupId>
<artifactId>hadoop-mapreduce</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
</project>1、准备一个自定义的Mapper类
package cn.itcats.hadoop.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Mapper类4个泛型的含义
* KEYIN: Map任务读数据的key类型,offset,是每行数据起始位置的偏移量,Long(Java)
* VALUEIN:Map任务读数据的value类型,其实就是一行行的字符串,String
*
* 如文本中的数据为 :
* hello world welcome
* hello welcome
*
* KEYOUT: map方法自定义实现输出的key的类型,String
* VALUEOUT:map方法自定义实现输出的value类型,Integer
*
* 词频统计: 相同单词的次数 (word,1)
* Long,String,String,Integer是Java里面的数据类型
* 因为涉及网络传输,需要序列化与反序列化
* 使用Hadoop提供的自定义类型:
* Long => LongWritable String => Text Integer => IntWritable
*/
//词频统计
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//把value对应的行数据按照指定的分隔符拆开
String[] words = value.toString().split(",");
for(String word : words){
//(hello,1) (word,1)
//转成小写,忽略大小写
context.write(new Text(word.toLowerCase()) , new IntWritable(1));
}
}
}
2、准备一个自定义的Reducer类
package cn.itcats.hadoop.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* (hello,1) (world,1)
* (hello,1) (world,1)
* (hello,1) (world,1)
* (welcome,1)
* <p>
* key 为 word values含义:
* map的输出到reduce端,是按照相同的key分发到一个reduce上去执行
* reduce1 : (hello,1) (hello,1) (hello,1) => (hello,[1,1,1])
* reduce2 : (world,1) (world,1) (world,1) => (world,[1,1,1])
* reduce3 : (welcome,1) => (welcome,[1])
*
* Reducer和Mapper中使用到了什么设计模式? 模板模式
*/
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()){
IntWritable value = iterator.next();
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
读写在HDFS完成
3、准备一个任务驱动类
package cn.itcats.hadoop.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
/**
* 使用MapReduce统计HDFS上文件对应的词频
* <p>
* Driver: 配置Mapper,Reducer的相关属性
* <p>
* 提交到HDFS运行
*
* 含有Combiner操作
*/
public class WordCountCombinerApp {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://hdp-01:9000");
// 创建一个Job
Job job = Job.getInstance(configuration);
// 设置Job对应的主类、Mapper、Reducer类
job.setJarByClass(WordCountCombinerApp.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//添加Combiner的设置
job.setCombinerClass(WordCountReducer.class);
//设置Job对应的参数: Mapper输出key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Job对应的参数: Reducer输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//如果文件已经存在则先删除,否则会报错org.apache.hadoop.mapred.FileAlreadyExistsException
//获取FileSystem对象进行exists/delete操作
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hdp-01:9000"), configuration, "root");
Path outputPath = new Path("/wordcount/output");
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath,true);
}
//设置job作业输入和输出的路径
FileInputFormat.setInputPaths(job, new Path("/wordcount/input"));
FileOutputFormat.setOutputPath(job, outputPath);
//提交job
boolean resullt = job.waitForCompletion(true);
System.exit(resullt ? 0 : 1);
}
}
4、将文件上传到HDFS的/wordcount/input中(没有创建提前创建好该文件夹)
1.txt
hello,world,welcome,hello,welcome,Welcome,Hello,haha,Haha,hAha
读写在本地中完成
将上述的第四步改为:
在工程下创建一个input文件夹
修改上述第三步的代码,只new Configuration()即可,最后把输入路径改成input、输出路径改成output即可
package cn.itcats.hadoop.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.File;
/**
* 使用MapReduce统计HDFS上文件对应的词频
*
* Driver: 配置Mapper,Reducer的相关属性
*
* 提交到本地运行运行(使用本地文件进行统计,统计结果输出到本地路径)
*/
public class WordCountLocalApp {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
// 创建一个Job
Job job = Job.getInstance(configuration);
// 设置Job对应的主类、Mapper、Reducer类
job.setJarByClass(WordCountLocalApp.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//设置Job对应的参数: Mapper输出key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Job对应的参数: Reducer输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置job作业输入和输出的路径
FileInputFormat.setInputPaths(job,new Path("input"));
FileOutputFormat.setOutputPath(job,new Path("output"));
//提交job
boolean resullt = job.waitForCompletion(true);
System.exit(resullt ? 0 : 1);
}
}
运行测试
运行WordCountLocalApp
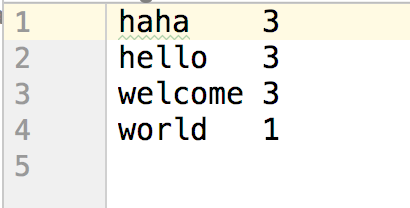
得到最终结果输出:
输出结果:
五、关于自定义复杂类型的介绍
package cn.itcats.hadoop.mapreduce.access;
/*
* 自定义复杂的数据类型
* 对此Hadoop有一些规范
* 1、需要实现Writable
* 2、需要实现write和readFields这两个方法
* 3、需要定义默认的构造方法
*/
import lombok.Data;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
@Data
public class Access implements Writable {
private String phone;
private long up;
private long down;
private long sum;
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(phone); //字符串
dataOutput.writeLong(up); //Long
dataOutput.writeLong(down);
dataOutput.writeLong(sum);
}
public void readFields(DataInput dataInput) throws IOException {
//规范: 严格按照上面写的顺序
this.phone = dataInput.readUTF();
this.up = dataInput.readLong();
this.down = dataInput.readLong();
this.sum = dataInput.readLong();
}
public Access() {
}
}
六、NullWritable介绍
若Mapper或Reducer中某个输入或输出不想输出显示,则使用NullWritable替换我们常用的类型(如Text、LongWritable)等
Plus:NullWritable.get(),返回NullWritable类型
七、自定义Partitioner介绍
默认情况下Map的输出需要做shuffle操作,将key根据一定的算法分发到Reduce上执行【如相同的key,或者具有相似特征的key】,我们也可以自定义分区写数据
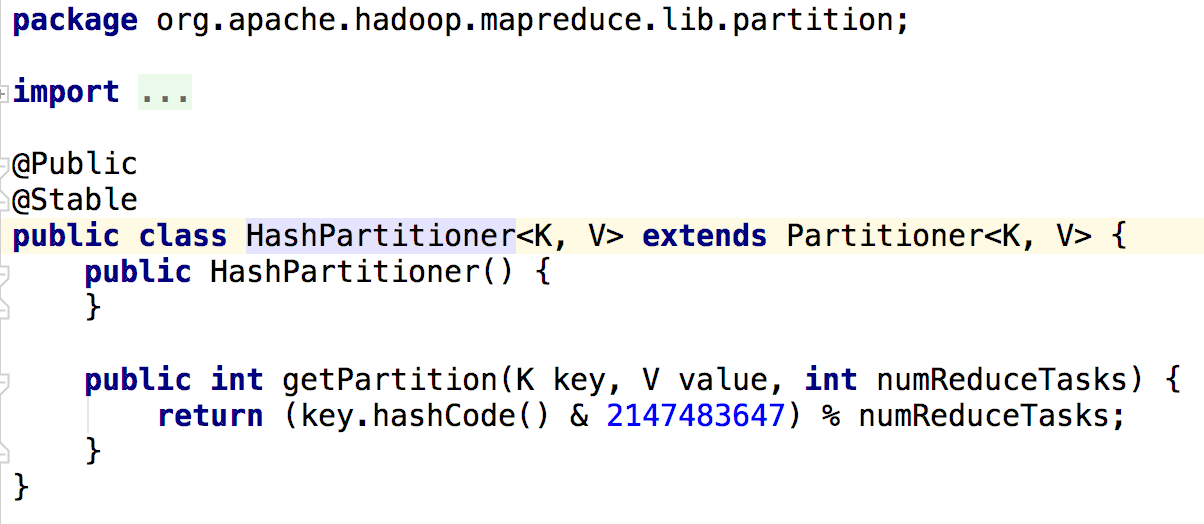
numReduceTasks:你的作业所指定的reducer的个数,决定了reduce作业输出文件的个数
HashPartitioner是MapReduce默认的分区规则
//泛型对应map的输出(KEYOUT和VALUEOUT)
public class AccessPartitioner extends Partitioner<Text,Access>{
//根据手机号开头数字,分派到不同的分区
public int getPartition(Text phone, Access access, int numPartitions) {
//总共定义了4种分区规则,后面设置分区数也要填4
if(phone.toString().startsWith("13")){
return 0;
}else if(phone.toString().startsWith("18")){
return 1;
}else if(phone.toString().startsWith("15")){
return 2;
}else{
return 3;
}
}
}在job任务驱动类中加上一行代码:
//设置自定义分区规则
job.setPartitionerClass(AccessPartitioner.class);
//设置reduce个数
job.setNumReduceTasks(4);观察output文件输出:【总共4个文件】
part-r-00000
part-r-00001
part-r-00002
part-r-00003
总结:Partitioner决定maptask输出的数据交由哪个reducetask处理
默认实现:分发的key的hash值与reduce task个数取模
八、程序修改为在Yarn上运行
第一步
那么outputPath、和inputPath则不能写死,修改为args[0]、args[1]
package cn.itcats.hadoop.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
/**
* 使用MapReduce统计HDFS上文件对应的词频
* <p>
* Driver: 配置Mapper,Reducer的相关属性
* <p>
* 提交到HDFS运行
*
* 含有Combiner操作
*/
public class WordCountYarnApp {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://hdp-01:9000");
// 创建一个Job
Job job = Job.getInstance(configuration);
// 设置Job对应的主类、Mapper、Reducer类
job.setJarByClass(WordCountYarnApp.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//添加Combiner的设置
job.setCombinerClass(WordCountReducer.class);
//设置Job对应的参数: Mapper输出key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Job对应的参数: Reducer输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//如果文件已经存在则先删除,否则会报错org.apache.hadoop.mapred.FileAlreadyExistsException
//获取FileSystem对象进行exists/delete操作
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hdp-01:9000"), configuration, "root");
Path outputPath = new Path(args[0]);
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath,true);
}
//设置job作业输入和输出的路径
FileInputFormat.setInputPaths(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, outputPath);
//提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
第二步
进入工程,执行maven打包命令
mvn clean package -DskipTests打包完成后jar包在当前项目的 target/文件夹内
在hadoop机器上执行
hadoop jar hadoop-mapreduce-1.0-SNAPSHOT.jar 完整类名 args[0] arg[1]
//其中上面的args[0]、args[1]都是我们修改源码后的参数,对应输入路径和输出路径,填上执行即可
总结:
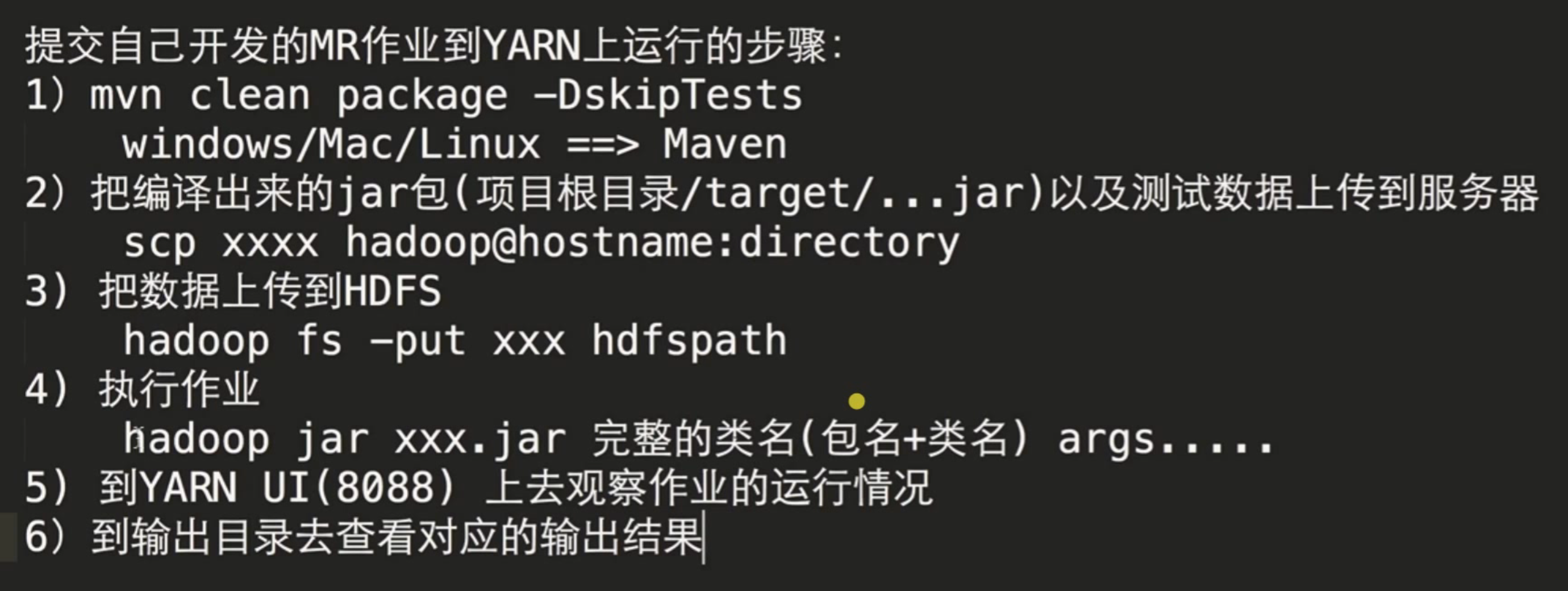
最后
以上就是幸福星星最近收集整理的关于MapReduce词频统计【自定义复杂类型、自定义Partitioner、NullWritable使用介绍】的全部内容,更多相关MapReduce词频统计【自定义复杂类型、自定义Partitioner、NullWritable使用介绍】内容请搜索靠谱客的其他文章。








发表评论 取消回复