一. 简介
1.1 介绍
Dataphin是由阿里研发的智能大数据建设平台,提供一站式数据中台(大数据平台)建设服务。Dataphin通过沙箱(项目)实现业务及作业资源隔离,运行更快,且数据同步到Dataphin后,会统一将敏感数据脱敏后放入脱敏层,增强安全性并提高了效率。
Dataphin支持选择不同计算引擎进行数据处理,包括:MaxCompute、HadoopHive、AnalyticDB PostgreSQL、Flink,产品使用大致分成几个部分:数仓规划、数据研发、资产管理和资产服务。其服务模式包括:
1)公共云在线服务:Dataphin 支持按月订购的预付费模式,开通即可使用;
2)线下独立部署:提供一次购买软件并每年订购维保的买断式服务。
Dataphin的产品框架如下:
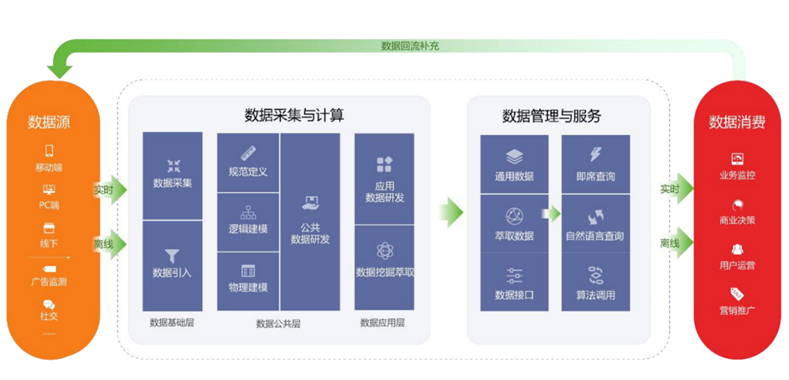
1.2页面展示

研发:报表开发及数据查询
资产:快速查询当前Dataphin有哪些数据资产
规划及管理中心:一般大数据运维及产品开发人员使用
注:右上角的消息通知,可以快速了解你申请的账号/表权限当前的审批节点在哪。
二. 操作手册
2.1 权限申请
DP使用需要开通账号权限、沙箱权限、表及字段权限,具体如下:
1)账号权限:使用Dataphin的权限(走工单);
2)项目(沙箱)权限:申请与自己业务及部门相关的项目权限,实现作业资源隔离(走工单);
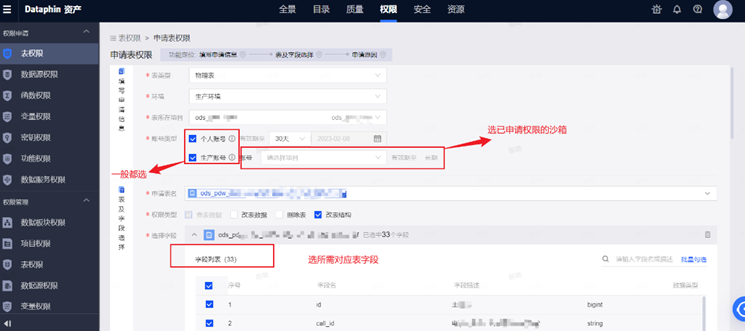
3)表权限及字段权限:在DP页面申请即可
资产—>搜索相关表—>申请权限—>选择项目及对应字段
Step1:打开资产页面
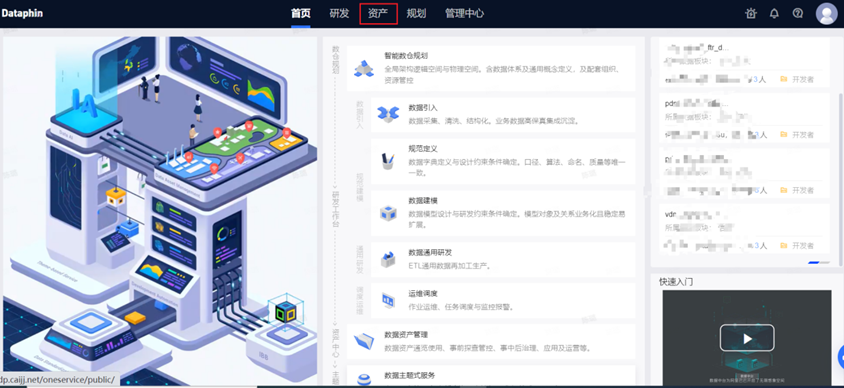
Step2:搜索对应的表
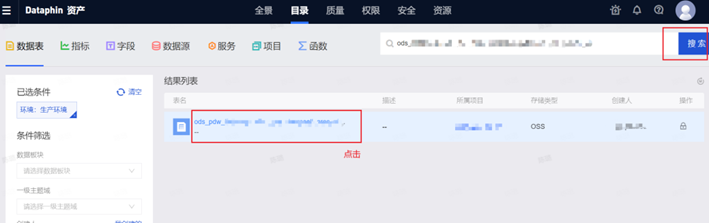
Step3:申请权限
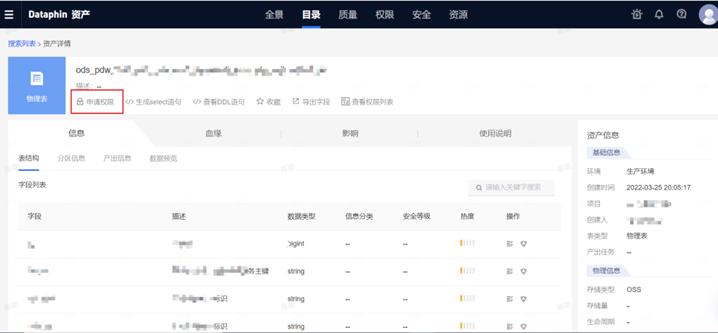
Step4:填写信息并提交
2.2 数据查询
步骤:选择沙箱—>创建文件夹及页面—>写SQL脚本à保存并执行
注:写SQL语句查询数据:只能查询申请过权限的表,不然会报错。
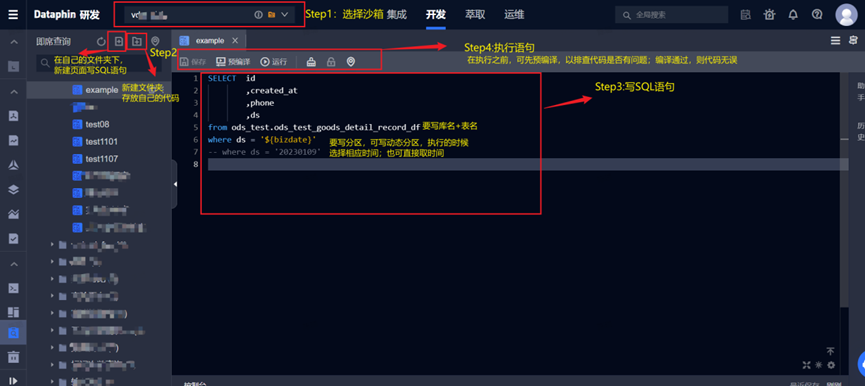
实例:
=======================================================
SELECT id
,created_at
,phone
,ds
from ods_test.ods_test_goods_detail_record_df
where ds = '${bizdate}'
-- where ds = '20230109'
========================================================
2.3 数据开发
必须选择可执行调度任务的沙箱权限。具体操作步骤如下:
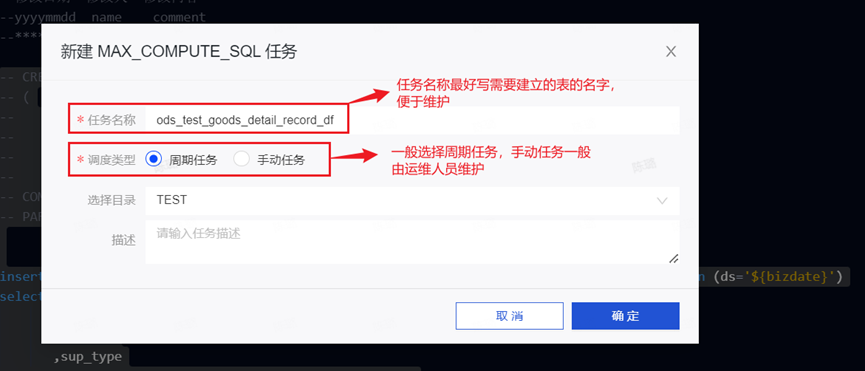
2.3.1:建表并写入数据库数据
Step1:新建页面,填写任务名称及调度类型,并点击确认。
Step2:建表&写入数据库数据
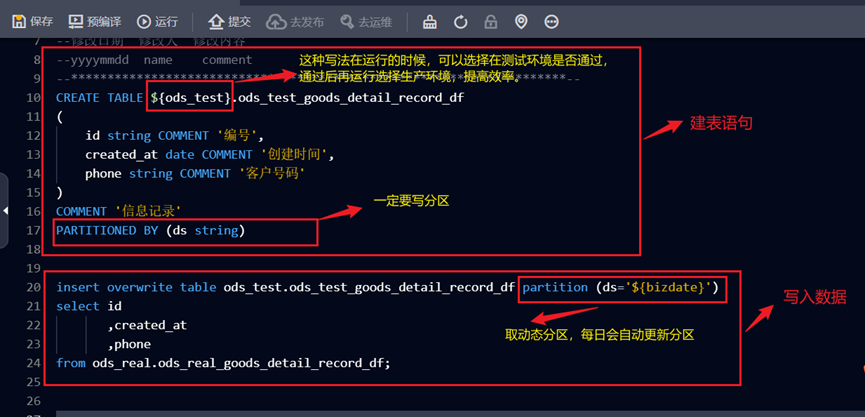
实例:
========================================================
CREATE TABLE${ods_test}.ods_test_goods_detail_record_df
(
id string COMMENT '编号',
created_at date COMMENT '创建时间',
phone string COMMENT '客户号码'
)
COMMENT '信息记录'
PARTITIONED BY (ds string)
=========================================================
insert overwrite tableods_test.ods_test_goods_detail_record_df partition (ds='${bizdate}')
select id
,created_at
,phone
fromods_real.ods_real_goods_detail_record_df;
=========================================================
Step3:运行、提交并发布。
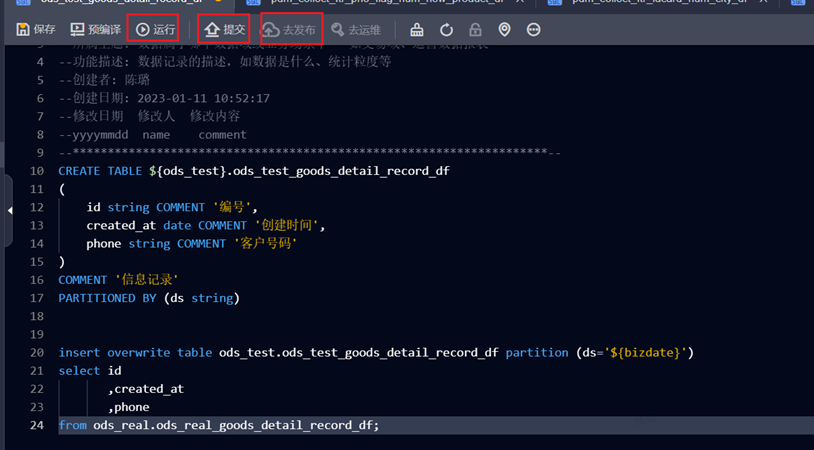
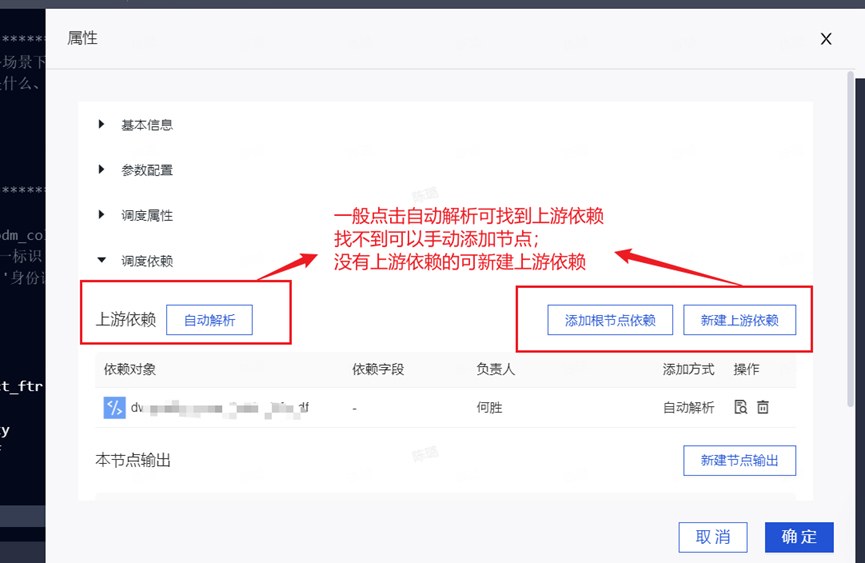
运行无误后,要填写属性进行调度配置
2.3.2:建表并写入本地数据
如果要写入本地数据,则需要如下步骤:
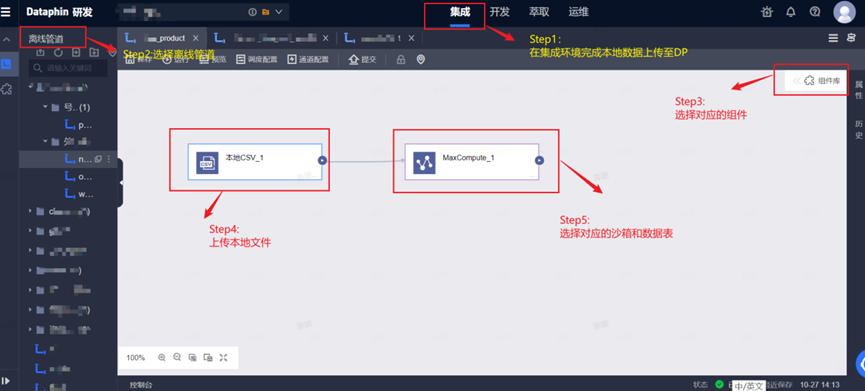
Step1&2:选择集成环境à新建页面à离线管道
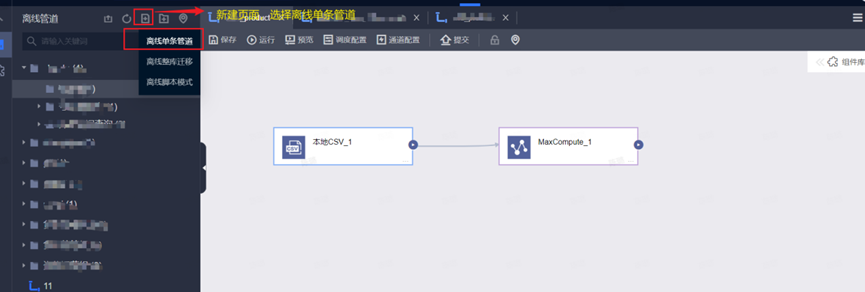
Step3:选择组件并拖入画布
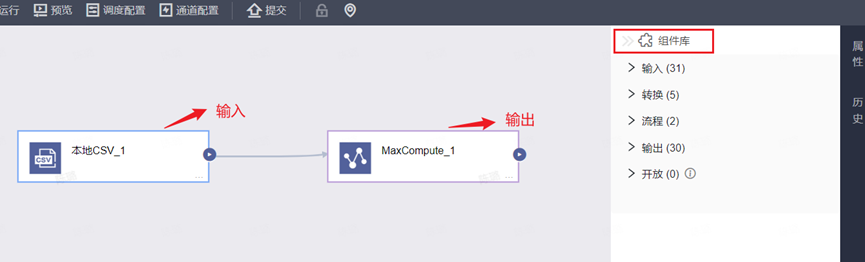
注:右键点击组件的三个点,可以进行配置、复制、删除等操作。
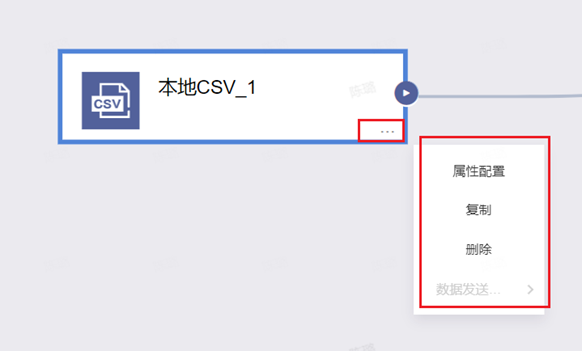
Step4:输入组件配置(以CSV文件为例)
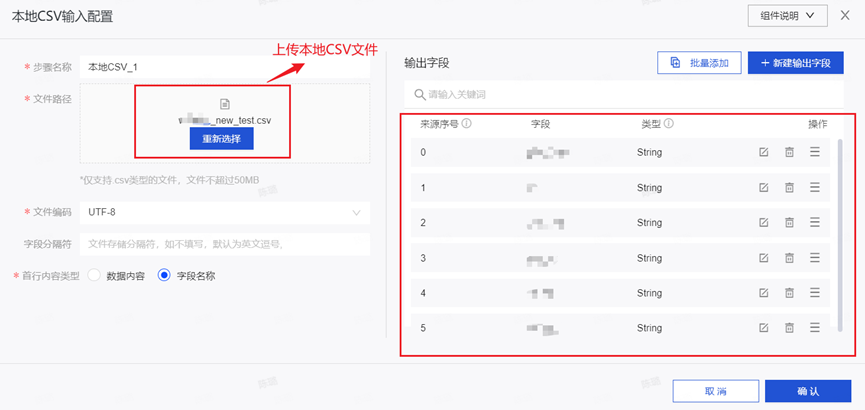
注:本地的CSV文件表头不要有中文,不然无法解析。
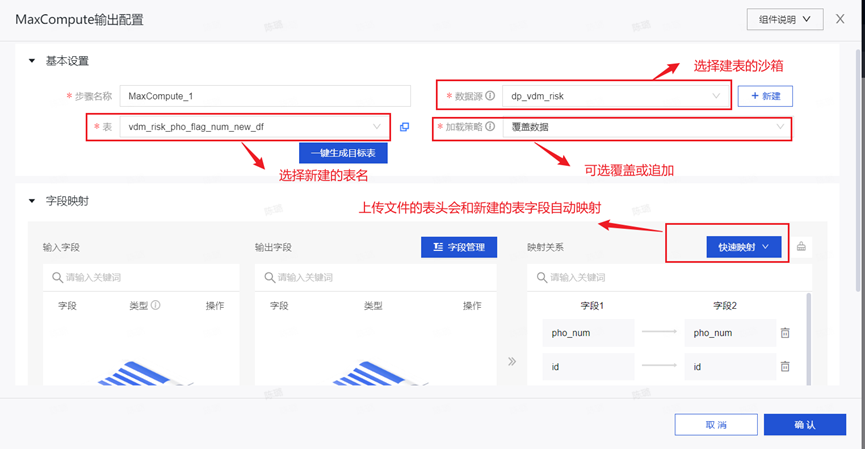
Step5:输出组件配置
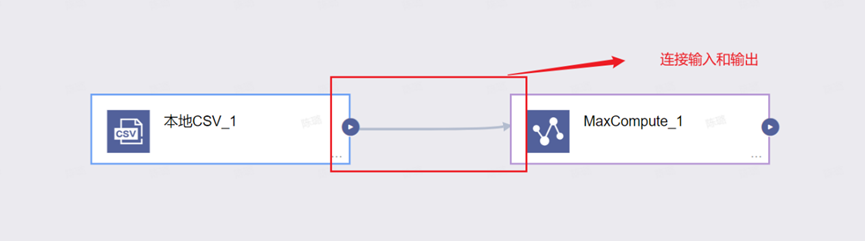
Step6:连接输入和输出
Step7:保存&运行&预览&提交
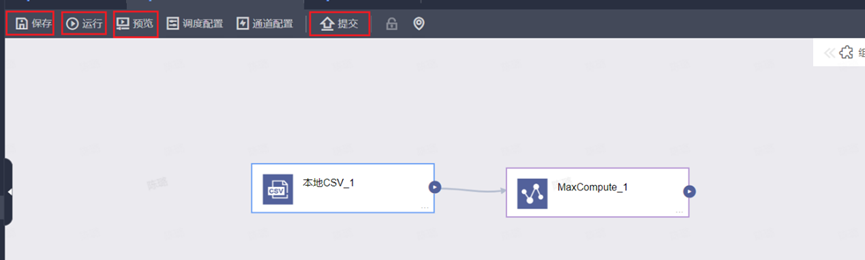
执行完上述步骤,即可在数据库查到相应的数据表和数据。
2.4 数据运维
2.5 连接Jupyter作数据分析
三. 常用文档及注意事项
3.1 常用文档
DP官网
https://help.aliyun.com/product/87584.html?spm=a2c4g.750001.list.108.4cc17b13iaSxMY
SQL对照表
https://help.aliyun.com/document_detail/96342.html
3.2常用释义
df/di
df指的是全量更新;di指的是增量更新。对于全量更新的表,取其最新分区即可;对于增量更新,根据数据需要的时间维度取分区即可。
ds:分区,DP取数必须要卡分区,不然会报错。即写sql语句的时候,where后一定要加ds = '${bizdate}'(动态分区)
统一命名规范
1)表字段、表名
表字段一般英文小写、不要用关键字命名字段,例如,datetime;
表名:结尾用df/di区分全量表还是增量表,开头加上数据库名,尽量能够在表明中描述清楚表的含义,单词间用短下划线连接。
例:ods_test.ods_test_goods_detail_record_df
2)脚本
脚本名称和输出结果表的名称保持一致
一个脚本尽应该只产生一张表,便于维护
添加必要注释
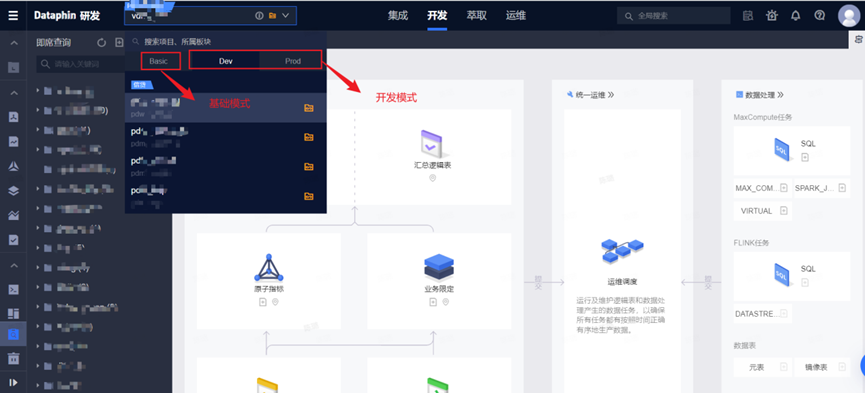
基础模式/开发模式
基础模式(Basic)只能查询,不可调度,故适合分析及策略人员;开发模式(Dev-Prod)可调度,适合数据开发人员。
3.3 常用SQL
时间/日期
日期与ds格式转换
date(call_time) = date(to_date('${bizdate}','yyyymmdd'))
ds =replace(date(dateadd(current_date(),-1,'day')),'-','')
datetime(concat(cast([日期(dte)] as string),' 00:00:00'))
date(to_date(ds,'yyyymmdd')) =date_add(current_date(),-2)
字符串
substr(b.uid,1,1) in ('0','2','f','4')
格式转换
cast(a.talk_length as bigint)
最后
以上就是阔达含羞草最近收集整理的关于【数据库】Dataphin操作文档的全部内容,更多相关【数据库】Dataphin操作文档内容请搜索靠谱客的其他文章。








发表评论 取消回复