一、YOLOV1
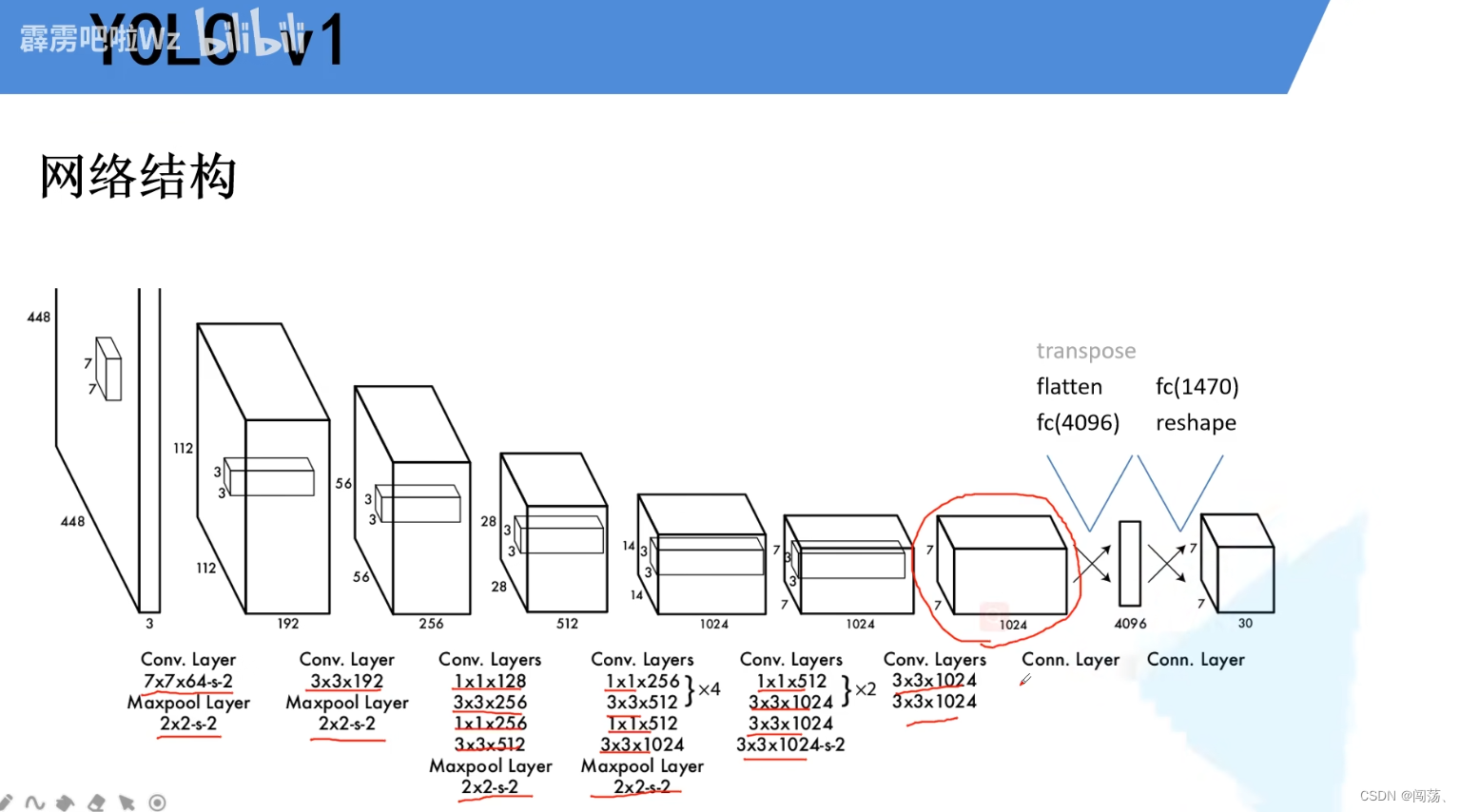 yolov1最后输出的是7x7x30,即最后的特征层为7x7=49个像素,因为是下采样后的,所以每个像素对应原图中的一块区域
yolov1最后输出的是7x7x30,即最后的特征层为7x7=49个像素,因为是下采样后的,所以每个像素对应原图中的一块区域
而30=1+4+1+4+20,也就是每个网格有2个bbox,输出的是位置信息和置信度,以及20分类
YOLOV1分为训练阶段、预测阶段
1.训练阶段
训练阶段,每个像素点(对应原图中的一块区域)预测两个Bbox,假设图像中有两个物体,原图中待测对象的中心点落在哪个网格中,则就由这个网格中的两个bbox进行预测对象,两个bbox又根据置信度舍去一个;
但是在这还要注意一个问题:其他grid预测的bbox咋办那,因为有置信度公式,它们也会计算置信度,只需要做到让它们的置信度非常小就行。
每个网格也只能预测一个类别
训练阶段中也就产生了三个损失:置信度、位置、种类损失;
最后网络也就输出了预测框的位置(x,y,w,h,conf,c);
通过损失函数反向传播------得到训练后的权重
置信度= bbox与GT的IOU值
2.预测阶段
加载训练之后的权重后,网络最后输出的仍然是7x7x30的张量,最后有49*2=98个bbox;
①首先通过设置confidence的阈值,去除掉一部分bbox,有的bbox中可能没有物体
②假如是20分类,然后每个类别都会进行NMS处理,选择最优的框,这样就得到了某个种类的预测框
NMS处理:20个种类,假设第一个种类是dog,将经过第一步骤后的bbox,根据是dog的概率进行排序,最大的先作为样本,然后依次给他作IOU比较,【所以,IOU设置过小,那么去除的框也就非常多,只有超过了这个阈值,才会去除掉剩余的框】
3.YOLOv1不足
1.对于群体的小目标检测效果差,因为每个网格的两个bbox都是针对同一个类别的置信度,所以比如当一群鸟飞过的时候,检测效果差;
2.不是基于anchor
3.对新的目标纵横比检测效果差
====================================================================================================================================================================================================================
二、YOLOV2
yolov1直接最后输出的是(7x7x30)的特征,直接输出bbox;
Fastet R-CNN、YOLOv2等以后算法都是基于anchor
1.什么是anchor
在深度学习时代,即使是R-CNN、Fast R-CNN都是基于滑窗来产生候选框,直到Faster R-CNN提出了RPN网络,RPN网络一个重要的概念就是anchor
窗口滑动的时候,本质就是遍历像素的过程,因此直接为每个像素分配不同的尺度和比例的窗口矩形,它们的中心都是其所属的像素点。对于长度和比例的分配们可以根据标注图像信息通过k-means聚类得到。而每个像素分配几个不同长度和比例的窗口举行就是Anchor。
2.举例
假设一张256256大小的图片,经过64,、128、256倍率的下采样,产生44,、22、11大小的特征图,在这三个特征图每个像素点上设置三个不同大小的矩形框,就是anchor。所以来说anchor的位置是固定的,从而根据偏移、倍率计算出真实的预测框。
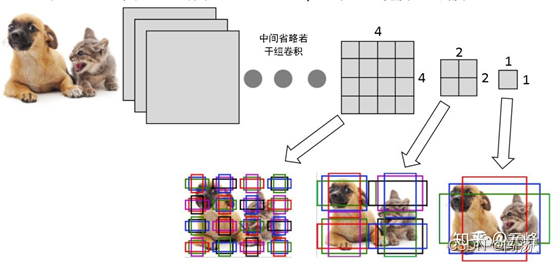
3.anchor大小、比例设置也很重要
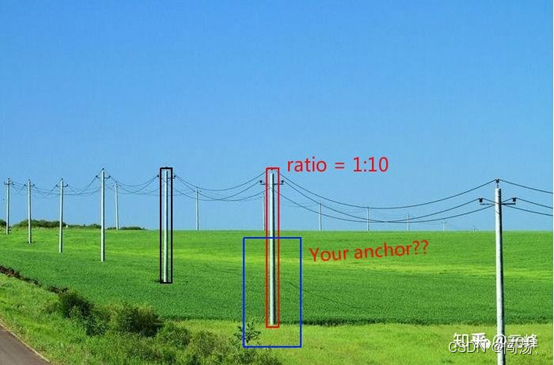
如图,电线杆的宽高比可能不止1:10,而且特别细。如果您设置的anchor长宽比为1:1、1:2、 2:1、 1:3、 3:1这五个不同的长宽比,那可能到导致在训练的时候,没有哪个anchor与电线杆的IoU大于0.5,导致全部为负样本。
在YOLOV3中9个anchor的大小如下,(有三个特征层,每个特征层上每个像素点有三个anchor)

三、YOLOV3

最后
以上就是无辜服饰最近收集整理的关于YOLO-V3过程示意图的全部内容,更多相关YOLO-V3过程示意图内容请搜索靠谱客的其他文章。








发表评论 取消回复