接前述,数据读取
上次遗留下两个问题:
-
1、该案例的数据集过多 ,如果每次读一个数据的部分行(比如10000行),那在拼接所有数据集的时候也是每个数据只读10000行吗??
回答:虽然我们通过更改数据类型,使得原始数据的大小有所改变,但如果想要把所有的数据集合拼接读取出来,也是依旧对内存有一定要求的。 -
2、对于表字段含义的理解,我们接下来将以taxiGps20200619.csv为例进行字段含义的说明
- 简介
2020年端午前一周A城市巡游车GPS数据,文件名:taxiGps20190603.zip
- 具体数据项
CARNO:车牌号、
LATITUDE:纬度(WGS84 GPS标准)、
LONGITUDE:经度(WGS84 GPS标准)、
GPS_DATE:卫星定位时间、
DIRECTION:行驶方向角、
SPEED:GPS速度、
RUNNING_STATUS/OPERATING_STATUS: 运营状态(空车(1)、载客(2)、电召(4)、停运(8)、交班(16)、包车(32))
- 数据范围
20190603A城市巡游车GPS数据,预估(635M,2000万条)

从描述统计来看,我们可以发现,经度和纬度存在0值,表明存在错误,这个问题可以尝试平滑插值。
另外,可以看到GPS速度的最大值为1922,不合常理。
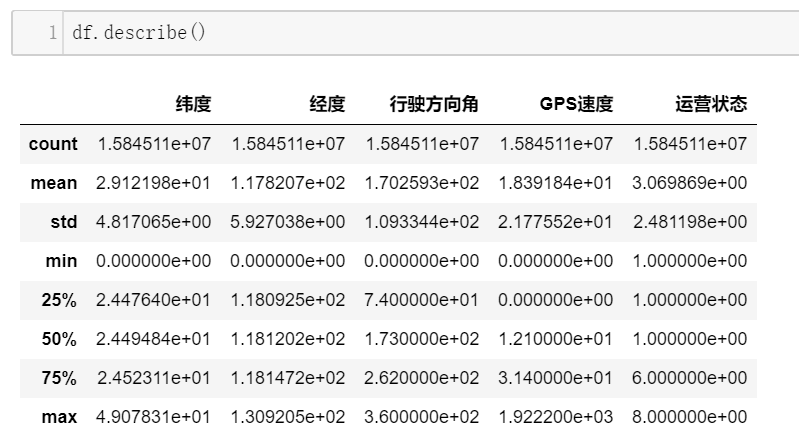
注意:行驶方向角即汽车前进的方向。
- 查看是否有缺失值
df.isnull().sum()
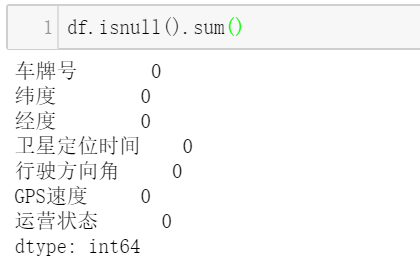
熟悉一下数据:
taxiGps20190603这个数据集中有6727辆车,涉及到的运营状态有三种,分别为1,6,8【运营状态(空车(1)、载客(2)、电召(4)、停运(8)、交班(16)、包车(32))】。
最后
以上就是懦弱胡萝卜最近收集整理的关于DCIC-A城市巡游车与网约车运营特征对比分析-2-可视化的全部内容,更多相关DCIC-A城市巡游车与网约车运营特征对比分析-2-可视化内容请搜索靠谱客的其他文章。








发表评论 取消回复