mongoDB 概述
*********************
基本概念
数据库:类似于mysql 的数据库,可存储多个集合(collection)
集合:类似于mysql的表,存储文档,分普通集合、固定集合(capped collection,大小固定,如果空间不足,最早的文档会被删除)
文档:存储数据,存储格式为BSON(json格式的拓展)

*********************
_id:文档的唯一标识
每条文档都有一个"_id",如果没有设置,默认为ObjectId;
同一个集合文档的_id不能重复,不同集合文档的_id可以重复
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 时间戳 | 主机名 | 进程号 | 计数器 | ||||||||
ObjectId:占12个字节
时间戳:4字节,单位为秒
主机标识:3字节
进程号:2字节
计数器:3字节,单调递增,保证同一主机、同一进程在同一秒的ObjectId唯一
*********************
gridfs:存储大型文件
作用:单个BSON对象存储的文档大小不能超过16m,当存储文件时,如果文件太大,可以使用gridfs进行存储
工作原理:gridfs规范指定文件分块标准,将文件分块之后,封装成BSON对象存储,同时记录文件的分块信息,当时用的时候,按顺序拼接返回完整的文件
*********************
mongoDB 存储原理
读过程:通过内存映射将磁盘中的数据映射到内存,读直接从内存中读取数据
写过程:将数据写入内存,然后由系统定时刷新到磁盘,为防止数据丢失,mongoDB提供了journal,默认情况下,每隔100毫秒将数据写入journal中,保证了数据安全
存储引擎
MMAPv1:提供集合级别的锁;为文档分配2的N次方的存储空间(4.2版本开始,移除MMAPv1)
WiredTiger(默认):提供文档级别锁,支持乐观并发控制;支持文档压缩
in-memory:所有数据存储在内存,不持久化数据,断电后数据丢失,适合用mongoDb做缓存的场景
*********************
副本集
基本特性
主节点故障后可自动将从节点切换为主节点;
从节点可做数据备份,防止主节点故障后数据丢失;
主节点上接受写入请求,从节点上读取数据,可实现速写分离
节点类型
{
_id: <int>,
host: <string>, // required
arbiterOnly: <boolean>, // ture:仲裁节点,不复制数据,默认为false
buildIndexes: <boolean>, // 默认:true,可创建索引
hidden: <boolean>, // true:对客户端不可见,默认为false
priority: <number>, // 默认1,为0表示节点不能被选为primary节点
tags: <document>, // 默认不添加标签
slaveDelay: <int>, // 从节点复制延时时间,默认:0
votes: <number> // 可选值:0、1(默认),为0表示节点没有投票权
} //如果priority>0,则votes>0主节点:写入数据(priority>0,votes>0)
从节点:备份主节点数据,对外提供读取服务
仲裁节点:辅助投票,不备份数据,不能成为主节点(priority=0,votes=1,arbiterOnly=true)
非投票节点:只负责备份数据,没有投票权,不能称为主节点(priority=0,votes=0)
rs.add( { _id:"number", host: "host:27017", priority: 0, votes: 0 } ) //添加非投票节点
工作原理
副本集中的节点通过心跳检测监控节点的健康状况,当主节点不能正常工作时,触发故障转移
当主节点失去大多数其它节点的心跳,会自动降级为从节点,防止网络恢复后出现多个主节点
数据复制过程
主节点将写入请求写入oplog(oplog为固定集合,不记录读操作);
从节点监控主节点oplog,本地执行写入操作,同时写入本地oplog;
主节点记录从节点复制状态,确保从节点跟上主节点的数据更新;
如果从节点落后太多,主节点阻塞等待,满足指定数量的从节点同步后,接受客户端写入请求
说明:从节点首次启动时,会对主节点数据进行全量复制(主节点local数据库除外)
复制状态:主从节点交互状态(复制时间戳、选举状况)
复制状态的文档数据保存在local数据库中,local数据库中的数据不会被从节点复制
主从节点都会检查本地的local数据库,确保从节点跟上主节点的数据更新
故障转移
当主节点故障后,触发故障转移,投票选举新的主节点,
优先投票给数据最新的从节点,
当不能选举产生主节点时,仲裁节点也会辅助投票,
投票产生主节点后,从节点切换主节点,并做数据同步,
此外,如果节点设置了优先级,优先级最高的节点没有成为主节点,运行一段时间后,会重新触发选举,将优先级最高的节点切换为主节点
数据回滚
新的主节点选举出来后,从节点需要与主节点进行数据同步;
如果从节点oplog中的数据在主节点的oplog中没有相关记录,需要删除相关数据
*********************
分片集群
使用场景:数据量很大时,将数据按照分片策略拆分,分散存储在不同的分片上
分片策略:区间分片、hash分片、标签分片
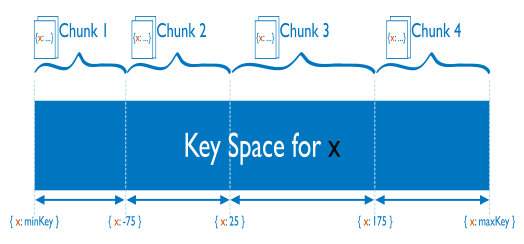
区间分片:按照指定分片字段的先后顺序分片,支持复合分片键;如果分偏见对应的数据线性增长,可能会造成一段时间的数据大量的请求落在某个分片上
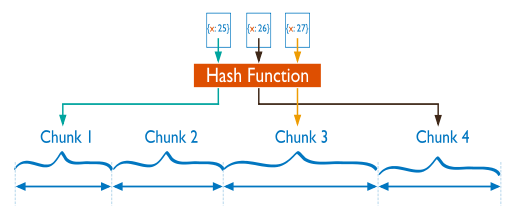
hash分片:将指定的字段hash取值后分片,只支持单分片键;这种分片方式使数据分布更均匀
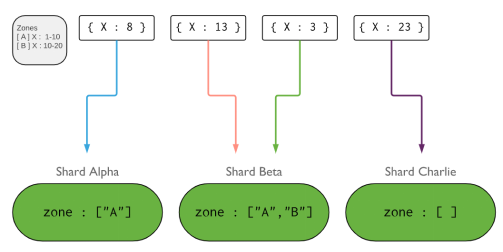
标签分片:分片服务器打标签,设置标签对应分片键的数据范围,插入数据时,在范围内的文档会自动存储到对应的分片,若不在范围内,可随机选取分片存储
应用场景:将日志数据存储到低配置的服务器;
用户数据量较小时,将用户数据(user)存储到同一个分片服务器上,提高查询效率
迁移块
数据分流后以块的形式存储在分片中,块的大小最大为64m或者文档数量达到100000后就继续分块;
分块后的两个分块数据量为原来的一半,此时的分块只是修改块的元数据信息,真实的物理存储位置并未发生改变;
当不同的分片块的数量相差很大时(一般为8),就会触发块的迁移,直至各分片块的数量大致相等为止
*********************
读写级别
写级别(write concern)
{ w: <value>, j: <boolean>, wtimeout: <number> }w:0 :数据写入主节点内存,不返回写入结果
w:1 :数据写入主节点内存,返回写入结果
w:2 :数据写入主节点内存、至少一个从节点内存,返回写入结果
w:n :数据写入主节点内存,至少n-1 个从节点内存,返回写入结果
w:majority :数据写入超过半数的副本集内存,返回写入结果
j:true :数据写入磁盘
wtimeout:value :写入超时时间,在w:n>1时生效
读级别(read concern)
local:读取写入本地的数据,不保证数据已被副本集中大部分(majority)节点写入
available:读取的数据不保证被副本集中的大部分节点写入
majority:读取副本集中大部分(majority)节点已经写入内存的数据
linerizable:读取副本集中大部分(majority)节点已经写入内存的数据
snapshot:快照数据,在write concern为majority前提下,可保证读取到一致性的数据
*********************
事务读写级别
***************
read preference
If the transaction-level read preference is unset,
the transaction uses the session-level read preference.
If transaction-level and the session-level read preference are unset,
the transaction uses the client-level read preference.
By default, the client-level read preference is primary.事务中如果没有设置read preference,默认使用primary,即读取主节点数据
***************
read concern
If the transaction-level read concern is unset, the transaction-level read concern
defaults to the session-level read concern.
If transaction-level and the session-level read concern are unset,
the transaction-level read concern defaults to the client-level read concern.
By default, client-level read concern is "local" for reads against the primary如果没有设置read concern,默认为local
事务中支持的read concern
local:读取本地数据,数据可能会回滚
majority:在分片集群中,不能保证跨分片数据的是同一个快照中的数据
snapshot:分片集群中,可保证跨分片数据来自同一个数据快照
***************
write concern
If the transaction-level write concern is unset, the transaction-level write concern
defaults to the session-level write concern for the commit.
If the transaction-level write concern and the session-level write concern are unset,
transaction-level write concern defaults to the client-level write concern. By default,
client-level write concern is w: 1. 如果没有设置write cocern,默认为w:1
w:1
When you commit with w: 1 write concern, transaction-level "majority" read concern provides
no guarantees that read operations in the transaction read majority-committed data.
When you commit with w: 1 write concern, transaction-level "snapshot" read concern provides
no guarantee that read operations in the transaction used a snapshot of majority-committed dataread concern:majority :不能保证读取的数据被副本集中的大部分节点提交
read concern:snapshot :不能保证分片集群中读取的是同一个快照中的数据
w:majority
When you commit with w: "majority" write concern, transaction-level "majority" read concern
guarantees that operations have read majority-committed data. For transactions on sharded
clusters, this view of the majority-committed data is not synchronized across shards.
When you commit with w: "majority" write concern, transaction-level "snapshot" read concern
guarantees that operations have from a synchronized snapshot of majority-committed data.read concern:majority :不能保证分片集群中读取的是同一个快照的数据
read concern:snapshot :分片集群中读取的是同一个快照的数据
最后
以上就是飞快灰狼最近收集整理的关于mongoDB 概述的全部内容,更多相关mongoDB内容请搜索靠谱客的其他文章。








发表评论 取消回复