文章目录
- 插件编写分析举例
- 文本文件输入插件分析
- BaseStep
- BaseStepMeta
- 编写插件需要知识点总结
- 其他参考
插件编写分析举例
文本文件输入插件分析
我们以 文本文件输入插件 举例:
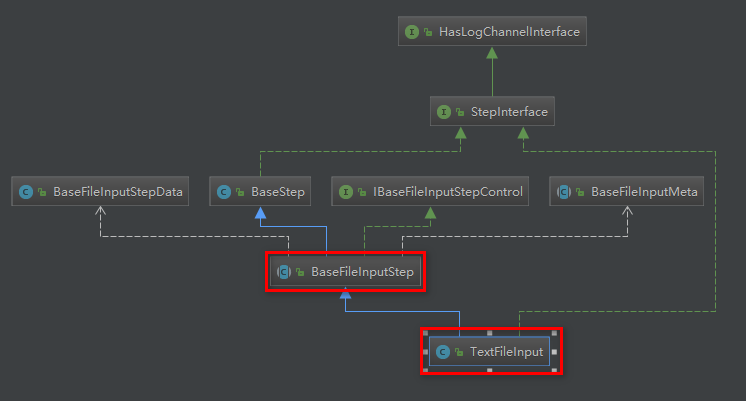
 插件继承关系
插件继承关系
public class TextFileInput extends BaseFileInputStep<TextFileInputMeta, TextFileInputData> implements StepInterface {
private static Class<?> PKG = TextFileInputMeta.class; // for i18n purposes, needed by Translator2!!
TextFileInput 继承自抽象类BaseFileInputStep。
TextFileInput 复写了init()类。
BaseFileInputStep抽象类,完成主要的文本输入插件功能。
这里BaseFileInputStep<M extends BaseFileInputMeta<?, ?, ?>, D extends BaseFileInputStepData> 抽象类泛型传入的参数为<TextFileInputMeta, TextFileInputData>
-
抽象step类BaseFileInputStep init( StepMetaInterface smi, StepDataInterface sdi )方法
初始化线程初始化step时,会调这个抽象类的init方法。
这里它先调它抽象父类BaseStep的init方法,BaseStep是所有自定义插件需要继承的类。
然后执行自己的一些处理,
在最后它调用子类的init方法,return init();总结:这里有个很好的编程技巧,这里抽象类BaseFileInputStep init中既把父类BaseStep的init调用了,也把子类的init调用了。
-
抽象类BaseFileInputStep的processRow()方法
/**
* Process next row. This methods opens next file automatically.
*/
@Override
public boolean processRow( StepMetaInterface smi, StepDataInterface sdi ) throws KettleException {
meta = (M) smi;
data = (D) sdi;
if ( first ) {
first = false;
prepareToRowProcessing();
if ( !openNextFile() ) {
setOutputDone(); // signal end to receiver(s)
closeLastFile();
return false;
}
}
while ( true ) {
if ( data.reader != null && data.reader.readRow() ) {
// row processed
return true;
}
// end of current file
closeLastFile();
if ( !openNextFile() ) {
// there are no more files
break;
}
}
// after all files processed
setOutputDone(); // signal end to receiver(s)
closeLastFile();
return false;
}
分析:主要分成三部分,
1)一部分为第一次开始执行调 prepareToRowProcessing();
2)openNextFile()
这个方法里面会调子类createReader,创建读文件reader实例,并把meta、data、data.file传入
data.reader = createReader( meta, data, data.file );
@Override
protected IBaseFileInputReader createReader( TextFileInputMeta meta, TextFileInputData data, FileObject file )
throws Exception {
return new TextFileInputReader( this, meta, data, file, log );
}
3)data.reader.readRow() 具体文件行处理。
- 分析prepareToRowProcessing();
为什么不在step插件的init方法中,读取文件呢?因为文件可能是从上一个step获取,是上一个step的执行结果,所以放在proccessRow()阶段。
这里看代码,应该是没有读取真正的文件,就对文件字段的一些处理。
- data.reader.readRow() 分析
- 读取文件到行缓存
public List lineBuffer;
读的行还会做一些过滤,只有通过过滤的行,才会添加到缓存行对象中。
tryToReadLine( boolean applyFilter )
if ( applyFilter ) {
// Filter row?
boolean isFilterLastLine = false;
boolean filterOK = checkFilterRow( line, isFilterLastLine );
if ( filterOK ) {
data.lineBuffer.add( new TextFileLine( line, lineNumberInFile++, data.file ) ); // Store it in the
// line buffer...
} else {
return false;
}
}
- 从行缓存中读取第一行到TextFileLine 类实例,并且行缓存删除第一行
TextFileLine textLine = data.lineBuffer.get( 0 );
data.lineBuffer.remove( 0 );
- 对文件内容之类有一些分支,处理文本中分页的,处理文本页脚的,剩下的才是真正处理用户想要的数据行。还有对固定折行标识的处理。
也就是说,它这里对文本文件有些特殊的处理,从而取真正的数据行。
然后调
TextFileInputUtils.convertLineToRow
把行数据转换为 Object[] r;
r =
TextFileInputUtils.convertLineToRow( log, textLine, meta, data.currentPassThruFieldsRow,
data.nrPassThruFields, data.outputRowMeta, data.convertRowMeta, data.filename, useNumber,
data.separator, data.enclosure, data.escapeCharacter, data.dataErrorLineHandler,
meta.additionalOutputFields, data.shortFilename, data.path, data.hidden,
data.lastModificationDateTime, data.uriName, data.rootUriName, data.extension, data.size )
BaseStep
BaseStep是 step插件处理行实现类,自定义类继承该类实现自己的step插件,它提供了许多实用的方法。
常用方法、成员变量整理
- init( StepMetaInterface smi, StepDataInterface sdi )
初始化step会调该方法,写自定义插件时可以覆写该方法,还可以利用调super.init这种方式,复用BaseStep的init方法。 - public Trans getTrans()
获取trans对象
如下,通过返回的trans对象,我们可以获取之前的执行结果。
Result previousResult = getTrans().getPreviousResult(); - Object[] getRow()
通过input rowset从前面的steps接收数据。 - void putRow( RowMetaInterface rowMeta, Object[] row )
Putrow用于复制一个row到rowset或rowsets,这应该比其他所有行具有优先级!
(synchronized)如果distribute为true,则一行只复制一次到所有的rowset(rowsets),否则副本将发送到单个rowset。
注意: rowMeta行元信息,这个参数不能为null,否则报异常Unable to clone row for metadata : null
也就是说Object[] row必须对应有行元信息!
- boolean outputIsDone()
BaseStepMeta
public class BaseStepMeta implements Cloneable, StepAttributesInterface {
此类负责实现有关step meta的公共方法,如日志记录。
- void getFields
该方法可以让后续step读到字段列表
自定义stepMeta可以通过覆写该方法 让后续step读到自定义的字段信息。
outputFields为 JSONArray类型的变量,为自定义插件配置的字段信息。
/**
* 该方法可以让后续step读到字段列表
*/
@Override
public void getFields(RowMetaInterface rowMeta, String origin, RowMetaInterface[] info, StepMeta nextStep,
VariableSpace space, Repository repository, IMetaStore metaStore ) throws KettleStepException {
try {
//如果指定了输出字段,则清除原有的后新加字段
if(outputFields.size()>0) {
rowMeta.clear(); // Start with a clean slate, eats the input
}
for (int i = 0; i < outputFields.size(); i++) {
JSONObject field = outputFields.getJSONObject(i);
ValueMetaInterface valueMeta = ValueMetaFactory.createValueMeta(field.getString("name"),
ValueMetaFactory.getIdForValueMeta(field.getString("type")));
valueMeta.setOrigin(origin);
rowMeta.addValueMeta(valueMeta);
}
} catch (Exception e) {
throw new KettleStepException(e);
}
}
总结:可以使用该方法生成自定义字段。
编写插件需要知识点总结
- step执行完毕,需要置step状态为停止,这时step线程就会跳出while(true)循环。
如下step运行线程Runnabble对象 RunThread中isStopped()方法判断的是BaseStep类的成员变量private AtomicBoolean stopped;
// Wait
while ( step.processRow( meta, data ) ) {
if ( step.isStopped() ) {
break;
}
}
注意:这里while条件是 processRow的返回值,我们自定义插件processRow 返回false就会跳出while循环!注意!
processRow返回false,这个step执行完毕,看kettle界面,step插件右上角会有一个对号的图标。
- 区分插件init()方法和 processRow()方法的在哪个阶段执行
trans需要在step启动后执行的东西(需要上一个step结果),要放在processRow()函数阶段,放在init()中,是在step实例化阶段执行,这时上个step还没有执行,它需要从队列rowSet拿数据就拿不到。
其他参考
kettle通用插件[kettlePlugins]使用说明
参考URL: https://my.oschina.net/nivalsoul/blog/1620664
最后
以上就是拼搏御姐最近收集整理的关于IDEA下kettle 步骤插件开发的全部内容,更多相关IDEA下kettle内容请搜索靠谱客的其他文章。








发表评论 取消回复