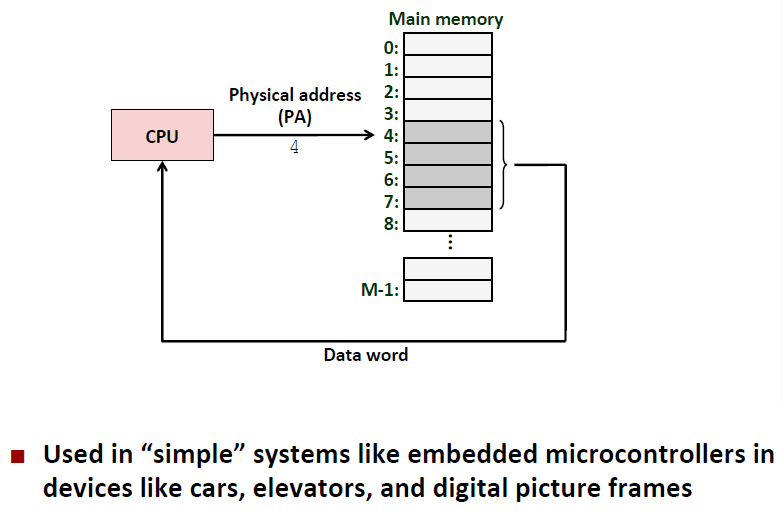
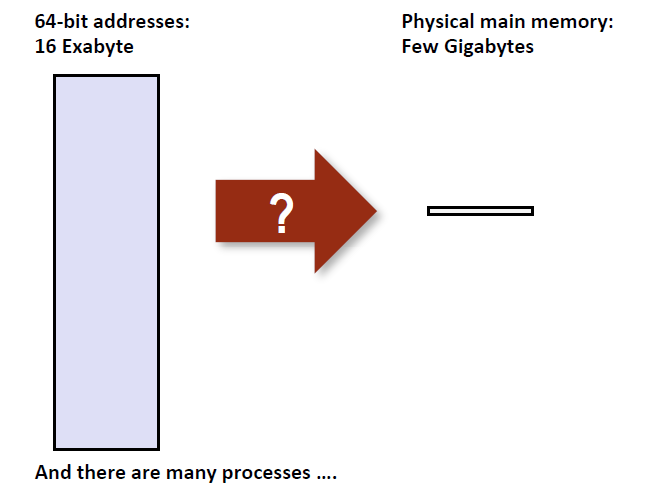
在有进程地址空间虚拟化概念之前,所有的程序都得实打实的知道自己在物理内存中的分配(程序员手写分配啊!!!)。如果程序小、少,还能凑合着进行管理,但是,面对实际的多程序,大体量程序,不得不将内存的管理与程序的编写进行分离,尽管这样做“有一点1”降低效率。
Using Physical Address:
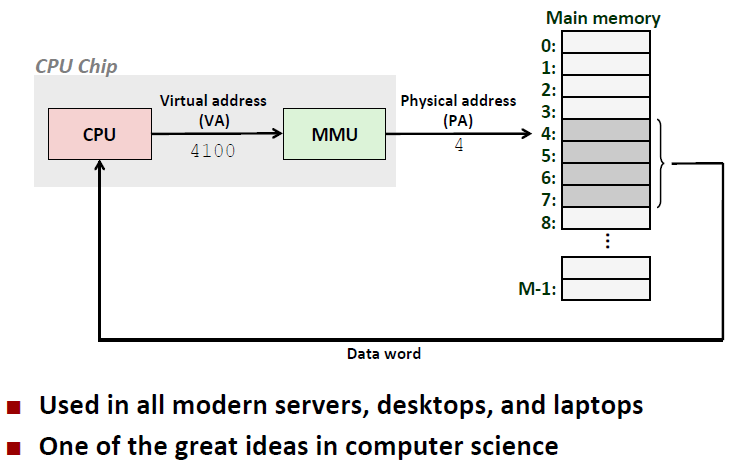
Using Virtual Address:
一、地址虚拟化与进程私有地址空间
进程的地址空间是私有的,名曰:私有地址空间。何为私有,这就与虚拟化有关了。操作系统 将内存地址的概念(虚拟地址)从内存地址的实现(物理地址)中抽象出来了,使得编程工作者可以不用考虑自己编写的代码、变量等数据在终端运行的时候具体位于哪块物理内存地址中。在编写程序时,我们无需关心对物理内存的分配,也不用担心不同的进程对”相同地址值2“操作时是否产生冲突,带来数据的不一致性。
code
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include "common.h"
int
main(int argc, char *argv[])
{
int *p = malloc(sizeof(int)); // a1
assert(p != NULL);
printf("(%d) memory address of p: %08xn", getpid(), (unsigned) p); // a2
*p = 0; // a3
while (1) {
Spin(1); //这个函数的作用是1s之后返回
*p = *p + 1;
printf("(%d) p: %dn", getpid(), *p); // a4
}
return 0;
}
输出
程序在关闭栈随机化功能的情况下运行。
prompt> ./mem &; ./mem &
[1] 24113
[2] 24114
(24113) memory address of p: 00200000
(24114) memory address of p: 00200000
(24113) p: 1
(24114) p: 1
(24114) p: 2
(24113) p: 2
(24113) p: 3
(24114) p: 3
(24113) p: 4
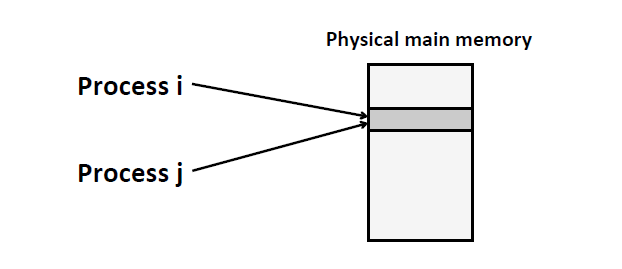
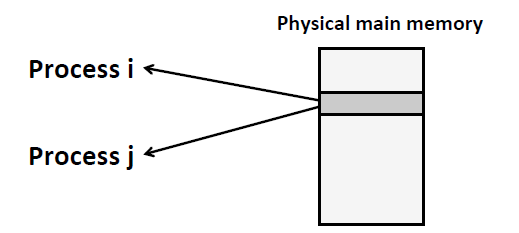
(24114) p: 4可以看到,两个进程,进程号不同,但是p的地址是一样的,不过这两个进程似乎在不同的地址空间运行,因为它们对p的修改互不影响。确实如此,因为操作系统将内存虚拟化了。
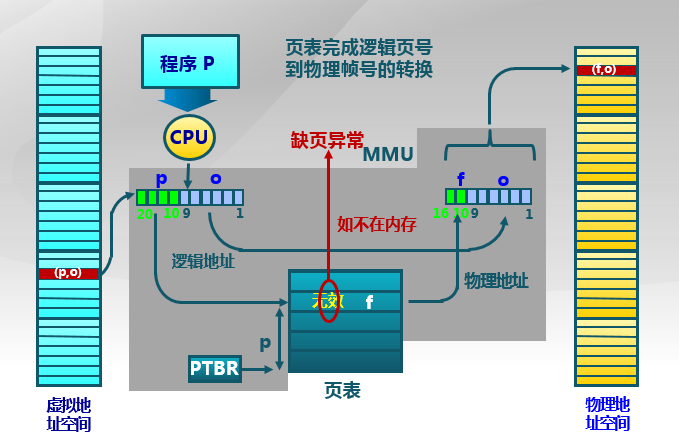
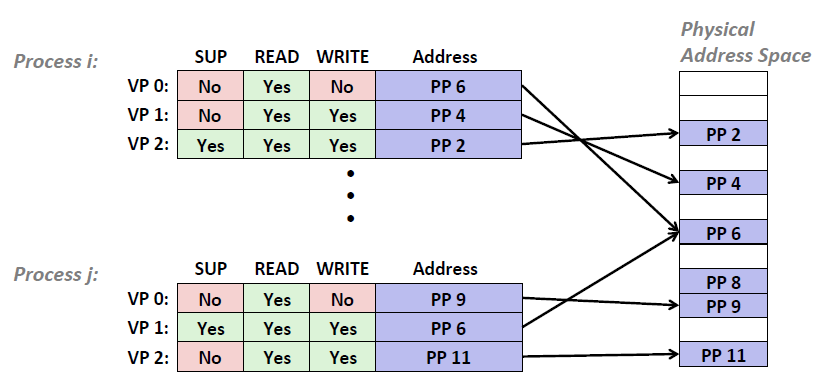
图一:页表与地址空间转换
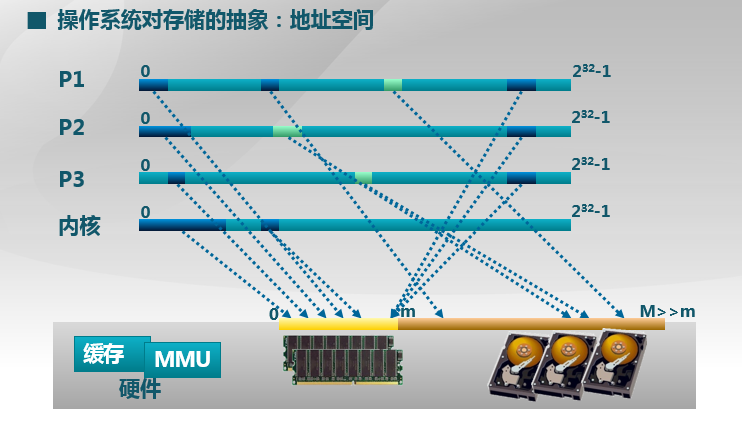
图二:不同进程的地址空间映射
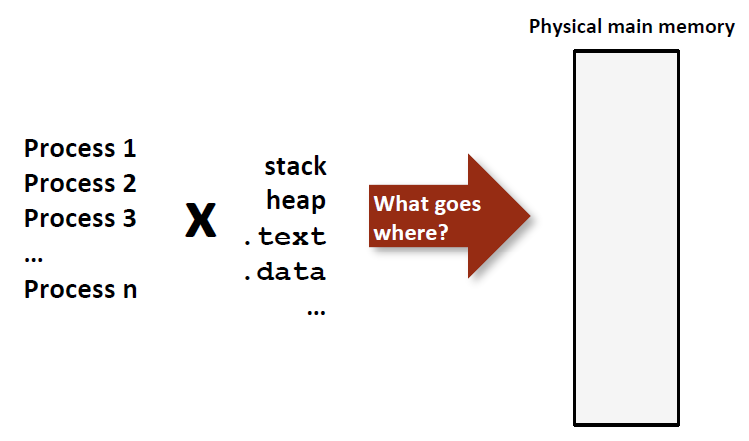
1.1 虚拟内存
1.1.1 Why
How Does Everything Fit?
Memory Management:
how to protect:
how to share:
1.1.2 solution
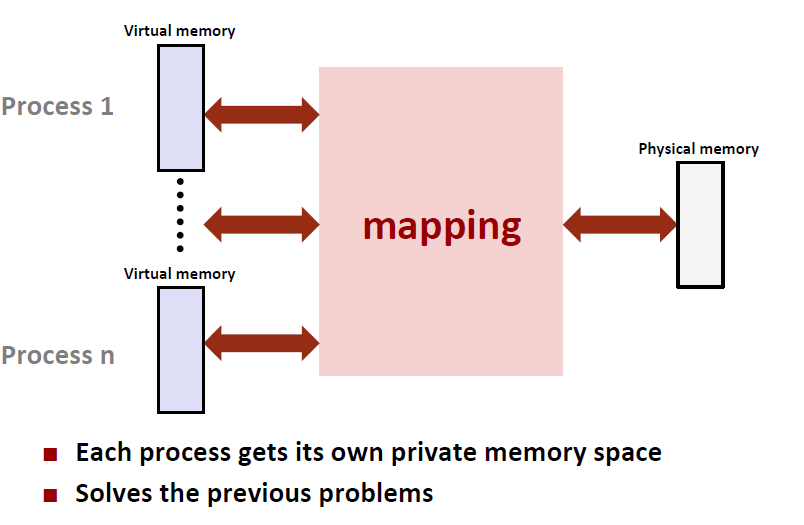
1.1.3 Benefit
simplifying linking and loading:
memory protection:
. Extend PTEs with permission bits
. Page fault handler checks these before remapping
if violated, send process SIGSEGV(segnmentation fault)
二、Unix操作进程的系统调用
2.1 获取进程ID
getpid函数和getppid函数:getpid函数返回调用这个函数的进程的PID3,getppid函数返回它的父进程的PID(创建调用这个函数的进程的进程)。
#include<sys/types.h>
#include<unistd.h>
pid_t getpid(void);
pid_t getppid(void);pid_t定义在types.h中,类型为int.
2.2 创建和终止进程
1)终止。进程会因为三种原因终止:
- 收到一个信号,该信号的默认行为是终止进程。
- 从主程序返回。
- 调用exit函数。
#include<stdlib.h>
void exit(int status);exit函数以status退出状态来终止进程。
2)fork函数。父进程通过调用系统调用fork函数创建一个新的运行子进程。
#include<sys/types.h>
#include<unistd.h>
pid_t fork(void);新创建的子进程几乎但不完全与父进程相同。子进程得到与父进程用户级虚拟地址空间相同的(但是独立的)一份拷贝4,包括文本、数据和bss 段、堆以及用户栈。子进程还获得与父进程任何打开文件描述符相同的拷贝,这就意味着当父进程调用fork 时,子进程可以读写父进程中打开的任何文件。父进程和新创建的子进程之间最大的区别在于它们有不同的PID。
如果能够在fork 函数在父进程和子进程中返回后立即暂停这两个进程,我们会看到每个进程的地址空间都是相同的。每个进程有相同的用户栈、相同的本地变量值、相同的堆、相同的全局变量值,以及相同的代码。
fork函数被父进程调用一次,返回两次:一次返回到父进程中,返回值是子进程的PID,一次返回到新创建的子进程中,返回值是0。返回值提供一个明确的方法来分辨程序是在父进程还是在子进程中执行。父进程和子进程在返回之后并发运行。
2.3 加载并运行程序
execve函数在当前进程的上下文中加载并运行一个新程序。
#include<unistd.h>
int execve(const char *filename, const char *argv[], const char *envp[]);
//如果成功,则不返回,如果错误,则返回-1。
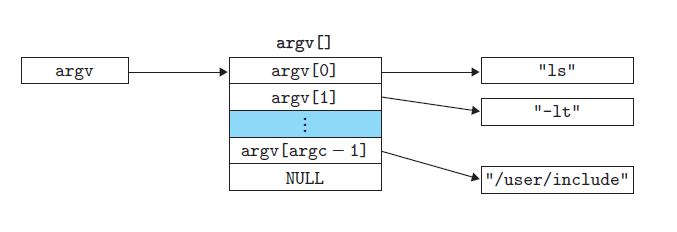
参数列表
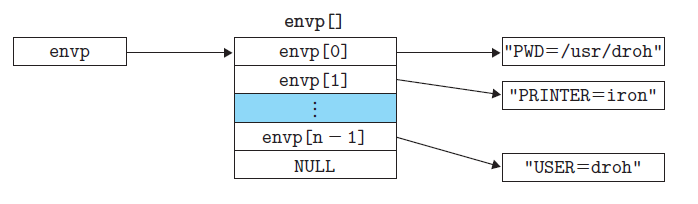
环境列表
execve函数加载并运行可执行目标文件filename,且带参数列表argv和环境变量列表envp。作用是根据指定的文件名找到可执行文件,并用它来取代调用进程的内容,换句话说,就是 在调用进程内部执行一个可执行文件。这里的可执行文件既可以是二进制文件,也可以是任何Linux下可执行的脚本文件。
与一般情况不同,函数执行成功后不会返回,因为调用进程的实体,包括代码段,数据段和堆栈等都已经被新的内容取代,只留下进程ID等一些表面上的信息仍保持原样,颇有些神似”三十六计”中的”金蝉脱壳”。看上去还是旧的躯壳,却已经注入了新的灵魂。只有调用失败了,它们才会返回一个-1,从原程序的调用点接着往下执行 5。
在execve 加载了filename 之后,它调用启动代码。启动代码设置栈,并将控制传递给新程序的主函数,该主函数有如下形式的原型
int main(int argc , char **argv, char **envp)
或者等价地,
int main(int argc , char *argv[] , char *envp[])j
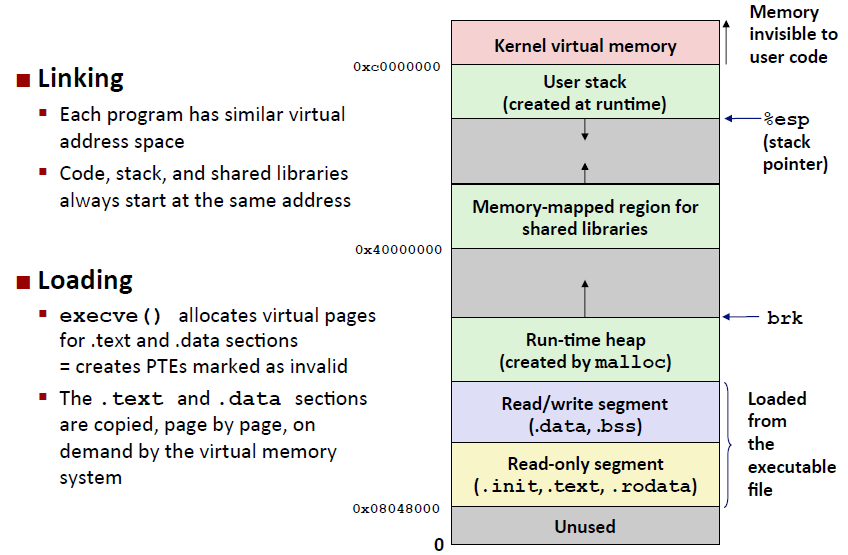
当main 开始在一个32 位Linux 进程中执行时,用户栈有如下图所示的组织结构。
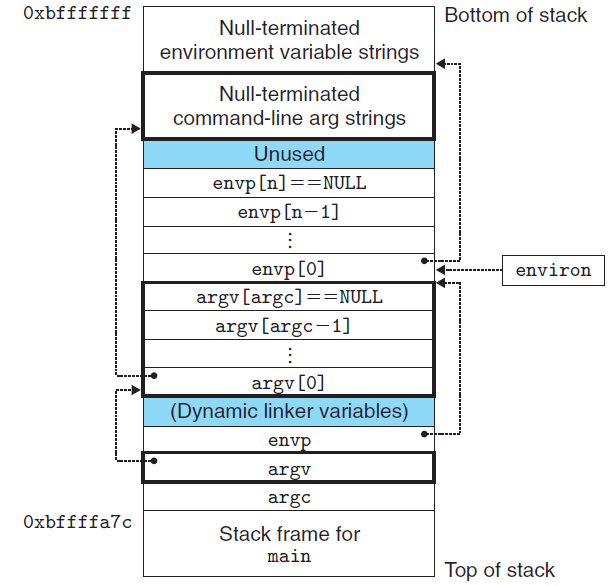
让我们从栈底(高地址)往栈顶(低地址)依次看一看。首先是参数和环境字符串,它们都是连续地存放在栈中的,一个接一个,没有分隔。栈往上紧随其后的是以null 结尾的指针数组,其中每个指针都指向栈中的一个环境变量串。全局变量environ 指向这些指针中的第一个envp [0] 。紧随环境变量数组之后的是以null 结尾的argv[] 数组,其中每个元素都指向栈中一个参数串。
在栈的顶部是main 函数的3 个参数:
1) envp ,它指向envp[] 数组
2) argv ,它指向argv[]数组
3) argc ,它给出argv[]中非空指针的数量在Linux中专门有库函数6对系统调用execve函数进行包装。
2.4 其他函数
参考【深入理解计算机系统】第8章第8.4节 进程控制
- 其实现在的操作系统对地址映射的优化已经使得虚拟地址翻译的过程几乎不消耗什么时间。 ↩
- 不同的进程中的某些数据拥有相同的地址值是很正常的事情,因为进程的虚拟地址空间都是一样的,我们不用担心内存冲突,因为,虽然这些进程的某些数据拥有相同的地址值,但是它们在实现的时候(物理内存)由操作系统来安排物理内存,这些相同的虚拟地址值要么被操作系统映射到不同的物理内存地址上;要么被映射到相同的物理内存地址上,同时在进程各自的页表项中添加了对这个共享物理内存的访问权限的控制。 ↩
- 每一个进程都有一个唯一的正数 “进程ID”(PID)。 ↩
- 这里用到的是写时拷贝技术,在刚刚创建了子进程之后,子进程的页表等数据完全是拷贝自父进程,所以子进程和父进程共享物理内存中的内容,但是,当其中一个进程要改写物理内存中的内容时,它会把改写的共享数据拷贝到另外的物理内存区域中,并且更改与之对应的页表项,使其映射到更改之后的物理区域。 ↩
- 现在我们应该明白Linux下是如何执行新程序的了,每当有进程认为自己不能为系统和用户做出任何贡献了,他就可以发挥最后一点余热,调用任何一个exec,让自己以新的面貌重生;或者,更普遍的情况是,如果一个进程想执行另一个程序,它就可以fork出一个新进程,在fork调用返回之后,父、子进程并发执行下一条判断语句,通过判断进程号(PID)来确定父、子进程,然后子进程调用任何一个exec,父进程会跳过exec执行语句,接着往下执行,父进程的代码等内容没有改变。但是,子进程通过exec加载了其他程序,所以,在父、子进程并发的执行fork调用返回点后的判断进程号(PID)的语句之后,他们将并发的执行不同的代码指令。这样看起来就好像通过执行应用程序而产生了一个新的进程一样,而且这个新的进程可以是任何程序的一个进程。事实上第二种情况被应用得如此普遍,以至于Linux专门为其作了优化,我们已经知道,fork会将调用进程的所有内容原封不动的拷贝到新产生的子进程中去,这些拷贝的动作很消耗时间,而如果fork完之后我们马上就调用exec,这些辛辛苦苦拷贝来的东西又会被立刻抹掉,这看起来非常不划算,于是人们设计了一种”写时拷贝(copy-on-write)”技术,使得fork结束后并不立刻复制父进程的内容,而是到了真正使用的时候才复制被使用的部分,这样如果下一条语句是exec,它就不会白白作无用功了,也就提高了效率。 ↩
- exec族库函数 ↩
最后
以上就是危机书本最近收集整理的关于进程—初印象的全部内容,更多相关进程—初印象内容请搜索靠谱客的其他文章。








发表评论 取消回复