log4j 全称 log for java,项目始于1996年初,一个名为E.U. SEMPER(Secure Electronic Marketplace for Europe) 的项目,项目中需要一个api跟踪工具,于是最初的版本诞生了,随着后来对工具的不断增强,那个工具就演变成如今的Log4j。后来它以Apache Software License协议发布,最新的Log4j版本,包括全部的源码,class文件和文档,1.x可以在 http://logging.apache.org/log4j/上找到。如今,Log4j移植到C, C++, C#, Python, Ruby等语言。
log4j有很多有点,比如易用,易扩展,可以输出到任何地方,同时它是线程安全的,你不用担心很多细节,Log4j当然还有它的缺点,它会在一定程度上减慢程序,不当的使用甚至可以让你的程序挂掉。
梳理本文的目的就是让大家能明白每一行日志信息,是如何按正确的格式,写入到指定的文件或其它介质的,如何打印日志才正确,以及什么场景下需要特殊处理,更胜者需要扩展。
平时我们在输出日志信息时,其实很少考虑是否必须要打,如果打印了会造成什么影响,如何能快速打印日志,同时不影响主流程,一下让那个我们看看,log4j是如何实现的。
本文主要讲述的是Log4j 1.x版本,也会对竞争者logback 等 以及 log4j 2.x 做简要介绍和对比。
1. log4j 介绍
三个重要元素:
Logger:
前身是Category, 是日志记录的入口。
Appender:
真正负责落实日志记录的地方。
Layout:
负责格式化日志信息的地方。
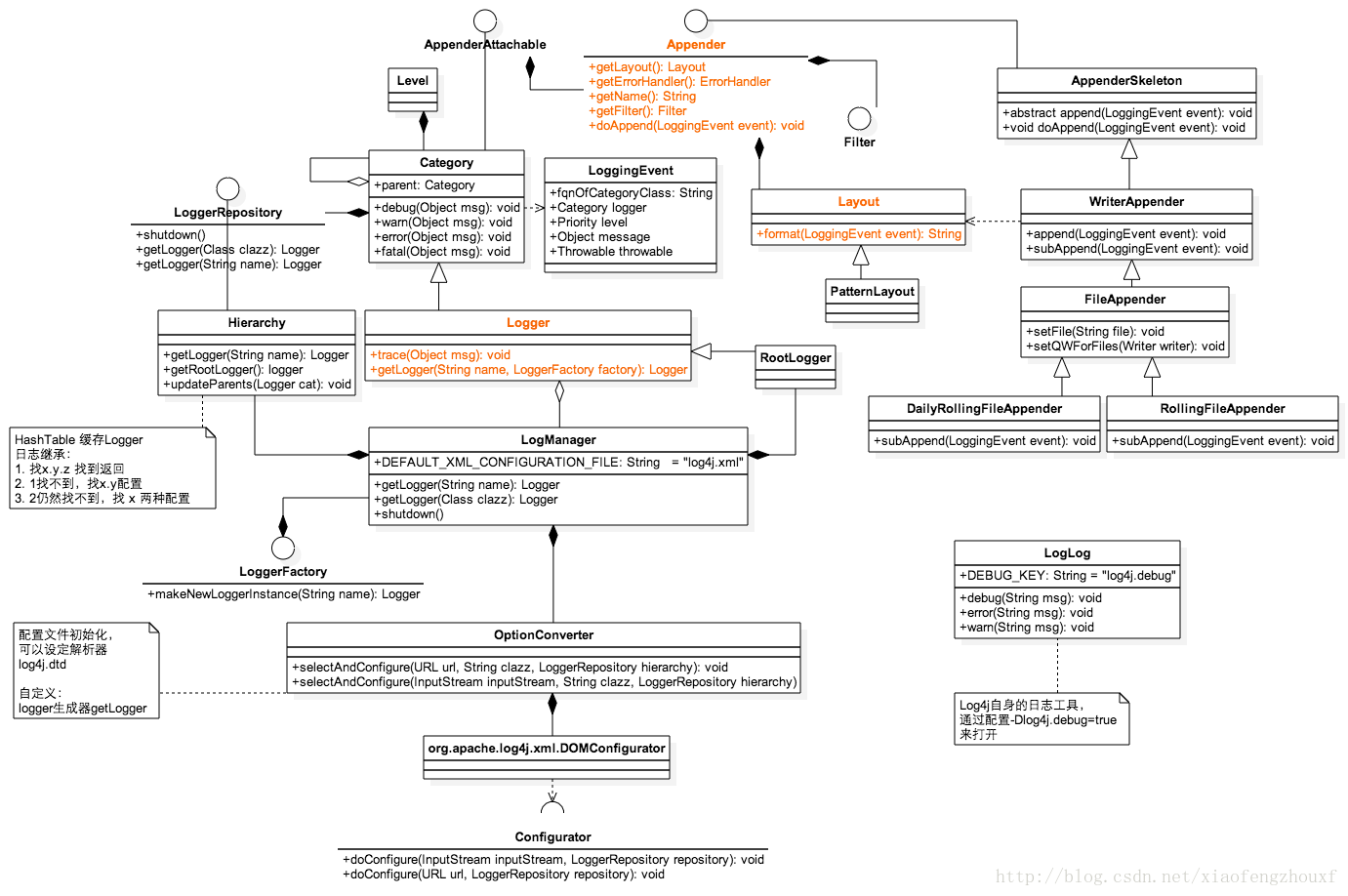
图1 Log4j 主要类图
如上图所示,关键的三个元素串起了日志记录的整个过程。
1.1 启动
通常程序中打印日志,并没有显示的初始化Log4j 配置文件,于是会在LogManager 类中的静态块里面,初始化,默认在classpath目录下找log4j.xml文件,找不到找log4j.properties文件,如果需要自定义路径和文件可以使用DOMConfigurator.configure 加载log4j.xml,使用PropertyConfigurator.configure 加载log4j.properties,目前1.2.x版本已经明确logj4.properties 将来只允许Logj4内部使用,所以尽量不要再使用,以免升级带来不必要的麻烦。
读取log4j.xml时候,使用Log4j.dtd作为文件校验,这里看下主要元素格式定义:
<!ELEMENT logger (param*,level?,appender-ref*)>
<!ATTLIST logger
class CDATA #IMPLIED
name CDATA #REQUIRED
additivity (true|false)"true"
>
从定义可以看出,logger 除了平时用到的level 外还有param, 该参数定义:
<!ELEMENT paramEMPTY>
<!ATTLIST param
name CDATA #REQUIRED
value CDATA#REQUIRED
>
通过设置param的name,value属性,可以把value设置到logger实现类的name属性中,class属性可以用作自定义logger类。,additivity 表示是否把信息打印到上一级(默认为继承类型的Logger管理方式),设置为true则打印到上一级,默认为true。appender-ref用来关联appender,可以配置多个appender-ref关联多个Appender。
<!ELEMENT appender (errorHandler?, param*,
rollingPolicy?, triggeringPolicy?, connectionSource?,
layout?, filter*, appender-ref*)>
<!ATTLIST appender
name CDATA#REQUIRED
class CDATA#REQUIRED
>
appender 有很多属性是比较特别的,这里只说filter 和 appender-ref。 filter 可以在每次打印日志时候,过滤日志事件是否打印,filter可自定义。 appender-ref 同样是用来关联现有的appender, 只有实现了AppenderAttachable 的 Appender 才行,例如AsyncAppender。
启动过程就是解析上面的配置,生成一个LoggerRepository, LoggerRepository 包含了一个映射表,表键为log 名称,表值为Appender ,而Appender 关联一种Layout。
默认的LoggerRepository 是 Hierarchy , 可以通过LogManager.setRepositorySelector 自定义,不过Log4j没有提供启动参数或者配置方式的自定义,有点不太合理,调用该方法后还得重新解析一遍配置才行。
Hierarchy使用HashTable 来维系log名称到Logger的过程,Logger 对象是在解析配置文件时候就可以创建好。而且每次创建Logger对象时,都会构建其继承关系,即如果当前的log名称为x.y.z 则他会在已经初始化好的Logger对象中找x.y 和 x 作为其父亲。 于是启动配置完成后,Hierarchy 管理的LoggerRepository 会包含所有Logger的父子树,最上一层就是root, 具体实现参考Hierarchy.updateParents。
当然使用HashTable 也有个问题,所有方法都是同步的,且Hierarchy getLogger()实现还定义了同步块来防止生产者消费者问题,所以每次获取会比较慢,而Logger 对象在整个log4j初始化完成后,就基本属于静态类(除非增加configureAndWatch 实现修改检测),所以一般使用方式都是定义类变量,且为static和finally的, 这会让日志打印快一些。
1.2 日志打印
Log.error(Object msg,Throwable throwable) 方法打印日志时,会在Logger对象中创建一个LoggingEvent类,其包含几个只要参数:
String fqnOfCategoryClass: logger 全路径名
Priority level : 日志级别
Object message: 日志信息
Throwable throwable: 异常信息和线程栈
有了这些信息后,LoggingEvent会被传递给所有与log名称关联的Logger,实现如下:
public
void callAppenders(LoggingEvent event) {
int writes = 0;
for(Category c = this; c != null; c=c.parent) {
// Protected against simultaneous call to addAppender, removeAppender,...
synchronized(c) {
if(c.aai != null) {
writes += c.aai.appendLoopOnAppenders(event);
}
if(!c.additive) {
break;
}
}
}
}
appendLoopOnAppenders 方法是真正打印的地方,如果所有Logger的additive都设置为true, 则日志会在整个Logger树中打印一遍,这个是很没有必要的,所以配置日志时候需要非常注意,尽量在x.y.z 和 root 中间,不要配置多余的x.y, x这样的日志,尽量设置additive为false。
appendLoopOnAppenders 方法会调用Logger配置中 appender-ref 关联的0个或者多个Appender, 如为0个则不打印,多个则便利所有Appender,调用其doAppend方法,打印LoggingEvent。 doAppend 方法就会遍历Filter类,判断当前的LoggingEvent是否需要过滤掉不处理,然后调用Appender 配置中 class 对应的真正Appender实现的appender方法。这里有一个扩展点 Filter , Filter 不能修改LoggingEvent 中的内容,因为LoggingEvent没有提供这样的能力,所以它只能根据LoggingEvent的内容,比如日志信息,级别等,判断这个日志是否需要打印, 这个功能其实有点弱啊,上面已经提过Filter可以在配置文件中定义0个或者多个,可以自定义。
常用的Appender 有如下几个, 都继承自 WriterAppender。
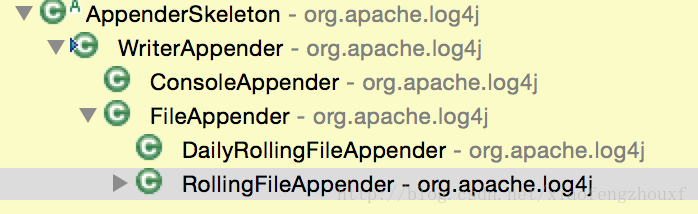
图2 常用 Appender
WriterAppender 类中主要方法为:
void subAppend(LoggingEvent event) {
this.qw.write(this.layout.format(event));
if(layout.ignoresThrowable()) {
String[] s = event.getThrowableStrRep();
if (s != null) {
int len = s.length;
for(int i = 0; i < len; i++) {
this.qw.write(s[i]);
this.qw.write(Layout.LINE_SEP);
}
}
}
if(shouldFlush(event)) {
this.qw.flush();
}
}
qw变量为java.io.Writer 的包装类,负责把日志信息以流的形式写出。
ConsoleAppender 默认输出到SYSTEM_OUT,把流重定向到System.out。
DailyRollingFileAppender 和 RollingFileAppender 则继承 FileAppender , 把流重定向到FileOutputStream。 RollingFileAppender 写的时候,会判断累加字符串的长度,超过配置maxFileSize大小则创建一个新的文件,DailyRollingFileAppender 则判断写日志的时间是否为新的一天,是则创建新文件。
另外还有很多可以用的Appender :
图3 Appender 列表
其中要说的是AsyncAppender, 可以把同步的日志转成异步写配置如。
<appender name="ASYNC_APP" class="org.apache.log4j.AsyncAppender">
<param name="bufferSize" value="512"/>
<param name="blocking" value="false"/>
<appender-ref ref="APP"/>
</appender>
通过1个或者多个 appender-ref 标签来代理同步的Appender, bufferSize 代表的是缓存多少个日志事件(error等方法调用一次就是一个事件),默认值为128。
同步方法会因为等待日志同步写到目标源而阻塞正常流程,但异步后也只是启动一个线程在不停的一个一个的把事件写出去,所以IO并没有减少,同时程序当缓冲区满之后,还需要判断blocking参数, 当blocking为false时,日志就会被缓存到另一个集合中,而且没有限制内存大小或者事件数量,于是会有OOM风险,如果blocking为true, 则缓冲区满时log的所有方法都会阻塞,等待异步写线程清空缓冲区才能唤醒,同时当前的事件就会丢失(看去像是Bug),具体程序见AsyncAppender.append 方法。所以异步写日志还是有很大的风险,得视涉及的系统而定。
Appender 本身也是log4j的一个扩展点,大家可以实现自己的Appender, 配置到Logj4.xml中,例如需要增加与特定监控系统结合的Appender是一个比较常用的场景。
2. Log4j 调试
Log4j 本身有自己的日志工具,类名为LogLog, Log4j内部代码都是通过它来打印信息的,默认是调试功能是关闭的,有两种方式打开:
a. 配置jvm启动参数 -Dlog4j.debug
b. 使用配置文件log4j:configuration元素的threshold 属性,设置为debug , 该元素
的日志级别就是LogLog工具的日志级别,可以
all|trace|debug|info|warn|error|fatal|off|null,默认是null.
LogLog的输出,debug下输出到System.out, errorwarn下输出到System.err,配置后打印信息如下:
log4j: Trying to find [log4j.xml] using context classloader sun.misc.Launcher$AppClassLoader@75a06ec2.
log4j: Using URL [file:/xxx/target/test-classes/log4j.xml] for automatic log4j configuration.
log4j: Preferred configurator class: org.apache.log4j.xml.DOMConfigurator
log4j: System property is :null
log4j: Standard DocumentBuilderFactory search succeded.
log4j: DocumentBuilderFactory is: com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImpl
log4j: debug attribute= "null".
log4j: Ignoring debug attribute.
log4j: Threshold ="null".
log4j: Retreiving an instance of org.apache.log4j.Logger.
log4j: Setting [com.test.xxx] additivity to [false].
log4j: Level value for com.cmcc.mriya is [debug].
log4j: com.cmcc.mriya level set to DEBUG
log4j: Class name: [org.apache.log4j.ConsoleAppender]
log4j: Parsing layout of class: "org.apache.log4j.PatternLayout"
log4j: Setting property [conversionPattern] to [%d - %c -%-4r [%t] %-5p %x - %m%n].
log4j: Adding appender named [CONSOLE] to category [com.test.xxx].
log4j: Level value for root is [debug].
log4j: root level set to DEBUG
log4j: Adding appender named [CONSOLE] to category [root].
从调试信息中可以看到,当前读取到的日志配置文件为/xxx/target/test-classes/log4j.xml, 还有现有配置的Logger 和 Appender 信息,对于调试log4j的日志输出有一定帮助。
3. 同类日志工具比较
3.1 slf4j
slf4j由log4j作者Ceki开发,用来替代commons-logging,它是一个日志的Facade,通过代理和适配具体的日志组件,完成log4j, logback, jdk logging等工具的统一管理,简便日志的使用。
使用时,需要用到slf4j-log4j12 和 slf4j-api 两个包与log4j 1.2.x 整合,当调用 slf4j-api中的LoggerFactory的getLogger方法 获取一个Logger 时,LoggerFactory 会通过反射加载StaticLoggerBinder 类,而该类在slf4j-log4j12 包中,StaticLoggerBinder会创建一个 Log4jLoggerFactory, 然后后面的Logger 创建,都会通过 Log4jLoggerFactory完成,通过Log4jLoggerAdapter适配器把Log4j的Logger适配到slf4j的Logger类, 于是就完成了slf4j与Log4j的整合。
使用的好处日后可以方便从log4j 迁移到logback等其它日志组件;支持参数化的logger.error(“xxx,{}”, id), 多个参数也支持,所以一定程度上是简化了日志打点;使用ConcurrentMap<String, Logger>方式缓存了Logger, 加快Logger的获取。
3.2 Logback
Logback由log4j作者Ceki开发, 用来取代log4j 1.2.x版本,同时它也实现了slf4j的功能。
Logback 分为三个模块:Core、Classic 和 Access。Core模块是其他两个模块的基础。 Classic模块扩展了core模块。 Classic模块相当于log4j的显著改进版。Logback-classic 直接实现了 SLF4J API。
要引入logback,由于Logback-classic依赖slf4j-api.jar和logback-core.jar,所以要把slf4j-api.jar、logback-core.jar、logback-classic.jar,添加到要引入Logbac日志管理的项目的class path中。
下面是官网从log4j迁到到logback的原因的翻译版本:
更快的实现
Logback的内核重写了,在一些关键执行路径上性能提升10倍以上。而且logback不仅性能提升了,初始化内存加载也更小了。
非常充分的测试
Logback经过了几年,数不清小时的测试。Logback的测试完全不同级别的。在作者的观点,这是简单重要的原因选择logback而不是log4j。
Logback-classic非常自然实现了SLF4j
Logback-classic实现了SLF4j。在使用SLF4j中,你都感觉不到logback-classic。而且因为logback-classic非常自然地实现了SLF4J,所以切换到log4j或者其他,非常容易,只需要提供成另一个jar包就OK,根本不需要去动那些通过SLF4JAPI实现的代码。
非常充分的文档
官方网站有两百多页的文档。
自动重新加载配置文件
当配置文件修改了,Logback-classic能自动重新加载配置文件。扫描过程快且安全,它并不需要另外创建一个扫描线程。这个技术充分保证了应用程序能跑得很欢在JEE环境里面。
Lilith
Lilith是log事件的观察者,和log4j的chainsaw类似。而lilith还能处理大数量的log数据
谨慎的模式和非常友好的恢复
在谨慎模式下,多个FileAppender实例跑在多个JVM下,能够安全地写道同一个日志文件。RollingFileAppender会有些限制。Logback的FileAppender和它的子类包括RollingFileAppender能够非常友好地从I/O异常中恢复。
配置文件可以处理不同的情况
开发人员经常需要判断不同的Logback配置文件在不同的环境下(开发,测试,生产)。而这些配置文件仅仅只有一些很小的不同,可以通过,和来实现,这样一个配置文件就可以适应多个环境。
Filters(过滤器)
有些时候,需要诊断一个问题,需要打出日志。在log4j,只有降低日志级别,不过这样会打出大量的日志,会影响应用性能。在Logback,你可以继续保持那个日志级别而除掉某种特殊情况,如alice这个用户登录,她的日志将打在DEBUG级别而其他用户可以继续打在WARN级别。要实现这个功能只需加4行XML配置。可以参考MDCFIlter
SiftingAppender(一个非常多功能的Appender)
它可以用来分割日志文件根据任何一个给定的运行参数。如,SiftingAppender能够区别日志事件跟进用户的Session,然后每个用户会有一个日志文件。
自动压缩已经打出来的log
RollingFileAppender在产生新文件的时候,会自动压缩已经打出来的日志文件。压缩是个异步过程,所以甚至对于大的日志文件,在压缩过程中应用不会受任何影响。
堆栈树带有包版本
Logback在打出堆栈树日志时,会带上包的数据。
自动去除旧的日志文件
通过设置TimeBasedRollingPolicy或者SizeAndTimeBasedFNATP的maxHistory属性,你可以控制已经产生日志文件的最大数量。如果设置maxHistory为12,那那些log文件超过12个月的都会被自动移除。
详细见参考一栏链接,Logback 是log4j 进化版,从锁的粒度,到Logger的存储结构,都做了优化,从而性能更好,简单测试来看,性能有10%以上的提升。
Logback 目前是一个中间产物,虽然在log4j 1.x 上做了一些优化,但并没有实质性的修改,目前已经有Log4j 2.x 推出,所以logback这边就不详述了。
3.4 log4j 2.x 介绍
Log4j 2.X 作者同样是Ceki, 他在logback 和 log4j 1.x 的基础上,进一步优化。
从log4j 1.x 到 2.x 并不是平滑的,迁移方法见 http://logging.apache.org/log4j/2.x/manual/migration.html, 不知为什么,配置文件怎么看还是1.x的版本比较顺眼。
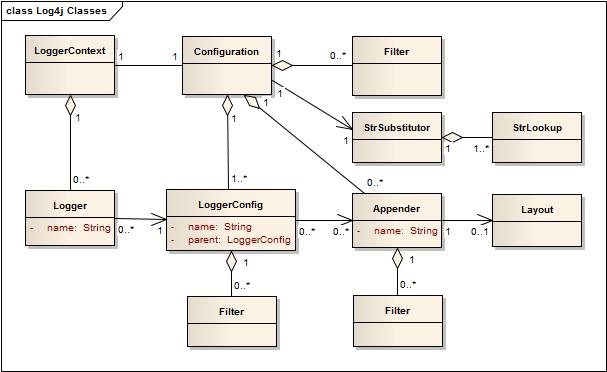
图5 Log4j 2 类图(源自官网)
logj4 2中同样存在logger的继承关系,与Log4j 1.x 的 Hierarchy 功能对应的是 LoggerConfig。 在启动解析配置文件时,通过AbstractConfiguration的addLoggerAppenderLogger方法构建LoggerConfig 继承关系; 初始化Logger对象时,通过 AbstractConfiguration的getLoggerConfig 方法,由log的名称及其子名称( x.y 为 x.y.z 的子名称 )的log 关联到对应 LoggerConfig 实例,而LoggerConfig 管理着 Appender 集合,从而进行日志输出。
继承关系由原来的复杂的,ProvisionNode 等Child,Parent 结构,修改为简单map映射表, Logger获取从原来的Hashtable存储并且加synchronized 锁整个Hashtable 改成使用ConcurrentHashMap 直接静态获取, 所以log4j2 获取Logger 不用再在每个类定义static 变量了, 使用时获取也问题不大。
log4j 1.x 的异步打印上面做了分析,有很大问题,而log4j 2中使用了Disruptor 无锁方式,其关键是一个RingBuffer 结构,据称整体性能能提升10倍。
另外log4j 2还做了一些Bug修复,和插件的扩展。
4. 总结
目前大多还在使用Log4j 1.2.x版本,使用时候需要注意Logger 对象得到需要设置为static, 避免多次重复获取, 配置日志时候减少层级, 尽量配置additive 为false ,而不重复打印。
Log4j 2 已经包含了所有logback的特性,而且还进一步优化了性能,所以建议升级直接使用Log4j 2。
5. 参考:
http://logback.qos.ch/reasonsToSwitch.html
http://logging.apache.org/log4j/1.2/
http://logging.apache.org/log4j/2.x/
http://lmax-exchange.github.com/disruptor
最后
以上就是阳光玉米最近收集整理的关于log4j 1.x 2.x 源码阅读笔记的全部内容,更多相关log4j内容请搜索靠谱客的其他文章。








发表评论 取消回复