淘宝卖家必备程序
前一阵闲的冒泡开了个淘宝店,因为改价格等各种原因麻烦的不得了,这不就心思爬个虫懒得一页页翻了么!
如果你没开过淘宝店或者非得自己亲眼看网页价格,那么这篇咱们就没啥缘分了,我们以后随缘再见~
话不多说直接教程(以下教程没开店的人员可能看不懂):
- 首先先进入我们的淘管家。登陆自己的账号,进入我们的店铺页面。我们会看到如下界面
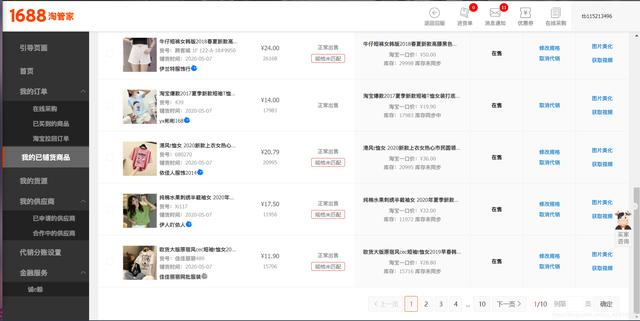
- 首先介绍一下这是我的店铺,我们能发现这里存在买价和卖价,并且还需要翻页才能查看到你所有的店铺信息。在这里我首先想拿到的就是衣服名字、买价、卖价以及这部分的差价。均提取出来保存到 csv 文件中。
- 我们首先打开检查模式(右键检查或者键盘中F12敲一敲)。在这里我们直接进入 Network 网络传输这里。如果这里为空不用担心,因为刷新一下传输太多了咱们看不过来,我们直接点击下一页点到第一个传输位置,我们会发现 Preview 里面有我们的json信息,pageList 能看到卖货信息全在这里。那就容易了,记住这个 url 请求地址就好。
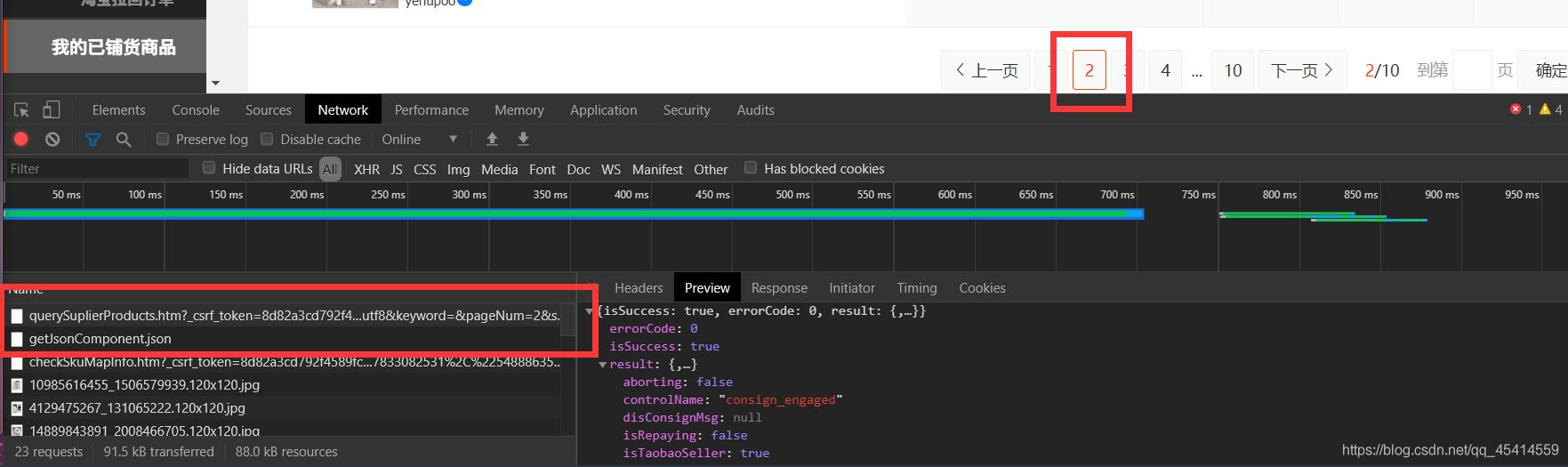
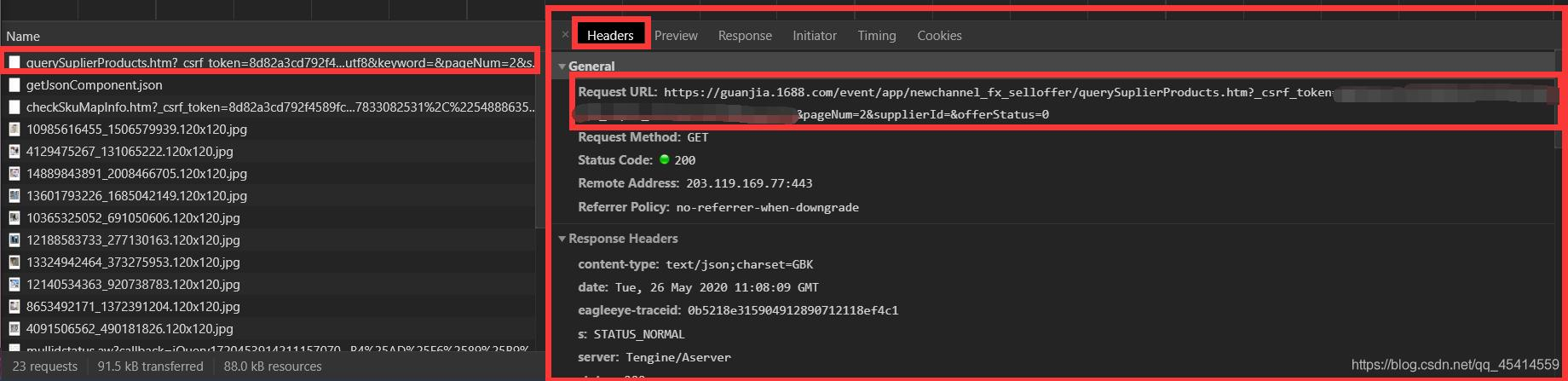
url 地址怎么获取:还是刚才那个第一个别变,我们直接找Headers信息找到第一项 Request URL 就是我们需要的那个网站信息,这个网址非常乱。如果你不想了解爬虫的话看不懂无所谓。其实这个就是你淘宝账号的key信息,属于你自己一个人的网址链接。我们只需要看到 pageNum=2 参数,就大概能猜到这个是你当前的页数了。(PS:一开始我以为我还得自己去寻找一共多少页信息,结果我发现这个Json里面全都包括了?淘宝牛皮!)
- 之后就该手撸代码啦。。巴拉巴拉写完啦(没有过程。解析再源代码,想看的话往后翻翻就能看到啦)。在这里是不是有人想知道淘宝需要登陆而且很严格的吧。没关系!
传说有一个大佬他叫皮卡丘,曾经开源了第三方库名为 DecryptLogin ,这个库能帮我们做到很多很多登陆的问题,有大佬不用愁!再次感谢大佬开源
- 之后将自己的代码做成可执行文件分享出来给小伙伴们用

源代码(修改 search_url 的网址为自己的店铺):
源代码(修改 search_url 的网址为自己的店铺):
import os,pickle,csv,sys
from tkinter import messagebox
from lxml import etree
from DecryptLogin import login
class TBCrawler():
def __init__(self, **kwargs):
self.clothes = {}
if os.path.isfile('session.pkl'):
self.session = pickle.load(open('session.pkl', 'rb'))
else:
self.session = TBCrawler.login()
f = open('session.pkl', 'wb')
pickle.dump(self.session, f)
f.close()
self.run("1")
self.save()
def run(self,page):
# 把这里改成自己的信息,如果xxx之外的地方出现较大问题,则可能就是获取错了
# 改xxxxx位置就好了,其他不要动。
search_url = "https://guanjia.1688.com/event/app/newchannel_fx_selloffer/querySuplierProducts.htm?_csrf_token=Xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxd&_input_charset=utf8&keyword=&pageNum={}&supplierId=&offerStatus=0".format(page)
response = self.session.get(search_url)
# 因为读取pkl登陆信息cookie容易过期,则需要判断一些这里应不应该结束程序
try:result = response.json()["result"]
except:
messagebox.showinfo("warning","登陆过期,请删除pkl信息重新运行")
sys.exit(0)
pageList = result["pageList"]
for dicts in pageList:
name,bug,sell = dicts["itemTitle"],dicts["maxPurchasePrice"],dicts["maxTbSellPrice"]
interest = float(sell) - float(bug)
self.clothes[name] = [bug,sell,interest]
# 在这里输出一下信息, 别因为页数多爬取好久一点信息没有都不知道爬到哪了。
print(self.clothes)
all_page = int(result["pageCount"])
if int(page) < all_page:
self.run(int(page)+1)
def save(self):
with open("clothes.csv", 'w', newline='', encoding='utf_8_sig') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["衣服名","买价","卖价","利益"])
for key in self.clothes.keys():
value = self.clothes[key]
csv_writer.writerow([key,value[0],value[1],value[2]])
@staticmethod
def login():
lg = login.Login()
_, session = lg.taobao()
return session
if __name__ == '__main__':
crawler = TBCrawler()import os,pickle,csv,sys
from tkinter import messagebox
from lxml import etree
from DecryptLogin import login
class TBCrawler():
def __init__(self, **kwargs):
self.clothes = {}
if os.path.isfile('session.pkl'):
self.session = pickle.load(open('session.pkl', 'rb'))
else:
self.session = TBCrawler.login()
f = open('session.pkl', 'wb')
pickle.dump(self.session, f)
f.close()
self.run("1")
self.save()
def run(self,page):
# 把这里改成自己的信息,如果xxx之外的地方出现较大问题,则可能就是获取错了
# 改xxxxx位置就好了,其他不要动。
search_url = "https://guanjia.1688.com/event/app/newchannel_fx_selloffer/querySuplierProducts.htm?_csrf_token=Xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxd&_input_charset=utf8&keyword=&pageNum={}&supplierId=&offerStatus=0".format(page)
response = self.session.get(search_url)
# 因为读取pkl登陆信息cookie容易过期,则需要判断一些这里应不应该结束程序
try:result = response.json()["result"]
except:
messagebox.showinfo("warning","登陆过期,请删除pkl信息重新运行")
sys.exit(0)
pageList = result["pageList"]
for dicts in pageList:
name,bug,sell = dicts["itemTitle"],dicts["maxPurchasePrice"],dicts["maxTbSellPrice"]
interest = float(sell) - float(bug)
self.clothes[name] = [bug,sell,interest]
# 在这里输出一下信息, 别因为页数多爬取好久一点信息没有都不知道爬到哪了。
print(self.clothes)
all_page = int(result["pageCount"])
if int(page) < all_page:
self.run(int(page)+1)
def save(self):
with open("clothes.csv", 'w', newline='', encoding='utf_8_sig') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["衣服名","买价","卖价","利益"])
for key in self.clothes.keys():
value = self.clothes[key]
csv_writer.writerow([key,value[0],value[1],value[2]])
@staticmethod
def login():
lg = login.Login()
_, session = lg.taobao()
return session
if __name__ == '__main__':
crawler = TBCrawler()
原作者:꧁༺北海以北的等待༻꧂
如有侵权联系删除,开源代码或者完整项目代码回去加群:1136192749
谢谢大家阅读!
淘宝卖家必备程序
前一阵闲的冒泡开了个淘宝店,因为改价格等各种原因麻烦的不得了,这不就心思爬个虫懒得一页页翻了么!
如果你没开过淘宝店或者非得自己亲眼看网页价格,那么这篇咱们就没啥缘分了,我们以后随缘再见~
话不多说直接教程(以下教程没开店的人员可能看不懂):
- 首先先进入我们的淘管家。登陆自己的账号,进入我们的店铺页面。我们会看到如下界面
- 首先介绍一下这是我的店铺,我们能发现这里存在买价和卖价,并且还需要翻页才能查看到你所有的店铺信息。在这里我首先想拿到的就是衣服名字、买价、卖价以及这部分的差价。均提取出来保存到 csv 文件中。
- 我们首先打开检查模式(右键检查或者键盘中F12敲一敲)。在这里我们直接进入 Network 网络传输这里。如果这里为空不用担心,因为刷新一下传输太多了咱们看不过来,我们直接点击下一页点到第一个传输位置,我们会发现 Preview 里面有我们的json信息,pageList 能看到卖货信息全在这里。那就容易了,记住这个 url 请求地址就好。
url 地址怎么获取:还是刚才那个第一个别变,我们直接找Headers信息找到第一项 Request URL 就是我们需要的那个网站信息,这个网址非常乱。如果你不想了解爬虫的话看不懂无所谓。其实这个就是你淘宝账号的key信息,属于你自己一个人的网址链接。我们只需要看到 pageNum=2 参数,就大概能猜到这个是你当前的页数了。(PS:一开始我以为我还得自己去寻找一共多少页信息,结果我发现这个Json里面全都包括了?淘宝牛皮!)
- 之后就该手撸代码啦。。巴拉巴拉写完啦(没有过程。解析再源代码,想看的话往后翻翻就能看到啦)。在这里是不是有人想知道淘宝需要登陆而且很严格的吧。没关系!
传说有一个大佬他叫皮卡丘,曾经开源了第三方库名为 DecryptLogin ,这个库能帮我们做到很多很多登陆的问题,有大佬不用愁!再次感谢大佬开源
- 之后将自己的代码做成可执行文件分享出来给小伙伴们用
源代码(修改 search_url 的网址为自己的店铺):
源代码(修改 search_url 的网址为自己的店铺):
import os,pickle,csv,sys
from tkinter import messagebox
from lxml import etree
from DecryptLogin import login
class TBCrawler():
def __init__(self, **kwargs):
self.clothes = {}
if os.path.isfile('session.pkl'):
self.session = pickle.load(open('session.pkl', 'rb'))
else:
self.session = TBCrawler.login()
f = open('session.pkl', 'wb')
pickle.dump(self.session, f)
f.close()
self.run("1")
self.save()
def run(self,page):
# 把这里改成自己的信息,如果xxx之外的地方出现较大问题,则可能就是获取错了
# 改xxxxx位置就好了,其他不要动。
search_url = "https://guanjia.1688.com/event/app/newchannel_fx_selloffer/querySuplierProducts.htm?_csrf_token=Xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxd&_input_charset=utf8&keyword=&pageNum={}&supplierId=&offerStatus=0".format(page)
response = self.session.get(search_url)
# 因为读取pkl登陆信息cookie容易过期,则需要判断一些这里应不应该结束程序
try:result = response.json()["result"]
except:
messagebox.showinfo("warning","登陆过期,请删除pkl信息重新运行")
sys.exit(0)
pageList = result["pageList"]
for dicts in pageList:
name,bug,sell = dicts["itemTitle"],dicts["maxPurchasePrice"],dicts["maxTbSellPrice"]
interest = float(sell) - float(bug)
self.clothes[name] = [bug,sell,interest]
# 在这里输出一下信息, 别因为页数多爬取好久一点信息没有都不知道爬到哪了。
print(self.clothes)
all_page = int(result["pageCount"])
if int(page) < all_page:
self.run(int(page)+1)
def save(self):
with open("clothes.csv", 'w', newline='', encoding='utf_8_sig') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["衣服名","买价","卖价","利益"])
for key in self.clothes.keys():
value = self.clothes[key]
csv_writer.writerow([key,value[0],value[1],value[2]])
@staticmethod
def login():
lg = login.Login()
_, session = lg.taobao()
return session
if __name__ == '__main__':
crawler = TBCrawler()import os,pickle,csv,sys
from tkinter import messagebox
from lxml import etree
from DecryptLogin import login
class TBCrawler():
def __init__(self, **kwargs):
self.clothes = {}
if os.path.isfile('session.pkl'):
self.session = pickle.load(open('session.pkl', 'rb'))
else:
self.session = TBCrawler.login()
f = open('session.pkl', 'wb')
pickle.dump(self.session, f)
f.close()
self.run("1")
self.save()
def run(self,page):
# 把这里改成自己的信息,如果xxx之外的地方出现较大问题,则可能就是获取错了
# 改xxxxx位置就好了,其他不要动。
search_url = "https://guanjia.1688.com/event/app/newchannel_fx_selloffer/querySuplierProducts.htm?_csrf_token=Xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxd&_input_charset=utf8&keyword=&pageNum={}&supplierId=&offerStatus=0".format(page)
response = self.session.get(search_url)
# 因为读取pkl登陆信息cookie容易过期,则需要判断一些这里应不应该结束程序
try:result = response.json()["result"]
except:
messagebox.showinfo("warning","登陆过期,请删除pkl信息重新运行")
sys.exit(0)
pageList = result["pageList"]
for dicts in pageList:
name,bug,sell = dicts["itemTitle"],dicts["maxPurchasePrice"],dicts["maxTbSellPrice"]
interest = float(sell) - float(bug)
self.clothes[name] = [bug,sell,interest]
# 在这里输出一下信息, 别因为页数多爬取好久一点信息没有都不知道爬到哪了。
print(self.clothes)
all_page = int(result["pageCount"])
if int(page) < all_page:
self.run(int(page)+1)
def save(self):
with open("clothes.csv", 'w', newline='', encoding='utf_8_sig') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["衣服名","买价","卖价","利益"])
for key in self.clothes.keys():
value = self.clothes[key]
csv_writer.writerow([key,value[0],value[1],value[2]])
@staticmethod
def login():
lg = login.Login()
_, session = lg.taobao()
return session
if __name__ == '__main__':
crawler = TBCrawler()
原作者:꧁༺北海以北的等待༻꧂
如有侵权联系删除,开源代码或者完整项目代码回去加群:1136192749
谢谢大家阅读!
最后
以上就是羞涩钢笔最近收集整理的关于Python实现淘宝卖家价格分析,淘宝卖家必会的操作!淘宝卖家必备程序淘宝卖家必备程序的全部内容,更多相关Python实现淘宝卖家价格分析,淘宝卖家必会内容请搜索靠谱客的其他文章。








发表评论 取消回复