原文链接
本文发表于自然语言处理顶级会议 ACL 2018
项目源码链接
摘要
在情感分类任务中,人们关注的往往是一句话中所表露出情感的“最重要”的一部分,比如在美团上经常会有这种评价:“这家店的菜做的不错,但是服务特别差!”,而对于餐厅管理者来说,这条评论他们最关注的是“这家店服务特别差”这个部分,即整个句子对他们餐厅所表现出来的情感是“不满意”的,“这家店菜做的不错”就成了做情感分类任务中的“噪声”,会影响到算法判断出句子真正想要表现的情感,而以往的采用双向LSTM加上attention的做法不能很好的区分这种“噪声”,于是本文提出了一种新型的解决方案,来解决这个问题。
数据假定
假设咱们有一个句子 W={w1,w2,...,wn} W = { w 1 , w 2 , . . . , w n } ,其中 wn w n 为句子中的第 n n 个词语,我们假设我们想要关注的是句子的某一个部分(比如上文介绍的“这家店服务特别差”),那么我们就设这个部分为一个( target t a r g e t 是句子的一个子序列),可以表示为 WT={wT1,wT2,...,wTm} W T = { w 1 T , w 2 T , . . . , w m T } ,其中 wTm w m T 为 target t a r g e t 的第 m m 个词语,的embedding可以表示为 XT={xT1,xT2,...,xTm} X T = { x 1 T , x 2 T , . . . , x m T } ,整个句子的embedding可以表示为 X={x1,x2,...,xm} X = { x 1 , x 2 , . . . , x m } (注:embedding可以通俗的理解为将句子转换成了可以用数学表示的向量,方便送入神经网络进行计算)
情感分类任务建模
情感分类任务具体而言就是给定一个输入句子,判断它所包含的情感是“积极的”,还是“消极的”,还是“中立的”,本质上其实就是一个三分类任务,于是我们可以针对每一个句子标记一个label,即 y∈{P,N,O} y ∈ { P , N , O } ,(P代表positive,N代表negative,O代表neutral)
模型介绍
本文提出一种称为Tnet的模型,如下图所示:
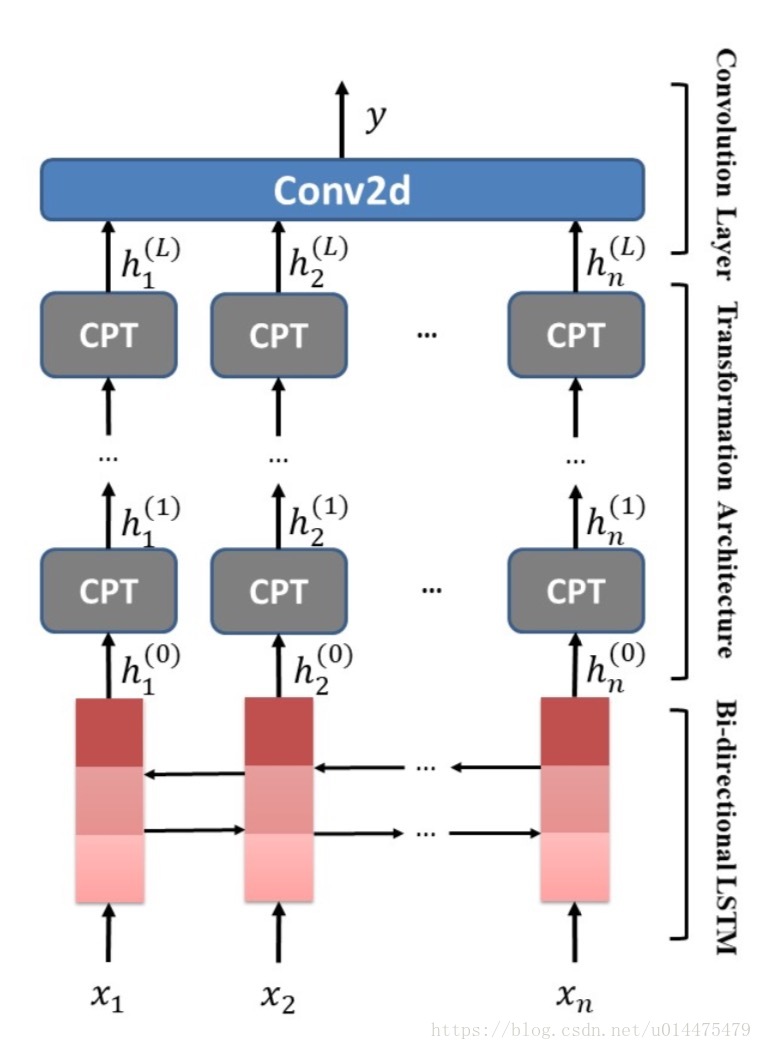
图中最底层(红色部分)是一个双向LSTM,得到输入的词序列
X={x1,x2,...,xm}
X
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
对应的隐含状态输出
h(0)={h(0)1,h(0)2,...,h(0)m}
h
(
0
)
=
{
h
1
(
0
)
,
h
2
(
0
)
,
.
.
.
,
h
m
(
0
)
}
,
中间层包含
L
L
个CPT层,这个CPT结构就是本文的重中之重了。
CPT结构如图所示:
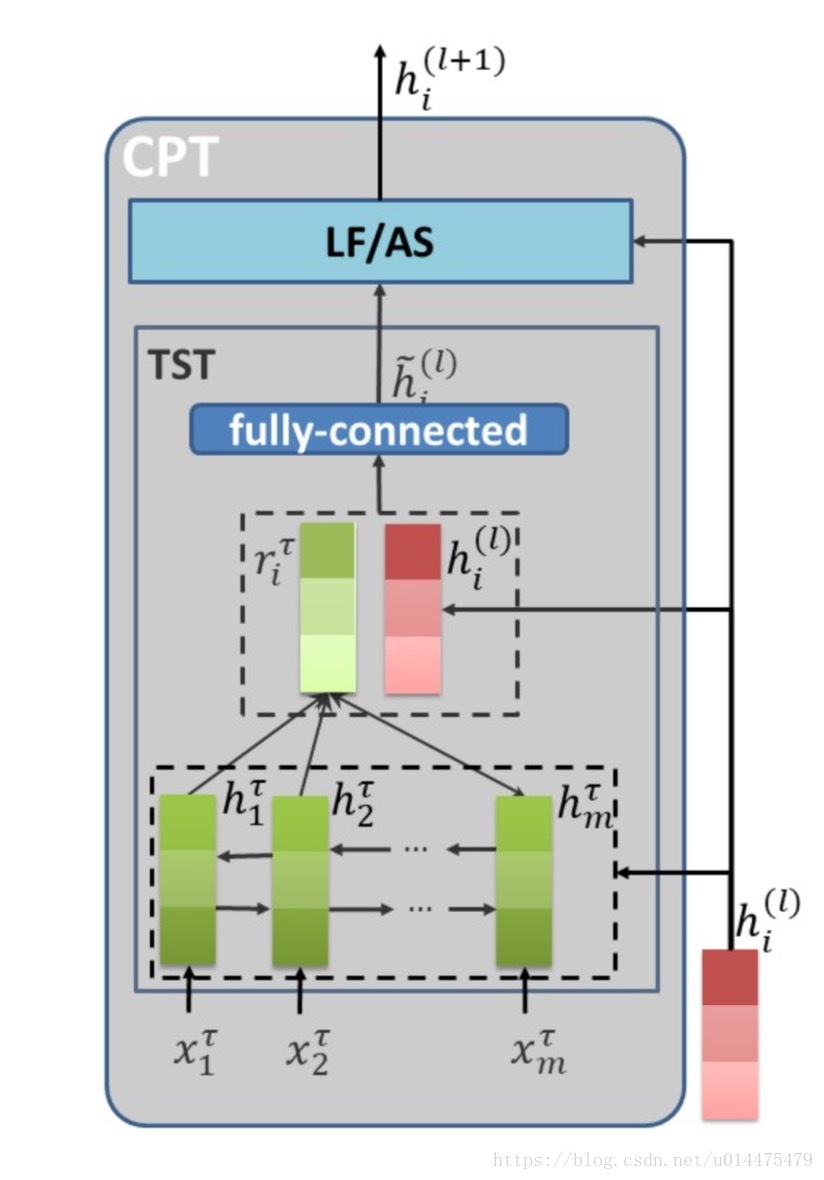
如图所示,它包含TST和LF/AS两个子结构:
我们先说TST
其最底层是一个双向LSTM,输入是,即
target
t
a
r
g
e
t
的embedding,输出是其对应的隐含层状态。本文认为
target
t
a
r
g
e
t
对不同的上下文的关注度不同(句子中有些成分对
target
t
a
r
g
e
t
密切相关,有些成分与
target
t
a
r
g
e
t
基本无关),即我们的每一个
htm
h
m
t
(
target
t
a
r
g
e
t
的隐含层状态输出)对每一个
h(l)i
h
i
(
l
)
(整个句子的隐含层状态输出)的关注度应该不同,那么我们就有:
其中 F(h(l)i,hTj) F ( h i ( l ) , h j T ) 就是 target t a r g e t 的第 j j 个词的隐含层状态对整个句子的第个词的隐含层状态的关注度(注:其中 (l) ( l ) 代表在第 (l) ( l ) 个CPT层),其计算公式如下:
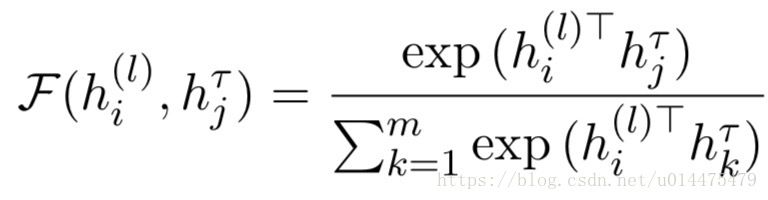
(注:上式本质上就是一个attention,虽然本文宣称没有做attention)
最后我们得到了 rTi r i T ,我们将其和 h(l)i h i ( l ) 给concat起来过一个全连接层得到输出送入第二个子结构LF/AS中,公式如下:
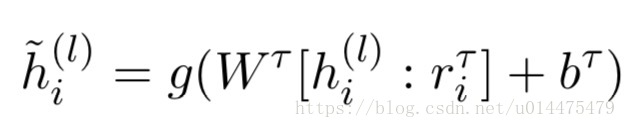
其中 g() g ( ) 为一个非线性激活函数, WT W T 为权重矩阵, bT b T 为biase
在来看LF/AS
由于在TST中我们的
target
t
a
r
g
e
t
又过了一遍双向LSTM,其输出肯定和整个句子过的双向LSTM的输出的分布不大相同,如果直接进行concat的话会导致从整个句子中学到的信息被大量的丢失,于是作者采用了两个独门秘笈来解决这个问题:
Lossless Forwarding
具体而言,就是将第 (l) ( l ) 个CPT层的输入 h(l)i h i ( l ) 在该CPT层输出时再加回来,这样的话就不会损失掉其原有的信息了,公式如下:
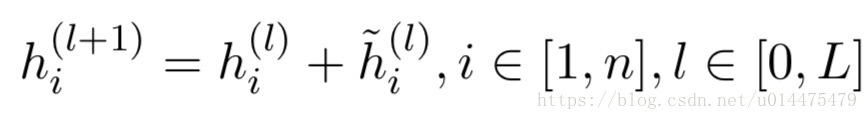
这样一层层传递下去,我们的每一层都会包含之前所有层的信息,如下图公式所示:
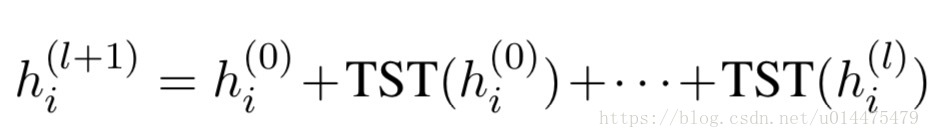
Adaptive Scaling
具体而言,就是借鉴LSTM的思想,训练一个门结构,用来判断有哪些信息会传递到下一层,哪些可以丢弃。如下所示:

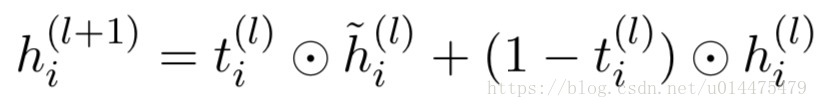
其中 t(l)i t i ( l ) 就是训练出来的门结构
得到了最后一层CPT的输出之后,我们将其送入一个卷积核大小为1的卷积层,然后再用max pool的方法提取特征,最后再接一个softmax层就得到了我们最终的输出了。
最后
以上就是彩色小鸭子最近收集整理的关于用神经网络做情感分类《Transformation Networks for Target-Oriented Sentiment Classification》的全部内容,更多相关用神经网络做情感分类《Transformation内容请搜索靠谱客的其他文章。








发表评论 取消回复