项目背景:
本文通过抓取京东某笔记本的评论数据,简单从几个维度进行分析,并制作用户评论的词云图。
爬取数据:
商品链接
通过对商品评论页面进行探索,发现评论数据是通过发送请求,然后从数据库调取此商品的评论数据,返回的评论数据是Json格式。可以点击下一页,抓到发送请求的链接:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100012443350&score=0&sortType=5&page=1&pageSize=10&isShadowSku=0&rid=0&fold=1
通过对以上链接进行分析,几个参数代表的含义:
**productId:**商品的ID,本项目就抓一个商品,ID不用变更。
**score:**评论类型(好:3、中:2、差:1、所有:0)
**sortType:**排序类型(推荐:5、时间:6)
**page:**第几页,京东只能抓100页的数据,不能抓到全部评论数据,就拿这一部分数据来探索下吧。
**pageSize:**每页显示多少条记录(默认10)
虽然限制只能抓取100页评论数据,但抓取过程还是很快的,没有遇到封IP的现象。
如果需要在京东上抓大量的其它数据,一般还是需要找代理IP的,不然抓不到几页就会被限。
本项目数据量比较小,抓到的数据直接存到csv文件里,再进行后续的进一步分析。
#爬取数据
import numpy as np
import pandas as pd
import requests
import json
#构建爬虫函数,这个爬取过程还是比较简单的。
def get_comments():
#评论页是从数据库调用的,可以直接从下面这个链接,返回json格式评论数据
url0=u'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100012443350&score=0&sortType=5&page={0}&pageSize=10&isShadowSku=0&rid=0&fold=1'
#模拟浏览器访问
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'}
for i in range(100):
url=url0.format(i)
response=requests.get(url,headers=header)
#返回的json不是标准格式,把头/尾的字符去除
json_response=response.text.replace('fetchJSON_comment98(','').replace(');','')
#json转换为字典格式,读取评论数据
json_response=json.loads(json_response)['comments']
#提取出[用户id,用户名,购买时间,评价时间,商品Id,商品规格信息,用户评分,用户评论/追评]
columns=['id','nickname','referenceTime','creationTime','referenceId','productColor','productSize','score','content']
end_columns=['userId','userName','buyTime','commentTime','productId','productColor','productSize','score','comment','afterComment']
#如下循环分别提取数据
for j in range(10):
userid=json_response[j][columns[0]]
username=json_response[j][columns[1]]
buytime=json_response[j][columns[2]]
commenttime=json_response[j][columns[3]]
productid=json_response[j][columns[4]]
productcolor=json_response[j][columns[5]]
productsize=json_response[j][columns[6]]
score=json_response[j][columns[7]]
comment=json_response[j][columns[8]]
#有些用户没有追评,则返回空值
try:
aftercomment=json_response[j]['afterUserComment']['content']
except:
aftercomment=''
#将以上提取出的数据放到一个列表里
comment_one=[userid,username,buytime,commenttime,productid,productcolor,productsize,score,comment,aftercomment]
#生成器返回提取出的列表数据
yield (comment_one)
#存入csv文件
import csv
path=r'E:codeasusasus_comments.csv'
end_columns=['userId','userName','buyTime','commentTime','productId','productColor','productSize','score','comment','afterComment']
def SaveCsv():
comments=open(path,'w',newline='',encoding='utf-8')
w=csv.writer(comments)
w.writerow(end_columns)
comments=get_comments()
for comment in comments:
w.writerow(comment)
#运行爬虫函数,爬取评论数据并保存
SaveCsv()
数据探索:
一.此款产品对应多种规格,哪种规格的评论数比较多?
侧面反映出:哪款规格的销量比较好。
#提取productId评论总数排名前十的产品及规格
t=raw_data[['productId']]
t['productCount']=1
t=t.groupby('productId').agg('sum').reset_index()
#按评论数从大到小排序
t=t.sort_values(by='productCount',ascending=False).reset_index(drop=True)
#提取排名前十的产品规格及评论数
t=t.iloc[:10,:]
#根据产品id提取产品规格
def get_product(id):
productColor=raw_data[raw_data['productId']==id]['productColor']
productColor.reset_index(drop=True,inplace=True)
for i in range(len(productColor)):
if len(productColor[i])>5:
color=productColor[i]
break
return color
t['productColor']=t['productId'].apply(get_product)
t
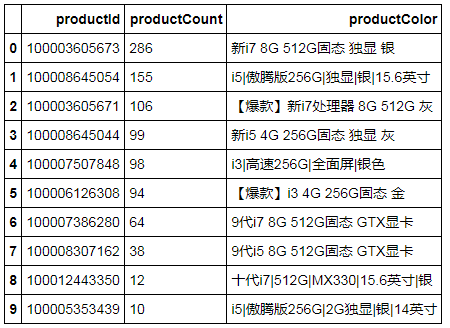
从上面结果可以看出:
1.最受用户欢迎的配置是:i7处理器;8G内存;512G固态硬盘;独立显卡。
这应该也是目前市场上的主流配置。
2.经济款:i5处理器;4G内存;256G固态硬盘;独立显卡。
这款配置低一档,但是价格也会低很多。这款产品适合向价格敏感性用户推广。
二.用户购买后多久会过来评价?
评价对于电商平台上的商品来说,是很重要的部分。而探索评价间隔天数,一方面从侧面反应出物流的速度,另一方面可以看到用户会不会及时来参与评价,可以对比销量数据,如果评价率过低,或者用户间隔很长时间才来评价,有必要制定相应的措施来促使用户及时评价。
#探索用户购买多少天后评价
from datetime import date
#计算日期间隔的函数
def get_gaptime(b_time,c_time):
c_time=c_time.split(' ')[0]
c_time=c_time.split('-')
b_time=b_time.split(' ')[0]
b_time=b_time.split('-')
gaptime=(date(int(c_time[0]),int(c_time[1]),int(c_time[2]))-
date(int(b_time[0]),int(b_time[1]),int(b_time[2]))).days
return gaptime
#计算日期间隔
gaptime=[]
for i in range(len(raw_data)):
b_time=raw_data.loc[i,'buyTime']
c_time=raw_data.loc[i,'commentTime']
gap=get_gaptime(b_time,c_time)
gaptime.append(gap)
raw_data['gapTime']=pd.DataFrame(gaptime)
#探索间隔时间的描述性统计分布
raw_data['gapTime'].describe().reset_index()
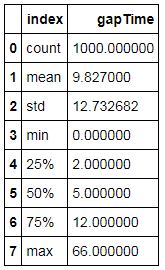
从上面数据可以看到:
1.参与评价的用户中,25%的用户在购买后,两天内就评价了。侧面说明物流时效还是很快的,现实中京东笔记本一般购买后第二天就能到货。
2.参与评价的用户中,50%的用户在购买后,五天内评价。笔记本也算是大件商品,购买后需要使用几天,而5天并不算太长。
3.参与评价的用户中,25%的用户在购买后,12天以上才参与评价。这部分用户可能是属于比较谨慎的用户,要多用段时间,然后再根据实际使用情况评价商品。
上述指标,同时可以作为用户画像的一个维度。
三.绘制用户评论数据的词云图
词云图可以反映出用户比较关心的点,同时利于品牌方了解用户心理,营销中也可以主打这些特点进行推广。
另外可以专门针对差评做词云图,更能针对性的解决用户体验不好的问题。
这部分分析按照本文步骤,很容易进行,如果想探索,把上面抓取的初始链接改个参数就OK,其它代码基本不用动。
#用户评论数据的词云分析
import jieba
import wordcloud
from PIL import Image
import matplotlib.pyplot as plt
#合并用户评论及追评
raw_data['text']=raw_data.apply(lambda x:str(x['comment'])+';'+str(x['afterComment']),axis=1)
#评论中一些词是京东评论页面提供的格式,用户按照这个格式填写,这部分不应该作为用户评论的一部分,剔除掉
def del_list(str1):
del_list=['运行速度:','屏幕效果:','散热性能:','外形外观:','轻薄程度:','其他特色:']
for i in del_list:
str1=str1.replace(i,'')
return str1
#剔除京东评论的固定格式词汇
raw_data['text']=raw_data['text'].apply(del_list)
#去除停用词
stopwords_dic=open(r'E:pythonstop_wordsstop_words.txt','rb')
stopwords_content=stopwords_dic.read()
stopwords_lst=stopwords_content.splitlines()
stopwords_dic.close()
#下面列表是去除停用词后,通过观察,我们这个文本里还存在的一些停用词,加到停用词表里。
#其中'华硕'作为品牌名称,本来抓的就是华硕的笔记本,没有统计的必要。
add_stopword=[',',';','nan','n','。','&','!','、','华硕','?','.','*']
#更新停用词表
stopwords_lst.extend(add_stopword)
#分词,并去除停用词。且同一个用户的评论内容,如果有重复词,也同时去除
raw_data['text_cut']=raw_data['text'].apply(lambda x:[i for i in set(jieba.cut(x)) if i not in stopwords_lst])
#把所有评论数据,汇总到一个列表里
text=[]
for i in raw_data['text_cut']:
text.extend(i)
#构建词频-词典
dic=dict()
for i in text:
if len(i) !=1:
dic[i]=text.count(i)
#dic = sorted(dic.items(),key=lambda x:x[1],reverse = True) #可以通过词频排序,观察高词频的情况
#定义词频背景,用的是华硕此款笔记本的一个图片
mask=np.array(Image.open(r'E:codeasusnotebook.jpg'))
wc=wordcloud.WordCloud(font_path='C:/Windows/Fonts/simhei.ttf', #设置字体格式
mask=mask, #设置背景图
max_words=100, #最多显示词数
max_font_size=150) #字体最大值
wc.generate_from_frequencies(dic) #从字典生成词云
image_colors=wordcloud.ImageColorGenerator(mask) #从背景图建立颜色方案
wc.recolor(color_func=image_colors) #将词云颜色设置为背景图方案
plt.figure(figsize=(6,6))
plt.imshow(wc) #显示词云
plt.axis('off') #关闭坐标轴
plt.show()

从上面词云图可以看出:
用户评论比较多的点是:
开机/运行速度快;外观轻薄好看;屏幕清晰;散热不错;性价比高。
这部分特点应该是产品的主要特点,在商品的标题及详情页描述中,可以针对性的进行优化。
上面就是简单的仅仅针对这款商品的评论数据进行探索分析,实际运用中,可以结合销量、用户信息等多维度数据进行更多角度的分析、探索。
最后
以上就是称心路人最近收集整理的关于京东商品评论分析(爬虫+分词+词云图)的全部内容,更多相关京东商品评论分析(爬虫+分词+词云图)内容请搜索靠谱客的其他文章。








发表评论 取消回复