五月两场 | NVIDIA DLI 深度学习入门课程
5月19日/5月26日
正文共9696个字,9张图,预计阅读时间28分钟。
监督学习的要点:
数据:对于输入数据 $$$x_i in R^d$$$,训练数据里的第i个样本。
模型:如何对于给定的 $$$x_i$$$预测 $$$hat{y}_i$$$。
1、线性模型: $$$hat{y}i=sum_j{w_j*x{ij}}$$$ (b=w0,有线性/对数几率回归). 对于不同的任务,$$$hat{y}_i$$$有不同的解释。如果是线性回归,则其可代表是预测的分数,如果是对数几率回归,则 $$$frac{1}{1+exp(-hat{y}_i)}$$$可解释为样例预测为正例的概率。
2、参数:从数据中学习的是参数,即所谓模型就是参数.所以线性模型可表示为: $$$Theta={w_j|j=1,2,...,d}$$$
3、最优化目标函数: $$$Obj(Theta)=L(Theta)+omega(Theta)$$$
其中前者是训练损失,度量的是模型对于训练数据的拟合度。后者是正则,度量的是模型的复杂度。
4、泛化训练损失: $$$L=sum_{i=1}^{n}l(y_i,hat{y}_i)$$$
对于平方误差损失: $$$ l(y_i,hat{y}_i)=(y_i-hat{y}_i)^2$$$
对于对数几率损失:$$$ l(y_i,hat{y}i)=y{i}ln(1+e{-hat{y}_i})+(1-y_{i})ln(1+e{hat{y}_i})$$$
(对数几率实际上类似于线性回归运用到分类时扩展的一种方法,对每个样本,输出的是一个几率,如果是分类的话则可以依照此几率来分类,它起到了一个将分类标记与线性回归模型连接起来的作用,根据最大似然法来求解最佳的参数)
5、正则: $$$L2=lambda{||w||^2}$$$
$$$L1=lambda{||w||}_1$$$
为什么要在目标里包含训练损失和正则两项?各有用途:最优化训练损失使得模型预测的更好,也就是期望我们的模型与真实分布尽可能拟合好。最优化正则则是为了获取一个简单的模型,使得模型在实际的预测中方差小,预测更据鲁棒性。
偏差与方差概念
偏差:描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据.
方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,
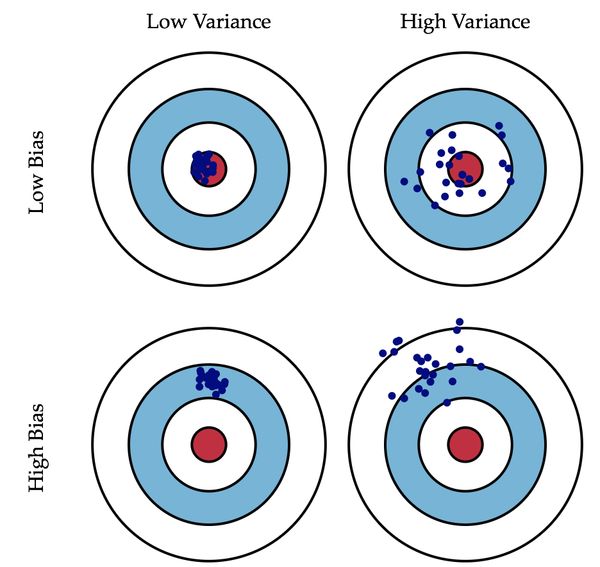
方差,是形容数据分散程度的,算是“无监督的”,客观的指标,偏差,形容数据跟我们期望的中心差得有多远,偏差则可以算是“有监督的”,有人的知识参与的指标(我们知道真实值大概是什么,真实值!=样本值)。
这也就是:方差大是常态,偏差大是要负责的。
偏差-方差分解
用于解释学习算法泛化性能的一种思路。即将学习算法的期望泛化误差做拆解。算法在不同的数据集上学得的效果很可能不同,即便这些数据集对于来自于一个分布的数据集,也就是说误差是永远有的,除非拿到全集,或者发生了离奇的巧合。
假设对于测试样本x,其在数据集中标记为yd,实际标记为y(有可能因为噪音导致二者不同),f(x,D)是学习算法在训练集D上可以得出的输出。以下省去推导过程,直接给出结果:
噪声为:(且假设噪声期望为零)
$$
epsilon2=E_D[(yd-y)2]
$$
期望输出 和 其与真实标记的差别即偏差(bias):
$$
hat{f}(x)=E_D[f(x;D)]
$$
$$
bias2(x)=(hat{f}(x)-y)2
$$
使用样本数相同的不同训练集产生的方差为:
$$
var(x)=E_D[(f(x;D)-hat{f}(x))^2]
$$
推导,得算法的期望泛化误差为:
$$
E(f;D)=E_D[(f(x;D)-yd)2]=bias2(x)+var(x)+epsilon^2
$$
由此可见,偏差刻画了算法的拟合能力,方差表示了同样大小的训练集的变动所导致的学习性能的变化,噪声表达了误差下限。泛化性能由以上三个决定。
决策树回顾
树形结构,基于特征对实例进行分类,可以看做是if-then规则的集合。
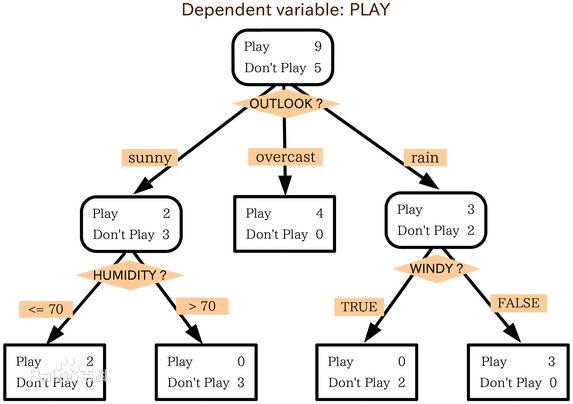
一般包括三个步骤:
1、特征选择:基本思路->信息增益(样本纯度越高,信息熵越小。在选择一个特征的某特征值进行分枝后,若能够使得纯度提升,即能降低熵->高的信息增益,则以该值分枝)
$$
Ent(D)=-sum_{k=1}^{N}p_klog_2p_k
$$
$$
Gain(D,a)=Ent(D)-sum_{n=1}Nfrac{|Dn|}{|D|}Ent(D^n)
$$
2、决策树生成:递归生成即可。
3、剪枝(前剪枝/后剪枝):主要是为了防止过拟合(为了简单本文后续不提及剪枝相关的东西)。
CART回归
与决策树大致相同,区别点在于:
处理的特征值有可能不是类别标记而是连续值。
二叉分支。
在每个叶节点和分支节点上都有一个分值,分值的计算方法一般为均值,即在每个节点上使用平方误差最小的准则来确定最优输出值(其实就是本节点内所有样本的输出y的均值)。
最主要的问题:选择什么策略来对输入空间划分(分支)?
最普通的方法:两层循环->对于每个特征的每个特征值计算:以该策略分支后,两个节点上的平方误差(节点内所有实例输出减去该分值后平方),取最小平方误差的那一对特征和特征值。公式阐述:
$$
min_{j,s}[min_{c_1}sum_{x_i in R_1(j,s)}(y_i-c1)^2+min_{c_2}sum_{x_i in R_2(j,s)}(y_i-c2)^2]
$$
由以上,回归树的生成可以总结为:对输入数据,选择最佳分割点,计算子节点(实例,分值),递归。停止后假设该树会有M个叶节点,这棵树就是模型。对于新输入数据放到二叉树里下行走到最后就行了。
所以,停止条件?没有找到相关的说明,一般来讲,是认为规定一下树的高度。而且似乎是必须规定的,否则树的递归是会走到每个叶节点里的样本对应输出值都一样时才会停止。
CART分类
CART分类树和决策树基本一致,只是将信息增益改为了基尼指数。
$$
Gini(D)=sum_{k=1}{N}sum_{k1 neq k}p_kp_{k1}=1-sum_{k=1}N{p_k^2}
$$
$$
Gini_index(D,a)=sum_{v=1}{V}frac{|Dv|}{|D|}Gini(D^v)
$$
基尼指数和熵类似,值越大表明样本集合不确定性越大,即纯度越低,所以我们选择基尼指数最小的特征和特征值。
那么假如一个特征下对应多个特征值,CART树要求是二叉树,怎么办?没有找到相关文章。一般来讲,如果是单独的决策树算法来分类,实现程序时简单的忽略掉只能二叉分类这个限制也没有什么差别。但是对于后面讲的boosting,GBDT等,实现程序里是选择按照其值等于和不等于来二分支的(也不一定,只是我看过的例子都是这样)。
默认子学习器就是决策树
三个思路
将多个学习器进行结合。随着集成个体分类器数目T的增大,集成的错误率将指数级下降,最终趋向于零。这里主要讲了三种方法,分别为boosting,Bagging,随机森林。
Boosting
先从初始训练集中训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整。使得先前基学习器做错的训练样本在后续受到更多关注。
Adaboosting
先从初始训练集中训练出一个基学习器,再根据基学习器的表现对训练样本分布和基学习器权重进行调整。使得先前基学习器做错的训练样本在后续受到更多关注。
Adaboosting的思路是基于加性模型。
步骤大致是:
首先初始化样本权值分布。
基于此分布从数据集D中训练出分类器ht,再根据此分类器误差来赋予其相应权值。
根据此值对训练集数据分布进行更新。更新的方法:一般是重赋权法,对于不能够读取权值的基学习方法可采用重采样法,即根据样本权重分布对训练集重新进行采样。
Bagging
实际中,想要个体学习器相互独立是很难的,但可以尽量使它具有较大的差异。
Bagging即采样时采用有放回采样,这样,初始训练集中约有63.2%的可以出现在采样结果里。而后训练多个树,预测时输出多个树的综合结果(民主投票)。与boosting区别是它是独立,民主的。
RT随机森林
是对决策树集成学习器进行的变动,即在选择划分属性时,不再采用求取最优划分属性的方法,而是先在所有属性里随机采样k个,然后在这k个里得到最优划分属性。采用这种方法训练多个树。预测方法与bagging一样。
其不仅是样本扰动,还有属性扰动,所以其表现往往很好。
随机森林的思路也是Bagging,即由对属性的有放回采样变为了对属性的采样。下面主要叙述Bagging与Boosting的差别。
Bagging对样本进行了多次的有放回采样,正常来说这样多个样本集合训练出来的多棵树,按照民主投票的方式获取最后结果,这样,如果我们可以假设多个样本集合之间是独立的,则最后的结果肯定会具有更好的鲁棒性,即方差会比较小。这种民主投票的思路对于偏差没有什么影响。
而Boosting 则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行加权,所以随着迭代不断进行,误差会越来越小,即其更加关心的是目前为止分错的点,多次迭代之后,结果会相当的拟合。所以模型的 bias 会不断降低。这种思路对于方差没有什么影响。
所以在实际中:
Bagging的树常常很深,因为其方差很小了,需要的就是进一步减小偏差即尽可能去拟合输出。而其多棵树投票的方式某种程度上也可以防止过拟合,从而树虽然深但是也不那么担心overfitting。
Boosting的树常常很浅,它是通过多棵树的累积训练来获得结果的,其模型本身就导致了bias本身就很小,所需要考虑的就是如何选择方差更小即更加简单的模型来避免过拟合,所以其深度一般很浅。
结合策略
结合方法
1、加权平均和简单平均法,对于离散的,可以采用绝对多数投票法、相对多数投票法、加权投票法。
2、学习法:这里将个体学习器称为初级学习器,而将结合策略称为次级学习器。
由于初级学习器和次级学习器都需要学习,即都需要样本和标签来学习。故而如果二者使用的样本一样则很容易过拟合。
采用交叉验证法。即将样本分为k份,采用其中的k-1份作为初级学习器,训练完毕后用1份作为次级学习器。这里次级学习器的输入为T个初级学习器在该样本上的输出,标签为该样本真实标签。如果k次训练后得到次级学习器。
个体学习器准确性越高,多样性越大,则集成越好。平均两个学习器多样性度量有:不合度量,相关系数,Q统计量,k统计量。
增强多样性:
1、数据样本扰动,即从数据集里产生不同的数据子集。通常是采样法,该方法对于对数据敏感即训练样本稍有变化就导致学习器显著变动的学习器有效。
2、输入属性扰动,从不同子空间观察数据。随机森林方法。
3、输出表示扰动,多训练样本的类标记稍作变动,如翻转法。
4、算法参数扰动,调参。
GBDT
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法。
该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力(generalization)较强的算法。近些年更因为被用于搜索排序的机器学习模型而引起大家关注。为了简洁,下面假定数据集很好,不包含缺失。
这里的回归含义:回归树所能够得到的结果其实也是离散值,是连续值中的离散值,区别于分类标记,并且与回归也有所不同。在回归树里对每个节点都增加一个预测值,该值等于这个节点里所有样本输出值的平均。可以看到的是GBDT的应用是很容易扩展成分类的,其实也一般更多用于分类而非回归。它也是分类算法里表现常常是最好的那一个。
GBDT的思路和简例
与上面adaboosting方法不同,GBDT里多棵决策树对多个子学习器的结果是累加的,其思路是:每一棵树学的是之前所有树的结论和的残差,残差->就是一个加上预测值后能够得到真实值的累加量。
比如,一个人年龄是18岁,第一棵树预测是12岁,差了6岁,此时第二棵树里其标记即为6岁,如果第二棵树的输出预测为5岁,则仍然存在1岁的残差,第三棵树里其标记为1岁。
下面是一个例子,样本为四个人ABCD,想要预测的是他们的年龄。限制每棵树的叶节点数最大为2即高度为2(以root高度为1记).

在第一棵树上,我们选择出了分割点,并且将样本分到两个叶节点,左边叶节点输出值为15,并且针对真实的数值给出了该节点中样本的残差。右边同理。在第二棵树中,输入的仍然是这四个人,但是他们的标签不再是年龄,而是残差值。经过这一棵树,残差值都为0了,训练结束。对于新进的样本,不妨就对第一个人A来说,第一棵树输出15,第二棵树输出-1,15+-1=14.所以预测年龄为14.
使用GBDT的原因:
boosting的最大好处在于,每一步的残差计算其实是变相的增大了分错instance的权值,而已经分对的instance则都趋向于0.这样后面的树就会越来越专注那些在前面被分错的instance。
Shrinkage(缩减)
Shrinkage的思想认为,每次走一小步逐渐逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易避免过拟合。即:它不信任每一棵残差树,它认为每棵树只学习到了部分真理,累加的时候只累计一小部分 **,通过多学几棵来弥补不足。
步子迈大了,容易出现问题。
没有Shrinkage时:(yi表示第i棵树上y的预测值, $$$hat{y}_i$$$表示第i棵树的输入值。 y(1~>i)表示前i棵树y的综合预测值)
$$$hat{y}(i+1)$$$=y真实值-y(1~>i)
y(1~>i)=sum(y1,y2,,,yi)
shrinkage不改变第一个方程,只把第二个改为:y(1~>i) =y(1~>i-1)+step*yi
即其仍然以残差为学习目标,但是对于残差学习出来的结果,只累加一小部分(step)来逐渐逼近目标.step一般都比较小,如0.1~0.001,这导致各个树的残差是渐变的而不是陡变的。
直觉上就是不像直接用残差一步修复误差,而是只修复一点点,其实就是将大步切分为小步。本质上来看,shrinkage为每棵树设置了一个权值,累加时要乘以这个权值。这和gradient没有关系。这个权值就是step。shrinkage能够减少过拟合。
泛化意义上的Boosting
Boosting最终表示为多个模型的加法模型为:
$$
f(x)=sum_{m=1}^MT(x;Theta_m)
$$
前向分步算法
输入:训练数据集T=(xi,yi),...(xn,yn);损失函数L(y,f(x));基函数集{b(x;y)};
输出:加法模型f(x)
1、初始化 $$$f_0(x)=0$$$
2、对m=1,2,...M:
极小化损失函数
$$
(beta_m,gamma_m)=arg min_{beta,gamma}sum_{i=1}^{N}L(y_i,f_{m-1}(x_i)+beta b(x_i;gamma))
$$
得到参数$$$beta_m$$$,$$$gamma_m$$$
更新:
$$
f_m(x)=f_{m-1}(x)+beta_{m}b(x;gamma_m)
$$
3、得到加法模型
$$
f(x)=f_M(x)=sum_{m=1}^Mbeta_{m}b(x;y_m)
$$
以上也是提升方法的大致结构,其中存在变化的部分就是极小化损失函数这一步。损失函数的不同也决定了算法的最终效果。
下面是各种不同的损失函数对于的方法:
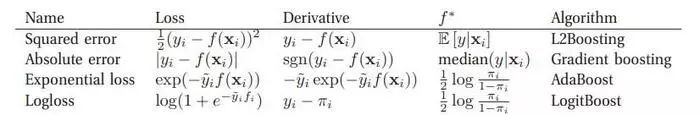
上面所讲的就是损失函数为均方误差损失函数对应的情况。推导如下:
$$
L(y,f(x))=(y-f(x))^2
$$
其损失变为:
$$
L(y,f_{m-1}(x)+T(x;theta_m))=[y-f_{m-1}(x)-T(x;theta_m)]2=[r-T(x;theta_m)]2
$$
这里:
$$
r=y-f_{m-1}(x)
$$
即为当前模型拟合数据的残差。所以此处对回归问题的提升树算法来说,只需要简单地拟合当前模型的残差。
下面给出提升树算法的具体过程:
输入:训练数据集
输出:提升树 $$$f_M(x)$$$
初始化 $$$f_0(x)=0$$$
对m=1,2,....,M:
计算残差: $$$r_mi=y_i-f_{m-1}(x_i)$$$
拟合残差 $$$r_{mi}$$$来学习一个回归树,得到 $$$T(x;theta_m)$$$
更新 $$$f_m(x)=f_{m-1}(x)+T(x;theta_m)$$$
得到回归树模型 $$$ f_M(x)=sum_{m=1}^{M}T(x;theta_m)$$$
泛化意义上的Gradient boosting
所谓的GB其实就是在更新的时候选择梯度下降的方向来保证最好的最后结果。
以上的残差即为损失函数为平方误差时所选择的’下降方向‘,而当一般的损失函数而言,往往每一步优化并不那么容易,针对这一问题,freidman提出梯度提升算法,这是利用最速下降法的近似方法,其关键是利用损失函数的负梯度(残差的估计值)在当前模型的值:
$$
-[frac{dL(y,f(x_i))}{df(x_i)}]{f(x)=f{m-1}(x)}
$$
在GBDT模型中的“参数”是什么?在GBDT中,参数对应了树的结构,以及每个叶子节点上面的预测分数。
因为现在我们的参数可以认为是在一个函数空间里面,我们不能采用传统的如SGD之类的算法来学习我们的模型,因此我们会采用一种叫做additive training的方式(另外,在我个人的理解里面,boosting就是指additive training的意思)。每一次保留原来的模型不变,加入一个新的函数$f$到我们的模型中。
理解:和梯度下降相似,都是求梯度,需要注意的是这里是对损失函数里的 $$$f_{m-1}(x)$$$来求下降方向,从以前梯度下降法里对w求梯度后求出的 $$$delta w$$$即为w的增量。推广到这里,可以理解为对f(x)求梯度后求出的$$$delta f(x)$$$即为f(x)的增量,而Boosting也正是要求所有f(xi)树的和。当L为平方误差时,求出的值也就是前面所提到的残差。
下面是梯度提升算法:
输入:训练数据集T,共N个样本
输出:损失函数L(y,f(x))
初始化 $$$ f_0(x)=arg min_csum_{i=1}^{N}L(y_i,c)$$$
这一步估计使得损失函数极小化的常数值计算损失函数的负梯度在当前模型的值,将其作为残差的估计。对于平方损失函数来说,它就是通常所说的残差。
对m=1,2,3...M:
对i=1,2,3...N计算:
$$
r_{mi}=-[frac{dL(y,f(x_i))}{df(x_i)}]{f(x)=f{m-1}(x)}
$$对 $$$ r_{mi}$$$拟合一个回归树,得到第m棵树的叶结点区域 $$$ R_{mj}$$$,j=1,2,3,...J.这一步是估计回归树叶节点区域,以拟合残差的近似值。
对j=1,2,3,...J,计算
$$
c_{mj}=arg min_c sum_{x_i in R_{mj}}L(y_i,f_{m-1}(x_i)+c)
$$
(这一步利用线性搜索估计叶结点区域的值,使得损失函数极小化,其实 $$$ f_{m-1}$$$指的就是前面所有树的输出累计和,这一步就是计算在当前模型下每个叶结点上应该如何输出c才能使得损失函数最小。)
更新 $$$ f_m(x)=f_{m-1}(x)+sum_{j=1}^{J}c_{mj}I(x in R_{mj})$$$
得到回归树:
$$
fhat(x)=f_M(x)=sum_{m=1}{M}sum_{j=1}{J}c_{mj}I(x in R_{mj})
$$
似乎没有提到正则,确实是这样,传统的GBDT算法步骤里确实没有正则项(我所找的都没有)。前面也有所提及,boosting里的树高度一般都设置的很低,再加上多棵树累积结果,其实其本身就不太容易过拟合。不过在具体实现时(xgboost)可以使用这样的思路:(树的节点个数+树的叶节点的输出值的L2范数) 来作为复杂度。
shrinkage也没有在这个步骤里,确实是这样,在具体实现时一般都会有,比如xgboost。这个值一般会设置的较小,而把迭代次数(即树的个数)设置的大一些。
监督学习?将GBDT里的步骤和监督学习的几点对应一下:
参数(模型)指的是多棵树,具体到每棵树,我们所学习到的实际是这个树的结构(分叉点)。
最优化目标函数:就是算法步骤里的损失函数。不同的在于这里我们的目标函数是一系列函数组成的,并且目的是要选择下一个函数使得损失函数最小。最简单的,平方误差损失里我们的最优化目标函数就是平方误差损失,算出的残差就是下一个函数要参照的东西。并且,这里可以加上树的正则项。
最优化方法:梯度提升方法。
以上对应的意义在于可以使模型一般化。
补充

那么,为什么呢?
1、理论:集成树的方法通常有更好的可控性。
想象对于一个任务,当使用LR模型,如果underfit,则可以通过增加特征或者加高阶特征.
问题是,这样加了之后模型的复杂度很可能会提升很多,例如对于模型中含有$$$x^2.5$$$这样一项的真实函数,如果我们用LR,则发现阶数为2时不行就变为阶数为3,就过了。而组合树(GBDT),在underfit时,就增加一个很弱的树,即前进的步长很短,每次进步一点点,可控性更好。
2、数据:噪音,距离,非线性,正则,分布
实际的数据噪音是必须有的,而树的算法通常来说抗噪能力更好。
它对于标签特征也很友好。举例来说对于喜欢苹果,梨,香蕉这样的三个标签,树算法无需去鉴别三个值的距离,而其他分类模型,大都难以处理这样的特征。实际数据往往特征非常多,我们很难去预先设置距离度量。
并且,随着树的生长,能够产生高度非线性的模型。而SVM等则需要借助核函数,如何确定合适的核函数又是一个问题。
多个树决定结果,本身就能够起到正则化的作用(有相关论文证明,直观来说就是即使每棵树都过拟合,但是大家过拟合的地方不一样,所以最后结果还是没问题的)。非参数模型,不需要假定数据的分布,这一点和NN类似。
3、xgboost
作为一个高效,灵活,简单,可扩展,在传统GBDT算法上优化的GBDT实现,陈天奇同学所写的xgboost包被广泛运用在比赛中。
但是,即便如此,也不能说gbdt之类的组合学习就是最好的分类方法,原因:
"No Free Lunch Theorems"
对于有监督学习,NFL证明在不对问题做任何假设和限定的情况下,不存在一个效果最优的分类器。所以,对于GBDT和SVM,总会在一个问题上GBRT比SVM更强。反之亦然。
换句话说,脱离了问题(数据)的性质,分布、大小、loss function,讨论分类器的好坏是没有意义的。最容易想到的,GBDT在高维稀疏数据上的表现显然是不太可能比SVM好的。
本文总共涉及了三个东西,第一个是组合学习的思路,第二个是简单的GBDT,第三个是GBDT,如果说还有什么的话,就是将子学习器决策树也提及了一下。
原文链接:https://www.jianshu.com/p/3e9e1c5c22e3
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看

LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础
最后
以上就是朴实背包最近收集整理的关于GBDT(梯度提升决策树)总结笔记的全部内容,更多相关GBDT(梯度提升决策树)总结笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复