特征工程系列:空间特征构造以及文本特征构造
本文为数据茶水间群友原创,经授权在本公众号发表。
关于作者:JunLiang,一个热爱挖掘的数据从业者,勤学好问、动手达人,期待与大家一起交流探讨机器学习相关内容~
0x00 前言
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。
那特征工程是什么?
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
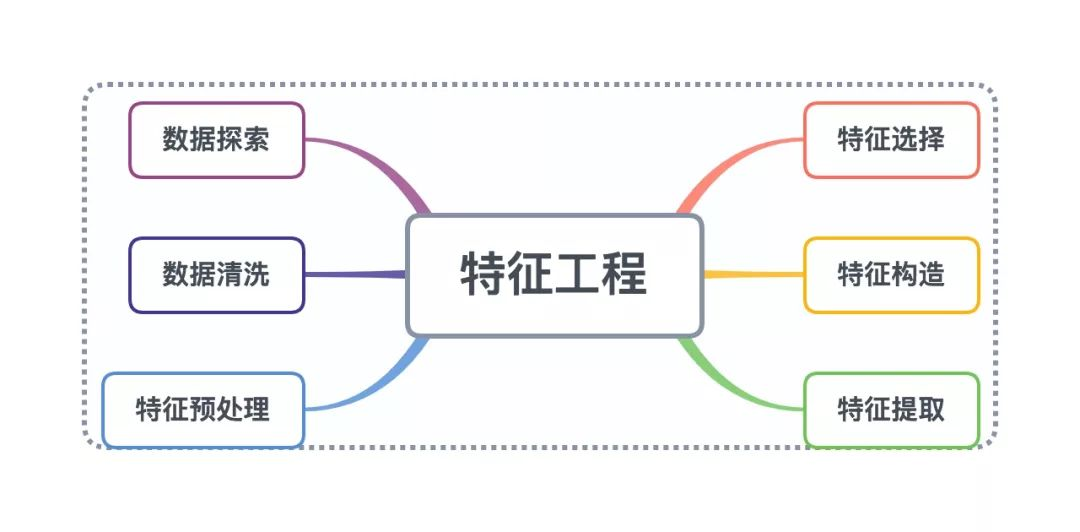
特征工程又包含了 Data PreProcessing(数据预处理)、Feature Extraction(特征提取)、Feature Selection(特征选择)和 Feature construction(特征构造)等子问题,本章内容主要讨论特征构造的方法。
创造新的特征是一件十分困难的事情,需要丰富的专业知识和大量的时间。机器学习应用的本质基本上就是特征工程。
——Andrew Ng
0x01 特征构造介绍
空间特征构造以及文本特征构造具体方法:
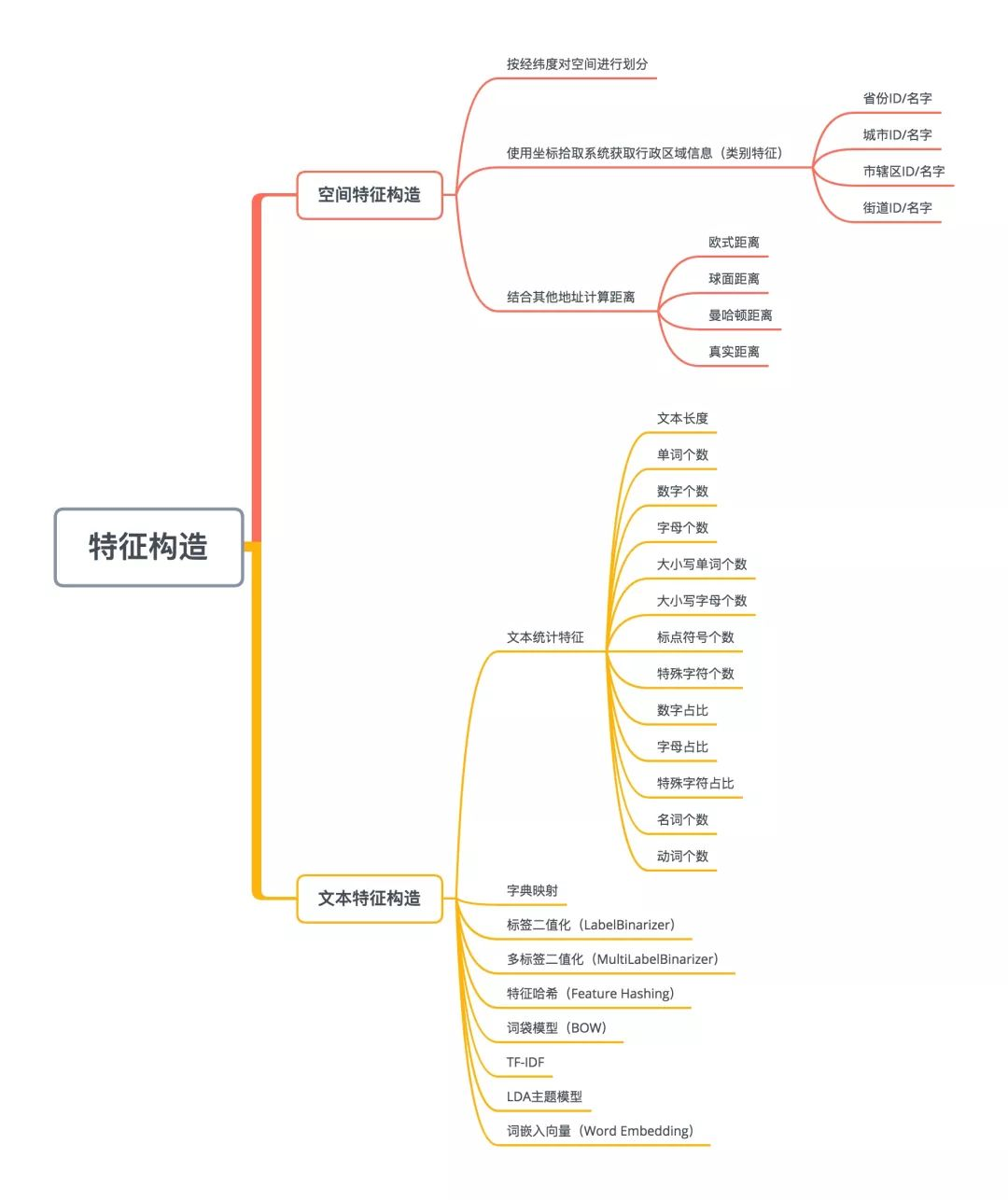
0x02 空间特征构造
1.按经纬度对空间进行划分
划分流程:
1)对经纬度进行特征分桶,得到类别特征
binned_latitude(lat) = [
0 < lat <= 10
10 < lat <= 20
]
binned_longitude(lon) = [
0 < lon <= 15
15 < lon <= 30
]
2)使用笛卡尔乘积生成空间划分后的特征
| 样本 | 0<lat<=10& 0<lon<=15 | 0<lat<=10& 15<lon<=30 | 10<lat<=20& 0<lon<=15 | 10<lat<=20& 15<lon<=30 |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 |
| 2 | ... | ... | ... | ... |
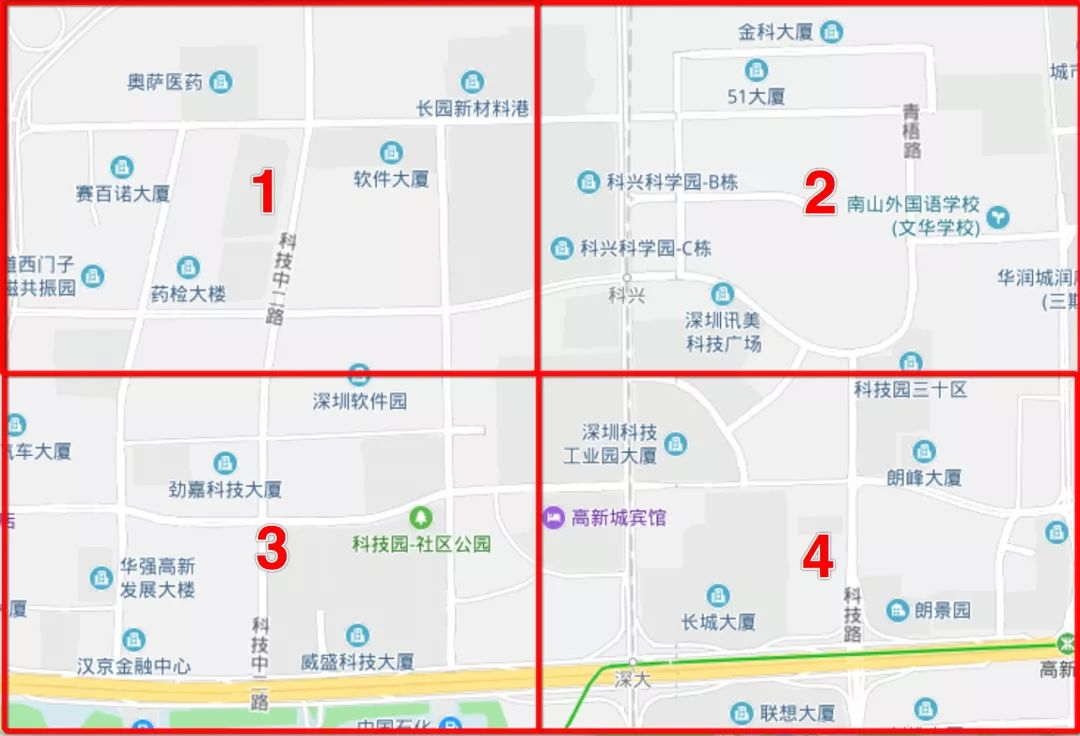
3)对每块子空间进行编码,得到类别特征
效果类似下图,把空间划分为多块子空间。
2.使用坐标拾取系统获取行政区域信息(类别特征)
-
省份ID/名字 -
城市ID/名字 -
市辖区ID/名字 -
街道ID/名字
3.结合其他地址计算距离
例如:计算每个地点至某商业中心的距离。
距离类型:
-
欧式距离 -
球面距离 -
曼哈顿距离 -
真实距离
0x03 文本特征构造
1.文本统计特征
-
文本长度; -
单词个数; -
数字个数; -
字母个数; -
大小写单词个数; -
大小写字母个数; -
标点符号个数; -
特殊字符个数; -
数字占比; -
字母占比; -
特殊字符占比; -
名词个数; -
动词个数;
适用范围:所有文本特征。
统计单词的个数作为特征的程序实现
import pandas as pd
# 构造数据集
df = pd.DataFrame({'兴趣': ['健身 电影 音乐', '电影 音乐', '电影 篮球', '篮球 羽毛球', ]})
# 统计兴趣爱好的数量
df['兴趣数量'] = df['兴趣'].apply(lambda x: len(x.split()))
display(df.head())
# 输出:
兴趣 兴趣数量
0 健身 电影 音乐 3
1 电影 音乐 2
2 电影 篮球 2
3 篮球 羽毛球 2
2.字典映射
有序特征的映射,使用的方法是先构建一个映射字典 mapping,再用 pandas 的 map() 或者 replace() 函数进行映射转换。
适用范围:只有一个词语的有序特征。
程序实现:
import pandas as pd
df = pd.DataFrame({'edu_level': ['博士', '硕士', '大学', '大专及以下']})
#构建学历字典
mapping_dict={'博士':4,'硕士':3,'大学':2,'大专及以下':1}
#调用map方法进行转换
df['edu_level_map']=df['edu_level'].map(mapping_dict)
display(df.head())
# 输出
edu_level edu_level_map
0 博士 4
1 硕士 3
2 大学 2
3 大专及以下 1
3.标签二值化(LabelBinarizer)
功能与 OneHotEncoder 一样,但是 OneHotEncode 只能对数值型变量二值化,无法直接对字符串型的类别变量编码,而 LabelBinarizer 可以直接对字符型变量二值化。
适用范围:只有一个词语或者包含多个词语的特征。例子:
只有一个词语的特征:职业。
有多个词语的特征:用户兴趣特征为“健身 电影 音乐”。
程序实现:
import pandas as pd
from sklearn.preprocessing import LabelBinarizer
df = pd.DataFrame({'职业': ['老师', '程序员', '警察', '销售', '销售', ]})
lb = LabelBinarizer()
lb.fit(df['职业'])
print('类别:{}'.format(lb.classes_))
# 输出:类别:['程序员' '老师' '警察' '销售']
display(lb.fit_transform(df['职业']))
# 输出:
array([[0, 1, 0, 0],
[1, 0, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1],
[0, 0, 0, 1]])
4.多标签二值化(MultiLabelBinarizer)
把有多个单词的文本转换01特征向量,转换后的结果可能会有多个为1的值。
适用范围:包含多个词语的特征。
程序实现:
import pandas as pd
from sklearn.preprocessing import MultiLabelBinarizer
# 构造数据集
df = pd.DataFrame({'兴趣': ['健身 电影 音乐', '电影 音乐', '电影 篮球', '篮球 羽毛球', ]})
df['兴趣列表'] = df['兴趣'].apply(lambda x: x.split())
display(df.head())
# 输出:
兴趣 兴趣列表
0 健身 电影 音乐 [健身, 电影, 音乐]
1 电影 音乐 [电影, 音乐]
2 电影 篮球 [电影, 篮球]
3 篮球 羽毛球 [篮球, 羽毛球]
# 构造特征
mlb = MultiLabelBinarizer()
feature_array = mlb.fit_transform(df['兴趣列表'])
print('类别顺序:{}'.format(mlb.classes_))
# 输出:类别顺序:['健身' '电影' '篮球' '羽毛球' '音乐']
print(feature_array)
# 输出:
[[1 1 0 0 1]
[0 1 0 0 1]
[0 1 1 0 0]
[0 0 1 1 0]]
5.特征哈希(Feature Hashing)
1)原理
特征哈希(Feature Hashing),特征散列化技术,或可称为 “散列法” (hashing trick) 的技术,使用哈希函数计算与名称对应的矩阵列。
当特征取值列表很大,且有多个需 onehot 编码时,会导致特征矩阵很大,且有很多 0,这时可用哈希函数将特征根据特征名和值映射到指定维数的矩阵。
2)适用范围:大数据集文本。
3)程序实现
from sklearn.feature_extraction.text import HashingVectorizer
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
hv = HashingVectorizer(n_features=10)
X = hv.fit_transform(corpus)
print('shape={}'.format(X.shape))
# 输出:shape=(4, 10)
print(X.toarray())
# 输出:
[[ 0. 0. 0. 0. 0. 0. -0.57735027 0.57735027 -0.57735027 0.]
[ 0. 0. 0. 0. 0. 0.81649658 0. 0.40824829 -0.40824829 0.]
[ 0. 0.5 0. 0. -0.5 -0.5 0. 0. -0.5 0.]
[ 0. 0. 0. 0. 0. 0. -0.57735027 0.57735027 -0.57735027 0.]]
6.词袋模型(BOW)
1)原理
词袋模型假设我们不考虑文本中词与词之间的上下文关系,仅仅只考虑所有词的权重。而权重与词在文本中出现的频率有关。
词袋模型首先会进行分词,在分词之后,通过统计每个词在文本中出现的次数,我们就可以得到该文本基于词的特征,如果将各个文本样本的这些词与对应的词频放在一起,就是我们常说的向量化。
2)适用范围:长文本特征。
3)程序实现
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer(min_df=1)
X = vectorizer.fit_transform(corpus)
print(X.toarray())
# 输出:
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 2 1 0 1]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]
feature_name = vectorizer.get_feature_names()
print(feature_name)
# 输出:['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
由于大部分文本都只会用词汇表中很少一部分的词,因此词向量中有大量的0,也就是说词向量是稀疏的。因此在实际应用中一般使用稀疏矩阵来存储。
7.TF-IDF
在大文本语料中,一些词语出现非常多(比如:英语中的“the”, “a”, “is” ),它们携带着很少量的信息量。我们不能在分类器中直接使用这些词的频数,这会降低那些我们感兴趣但是频数很小的term。
我们需要对 feature 的 count 频数做进一步 re-weight 成浮点数,以方便分类器的使用,这一步通过 tf-idf 转换来完成。
1)主要思想
如果某个词或短语在一篇文章中出现的频率 TF 高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF 实际上是:TF * IDF,TF 表示词频(term-frequency),IDF 表示 inverse document-frequency。它原先适用于信息检索(搜索引擎的ranking),同时也发现在文档分类和聚类上也很好用。
2)实现原理
词频(Term Frequency,TF)
词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)

逆向文件频率(Inverse Document Frequency,IDF)
逆向文件频率 (inverse document frequency, IDF) IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
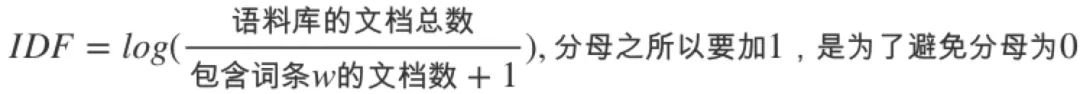
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的 TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
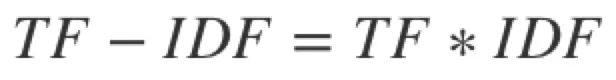
3)适用范围:长文本特征。
4)程序实现
from sklearn.feature_extraction.text import TfidfVectorizer
# 构造数据集
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
tfidf = TfidfVectorizer()
X = tfidf.fit_transform(corpus)
print(X.toarray())
# 输出:
[[0. 0.43877674 0.54197657 0.43877674 0. 0. 0.35872874 0. 0.43877674]
[0. 0.27230147 0. 0.27230147 0. 0.85322574 0.22262429 0. 0.27230147]
[0.55280532 0. 0. 0. 0.55280532 0. 0.28847675 0.55280532 0. ]
[0. 0.43877674 0.54197657 0.43877674 0. 0. 0.35872874 0. 0.43877674]]
# feature_name = tfidf.get_feature_names()
print(feature_name)
# 输出:['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
5)其它使用方法
实际使用时,特别是当文本内容比较长时,可以只保留权重值 top n 的向量:
-
使用 Top n 个单词的 TF-IDF 权重值作为特征值; -
提取 Top n 个单词,然后使用多标签二值化、词袋模型和词嵌入向量等相关方法来构造特征;
8.LDA主题模型
1)原理
LDA(Latent Dirichlet Allocation,隐含狄利克雷分布)是一种主题模型,它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题(分布)出来后,便可以根据主题(分布)进行主题聚类或文本分类。同时,它是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序的关系。
此外,一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
2)适用范围:长文本特征。
3)程序实现
import pandas as pd
import jieba
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
article_list = [
'沙瑞金赞叹易学习的胸怀,是金山的百姓有福,可是这件事对李达康的触动很大。易学习又回忆起他们三人分开的前一晚,大家一起喝酒话别,易学习被降职到道口县当县长,王大路下海经商,李达康连连赔礼道歉,觉得对不起大家,他最对不起的是王大路,就和易学习一起给王大路凑了5万块钱,王大路自己东挪西撮了5万块,开始下海经商。没想到后来王大路竟然做得风生水起。沙瑞金觉得他们三人,在困难时期还能以沫相助,很不容易。',
'沙瑞金向毛娅打听他们家在京州的别墅,毛娅笑着说,王大路事业有成之后,要给欧阳菁和她公司的股权,她们没有要,王大路就在京州帝豪园买了三套别墅,可是李达康和易学习都不要,这些房子都在王大路的名下,欧阳菁好像去住过,毛娅不想去,她觉得房子太大很浪费,自己家住得就很踏实。',
'347年(永和三年)三月,桓温兵至彭模(今四川彭山东南),留下参军周楚、孙盛看守辎重,自己亲率步兵直攻成都。同月,成汉将领李福袭击彭模,结果被孙盛等人击退;而桓温三战三胜,一直逼近成都。',
]
df = pd.DataFrame({'文章': article_list})
df['文章分词'] = df['文章'].apply(lambda x: ' '.join(jieba.cut(x)))
# 去停用词
stopwords_filename = 'data/HIT_stopwords.txt'
def get_stopwords_list(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
stopwords_list = get_stopwords_list(stopwords_filename)
# 把词转化为词频向量,注意由于LDA是基于词频统计的,因此一般不用TF-IDF来做文档特征
cnt_vector = CountVectorizer(stop_words=stopwords_list)
cnt_tf = cnt_vector.fit_transform(df['文章分词'])
print(cnt_tf)
# LDA建模
lda = LatentDirichletAllocation(n_topics=2,
learning_offset=50.,
random_state=0)
docres = lda.fit_transform(cnt_tf)
# 文档主题的分布
print(docres)
# 词列表
print(cnt_vector.get_feature_names())
# 主题和词的分布
print(lda.components_)
文档主题的分布
[[0.011413 0.988587 ]
[0.01987086 0.98012914]
[0.02454516 0.97545484]]
可见第一个和第二个文档较大概率属于主题2,则第三个文档属于主题1。
主题和词的分布
# 词列表
['347', '一起', '万块', '三人', '三套', '三年', '三月', '下海经商', '不想', '不要', '东南', '东挪西撮', '之后', '事业有成', '事对', '京州', '京州帝', '亲率', '以沫', '公司', '击退', '分开', '别墅', '前一晚', '县当', '县长', '参军', '同月', '名下', '后来', '周楚', '喝酒', '四川', '回忆起', '困难', '大家', '大路', '太大', '好像', '孙盛', '学习', '家住', '容易', '对不起', '将领', '康和易', '彭山', '彭模', '很大', '成汉', '成都', '战三胜', '房子', '打听', '时期', '有福', '李福', '李达', '李达康', '欧阳', '步兵', '毛娅', '永和', '没想到', '没有', '浪费', '温兵', '瑞金', '留下', '百姓', '直攻', '相助', '看守', '竟然', '而桓温', '股权', '胸怀', '袭击', '觉得', '触动', '话别', '豪园', '赔礼道歉', '赞叹', '踏实', '辎重', '这件', '连连', '逼近', '道口', '金山', '降职', '风生水']
# 每篇文章中每个词的权重
[[0.8881504 0.79494616 0.88179783 0.72261358 0.7825649 0.80513119
0.82520957 0.78049205 0.81985708 0.8075189 0.87151537 0.76026665
0.65725012 0.83192188 0.90323191 0.71051575 0.88162668 0.86249018
0.72348522 0.6859634 0.85216699 0.83801094 0.74827181 0.69732318
0.74391631 0.74718763 0.69555681 0.76728713 0.74016533 0.79252597
0.77958582 0.79331665 0.74595963 0.75151718 0.727614 0.68439365
0.7365373 0.82113611 0.83377043 0.80014547 0.81893092 0.7554505
0.75366236 0.77624709 0.71719464 0.84291399 0.80728078 0.70518523
0.83663851 0.76965302 0.76998538 0.84991333 0.82899283 0.83610283
0.77734802 0.79315431 0.71280155 0.85322984 0.75106508 0.76941605
0.89065397 0.87517217 0.76503638 0.81516416 0.82584699 0.85074834
0.79851313 0.73489237 0.79478729 0.84659611 0.75482478 0.87778172
0.73947408 0.79949669 0.74764634 0.82890922 0.79219997 0.7224377
0.80204307 0.8059688 0.72302738 0.85992729 0.76778892 0.86866686
0.7849911 0.74455222 0.71045084 0.74751146 0.75303978 0.88231417
0.70699699 0.81767636 0.7186858 ]
[1.1299159 1.73678241 1.70108861 1.63209268 1.24573913 1.17166174
1.17693454 1.6663298 1.13029804 1.24124777 1.12768978 1.16812888
1.21634987 1.13392317 1.23887105 1.24017098 1.19215182 1.34132569
1.30165184 1.19149742 1.20026225 1.28672459 1.69238527 1.22516326
1.18699503 1.2412282 1.21361079 1.26812676 1.22683284 1.17583033
1.19362235 1.35699255 1.21487917 1.2011862 1.25260128 1.69570488
4.42797426 1.12767075 1.17668924 1.63724037 3.07246623 1.14539765
1.26922685 1.70900224 1.25625654 1.19620242 1.1986915 1.73981801
1.28557341 1.24561315 1.63740977 1.2527631 1.687533 1.1186095
1.25932486 1.19376139 1.21549145 1.09958827 1.69627686 1.63400573
1.21757517 2.20850807 1.23833306 1.25239533 1.19799035 1.0949596
1.33692107 2.09364188 1.30451503 1.17003591 1.28622407 1.19110364
1.19129703 1.35972852 1.16049861 1.20988364 1.25763215 1.19630738
2.14870101 1.21893029 1.19022771 1.13023978 1.15592638 1.2631164
1.19764651 1.20991235 1.28665997 1.20537521 1.22217857 1.22113286
1.22059467 1.24019187 1.17945498]]
上面输出的“文档主题分布权重”和“主题和词分布权重”都可以作为特征来训练模型。
9.词嵌入向量(Word Embedding)
词嵌入(Word embeddings)是一种单词的表示形式,它允许意义相似的单词具有类似的表示形式。我们可以利用 Word Embedding 将一个单词转换成固定长度的向量表示,从而便于进行数学处理。
适用范围:所有文本特征。
1)只有一个词语的特征
例子:'职业': ['老师', '程序员', '警察', '销售', '销售', ]
程序实现:
from mitie import total_word_feature_extractor
import pandas as pd
import numpy as np
# 构造数据集
df = pd.DataFrame({'职业': ['老师', '程序员', '警察', '销售', '销售', ]})
# 加载语言模型,此处使用mitie的中文语言模型,也可以使用其他语言模型
twfe = total_word_feature_extractor('./total_word_feature_extractor_zh.dat')
# 把词语转换成embedding向量
embedding_array = np.array(list(df['职业'].apply(lambda x :twfe.get_feature_vector(x))))
print('shape={}'.format(embedding_array.shape))
# 输出:shape=(5, 271)
print(embedding_array)
# 输出:
[[ 0. 5.94052029 -0.55087203 ... 0.98895782 -0.45328307 -2.60366035]
[ 0. 5.73116112 -0.10071201 ... 0.08086307 -2.83375955 -1.30700874]
[ 0. 5.46504879 0.31765267 ... -0.67403883 -0.32645369 -0.19468342]
[ 0. 5.64302588 -0.60524434 ... -1.24884379 -1.201828 0.77896601]
[ 0. 5.64302588 -0.60524434 ... -1.24884379 -1.201828 0.77896601]]
2)包含多个单词的特征或者长文本
由于一个特征有多个单词,并且每个样本的单词数量不一样,而每个单词都有一个对应的 embedding 向量,把每个单词转换成特征向量后依然向量维数不一样,所以不能直接使用。
一般情况下,我们可以把每个多个单词对应的 embedding 向量求和/求平均值作为最终的特征向量。用求和/求平均运算单元的算法适用于任何单词数量的特征,这个求和/求平均值运算效果不错,实际上它会把所有单词的意思加起来,或者把所有单词的意思给平均起来。
包含多个单词的特征程序实现:
import pandas as pd
import numpy as np
from mitie import total_word_feature_extractor
# 构造数据集
df = pd.DataFrame({'兴趣': ['健身 电影 音乐', '电影 音乐', '电影 篮球', '篮球 羽毛球', ]})
df['兴趣列表'] = df['兴趣'].apply(lambda x: x.split())
display(df.head())
# 输出:
兴趣 兴趣列表
0 健身 电影 音乐 [健身, 电影, 音乐]
1 电影 音乐 [电影, 音乐]
2 电影 篮球 [电影, 篮球]
3 篮球 羽毛球 [篮球, 羽毛球]
# 加载Embedding模型
mitie_model_filename = 'data/total_word_feature_extractor_zh.dat'
twfe = total_word_feature_extractor(mitie_model_filename)
# 使用加法模型获取特征向量
add_embeding_array = np.array(list(df['兴趣列表'].apply(
lambda x : np.sum([twfe.get_feature_vector(w) for w in x], axis=0))))
print(add_embeding_array)
# 输出:
[[ 0. 17.69472837 0.99066588 ... 1.80016923 -3.46660849 1.61377704]
[ 0. 11.59600973 1.27471587 ... 1.51293385 -0.89438912 2.50961554]
[ 0. 11.41014719 0.71066754 ... 1.70346397 2.00526482 1.10128853]
[ 0. 10.79806709 -0.79963933 ... 1.38594878 3.12447354 0.0570921 ]]
# 使用平均值模型获取特征向量
mean_embeding_array = np.array(list(df['兴趣列表'].apply(
lambda x : np.mean([twfe.get_feature_vector(w) for w in x], axis=0))))
print(mean_embeding_array)
# 输出:
[[ 0. 5.89824279 0.33022196 ... 0.60005641 -1.15553616 0.53792568]
[ 0. 5.79800487 0.63735794 ... 0.75646693 -0.44719456 1.25480777]
[ 0. 5.7050736 0.35533377 ... 0.85173199 1.00263241 0.55064426]
[ 0. 5.39903355 -0.39981966 ... 0.69297439 1.56223677 0.02854605]]
长文本特征程序实现:
import pandas as pd
import jieba
import numpy as np
from mitie import total_word_feature_extractor
article_list = [
'沙瑞金赞叹易学习的胸怀,是金山的百姓有福,可是这件事对李达康的触动很大。易学习又回忆起他们三人分开的前一晚,大家一起喝酒话别,易学习被降职到道口县当县长,王大路下海经商,李达康连连赔礼道歉,觉得对不起大家,他最对不起的是王大路,就和易学习一起给王大路凑了5万块钱,王大路自己东挪西撮了5万块,开始下海经商。没想到后来王大路竟然做得风生水起。沙瑞金觉得他们三人,在困难时期还能以沫相助,很不容易。',
'沙瑞金向毛娅打听他们家在京州的别墅,毛娅笑着说,王大路事业有成之后,要给欧阳菁和她公司的股权,她们没有要,王大路就在京州帝豪园买了三套别墅,可是李达康和易学习都不要,这些房子都在王大路的名下,欧阳菁好像去住过,毛娅不想去,她觉得房子太大很浪费,自己家住得就很踏实。',
'347年(永和三年)三月,桓温兵至彭模(今四川彭山东南),留下参军周楚、孙盛看守辎重,自己亲率步兵直攻成都。同月,成汉将领李福袭击彭模,结果被孙盛等人击退;而桓温三战三胜,一直逼近成都。',
]
df = pd.DataFrame({'文章': article_list})
df['文章分词'] = df['文章'].apply(lambda x: ' '.join(jieba.cut(x)))
# 去停用词
stopwords_filename = 'data/HIT_stopwords.txt'
def get_stopwords_list(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
stopwords_list = get_stopwords_list(stopwords_filename)
def remove_stopwords_apply(article):
article_list = article.split(' ')
w_list = []
for w in article_list:
if w not in stopwords_list and len(w) > 0:
w_list.append(w)
return ' '.join(w for w in w_list)
df['文章分词去停用词'] = df['文章分词'].apply(remove_stopwords_apply)
display(df.head())
# 加载Embedding模型
mitie_model_filename = 'data/total_word_feature_extractor_zh.dat'
twfe = total_word_feature_extractor(mitie_model_filename)
# 使用加法模型获取特征向量
add_embeding_array = np.array(list(df['文章分词去停用词'].apply(
lambda x : np.sum([twfe.get_feature_vector(w) for w in x], axis=0))))
print('加法模型结果:n{}'.format(add_embeding_array))
# 使用平均值模型获取特征向量
mean_embeding_array = np.array(list(df['文章分词去停用词'].apply(
lambda x : np.mean([twfe.get_feature_vector(w) for w in x], axis=0))))
print('平均模型结果:n{}'.format(mean_embeding_array))
输出结果:
# 加法模型结果:
[[ 7.60000000e+01 8.59864759e+02 -2.00617124e+01 ... 2.81215128e+01]
[ 5.10000000e+01 5.03333374e+02 -4.37566057e+01 ... 1.04791496e+01]
[ 3.60000000e+01 4.14553602e+02 -6.15878703e+01 ... 1.78334359e+01]]
# 平均模型结果:
[[ 3.36283186e-01 3.80471132e+00 -8.87686389e-02 ... 1.24431472e-01]
[ 3.59154930e-01 3.54460123e+00 -3.08145110e-01 ... 7.37968283e-02]
[ 3.42857143e-01 3.94812954e+00 -5.86551145e-01 ... 1.69842246e-01]]
0x0FF 总结
-
空间特征(如GPS坐标)一般不能直接使用,需要先进行编码才能作为特征训练模型。可以直接把某块区域按一定的比例划分为多个子区域,也可以按行政区域划分为多个子区域,然后再对子区域进行标签二值化。
-
长文本特征的特征提取流程
-
Step 1:文本清洗,去除HTML标记、去停用词、转小写、去除噪声、统一编码等。 -
Step 2:分词。 -
Step 3:提取特征。
预告:下一篇文章将介绍自动化特征构造。
参考文献
[1] https://machinelearning-notes.readthedocs.io/zh_CN/latest/feature/%E7%89%B9%E5%BE%81%E5%B7%A5%E7%A8%8B%E2%80%94%E2%80%94%E6%97%B6%E9%97%B4.html
[2] https://www.cnblogs.com/nxf-rabbit75/p/11141944.html#_nav_12
[3] https://gplearn.readthedocs.io/en/stable/examples.html#symbolic-classifier
[4] 利用 gplearn 进行特征工程. https://bigquant.com/community/t/topic/120709
[5] Practical Lessons from Predicting Clicks on Ads at Facebook. https://pdfs.semanticscholar.org/daf9/ed5dc6c6bad5367d7fd8561527da30e9b8dd.pdf
[6] Feature Tools:可自动构造机器学习特征的Python库. https://www.jiqizhixin.com/articles/2018-06-21-2
[7] 各种聚类算法的系统介绍和比较. https://blog.csdn.net/abc200941410128/article/details/78541273
特征工程系列文章:
特征工程系列:数据清洗
特征工程系列:特征筛选的原理与实现(上)
特征工程系列:特征筛选的原理与实现(下)
特征工程系列:特征预处理(上)
特征工程系列:特征预处理(下)
特征工程系列:特征构造之概览篇
特征工程系列:聚合特征构造以及转换特征构造
特征工程系列:笛卡尔乘积特征构造以及遗传编程特征构造
特征工程系列:GBDT特征构造以及聚类特征构造
特征工程系列:时间特征构造以及时间序列特征构造
热门文章
直戳泪点!数据从业者权威嘲讽指南!
AI研发工程师成长指南
数据分析师做成了提数工程师,该如何破局?
算法工程师应该具备哪些工程能力
数据团队思考:如何优雅地启动一个数据项目!
数据团队思考:数据驱动业务,比技术更重要的是思维的转变

最后
以上就是欣慰柠檬最近收集整理的关于特征工程系列:空间特征构造以及文本特征构造特征工程系列:空间特征构造以及文本特征构造的全部内容,更多相关特征工程系列内容请搜索靠谱客的其他文章。








发表评论 取消回复