问题1:
需要查询的数据分散在各个微服务中
方案:
- API组合模式 / The API composition pattern:比较简单的模式,推荐使用。客户端分别调用各个服务,组织结果。
- 命令查询职责分离模式 / The Command query responsibility segregation (CQRS) pattern:比较牛逼的模式,较复杂。维护一组试图数据库专门用于查询。
1. 使用API组合模式查询数据
1.1. 以findOrder() 查询操作为例
findOrder() 通过主键(primary key)查询订单。接受orderId作为参数,返回OrderDetails对象,OrderDetails对象包含订单信息。
如下图,这个操作由前端模块在Order Status视图中发起。Order Status视图中展示的信息包括订单基本信息和配送信息。订单基本信息包括订单状态、支付状态、商家处理状态。配送状态包括位置,如果开始配送会有估计配送时间。
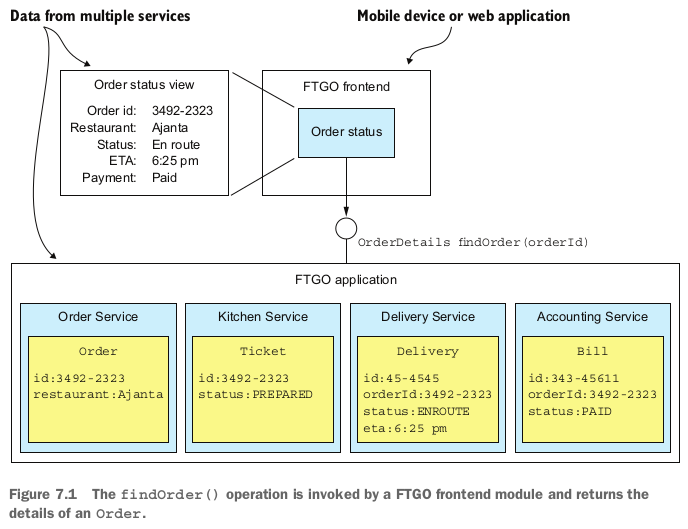
在为服务结构中,数据分散在一下服务中:
- Order Service: 包含订单基本信息和状态
- Kitchen Service: 商家准备状态以及预计准备时间
- Delivery Service: 订单配送状态,包括预计配送信息以及当前配置
- Accounting Service: 订单支付状态
1.2. API组合模式概述
在API组合模式中,查询操作需要分别和相关的服务交互并把查询结果组合起来。如下图所示:
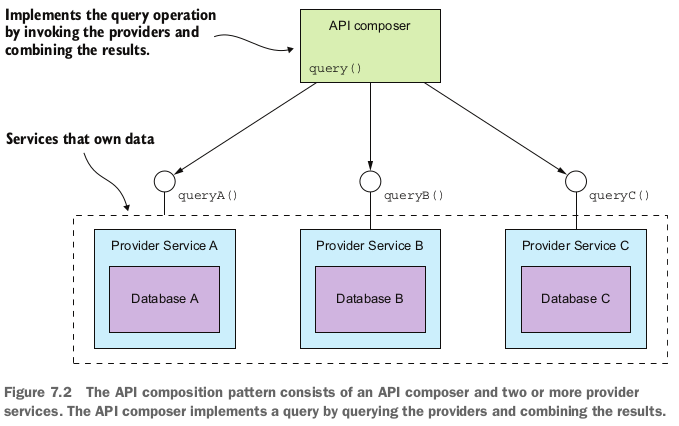
这个模式由两部分组成:
- API composer: APIcomposer发起查询,分别查询每个服务
- provider service: 提供查询数据的服务
上图中有三个provider service,API composer向这些服务请求数据,并把请求到的结果组合起来。API compser可以是网页应用,也可意识一个服务,比如API网关,这个服务会向前端暴露一个查询API。
总结
API组合模式 / API composition:分别请求各个服务的接口获取数据,再把请求到的数据组合起来
有多种因素决定是否可以使用这种模式来查询数据。比如数据是如何分隔的,数据服务提供的接口能力,以及数据服务使用的数据库等。
1.3. 使用API组合模式实现findOrder()查询操作
findOrder()查询操作和基于主键的链接查询类似。需要每个数据服务提供通过orderId查询数据的API。下图展示了Find Order Composer的设计:
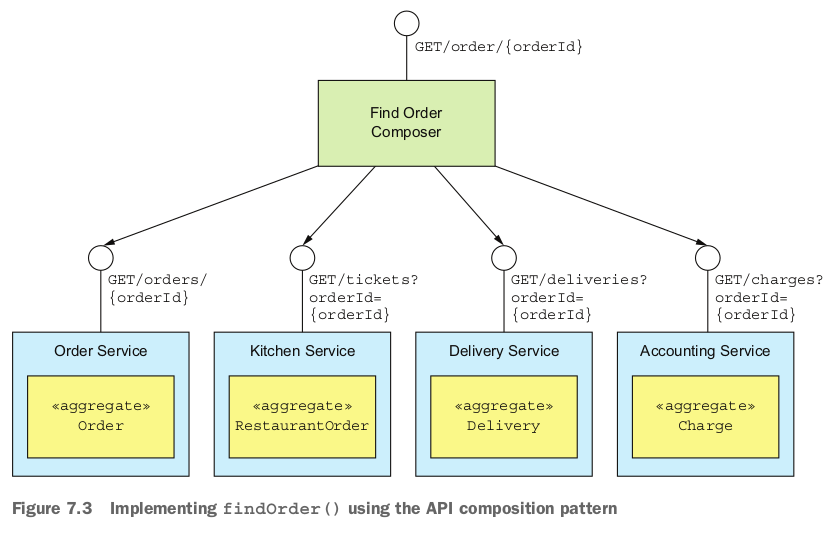
这个例子中,API composer通过REST接口向外暴露一个查询服务,每个数据服务也通过REST API提供服务。但是,数据服务使用gRPC等其他通讯协议也可以。
Find Order Composer暴露的REST服务为GET /order/{orderId}。这个服务会和四个数据服务交互,并通过orderId把各个服务的响应数据组合起来。每个数据服务通过REST接口响应单个聚合数据。比如OrderService通过主键查询数据并返回,其他服务通过外键查询数据。
1.4. API组合模式的设计问题
使用API组合模式需要解决一下问题:
- 架构中的哪些部分需要作为API composer
- 如何写出高效的聚合逻辑
定义API composer
有三种方式。
- 应用的客户端作为API composer
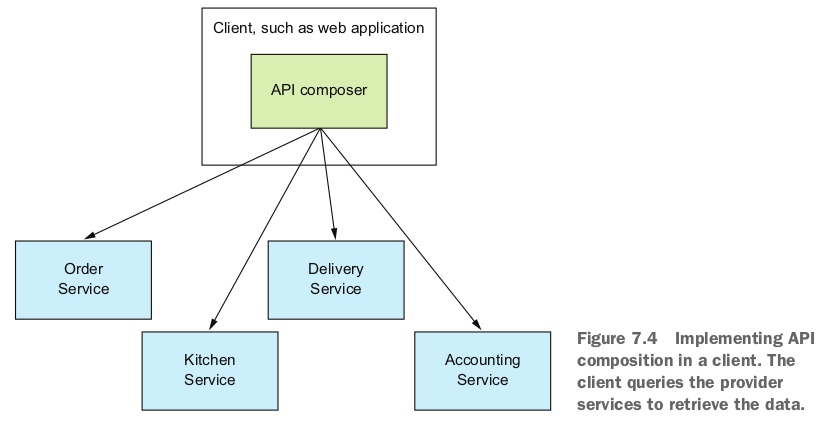
如果实现Order Status试图的客户端应用和数据服务在一个网络内,这种方式还比较高效,如果客户端和数据服务不在一个网络内,通过更慢的外部网络访问数据服务则不合适。 - API网关作为API composer,实现应用的外部API
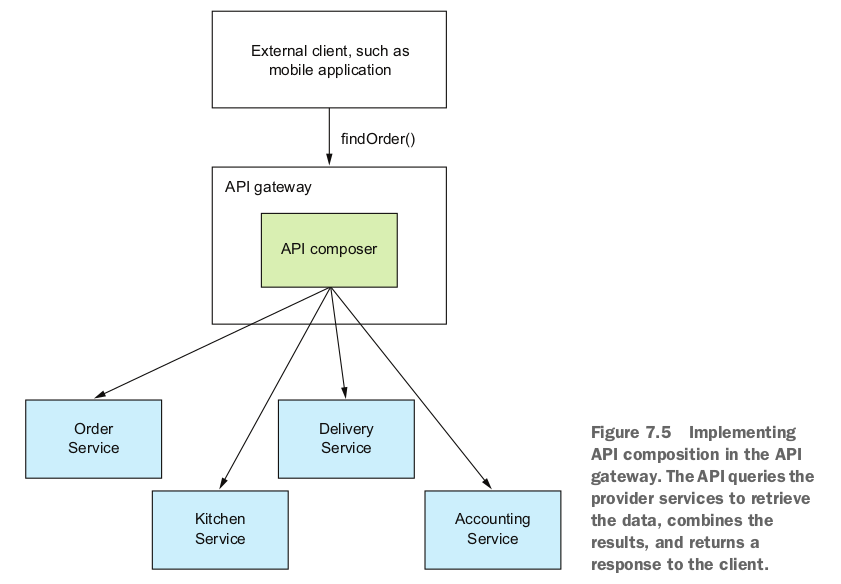
适用与外部应用高效的获取数据。 - 构建的单独的服务作为API composer
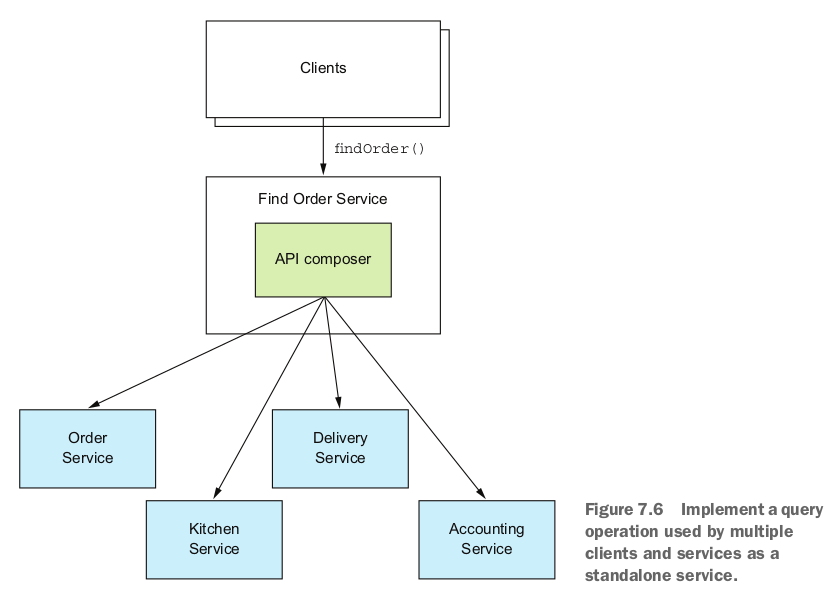
对于多个服务在内部使用的查询操作,应该使用此选项。尤其是聚合操作过于复杂,API 网关无法实现的时候。
API composer需要采用响应式编程模型
分布式系统中,最小化延迟是一个永恒的主题。API Composer在执行查询操作时,需要通过并行调用数据服务接口以最小化响应时间。
比如,上面的Find Order聚合操作就因该同时访问四个数据服务,因为这几个服务交互之间没有依赖关系。但有些时候,各个服务之间的调用存在依赖关系,就需要顺序调用。
提高服务的顺序调用和并发调用的混合执行的效率比较复杂。为了保证API composer的可维护性、性能和拓展性,需要使用响应式设计模式,比如基于Java CompletableFuture的RxJava observables。
1.5.API 组合模式的优劣
缺点:
- 增加成本
- 可用性降低
操作的可用性随着该操作涉及的服务数量增加而降低。
如果单个服务的可用性是99.5%,那么上例中的findOrder()服务的可用性是99.5% (4+1) = 97.5%。
提高可用性的操作包括:
- 使用缓存,API compser缓存数据服务返回的数据
- 返回不完整数据
- 缺乏事务数据一致性
比如,order service中订单已经取消,而kitchen service可能还未显示取消。有一些一致性可以在API composer中处理。
2.使用CQRS模式
有些应用使用Elasticsearch或者Solr这样的关系数据库管理系统(RDBMS)作为事务系统。有些应用通过同步写入保持数据库一致。还有一些从RDBMS复制数据到文本搜索引擎中。采用这些架构的应用利用了多个数据库的优势:RDBMS的事务性和文本数据库的检索能力。
命令与查询职责分离 / Command Query Responsibility Segregation:
维护一个或多个包含来自多个服务的数据的具象视图。这些视图由订阅了服务发布事件的服务维护
CQRS模式中,有专门用于应用查询的数据库。
2.1.使用CQRS的原因
以findOrderHistory为例
findOrderHistory()操作查询用户的历史订单。该操作有多个参数:
- consumerId: 用户的id
- pagination: 返回结果的页码
- filter: 过滤规则。包括返回结果最久的日期,可选的订单状态以及商家名称、购买的商品等。
这个操作会返回OrderHistory对象,OrderHistory中包含按订单日期降序排列的符合筛选规则的订单。由实现了历史订单视图的模块实现。
和findOrder()操作相比,这个操作不仅是返回多个订单这一差别。因为不是所有的服务都会存储过滤条件涉及的属性。比如按购买的商品筛选,只有Order Service和Kitchen Service存储了订单关联的购买商品,Delivery Service和Accounting Service都没有存储这一属性,所以不能按购买的商品筛选数据。
API composer模式有两种方案解决这个问题。
- 内存中组合
compser查询Deliver Service和Accounting Service中该用户的所有订单,再和Order Service和Kitchen Service的查询结果组合起来。如下图:
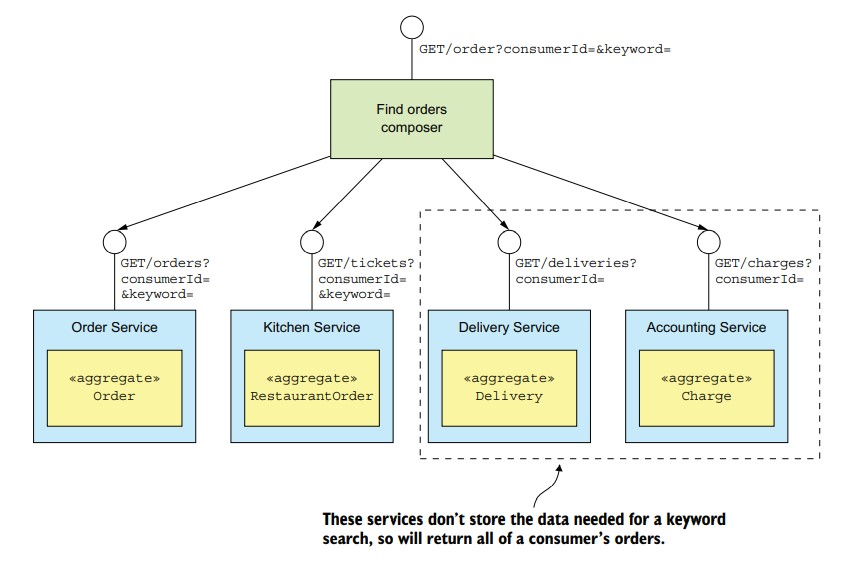
但是这种方法需要API composer查询和组合大量的数据,效率不高。 - 先查询Order Service和Kitchen Service,然后通过ID查询别的服务。但只有查询用的API支持批量操作时才有效。否则单个订单查询会产生大量的流量导致低效。
一个难以实现的本地查询操作:FindAvailableRestaurants()
除了跨服务查询会有一些问题,对单个服务做本地查询也会遇到一些问题。
假设findAvailableRestaurants()操作,查询可以在指定时间送到指定地点的餐馆。这需要做基于地理空间的查询。这个操作是订单流程的关键部分,由显示可用餐厅的UI模块调用。
假如实现findAvailableRestaurants()的应用使用的不是postgre这种支持地理拓展的数据库来存储商家信息,那它必须复制一份商家信息用于支持地理查询。复制数据就必须解决数据更新时的一致性问题。
另一个原因是,有时候存有数据的服务不一定是提供查询的服务。
findAvailableRestaurants()查询的是Restaurant Service的数据。这个服务主要是让商家能够管理自己的餐馆的信息。
服务不应该过载。开发Restaurant Service 的团队关注服务商家管理餐馆数据,和实现高容量的关键查询有很大不同。
所以 Restaurant Service仅仅向别的服务提供餐馆数据,由别的服务实现 findAvailableRestaurants()查询操作。这里可能是 Order Service。因此需要CQRS实现餐馆数据的最终一致性。
2.2.CQRS概述
CQRS把数据持久化模型和使用数据的模块分成两部分:命令侧和查询侧。如下图:
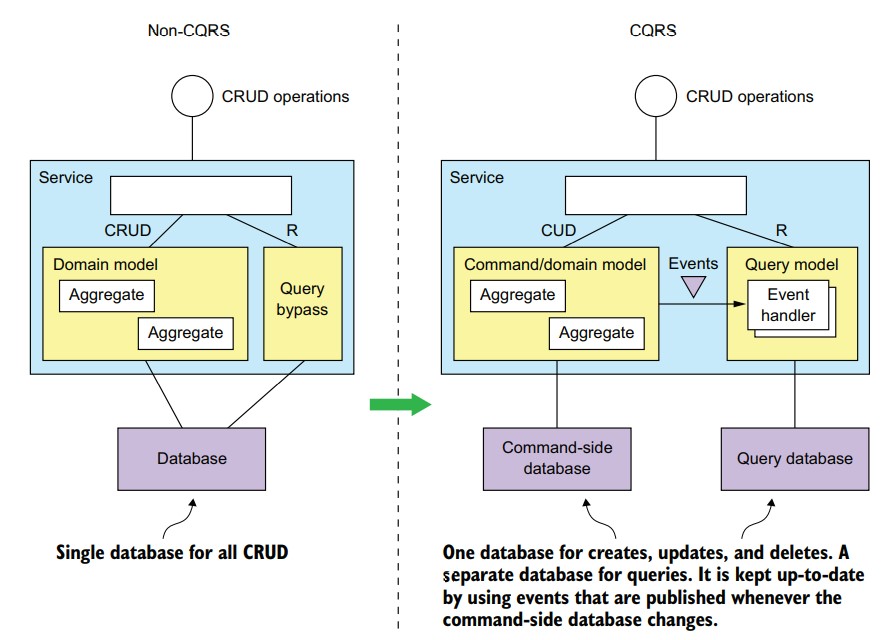
命令侧的模块和数据模型负责创建、更新和删除操作。查询侧的模块和数据模型负责查询。查询侧通过订阅命令侧发布的事件维系数据的一致性。
命令侧的数据变化时会发布域事件,可以通过Eventuate Tram框架或事件溯源。
查询侧不需要处理业务逻辑,可以使用支持查询需求的任何数据库。查询侧会有一个事件处理器,用于订阅域事件并更新数据。查询侧可能会用多个数据模型用于处理不同的查询请求。
这种服务也可以用于定义查询服务。查询侧的服务实现一个视图,这个视图订阅多个服务发布的事件。这样的视图不属于任何服务,所以作为单独的服务。如下例历史实现了findOrderHistory()查询操作的订单服务。
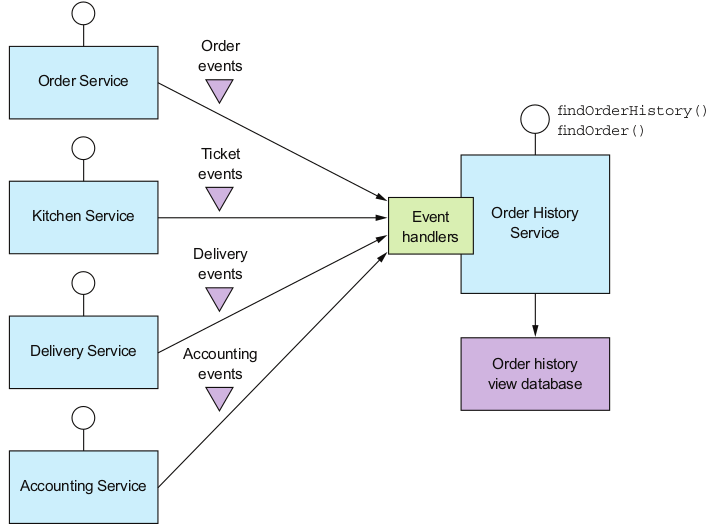
历史订单服务包含一个事件处理器,订阅其他四个命令侧服务的事件并更新历史订单视图数据库。
通过查询服务定义一个视图,专门复制另一个服务的数据也是比较好的方法,比如之前提到的Available Restaurants Service,就可以实现一个视图,提供findAvailableRestaurants()查询操作。这个服务订阅Restaurant Service的事件,并把Restaurant Service的数据同步到支持地理信息拓展的数据库中。
CQRS结构中会使用很多种数据库,并且通过订阅事件几乎可以实时同步数据。
2.3.CQRS的优点
- 实现微服务内的高效查询功能
- 实现异质化查询
- 可以查询基于事件的应用
CQRS改进了事件溯源结构的许多限制。事件存储只支持主键查询、而CQRS模式通过定地多个聚合查询的视图解决这一问题。 - 分离了服务的关注点
域模型不需要同时关心写命令和查询操作,分离了命令侧和查询侧的代码模式与数据库结构。
2.4.CQRS的缺点
- 结构复杂
查询侧服务既要有处理数据更新的视图也有查询的视图。同时还要管理多种数据存储服务。 - 需要处理复写延迟
命令侧发布事件到查询侧根据事件更新数据之间会有一段时间的延迟。会导致客户端发起更新请求后,查询的数据还是旧的。
建议优先使用API Composer,必要情况使用CQRS。
3.设计CQRS视图
CQRS试图提供一个视图,该视图包含一些列的查询操作。这些查询操作通过查询特定的数据库完成,数据库通过订阅一个或多个服务发布的事件来维护。如下图,视图模块中包含一个视图数据库(view database)和三个子模块:
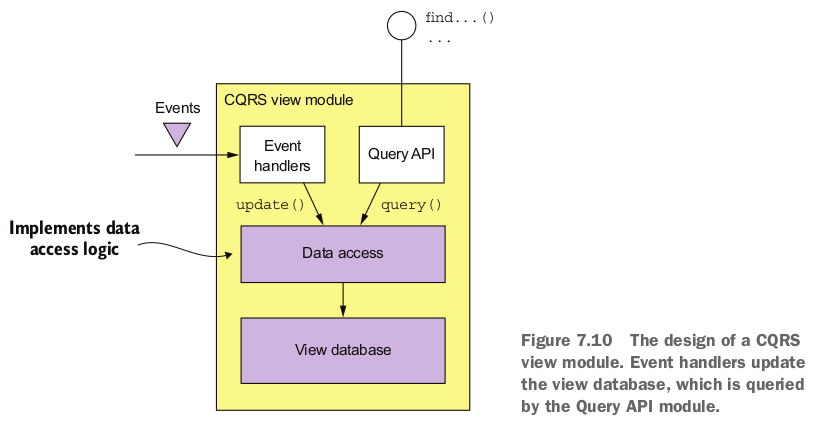
数据访问模块(data access)实现数据库的操作逻辑。事件处理器和查询操作通过数据访问模块更新和查询数据库。
所以,设计CQRS必须处理一下决策:
3.1. 选择视图的数据存储服务
选择的数据库以能够支持查询操作为主,同时要支持事件处理器快速更新数据。
| 需求 | 选择 | 例 |
|---|---|---|
| 基于主键查询JSON | 文档存储服务,比如MongoDB或DynamoDB,或者键值存储,比如Redis | 通过MongoDB存储历史订单 |
| 基于查询检索JSON对象 | 文档存储服务,比如MongoDB或DynamoDB | 使用MongoDB实现用户视图 |
| 文本查询 | 文本检索引擎,比如Elasticsearch | |
| 图检索 | 图数据库,比如Neo4j | 通过维护客户、订单和其他数据的图表来实施欺诈检测 |
| 传统SQL报表/商业智能 | RDBMS | 标准商业报表与分析 |
还需要考虑支持更新操作。通常时间处理器通过主键更新数据库。有时候需要通过外键更新数据库。假如订单和配送之间是一堆多的关系,这种情况下需要考虑有些数据库不支持非主键的更新。
3.2. 数据访问模块的设计
事件处理器和查询接口都不会直接访问数据库,而是通过数据访问模块。数据访问模块由数据访问对象(DAO)和相关辅助类组成。DAO负责映射高层级的数据类型和数据库API的数据类型。还要保证更新操作的幂等。
并发更新
如果视图订阅了多个聚合类型的事件,可能会导致同时更新同一条数据。
比如,Order时间和Delievery事件可能会同时更新一条订单记录。如果DAO在更新前先读取,那么需要引入乐观锁或悲观锁。
幂等的事件处理器
如果一个事件处理器接受了重复的事件依然可以保证结果的准确性,则是幂等的。比如,消息队列发送完DeliveryPickedUp和DeliveryDelivered事件后,由于网络波动等原因,再次发送了早期的事件:
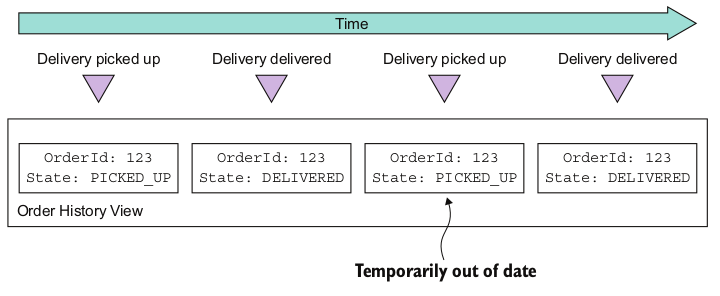
这时需要时间处理器能够根据事件ID检测到重复事件并丢弃该事件。
为了保证可靠性,时间处理器必须记录时间ID,并在更新数据库时自动更新事件ID,把视图更新和事件ID更新作为一个事务处理。
时间处理器不需要记录每一条事件的ID,因为事件ID单调递增,所以记录处理过得最大ID即可。如果记录来自多个聚合事件,那么需要维护一个[aggregate type, aggregate id] 和 max(eventId)之间的映射:
{...
"Order3949384394-039434903" : "0000015e0c6fc18f-0242ac1100e50002",
"Delivery3949384394-039434903" : "0000015e0c6fc264-0242ac1100e50002",
}
客户端应用使用最终一致性视图
命令侧和查询侧分离会导致更新不及时,可以通过一下机制让客户端检测到查询侧是否已经更新:
客户端调用命令侧更新后,命令侧返回事件id作为token,客户端携带token访问查询侧,如果还未更新该事件,则返回错误。
3.3.添加和更新CQRS视图
可能会遇到以下问题:
- 处理压缩的事件
消息中间件不可能无限期存储事件,传统的消息中间件比如RabbitMQ会在消费模块处理完事件后,将事件删除。Kafka可以配置存储一段时间的事件,但也不能无限期存储。所以新的视图需要处理压缩存储的事件,可能存在AWS S3上。处理这些事件可以用大数据技术,比如spark。 - 增量创建视图
创建视图的另一个问题是,处理所有事件所需的时间和资源会随着时间的推移而不断增长。最终,视图创建将变得缓慢且昂贵。解决方案是使用两步增量算法。第一步根据每个聚合实例以前的快照和创建快照后发生的事件定期计算该实例的快照。第二步使用快照和任何后续事件创建视图。
最后
以上就是无聊柚子最近收集整理的关于微服务中的查询的全部内容,更多相关微服务中内容请搜索靠谱客的其他文章。








发表评论 取消回复