我是靠谱客的博主 踏实花卷,这篇文章主要介绍4.3.3 Flink-流处理框架-Flink CDC数据实时数据同步-Flink CDC实操-DataStream方式1.写在前面2.相关依赖3.代码实现4.运行效果,现在分享给大家,希望可以做个参考。
目录
1.写在前面
2.相关依赖
3.代码实现
4.运行效果
1.写在前面
Flink CDC有两种实现方式,一种是DataStream方式,一种是FlinkSQL方式。
2.相关依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.7</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.7</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.7</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>3.代码实现
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 开启CK并指定状态后端为FS memory fs rocksdb
env.setStateBackend(new FsStateBackend("hdfs://192.168.0.111:9000/gmall-flink-cdc/ck"));
env.enableCheckpointing(5000L);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(10000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000);
// env.setRestartStrategy(RestartStrategies.fixedDelayRestart());
//2.通过FlinkCDC构建SourceFunction并读取数据
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("192.168.0.111")
.port(3306)
.username("root")
.password("123456")
.databaseList("gmall2021")
.tableList("gmall2021.user_info") //如果不添加该参数,则消费指定数据库中所有表的数据.如果指定,指定方式为db.table
.deserializer(new StringDebeziumDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
//3.打印数据
streamSource.print();
//4.启动任务
env.execute("FlinkCDC");
}
}
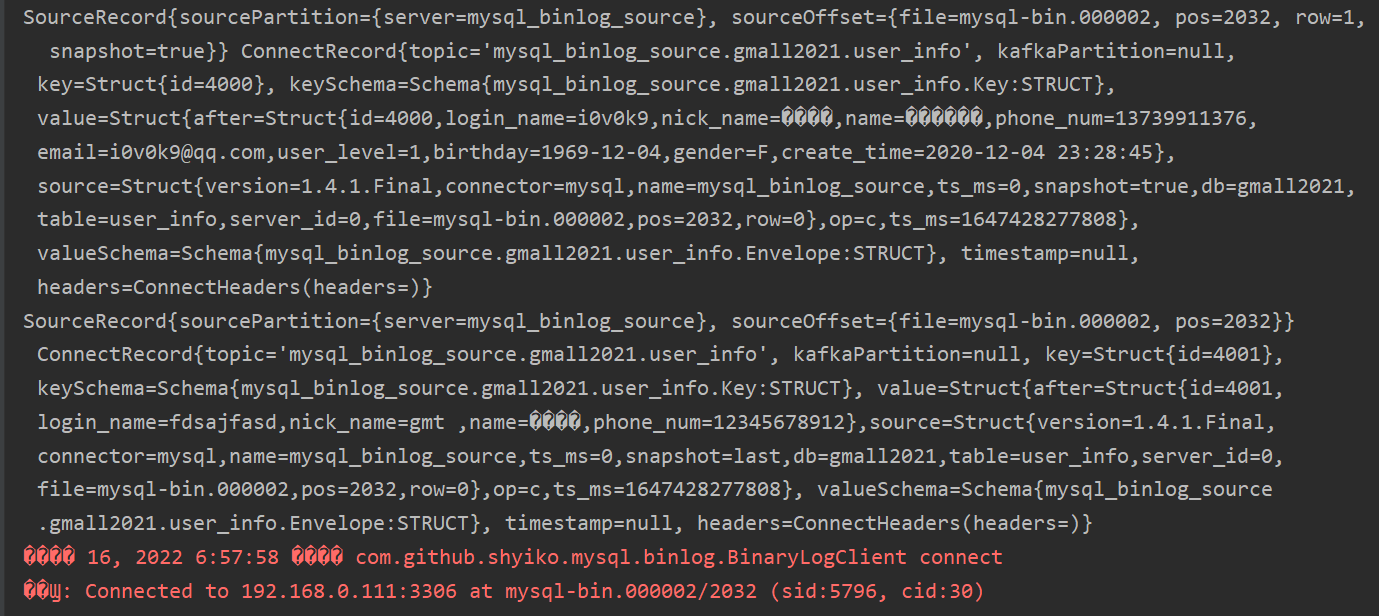
4.运行效果
最后
以上就是踏实花卷最近收集整理的关于4.3.3 Flink-流处理框架-Flink CDC数据实时数据同步-Flink CDC实操-DataStream方式1.写在前面2.相关依赖3.代码实现4.运行效果的全部内容,更多相关4.3.3内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复