简介
debezium在debezium关于cdc的使用(上)中有做介绍。具体可以跳到上文查看。本篇主要讲述使用kafka connector方式来同步数据。而kafka connector实际上也有提供其他的sink(Kafka Connect JDBC)来同步数据,但是没有delete事件。所以在这里选择了Debezium MySQL CDC Connector方式来同步。本文需要使用Avro方式序列化kafka数据。
流程
第一步准备
使用kafka消息中间介的话需要对应的服务支持,尤其需要chema-registry来管理schema,因电脑内存有限就没使用docker方式启动,如果条件ok内存够大的话阔以使用docker方式。所以使用的就是local本地方式。具体下载,安装,部署,配置环境变量我就不在重复描述了,阔以参考官方文档。
第二步启动kafka配套
进入目录后启动bin/confluent start

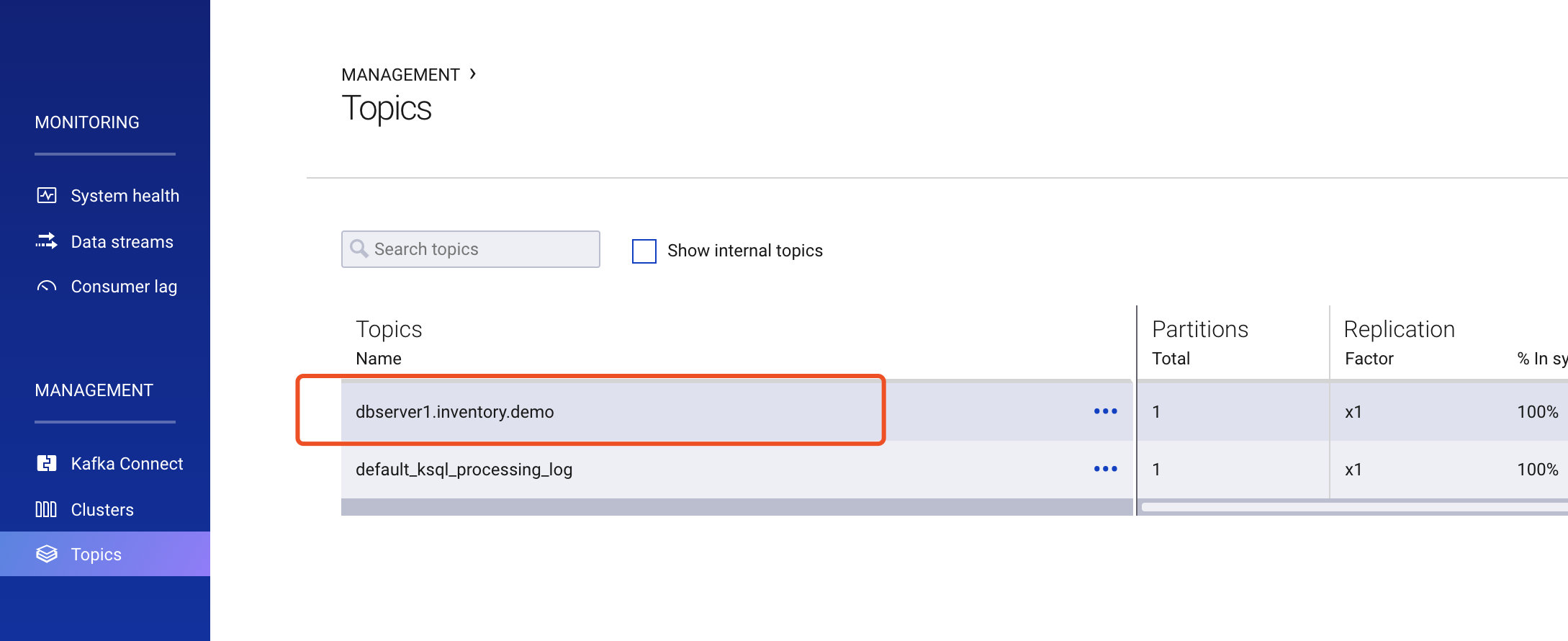
第三步创建kafka topic
可以通过kafka命令创建topic也可以通过Confluent Control Center 地址:http://localhost:9021来创建topic。我们还是按照上文的表来同步数据,所以创建topic:dbserver1.inventory.demo。
第四步创建kafka connect
可以通过kafka rest命令创建也可以使用Confluent Control Center创建。
方便点可以使用crul创建,以下为配置文件
{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "localhost",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.whitelist": "inventory",
"decimal.handling.mode": "double",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://localhost:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://localhost:8081",
"database.history.kafka.bootstrap.servers": "localhost:9092",
"database.history.kafka.topic": "dbhistory.inventory"
}
}
创建好后可以使用命令查询到或者在管理中心查看。

第五步启动同步程序
配置
spring:
application:
name: data-center
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/inventory_back?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
username: debe
password: 123456
jpa:
show-sql: true
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
# time-zone: UTC
kafka:
bootstrap-servers: localhost:9092
consumer:
group-id: debezium-kafka-connector
key-deserializer: "io.confluent.kafka.serializers.KafkaAvroDeserializer"
value-deserializer: "io.confluent.kafka.serializers.KafkaAvroDeserializer"
properties:
schema.registry.url: http://localhost:8081
kafka消费者
跟上文的处理流程是一样的。只不过DDL和DML分成2个监听器。
package com.example.kakfa.avro;
import com.example.kakfa.avro.sql.SqlProvider;
import com.example.kakfa.avro.sql.SqlProviderFactory;
import io.debezium.data.Envelope;
import lombok.extern.slf4j.Slf4j;
import org.apache.avro.generic.GenericData;
import org.apache.commons.lang3.StringUtils;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.util.Objects;
import java.util.Optional;
@Slf4j
@Component
public class KafkaAvroConsumerRunner {
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private NamedParameterJdbcTemplate namedTemplate;
@KafkaListener(id = "dbserver1-ddl-consumer", topics = "dbserver1")
public void listenerUser(ConsumerRecord record) throws Exception {
GenericData.Record key = record.key();
GenericData.Record value = record.value();
log.info("Received record: {}", record);
log.info("Received record: key {}", key);
log.info("Received record: value {}", value);
String databaseName = Optional.ofNullable(value.get("databaseName")).map(Object::toString).orElse(null);
String ddl = Optional.ofNullable(value.get("ddl")).map(Object::toString).orElse(null);
if (StringUtils.isBlank(ddl)) {
return;
}
handleDDL(ddl, databaseName);
}
/**
* 执行数据库ddl语句
*
* @param ddl
*/
private void handleDDL(String ddl, String db) {
log.info("ddl语句 : {}", ddl);
try {
if (StringUtils.isNotBlank(db)) {
ddl = ddl.replace(db + ".", "");
ddl = ddl.replace("`" + db + "`.", "");
}
jdbcTemplate.execute(ddl);
} catch (Exception e) {
log.error("数据库操作DDL语句失败,", e);
}
}
@KafkaListener(id = "dbserver1-dml-consumer", topicPattern = "dbserver1.inventory.*")
public void listenerAvro(ConsumerRecord record) throws Exception {
GenericData.Record key = record.key();
GenericData.Record value = record.value();
log.info("Received record: {}", record);
log.info("Received record: key {}", key);
log.info("Received record: value {}", value);
if (Objects.isNull(value)) {
return;
}
GenericData.Record source = (GenericData.Record) value.get("source");
String table = source.get("table").toString();
Envelope.Operation operation = Envelope.Operation.forCode(value.get("op").toString());
String db = source.get("db").toString();
handleDML(key, value, table, operation);
}
private void handleDML(GenericData.Record key, GenericData.Record value,
String table, Envelope.Operation operation) {
SqlProvider provider = SqlProviderFactory.getProvider(operation);
if (Objects.isNull(provider)) {
log.error("没有找到sql处理器提供者.");
return;
}
String sql = provider.getSql(key, value, table);
if (StringUtils.isBlank(sql)) {
log.error("找不到sql.");
return;
}
try {
log.info("dml语句 : {}", sql);
namedTemplate.update(sql, provider.getSqlParameterMap());
} catch (Exception e) {
log.error("数据库DML操作失败,", e);
}
}
}
数据流程
剩下的就是在inventory库中demo表中增删改数据,在对应的inventory_back库中demo表数据对应的改变。
欢迎关注微信公众号

最后
以上就是火星上乌龟最近收集整理的关于kafka mysql cdc_debezium关于cdc的使用(下)的全部内容,更多相关kafka内容请搜索靠谱客的其他文章。








发表评论 取消回复