文章目录
- 一、品牌统计
- 二、规格统计
- 三、分类和品牌过滤
- 四、规格过滤
- 五、价格区间查询
- 六、分页实现
- 七、搜索排序
- 八、高亮搜索
- 九、代码优化:分组合并搜索
- 十、总结
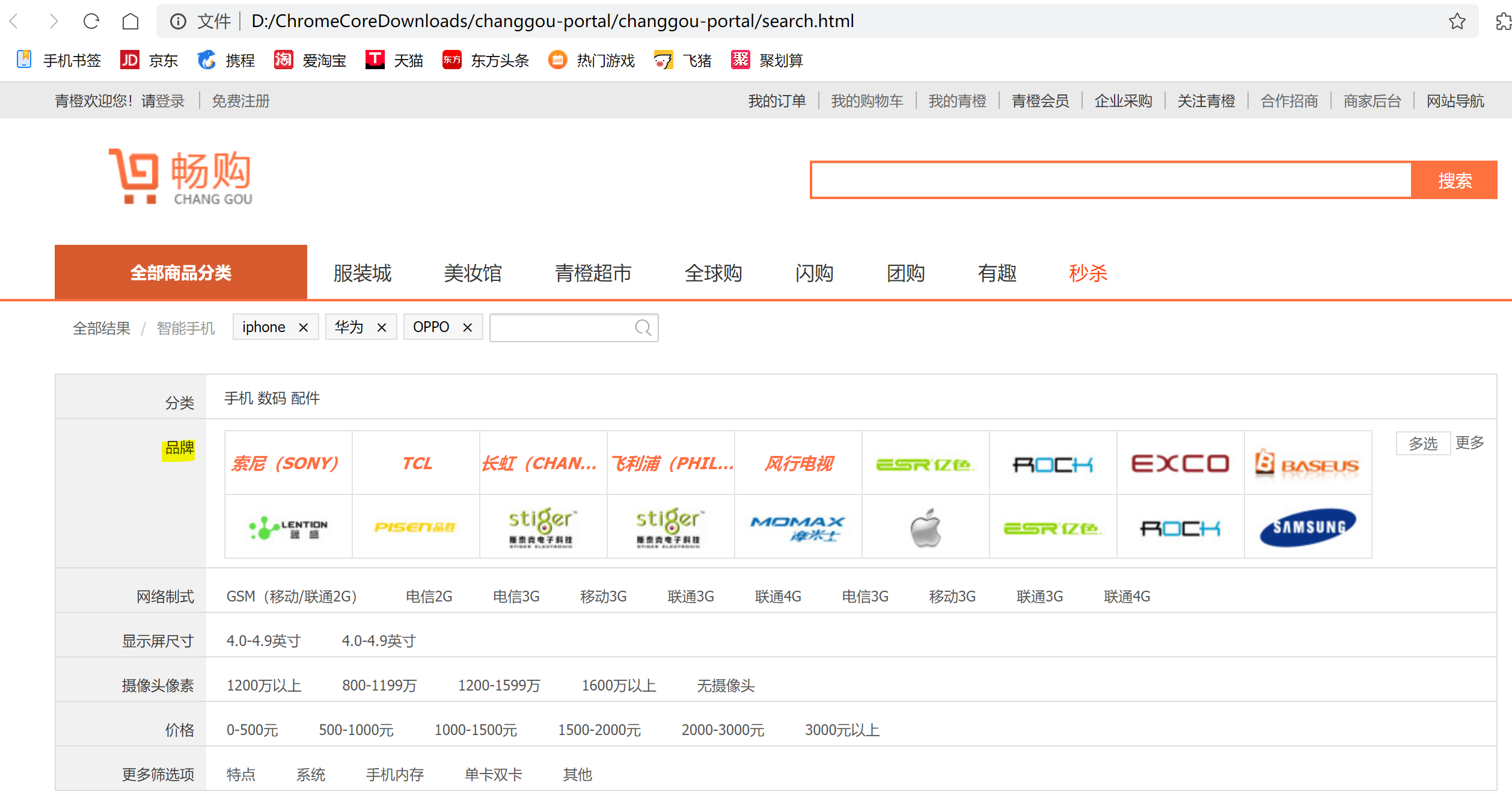
可以看到,在前端页面中,我们在上篇实现了按照 “分类” 进行分组,接下来需要按照 “品牌” 进行分组,展示用户选中的品牌对应的商品。
一、品牌统计
如果是写 SQL 语句,在执行搜索的时候,第 1 条 SQL 语句是执行根据关键字搜索,第 2 条语句 是 根据 品牌名字 分组:
-- 查询所有
SELECT * FROM tb_sku WHERE name LIKE '%手机%';
-- 根据品牌名字分组查询
SELECT brand_name FROM tb_sku WHERE name LIKE '%手机%' GROUP BY brand_name;
每次执行搜索的时候,需要显示商品品牌名称,这里要显示的品牌名称,其实就是符合搜素条件的所有商品的品牌集合,所以我们可以按照上面的实现思路,使用Elasticsearch ,先根据关键字搜索,再根据分组名称做一次分组查询即可。
先把上篇中根据分类名称进行分组查询的代码抽取出来:
public List<String> searchCategoryList(NativeSearchQueryBuilder nativeSearchQueryBuilder) {
// 分组查询分类集合
// addAggregation 添加聚合操作
// 第一个参数需要传入分组的依据,即 根据哪个域进行分组
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("skuCategory").field("categoryName"));
AggregatedPage<SkuInfo> aggregatedPage = elasticsearchTemplate.queryForPage(nativeSearchQueryBuilder.build(), SkuInfo.class);
// 可以根据多个域进行分组。
// 获取指定域的集合数据 {手机,电脑,电视}
StringTerms stringTerms = aggregatedPage.getAggregations().get("skuCategory");
List<String> categoryList = new ArrayList<String>();
for (StringTerms.Bucket bucket : stringTerms.getBuckets()) {
// 获取其中一个分类名称,比如 手机 或者 电脑 或者 电视
String categoryName = bucket.getKeyAsString();
categoryList.add(categoryName);
}
return categoryList;
}
仿照这个,我们来写根据品牌名称分组:
public List<String> searchBrandList(NativeSearchQueryBuilder nativeSearchQueryBuilder) {
// 分组查询品牌集合
// addAggregation 添加聚合操作
// 第一个参数需要传入分组的依据,即 根据哪个域进行分组
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("skuBrand").field("brandName"));
AggregatedPage<SkuInfo> aggregatedPage = elasticsearchTemplate.queryForPage(nativeSearchQueryBuilder.build(), SkuInfo.class);
// 可以根据多个域进行分组。
// 获取指定域的集合数据 {TCL,海尔,华为}
StringTerms stringTerms = aggregatedPage.getAggregations().get("skuBrand");
List<String> brandList = new ArrayList<String>();
for (StringTerms.Bucket bucket : stringTerms.getBuckets()) {
// 获取其中一个分类名称,比如 TCL 或者 海尔 或者 华为
String brandName = bucket.getKeyAsString();
brandList.add(brandName);
}
return brandList;
}
进行代码优化,把 搜索条件 和 集合搜索 的逻辑进行封装:
/**
* 搜索条件封装
*
* @param searchMap
* @return
*/
public NativeSearchQueryBuilder builderBasicQuery(Map<String, String> searchMap) {
// 构建搜索条件对象
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
if (searchMap != null && searchMap.size() > 0) {
// 根据关键词搜索
String keyWords = searchMap.get("keywords");
if (!StringUtils.isEmpty(keyWords)) {
builder.withQuery(
QueryBuilders.queryStringQuery(keyWords).field("name"));
}
}
return builder;
}
/**
* 集合搜索封装
*
* @param builder
* @return
*/
public Map<String, Object> searchlist(NativeSearchQueryBuilder builder) {
// 第二个参数需要传入 搜索的结果类型(页面展示的是集合数据)
// AggregatedPage<SkuInfo> 是对结果集的封装
AggregatedPage<SkuInfo> page = elasticsearchTemplate.queryForPage(
builder.build(), SkuInfo.class);
// 获取数据结果集
List<SkuInfo> contents = page.getContent();
// 获取总记录数
long totalNums = page.getTotalElements();
// 获取总页数
int totalPages = page.getTotalPages();
// 封装 Map 存储数据作为结果
Map<String, Object> resultMap = new HashMap<String, Object>();
resultMap.put("rows", contents);
resultMap.put("totalNums", totalNums);
resultMap.put("totalPages", totalPages);
return resultMap;
}
这样,根据关键字、分类、品牌名称进行搜索的代码变成了:
@Override
public Map<String, Object> search(Map<String, String> searchMap) {
// 构建搜索条件对象
NativeSearchQueryBuilder builder = builderBasicQuery(searchMap);
// 集合搜索
Map<String, Object> resultMap = searchlist(builder);
// 根据分类进行分组查询
List<String> categoryList = searchCategoryList(builder);
// 根据品牌名称进行分组查询
List<String> brandList = searchBrandList(builder);
resultMap.put("category", categoryList);
resultMap.put("brand", brandList);
return resultMap;
}
运行结果:
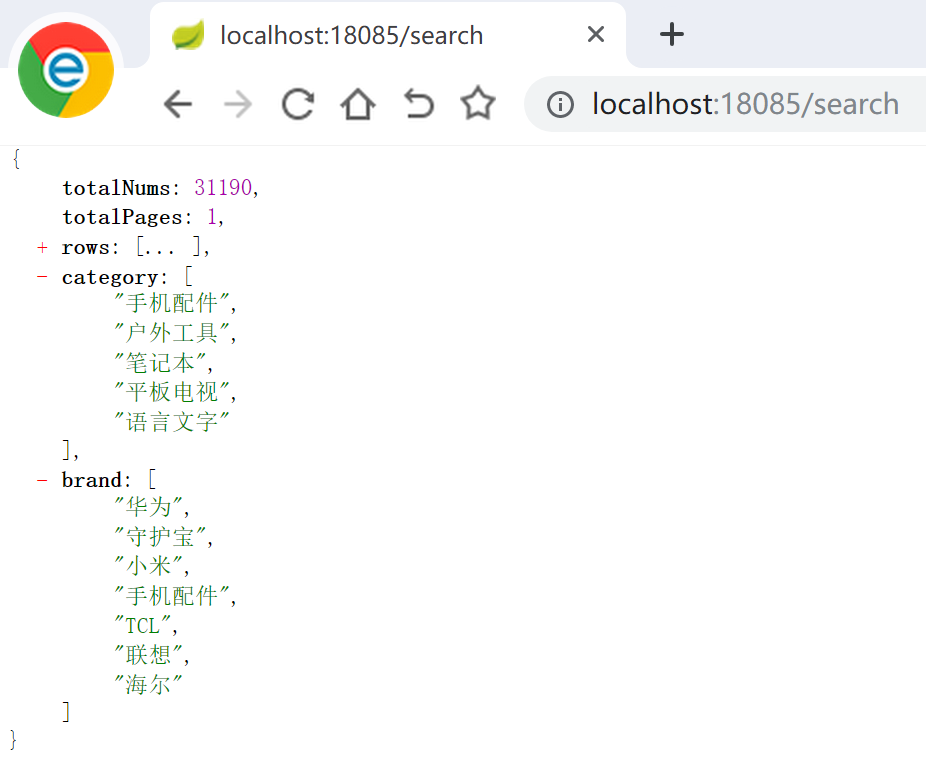
二、规格统计

可以看到,用户搜索的时候,除了使用分类、品牌搜索外,还有可能使用规格搜索,在前端页面中,展示出来的规格是 Map 形式,key 是 String 类型的 规格名称,就像之前实现过的 specMap 中的 “电视音响效果”、“电视屏幕尺寸”… … 而 value 是 Set 类型的规格的值,是不能重复 的。
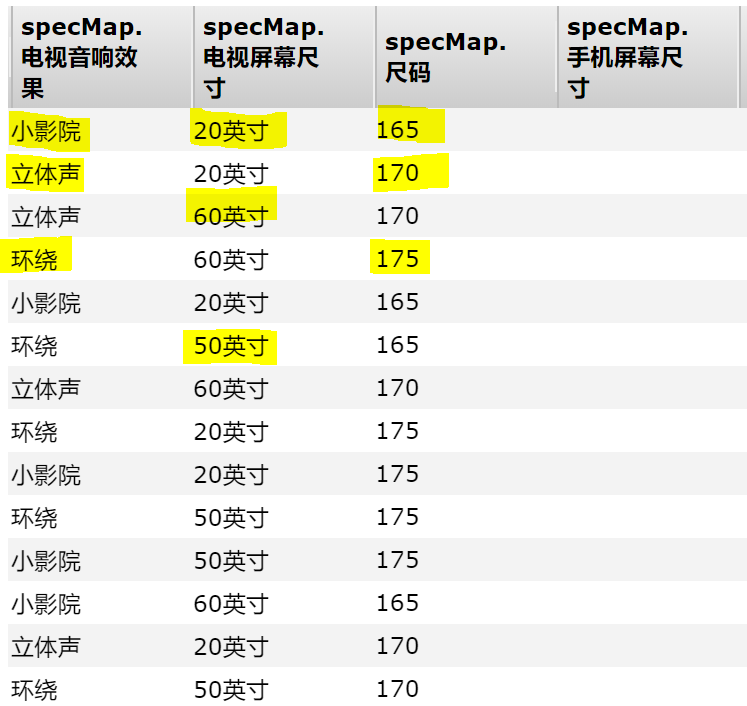
规格数据的显示实现,相比之前分类 和 品牌 的实现略微较难一些,需要对数据进行处理:
public Map<String, Set<String>> searchSpecList(NativeSearchQueryBuilder nativeSearchQueryBuilder) {
// 使用 spec.keyword 表示不分词
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("skuSpec").field("spec.keyword"));
AggregatedPage<SkuInfo> aggregatedPage = elasticsearchTemplate.queryForPage(nativeSearchQueryBuilder.build(),
SkuInfo.class);
// 按照规格进行分类查询
// 其实相当于对 spec 进行去重,可以提高后续对它的 value 去重的效率
StringTerms stringTerms = aggregatedPage.getAggregations().get("skuSpec");
List<String> specList = new ArrayList<String>();
for (StringTerms.Bucket bucket : stringTerms.getBuckets()) {
String specName = bucket.getKeyAsString();
specList.add(specName);
}
Map<String, Set<String>> allSpec = new HashMap<String, Set<String>>();
// 遍历 specList
for (String spec : specList) {
// 将 List 先转化成 Map
Map<String, String> specMap = JSON.parseObject(spec, Map.class);
// 再将 Map 转化成 Map<String,Set<String>>,key 不变,需要把 value 添加到 Set 中
for (Map.Entry<String, String> entry : specMap.entrySet()) {
String entryKey = entry.getKey();
if (allSpec.get(entryKey) == null) {
Set set = new HashSet<>();
set.add(entry.getValue());
allSpec.put(entryKey, set);
} else {
allSpec.get(entryKey).add(entry.getValue());
}
}
}
return allSpec;
}
运行结果:

注意,需要使用 .size 参数,搜索更多的记录,size 是分页时,每页的条数:
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("skuSpec").field("spec.keyword").size(10000));
运行结果:

三、分类和品牌过滤
现在需要考虑使用情况对代码进行优化。比如说,用户已经输入了 比如说 分类、品牌 的条件,这时前端会获取到这些参数,访问路径对应的后端代码中,就没必要再根据 分类、品牌进行分组查询了,(因为这个分组查询本身就是为了展示给用户,供用户选择的)只需要根据条件进行搜索。
???? 代码:
// 如果用户没有输入条件 或者 没有输入分类条件
if (searchMap == null|| searchMap.get("category") == null) {
// 根据分类进行分组查询
List<String> categoryList = searchCategoryList(builder);
resultMap.put("category", categoryList);
}
// 如果用户没有输入品牌 或者 没有输入品牌条件
if (searchMap == null|| searchMap.get("brand") == null) {
// 根据品牌名称进行分组查询
List<String> brandList = searchBrandList(builder);
resultMap.put("brand", brandList);
}
而且还需要根据用户选择的分类 和 品牌,获取相应的内容。
修改构建搜索添加的方法:
public NativeSearchQueryBuilder builderBasicQuery(Map<String, String> searchMap) {
// 构建搜索条件对象
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if (searchMap != null && searchMap.size() > 0) {
// 根据关键词搜索
String keyWords = searchMap.get("keywords");
String category = searchMap.get("category");
String brand = searchMap.get("brand");
if (!StringUtils.isEmpty(keyWords)) {
//builder.withQuery(
//QueryBuilders.queryStringQuery(keyWords).field("name"));
// 如果关键词不为空,根据关键词在 name 域进行搜索
boolQueryBuilder.must(QueryBuilders.queryStringQuery(keyWords).field("name"));
}
// 如果分类不为空
if (!StringUtils.isEmpty(category)) {
// 不需要分词
boolQueryBuilder.must(QueryBuilders.termQuery("categoryName", category));
}
// 如果品牌不为空
if (!StringUtils.isEmpty(brand)) {
// 不需要分词
boolQueryBuilder.must(QueryBuilders.termQuery("brandName", brand));
}
}
// 将 BoolQueryBuilder 对象填充给 NativeSearchQueryBuilder
builder.withQuery(boolQueryBuilder);
return builder;
}
运行结果:
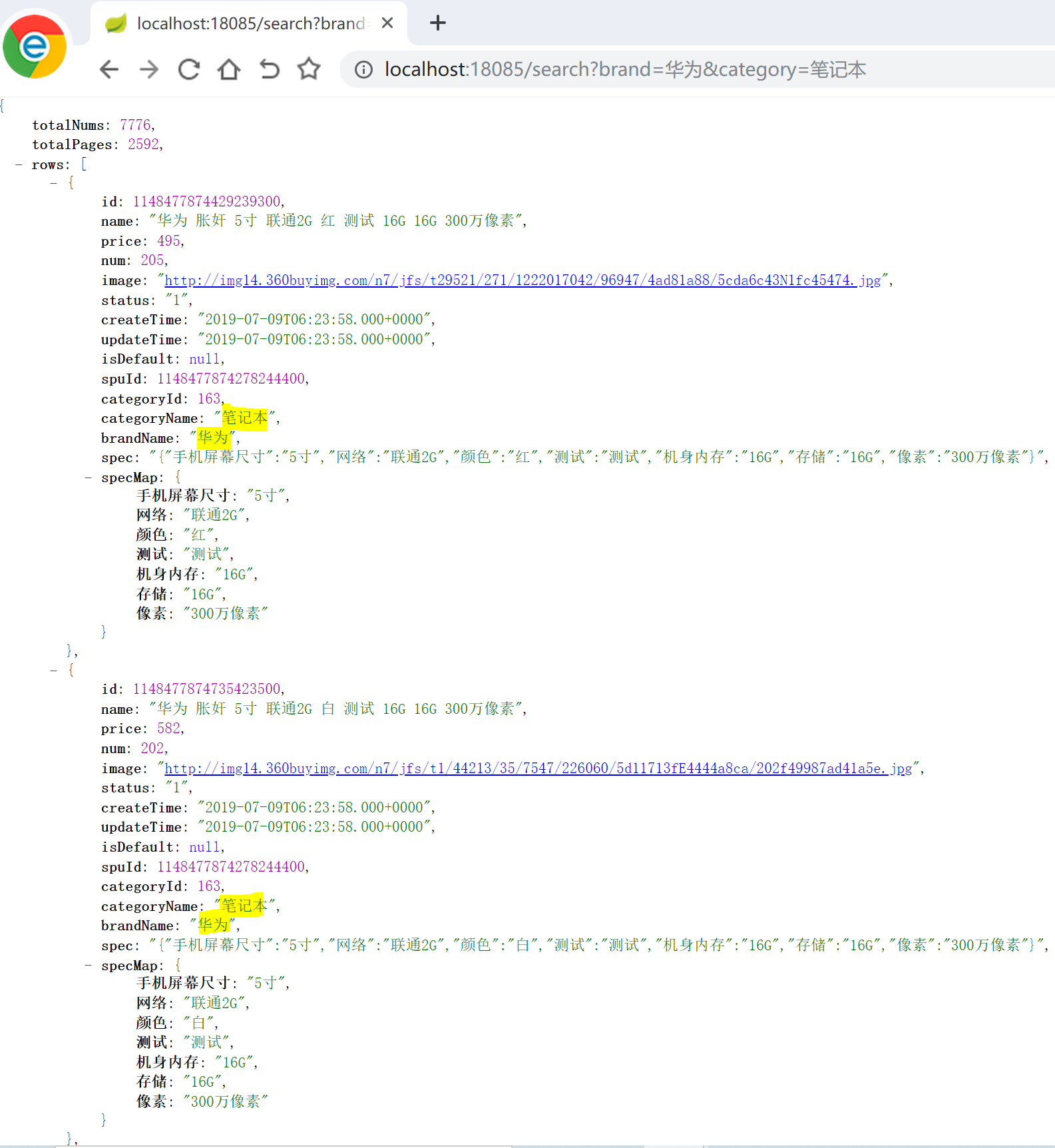
四、规格过滤
根据用户输入的规格参数进行查询:
for(Map.Entry<String,String> entry:searchMap.entrySet()){
String key=entry.getKey();
// 如果 key 前缀是 spec_,说明需要根据规格过滤
if (key.startsWith("spec_")) {
String value=entry.getValue();
// 不需要分词
// 比如传入 spec_像素,在索引库里,域是 specMap.像素
boolQueryBuilder.must(QueryBuilders.termQuery("specMap."+key.substring(5)+".keyword", value));
}
}
运行结果:
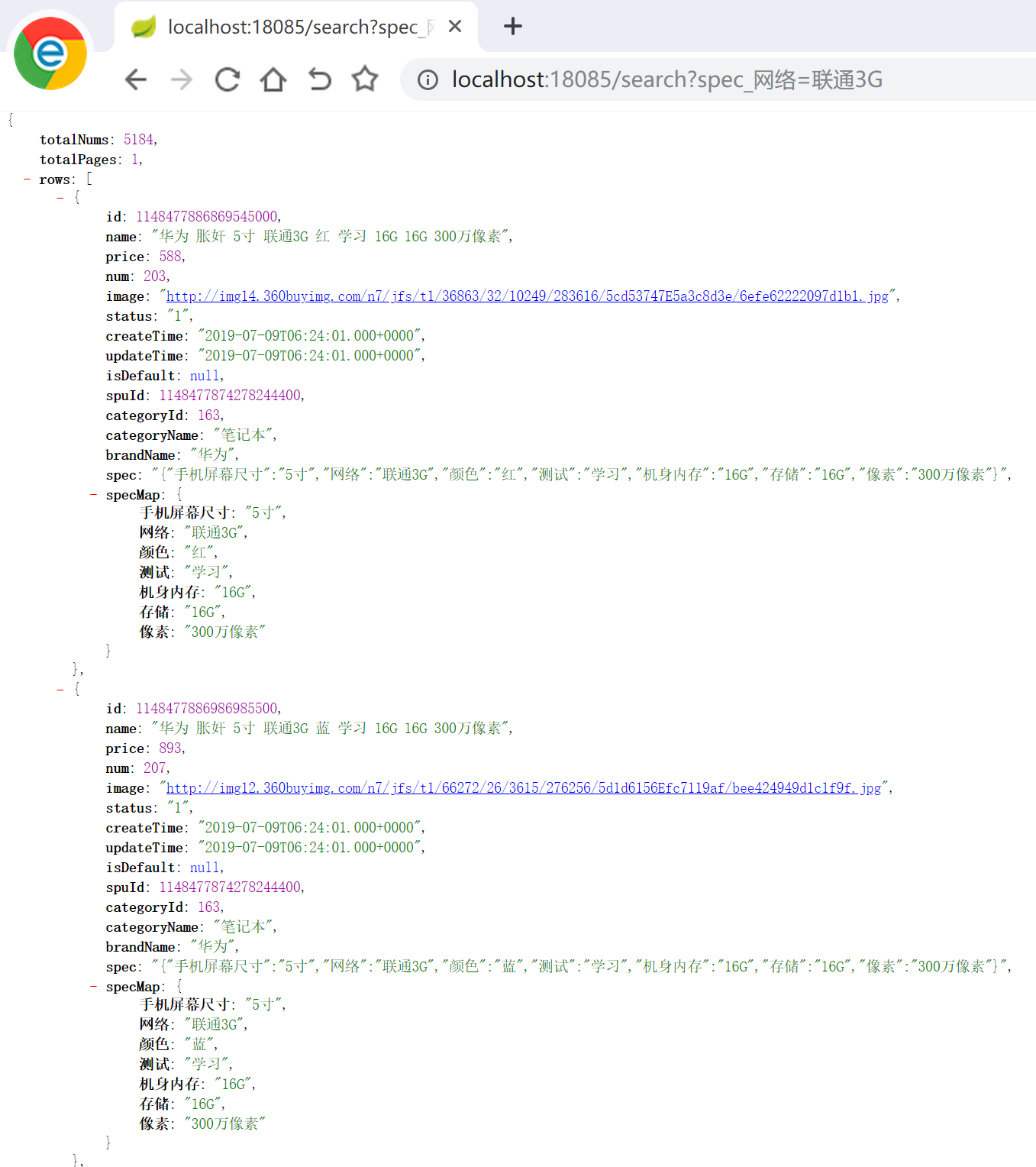
同样地,如果用户没有输入规格参数,就需要展示整个规格参数列表;但是如果用户输入了某一个参数,比如 spec_网络=联通 3G,应该展示不包含 “spec_网络” 的 规格参数列表。
实现这个功能,可以改后端代码(见 github),我的思路是,遍历传入的参数,当遇到 spec_ 开头的,比如说 “网络”,执行一次聚合查询,获取到整个 spec 的列表,在把 List 形式 的 spec 转化成 Map 的 putAllSpec 方法里,遍历 List,把每个字符串转化成 Map,然后对 Map 进行判断,如果取出来的 key 是 “网络”,就不作为最终的 Map 的 key,这样的话,最后的 Map 里就没有 “网络” 啦。但是这样写,每次获取到 spec_ 开头的参数时,都需要执行一次分组查询,效率很低。
考虑改前端代码(见下一篇),也就是说,如果没有输入以 _spec 开头的参数时,查出整个规格列表,但是不显示传入参数对应的值。
五、价格区间查询
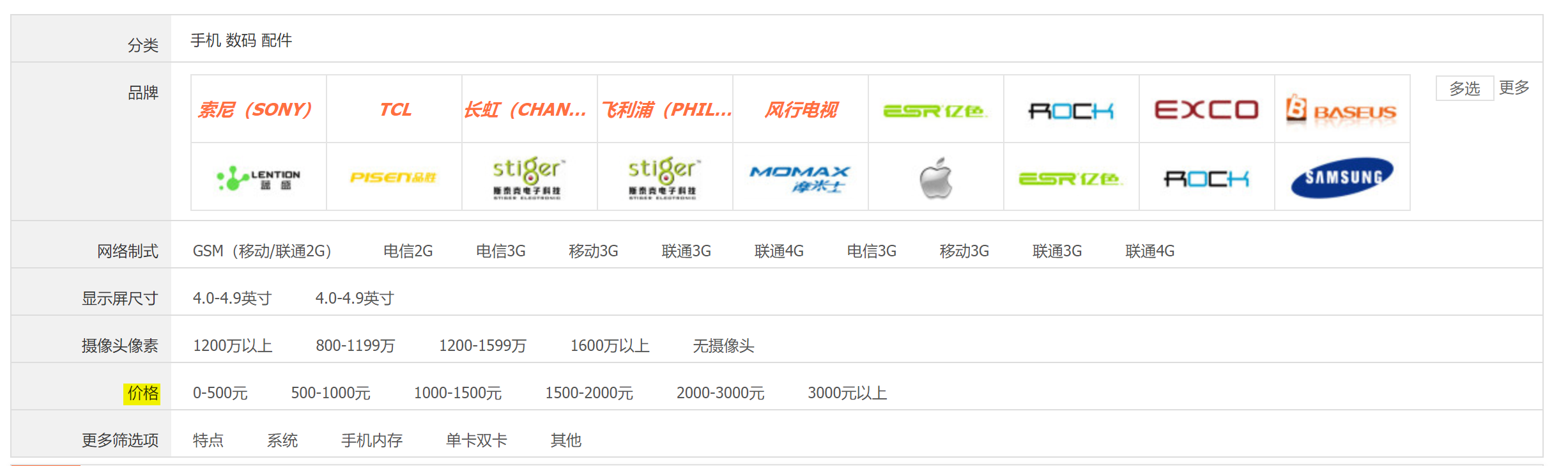
用户可以输入价格区间进行查询,可以看到,前端的数据格式是 0-500元 、500-1000元 、1000-1500元、1500-2000元、2000-3000元 、3000元以上, 后端代码需要先去掉中文 “元” 和 “以上”,然后根据 “-” 进行分割,作为查询条件。
???? 代码如下:
String price = searchMap.get("price");
if (!StringUtils.isEmpty(price)) {
// 需要去掉 "元" 和 “以上” 变成 0-500 500-1000 1000-1500 1500-2000 2000-3000 3000
price = price.replace("元", "").replace("以上", "");
// 需要根据 “-” 进行分割 [0,500] [500,1000] ... ... [3000]
String[] prices = price.split("-");
if (prices != null && prices.length > 0) {
// price[0]!=null price>price[0]
if (prices.length == 1) {
boolQueryBuilder.must(QueryBuilders.rangeQuery("price").gt(Integer.parseInt(prices[0])));
} else {
// price[1]!=null price<=price[1]
boolQueryBuilder.must(QueryBuilders.rangeQuery("price").lte(Integer.parseInt(prices[1])));
}
}
// 将 BoolQueryBuilder 对象填充给 NativeSearchQueryBuilder
builder.withQuery(boolQueryBuilder);
}
return builder;
}
运行结果:

六、分页实现
页面需要实现分页搜索,所以后台每次查询的时候,需要实现分页。用户页面每次会传入当前页和每页查询多少条数据,当然如果不传入每页显示多少条数据,默认查询 30 条即可。
分页使用 PageRequest.of( pageNo- 1, pageSize); 实现,第 1 个参数表示第 N 页,从 0 开始,第 2 个参数表示每页显示多少条,实现代码如下,写在封装搜索条件的方法 builderBasicQuery 中:
// 实现分页,如果用户没有传入分页参数,默认 第 1 页
Integer pageNum = coverterPage(searchMap);
// 默认每页显示 3 条数据
Integer size = 3;
builder.withPageable(PageRequest.of(pageNum - 1, size));
/**
* 接受前端分页参数 页码、每页数据条数
*
* @param searchMap
* @return
*/
public Integer coverterPage(Map<String, String> searchMap) {
if (searchMap != null) {
String pageNum = searchMap.get("pageNum");
Integer pageNum1 = Integer.parseInt(pageNum);
if (pageNum1 >= 1) {
return pageNum1;
}
}
return 1;
}
运行结果:

可以看到,实现了分页查询,默认每页显示 3 条数据。
七、搜索排序

排序可以根据综合(广告费交得越多排在越前面)、销量、评价、新品(上架时间)、价格等排序,只需要告知排序的域,以及排序方式,即可实现排序。
- 销量排序:除了销售数量外,还应该 要有时间段限制 (比如 某月、某季度)。
- 新品排序:直接根据商品的发布时间或者更新时间排序(“新” 品,“新” 品,只需要按照发布或更新时间降序排列即可)。
- 评价排序:评价分为好评、中评、差评,可以在数据库中设计 3 个列,用来记录好评、中评、差评的量,每次排序的时候,根据好评的比例来排序,当然还要有条数限制,评价条数需要超过 N 条。
- 价格排序:只需要根据价格高低排序即可,降序价格高 -> 低,升序价格低 -> 高
我们先不针对某个功能实现排序,只需要在后台接收 2 个参数,分别是排序域名字和排序方式:
// 指定排序的域
String sortField = searchMap.get("sortField");
// 指定排序规则
String sortRule = searchMap.get("sortRule");
if (!StringUtils.isEmpty(sortField) && !StringUtils.isEmpty(sortRule)) {
builder.withSort(new FieldSortBuilder(sortField).order(SortOrder.valueOf(sortRule)));
}
运行结果:
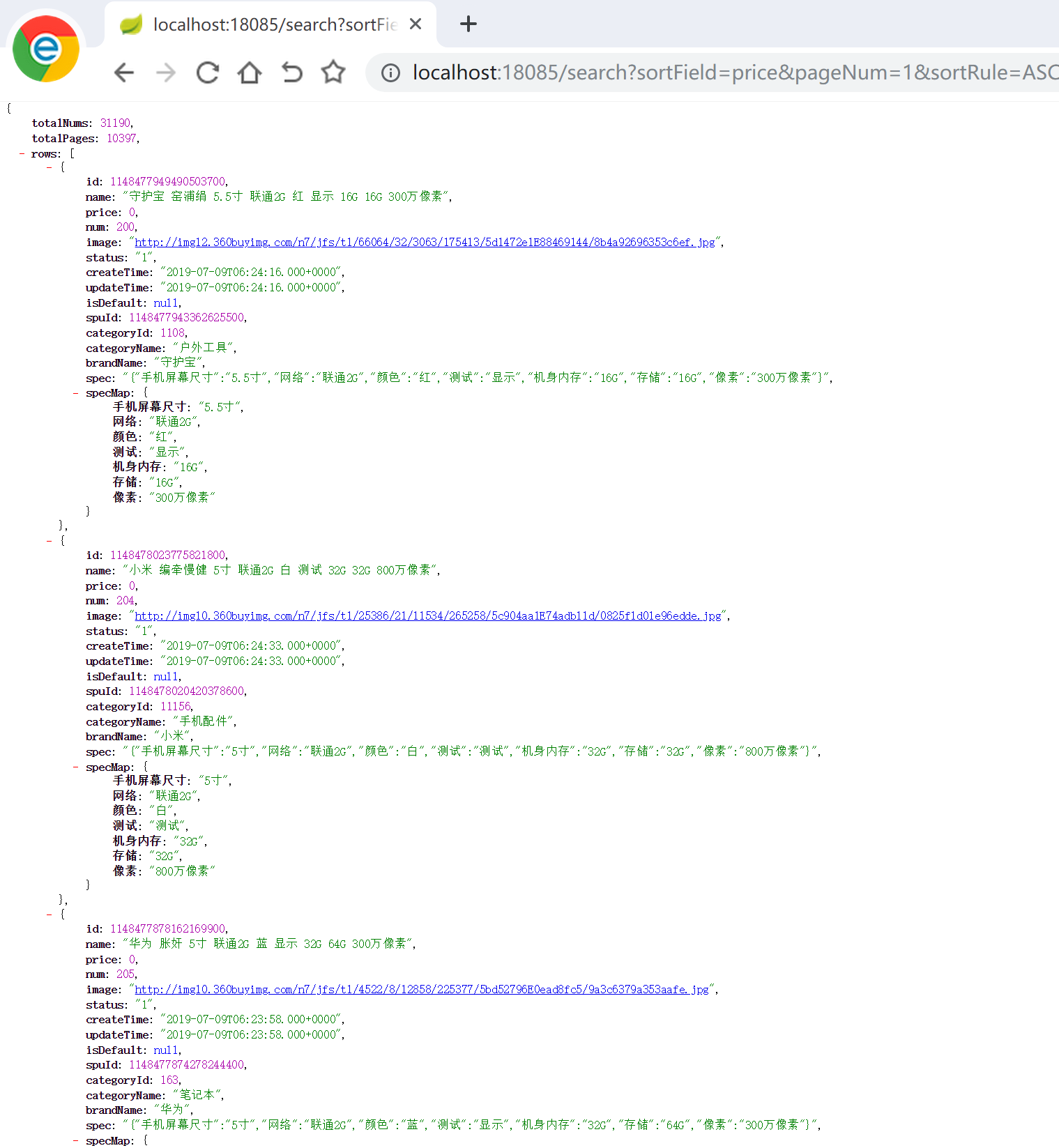
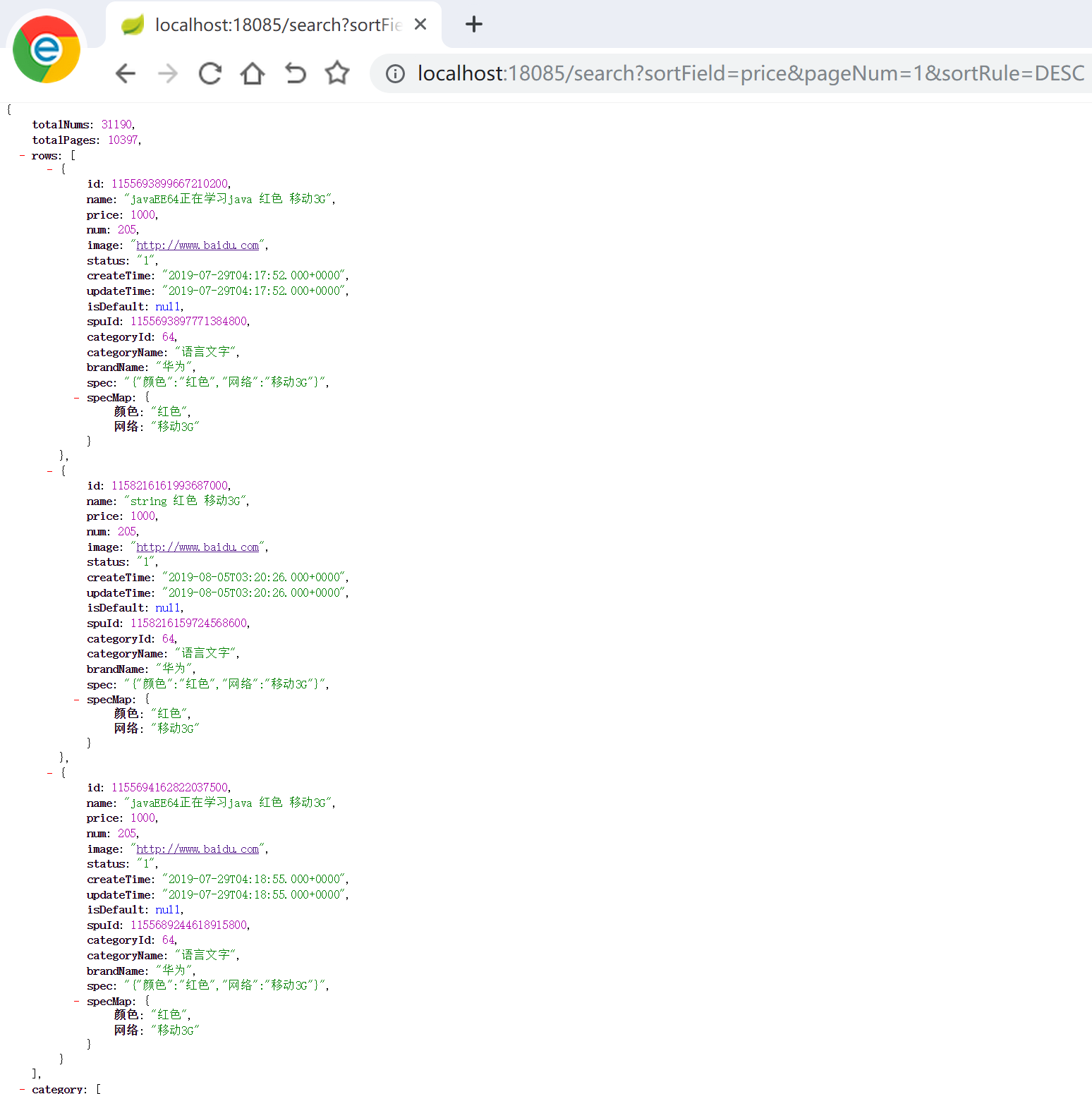
可以看到,实现了按照价格进行排序的效果,注意,输入升序 ASC 和 降序 DESC 字母必须是大写的。
八、高亮搜索
高亮显示 是指 根据商品关键字搜索商品的时候,显示的页面对关键字给定了特殊样式,让它显示更加突出。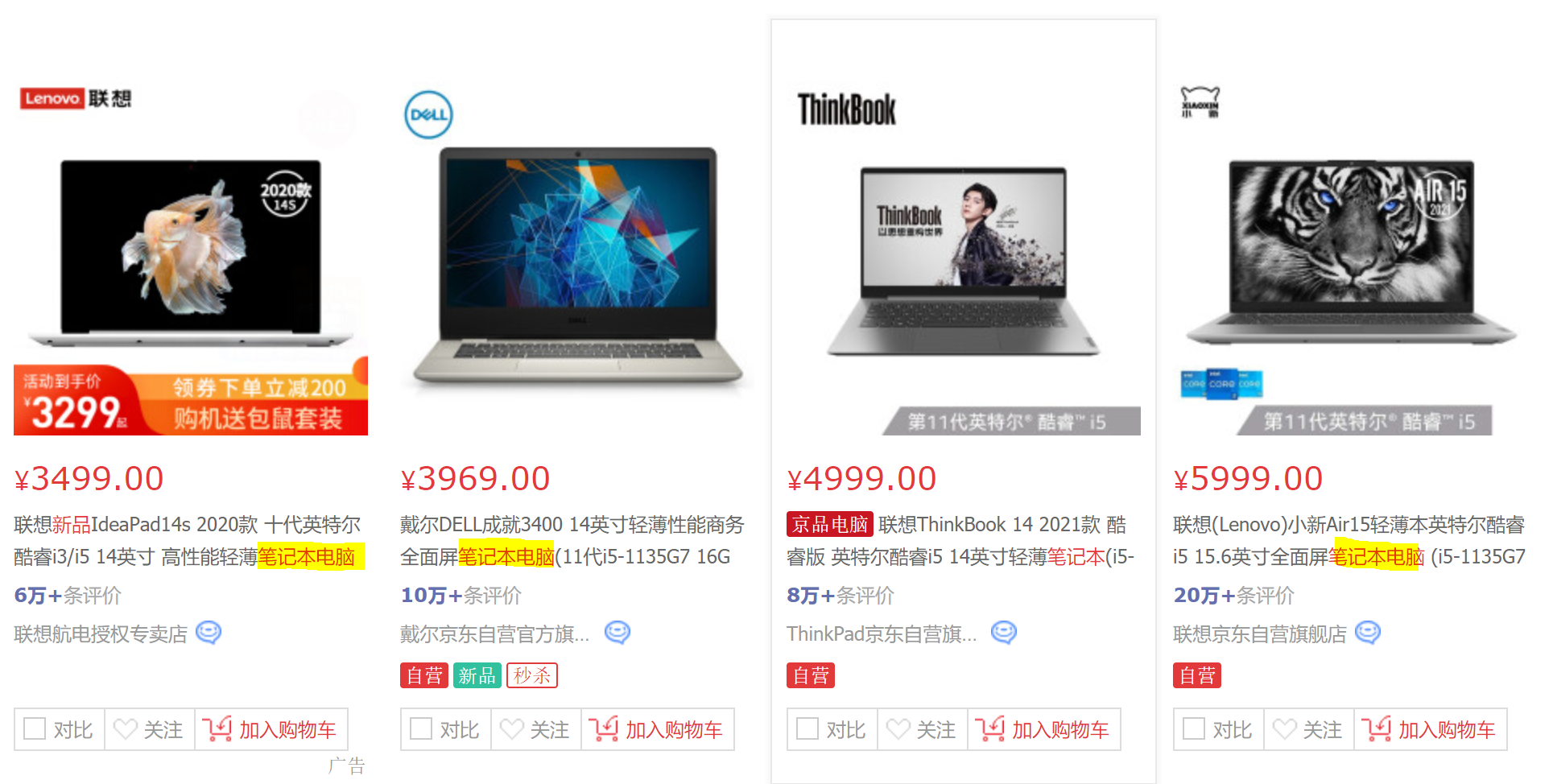
可以看到,上图商品搜索中,关键字变成了红色,其实就是给定了红色样式。
高亮搜索实现步骤:
- 指定高亮域,也就是,设置哪个域需要高亮显示
- 设置高亮域的时候,需要指定 前缀 和 后缀 ,也就是关键词用什么 html 标签包裹,再给该标签样式
// 指定高亮域
HighlightBuilder.Field field=new HighlightBuilder.Field("name");
// 前缀 <em style="color:red">
field.preTags("<em style="color:red">");
// 后缀 </em>
field.postTags("</em>");
// 碎片长度 即 当关键词所在的记录过长时
// 截取关键词数据之前与之后,展示数据的最大长度
field.fragmentOffset(100);
// 添加高亮
builder.withHighlightFields();
AggregatedPage<SkuInfo> page = elasticsearchTemplate
.queryForPage(
// 搜索条件封装
builder.build(),
// 执行搜索后数据集合需要转化的字节码类型
SkuInfo.class,
// 执行搜索后将数据结果集封装到该对象中
new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse searchResponse, Class<T> aClass, Pageable pageable) {
// 存储转换后的高亮对象
List list = new ArrayList();
// 遍历结果集
for (SearchHit hit : searchResponse.getHits()) {
// 转化成 JavaBean
SkuInfo skuInfo = JSON.parseObject(hit.getSourceAsString(), SkuInfo.class);
// 分析结果集,获取高亮数据
HighlightField highlightField = hit.getHighlightFields().get("name");
// 取出高亮数据
if (highlightField != null && highlightField.getFragments() != null) {
Text[] fragments = highlightField.getFragments();
StringBuffer buffer = new StringBuffer();
for (Text fragment : fragments) {
buffer.append(fragment.toString());
}
// 把非高亮数据中指定域替换成高亮数据
skuInfo.setName(buffer.toString());
// 将高亮数据添加到集合中
list.add(skuInfo);
}
}
// 将数据返回
// 构造方法需要的参数:搜索得到的数据集合 List,携带高亮的
// 分页对象
// 总条数
return new AggregatedPageImpl<T>(list, pageable, searchResponse.getHits().getTotalHits());
}
});
使用 debug 打断点跟代码,可以看到,当我们访问 http://localhost:18085/search?price=0-500元&keywords=联通 时,”联通“ 是进行了高亮设置的:

而且数据也能正常显示,但是,如果访问 http://localhost:18085/search?price=0-500元,也就是没有使用 keywords 参数, rows 是空的,也就是没有查询到结果。
这是因为,有 keywords=联通 作为参数时,执行 builderBasicQuery 方法里的
if (!StringUtils.isEmpty(keyWords)) {
//builder.withQuery(
//QueryBuilders.queryStringQuery(keyWords).field("name"));
// 如果关键词不为空,根据关键词在 name 域进行搜索
boolQueryBuilder.must(QueryBuilders.queryStringQuery(keyWords).field("name"));
}
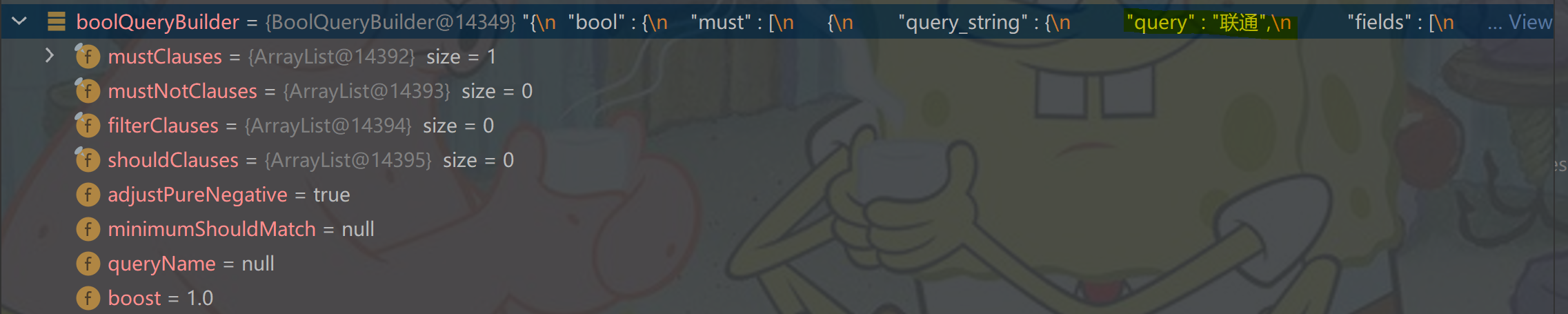
方法后,boolQueryBuilder 的 view 是这样的:
{
"bool" : {
"must" : [
{
"query_string" : {
"query" : "联通",
"fields" : [
"name^1.0"
],
"type" : "best_fields",
"default_operator" : "or",
"max_determinized_states" : 10000,
"enable_position_increments" : true,
"fuzziness" : "AUTO",
"fuzzy_prefix_length" : 0,
"fuzzy_max_expansions" : 50,
"phrase_slop" : 0,
"escape" : false,
"auto_generate_synonyms_phrase_query" : true,
"fuzzy_transpositions" : true,
"boost" : 1.0
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
boolQueryBuilder 变量的 query 的值是 “联通”,而且和 name 域是关联着的,所以会给 “联通” 加高亮。 (如果是执行 DSL 语句实现高亮,也是要用到 “query” 的,前缀和后缀就是作用在 “query” 上。)
而如果不传 keyword,只传了 price ,就会发现,执行完
// 搜索条件构建对象
NativeSearchQueryBuilder builder = builderBasicQuery(searchMap);
整个方法后,boolQueryBuilder 变量是这样的:

它 的 view :
{
"bool" : {
"must" : [
{
"range" : {
"price" : {
"from" : null,
"to" : 500,
"include_lower" : true,
"include_upper" : true,
"boost" : 1.0
}
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
是有对 price 进行查询,但是因为无高亮相关的数据,所以 rows 是空的。(其实如果去掉高亮搜索,只输入 price ,boolQueryBuilder 的 view 也是这样的,主要是调用 elasticsearchTemplate 的 queryForPage 方法时,还传入了 new SearchResultMapper() 参数,这个参数是查询得到的结果集,而只显示含高亮数据的,而数据并没有和 “name” 域关联起来,所以结果集是空的。个人理解,如果有误,请读者及时指出 ????。)
九、代码优化:分组合并搜索
注意到一个问题,我们对关键词进行了条件搜索,还对 分类、品牌、规格 分别进行了分组搜索,这样相当于执行了 4 次语句,访问了 4 次 ElasticSearch,效率比较低。 因此,很有必要对代码进行抽取、优化,比如说,先构建好条件,只执行一次语句。详细代码见 https://github.com/betterGa/ChangGou
search 代码优化后:
public Map<String, Object> search(Map<String, String> searchMap) {
// 搜索条件构建对象
// 实现:根据关键词进行搜索,根据分类、品牌、规格过滤,根据价格区间进行查询,排序,分页 的功能
NativeSearchQueryBuilder builder = builderBasicQuery(searchMap);
// 实现高亮搜索,执行搜索语句,获取数据结果
Map<String, Object> resultMap = searchlist(builder);
// 如果没有输入品牌、分类参数,就获取参数列表
resultMap.putAll(searchGroupList(builder,searchMap));
return resultMap;
}
十、总结
在 kibana 中执行 GET /skuinfo/_mapping,可以看到:
{
"skuinfo": {
"mappings": {
"docs": {
"properties": {
"brandName": {
"type": "keyword"
},
"categoryName": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "ik_smart"
},
"price": {
"type": "double"
},
"spec": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"specMap": {
"properties": {
"像素": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
... ...
},
... ...
在 Elasticsearch 索引库中,建立了 skuInfo 索引,skuInfo 索引类型 docs 中 包括 brandName、categoryName、name、price、spec 等属性。
之所以把 name、spec 设置为 text 类型,而 brandName、categoryName 设置为 keyword 类型,是因为 text 是自动分词的(不过比较费内存),像输入关键字,就需要去 name 域中,输入规格,就需要去 spec 中,而 name 和 spec 的值一般都比较长,所以需要进行分词查找,而 keyword 是不会分词的,而且 brandName 和 category 应该是前端写定的,必须是精确查询。
在 规格统计 中,把 spec 拆成 specMap 的形式,是为了后续对 spec_xxx 进行过滤。(后续可能会对 spec 进行分词查询吧,毕竟它的值比较长,所以设置为 text )
统计其实就是根据某个属性进行分组,得到组名列表,比如,品牌统计得到的是 { TCL,海尔,华为 }。对 spec 规格页进行了分组,其实就相当于去重,
过滤 其实就是查询,对于 brandName 和 category 是精确查询,对于 spec_xxx,本身是 text 类型,但是进行查询时使用了它的 keyword 的 field,所以也是精确查询,都是没有分词的。
还要注意,高亮搜索是对 “name” 域,所以后续必须传入 keywords 参数,才能与 “name” 进行关联,执行查询语句,查询出来的是要显示高亮的数据,所以如果没有传入 keywords 参数,将查到空数据。
接下来进行了一些逻辑优化,比如说,先根据关键字执行查询,获取数据;如果用户已经输入了 分类、品牌参数,就不需要展示组名列表了;(这样的话,就不担心分类和品牌之间的关联关系了,因为最先是根据关键字进行搜索的,查询到的结果中的分类和品牌必然是关联的);把构造条件的语句抽取出来,只执行一次查询… …
具体的功能实现见本篇文章。就像 JDBC ,按照步骤写代码即可,要注意编码仔细,比如传入变量 value ,和 字符串 “value”,执行的结果大不相同 ????,比如要注意判空。
最后
以上就是整齐大炮最近收集整理的关于微服务商城系统(七)商品搜索 数据统计、过滤、分页、排序、高亮搜索的全部内容,更多相关微服务商城系统(七)商品搜索内容请搜索靠谱客的其他文章。








发表评论 取消回复