症状:增加了CONCURRENT_REQUESTS,但是下载器并没有得到充分的利用,调度器也是空的。
示例:首先来运行一个没有这种问题的例子,把响应时间设置成1s,这样可以简化下载器吞吐量的计算:T = N/S = N/1 = CONCURRENT_REQUESTS。
$ time scrapy crawl speed -s SPEED_TOTAL_ITEMS=500
-s SPEED_T_RESPONSE=1 -s CONCURRENT_REQUESTS=64
s/edule d/load scrape p/line done mem
436 64 0 0 0 0
...
real 0m10.99s此时的下载器是满负荷工作的,总共花费的时间是11s,和模型计算出来的结果相符合: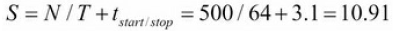 s。
s。
现在,还是这个程序(源码参见这里),这次不从列表中获取初始URL,而是给出一个索引页,从索引页中自己来提取20个URL:
$ time scrapy crawl speed -s SPEED_TOTAL_ITEMS=500
-s SPEED_T_RESPONSE=1 -s CONCURRENT_REQUESTS=64
-s SPEED_START_REQUESTS_STYLE=UseIndex
s/edule d/load scrape p/line done mem
0 1 0 0 0 0
0 21 0 0 0 0
0 21 0 0 20 0
...
real 0m32.24s显然这次和之前的例子不一样,不知何故,下载器中的请求数量比它的最大容量要小,吞吐量为T = N/(S - 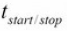 ) = 500/(32.2 - 3.1) = 17个请求每秒。
) = 500/(32.2 - 3.1) = 17个请求每秒。
讨论:看一下d/load栏就知道下载器没有被充分利用,这是因为我们并没有给它提供足够的URL。整个抓取过程生产URL的速度没有它消费URL的速度快。在本例中,从每个索引页可以获得20 + 1(下一个索引页)个URL,这样的吞吐量不可能达到每秒超过20个请求,因为获取URL的速度很慢。这种问题比较微妙。很容易就被忽视了。
解决方法:如果每个索引页有多于一个的下一页的链接,我们就可以使用这些链接来加速URL的产生。如果能找到含有更多的结果(例如50个)的索引页那就更好了。可以通过一些仿真来观察程序的性能:
$ for details in 10 20 30 40; do for nxtlinks in 1 2 3 4; do
time scrapy crawl speed -s SPEED_TOTAL_ITEMS=500 -s
SPEED_T_RESPONSE=1
-s CONCURRENT_REQUESTS=64 -s
SPEED_START_REQUESTS_STYLE=UseIndex
-s SPEED_DETAILS_PER_INDEX_PAGE=$details
-s SPEED_INDEX_POINTAHEAD=$nxtlinks
done; done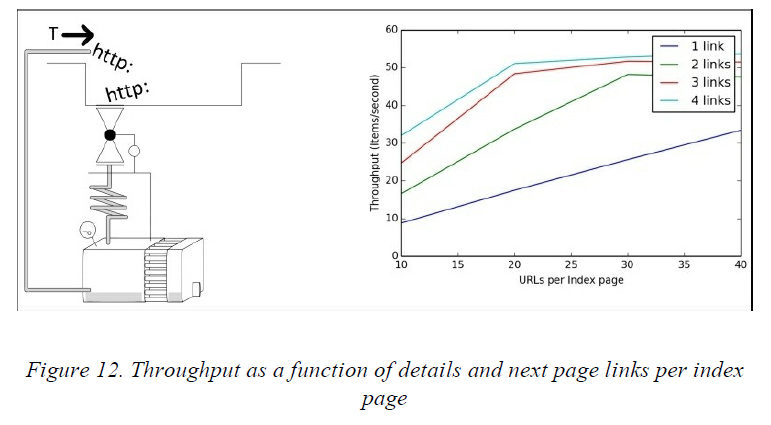
在图12中可以看到吞吐量随着这两个参数而变化的情形。在到达系统的限制之前,我们可以观察到吞吐量是随着这两个参数而线性增长的。你也可以重新排序一下爬虫的Rule来做个实验。如果你使用的是LIFO(默认)的顺序,那么如果你把提取索引页的请求放在Rule列表中的最后一个,以便调度器分配请求的时候把对索引页请求的顺序排在前面,这样会有一个吞吐量方面的微小的提升。你也可以把把索引页的请求设置一个比较高的优先级,这两种方法都不会有太过显著的提升,但是可以通过设置SPEED_INDEX_RULE_LAST=1和SPEED_INDEX_HIGHER_PRIORITY=1来分别尝试一下。要记住的一点是,这些解决方法都是先下载索引页,这样就能在调度器中产生很多URL,不过也会导致内存的需求增加。这些方法还有一个问题,由于是LIFO或者索引页高优先级的模式,爬虫会先处理完对所有索引页的请求,在抓取完所有的索引页之前不会产生太多的结果,如果索引页比较少,那还可以,但是如果索引页比较多,那就不是我们希望的结果了。
对于上面的问题,可以通过把索引页分成几个部分来解决。这就要求你能在程序中使用不只一个初始的索引URL了,而且这些初始的索引URL相互之间要离得比较远才行。例如,如果有100个索引页,那么就可以选择1和51这两个索引页当做初始的URL。这样爬虫就能以两倍的速度来遍历索引页。可以使用-s SPEED_INDEX_SHARDS设置项来仿真一下:
$ for details in 10 20 30 40; do for shards in 1 2 3 4; do
time scrapy crawl speed -s SPEED_TOTAL_ITEMS=500 -s
SPEED_T_RESPONSE=1
-s CONCURRENT_REQUESTS=64 -s
SPEED_START_REQUESTS_STYLE=UseIndex
-s SPEED_DETAILS_PER_INDEX_PAGE=$details -s
SPEED_INDEX_SHARDS=$shards
done; done这个结果显然比之前的要好,如果能使用的话,最好使用这个方法来解决下载器中请求不够的问题。
最后
以上就是魁梧超短裙最近收集整理的关于解决Scrapy性能问题——案例六(下载器中请求太少)的全部内容,更多相关解决Scrapy性能问题——案例六(下载器中请求太少)内容请搜索靠谱客的其他文章。





![scrapy报错解决[twisted.internet.error.TimeoutError: User timeout caused connection failure:]](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)


发表评论 取消回复