本文目录
- 一、爬虫框架Scrapy安装
- 二、创建Scrapy项目
- 三、分析网页,编写爬虫代码
- 3.1 存储到json
- 3.2 存储到MongoDB
本文章记录mac环境下框架安装。
一、爬虫框架Scrapy安装
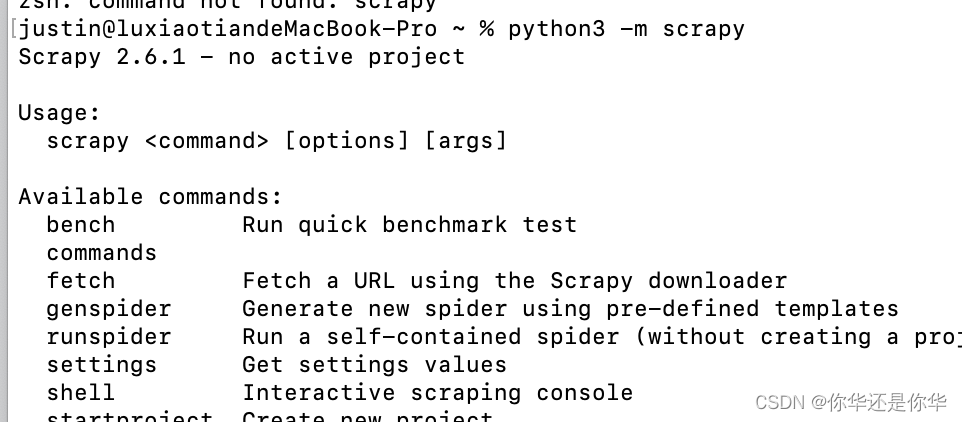
运行命令pip3 install scrapy,安装完之后输入python3 -m scrapy,出现如下图,则安装成功:
二、创建Scrapy项目
我们爬去scrapy推荐的爬取它自己的网站quotes.toscrape.com
输入命令:python3 -m scrapy startproject spiderdemo:

接着cd spiderdemo:

然后输入命令python3 -m scrapy genspider spider1 quotes.toscrape.com 创建一个爬虫,名称,域名:
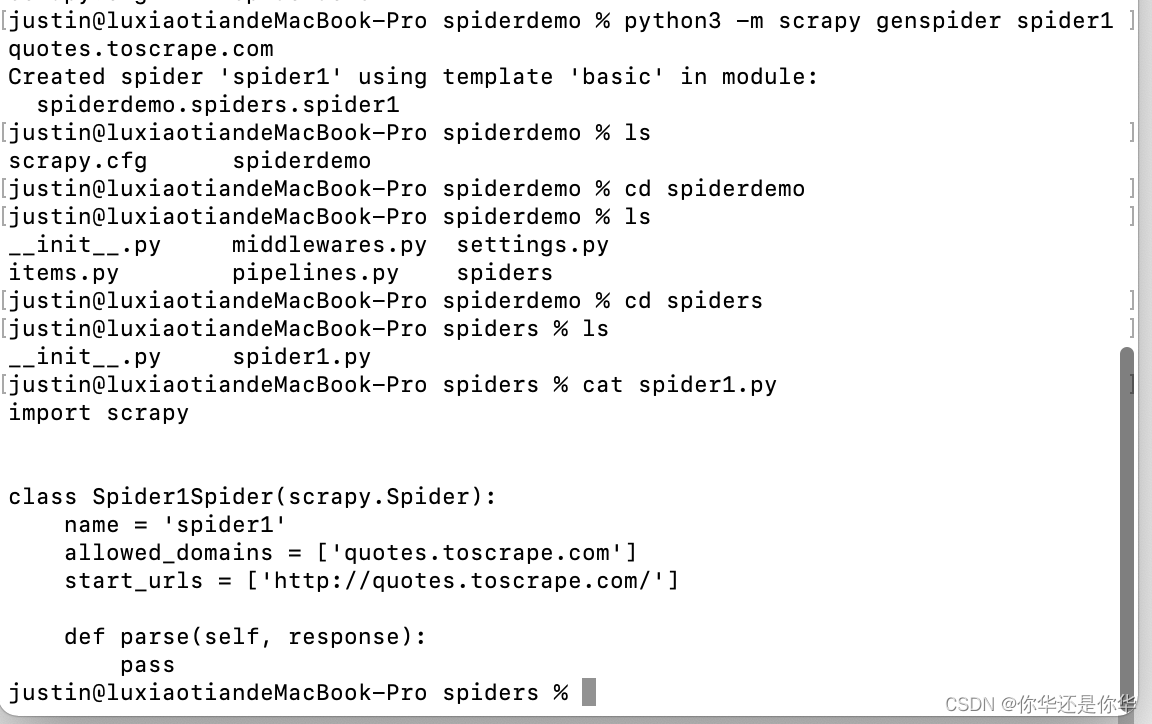
在上图可以看到,为我们生成了一个spider1.py文件。
用pycharm打开创建的项目:
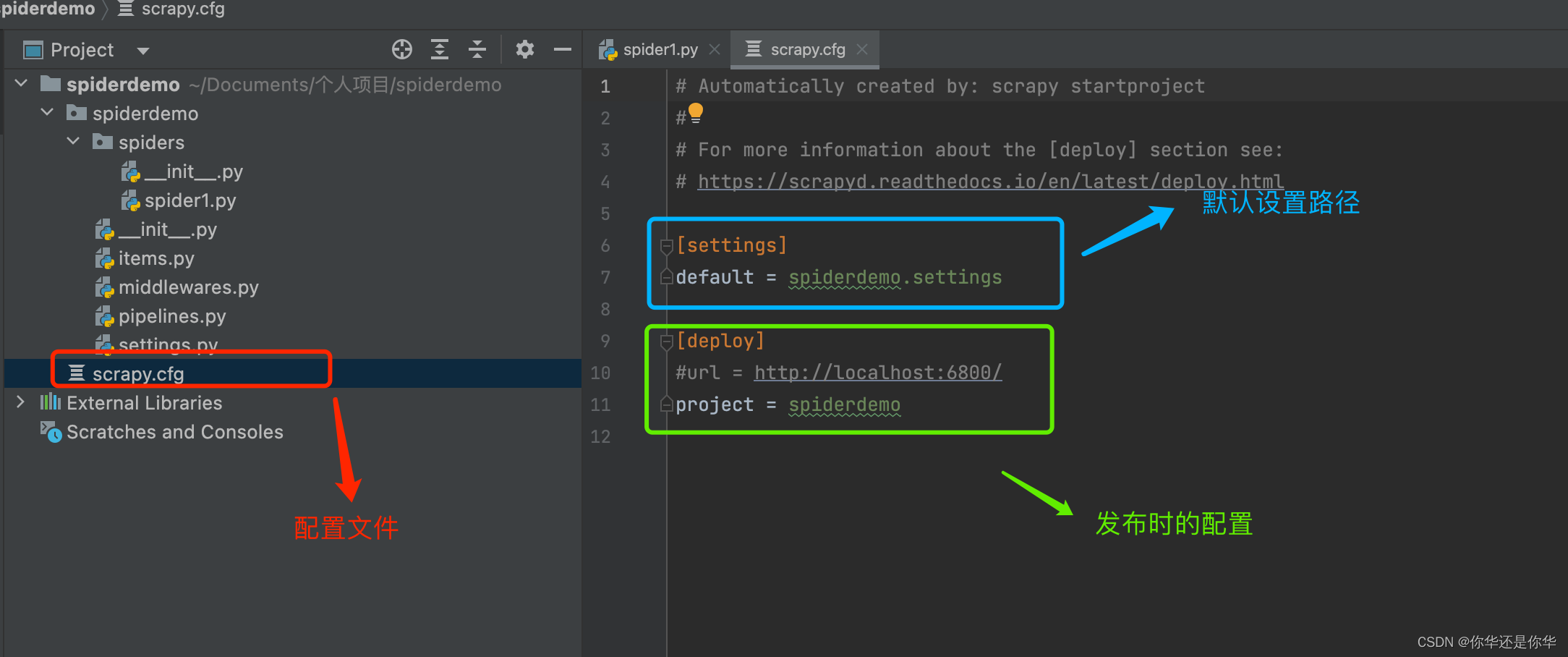
我们可以看到项目结构解读如下:
item.py:数据存储结构;
middlewares.py:爬取过程中的中间件;
piplines.py:获取items;
settings.py:配置文件;
spider1.py:写主逻辑;
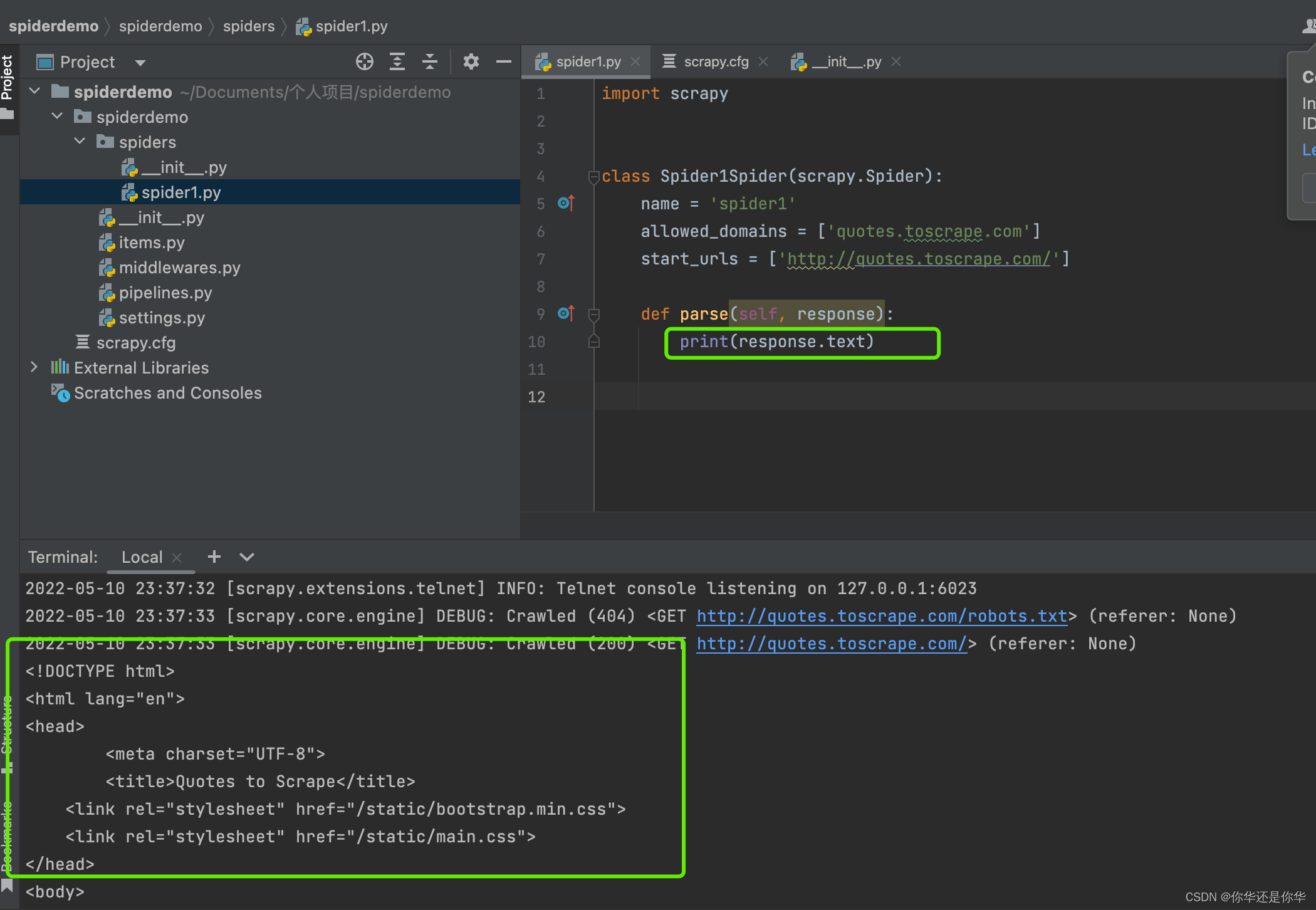
我们将spider1.py改为如下,然后输入命令python3 -m scrapy crawl spider1 :
三、分析网页,编写爬虫代码
打开quotes.toscrape.com调试网页代码查看:
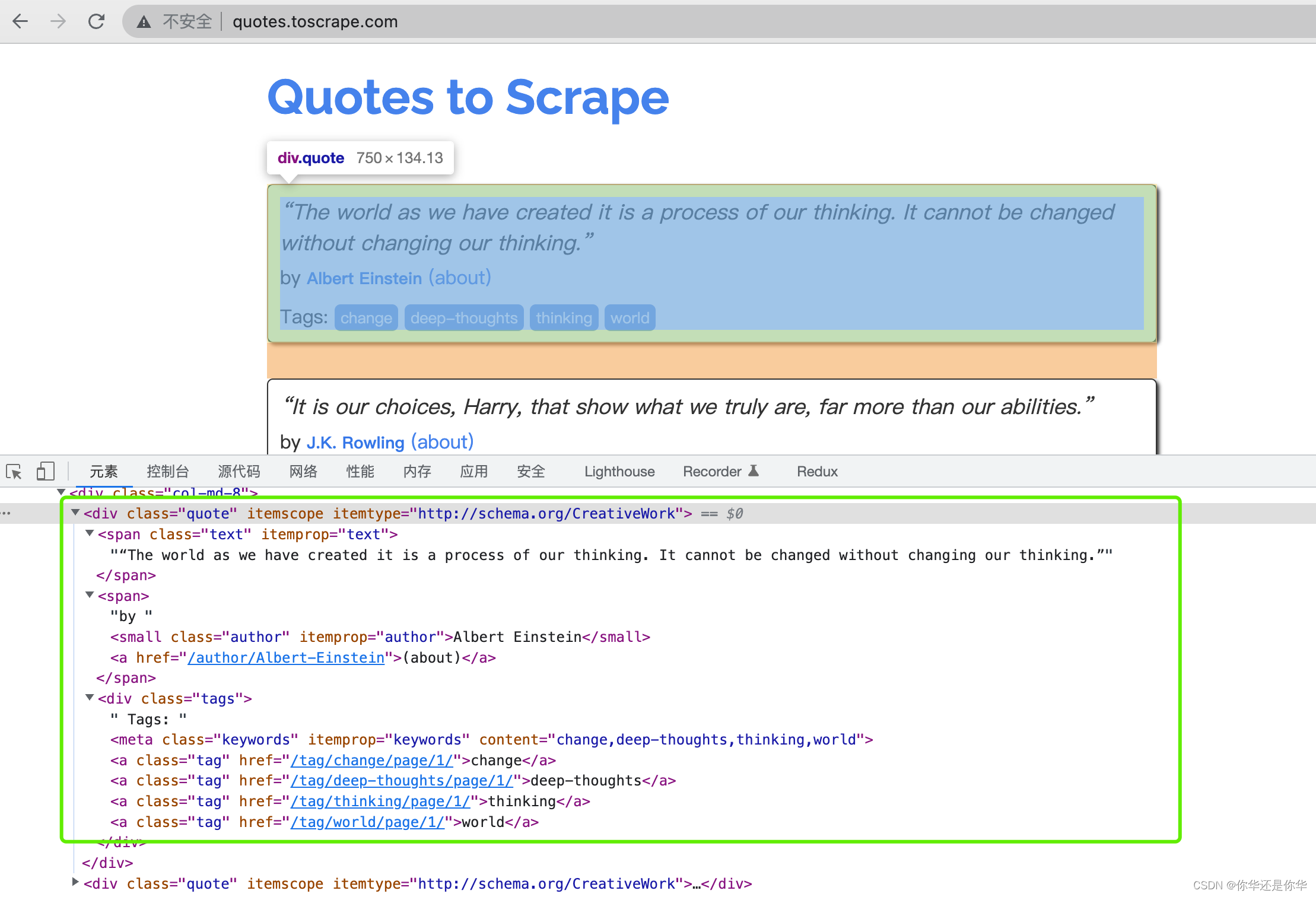
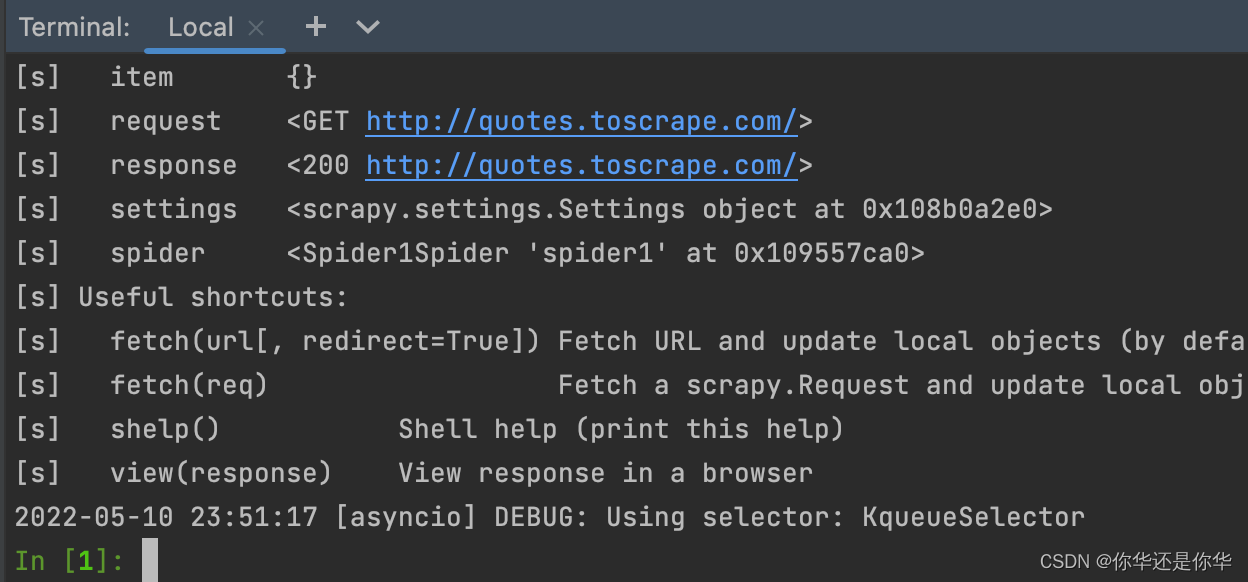
scrapy提供了调试命令python3 -m scrapy shell http://quotes.toscrape.com/后进入调试模式:
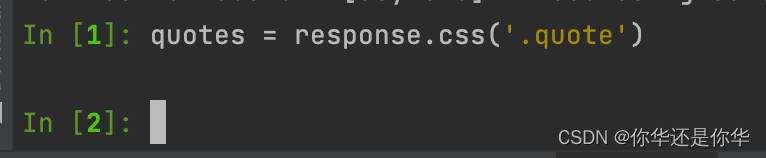
我们输入quotes = response.css('.quote'):
再输入quotes[0].css('.tags .tag::text').extract():

可以看到这里的调试器都是实时测试结果。
3.1 存储到json
在items.py文件中写入,要抓取的格式:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class SpiderdemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
在spider1.py中写入,分页抓取逻辑:
import scrapy
from spiderdemo.items import SpiderdemoItem
class Spider1Spider(scrapy.Spider):
name = 'spider1'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
spider1s = response.css('.quote')
for spider1 in spider1s:
item = SpiderdemoItem()
text = spider1.css('.text::text').extract_first()
author = spider1.css('.author::text').extract_first()
tags = spider1.css('.tags .tag::text').extract()
item['text'] = text
item['author'] = author
item['tags'] = tags
yield item
next = response.css('.pager .next a::attr(href)').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)
1、reponse已经是scrapy给我们处理后的,并且其上还有css选择器的功能,抓取网页节点。
2、::text获取文本。
3、extract_first获取第一个值。
4、extract获取所有值。
5、item定义好的格式直接赋值。
6、yield返回生成器,结束程序。
7、::attr获取元素属性。
8、response.urljoin域名拼接。
9、yield scrapy.Request(url=url, callback=self.parse)返回生成器,回调函数是调用自己,再将数据抓取下来。
输入命令python3 -m scrapy crawl spider1 -o spider1.json,抓取并且将数据存储为json格式:
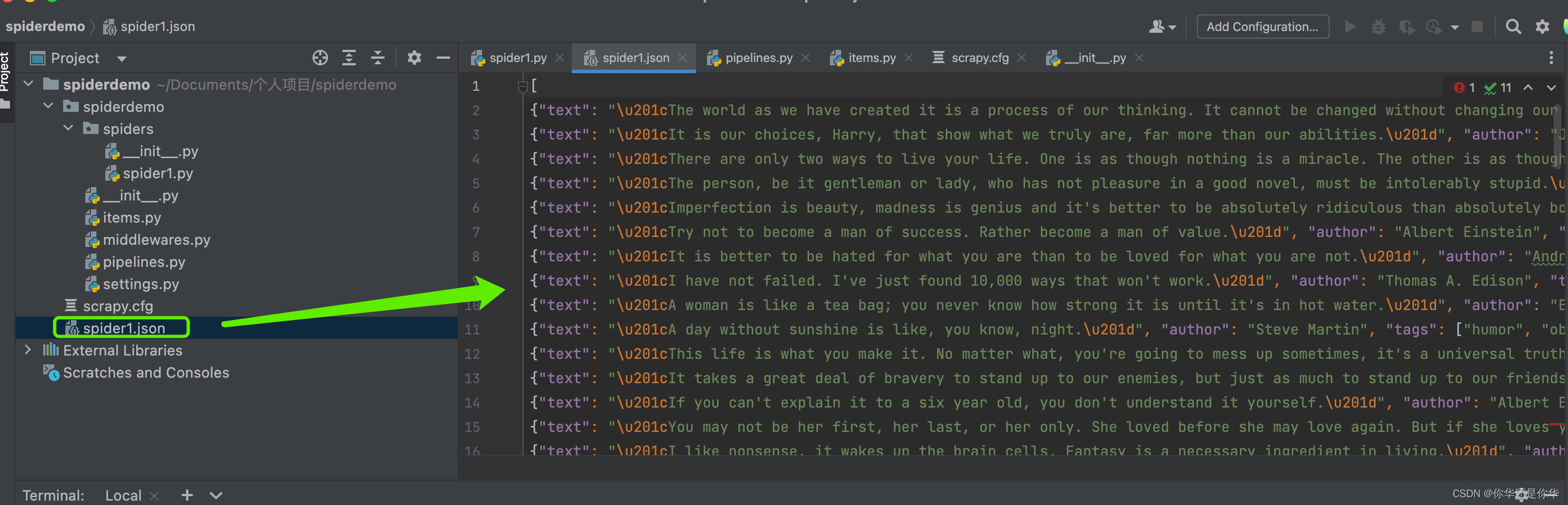
可以看到数据抓取回来,并且存储到json文件里了。
还可以支持远程服务器的存储:
python3 -m scrapy crawl spider1 -o ftp:://username:password@ftp.example.com/data/spider1.json
3.2 存储到MongoDB
如果要将抓取到的数据存储到数据库的话,那么在piplines.py中修改为如下代码:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import pymongo
from scrapy.exceptions import DropItem
class TextPipeline(object):
def process_item(self, item, spider):
if item['text']:
item['text'] = item['text']
return item
else:
return DropItem('Missing Text')
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
name = item.__class__.__name__
self.db[name].insert_one(dict(item))
return item
def close_spider(self, spider):
self.client.close()
在settings.py中加入MongoDB配置信息:
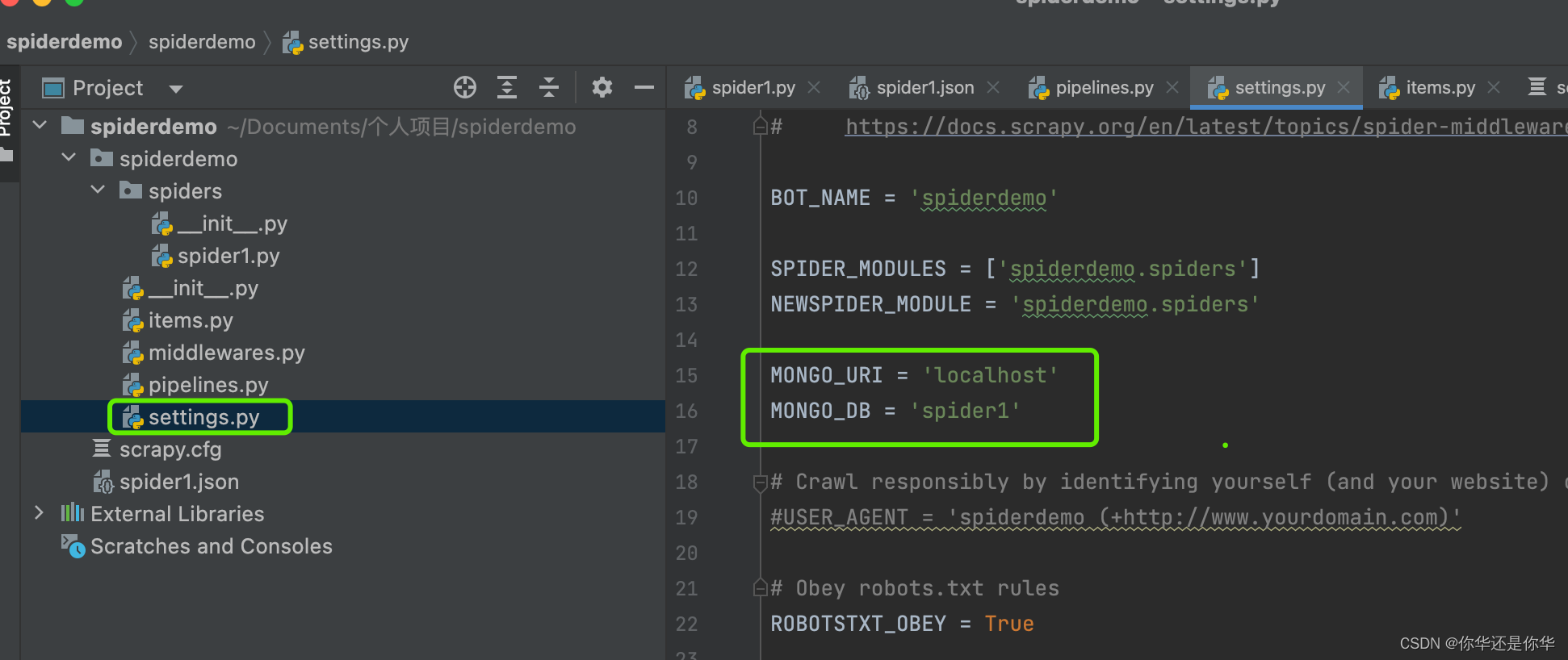

300,400代表着优先级。
确保你的MongoDB是开启的状态,接着运行命令:python3 -m scrapy crawl spider1 :
可以看到:

数据已经存储到MongoDB中了。
在学习python爬虫的路上。如果你觉得本文对你有所帮助的话,那就请关注点赞评论三连吧,谢谢,你的肯定是我写博的另一个支持。
最后
以上就是凶狠盼望最近收集整理的关于Scrapy爬虫框架搭建及抓取分页数据存储到库一、爬虫框架Scrapy安装二、创建Scrapy项目三、分析网页,编写爬虫代码的全部内容,更多相关Scrapy爬虫框架搭建及抓取分页数据存储到库一、爬虫框架Scrapy安装二、创建Scrapy项目三、分析网页内容请搜索靠谱客的其他文章。








发表评论 取消回复