今天刚学,都是个人理解,不准确或者错误的地方,跪求大佬轻喷,┭┮﹏┭┮
好像写的很乱,大概就是,跟着我说的做一遍,应该会有一个基本的了解~~
前言:
python课最后的实验报告是要爬取一个异步加载网页的数据,然后,很多人就懵了,点下一页,URL不变。对从豆瓣 top250 开始学爬虫的小白及其不友好,骂骂咧咧的打开B站,这代码真白,呸,这代码真妙。
我看了大佬的视频,大概要几个小时可以全部看完,不喜欢看文字的同学:
先点这里~~~
再点这里~~~
看完了吧,可以退场了,????
然后开始讲文字部分。
问题分析:
- 准备工作,这里是分析源码,找到页面数据部分的访问链接(个人理解,用词不一定准确)
ps:这个就是问题所在,异步加载网页的数据访问链接不容易找到 - 获取数据,这里是通过找到的规律,获取不同的数据(指数据源码)
ps:常规操作,得到 json 即可 - 解析数据,这里是指对 json 内容的处理
ps:python 不愧是被封装到牙齿的语言阿,直接用 json 的包处理即可 - 保存数据,存到数据库里边吧
ps:送佛送到西
我们直接找个实例来讲,
请出我们的小白鼠:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
对,我报告就是写的这个网页,别抄
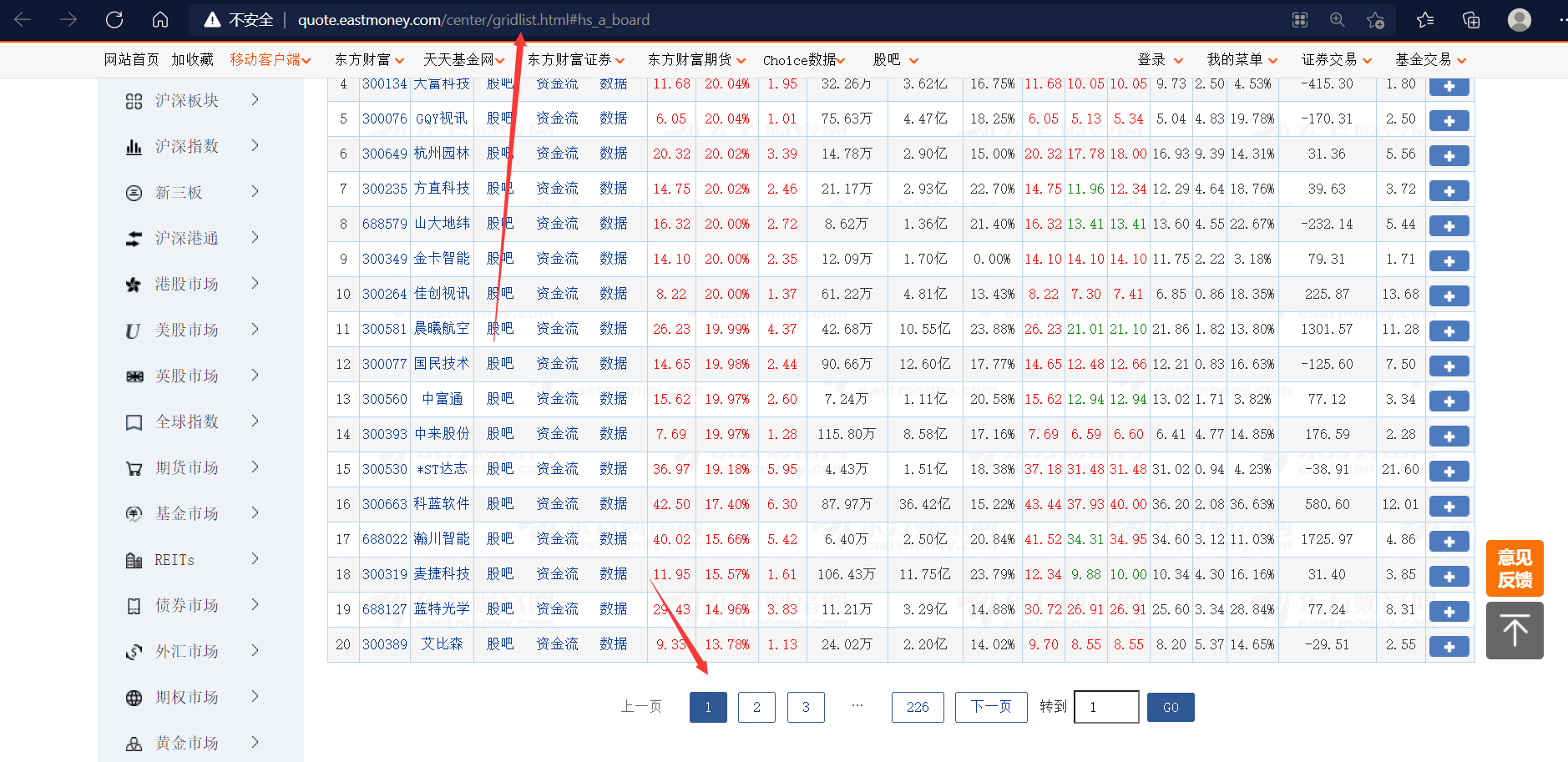
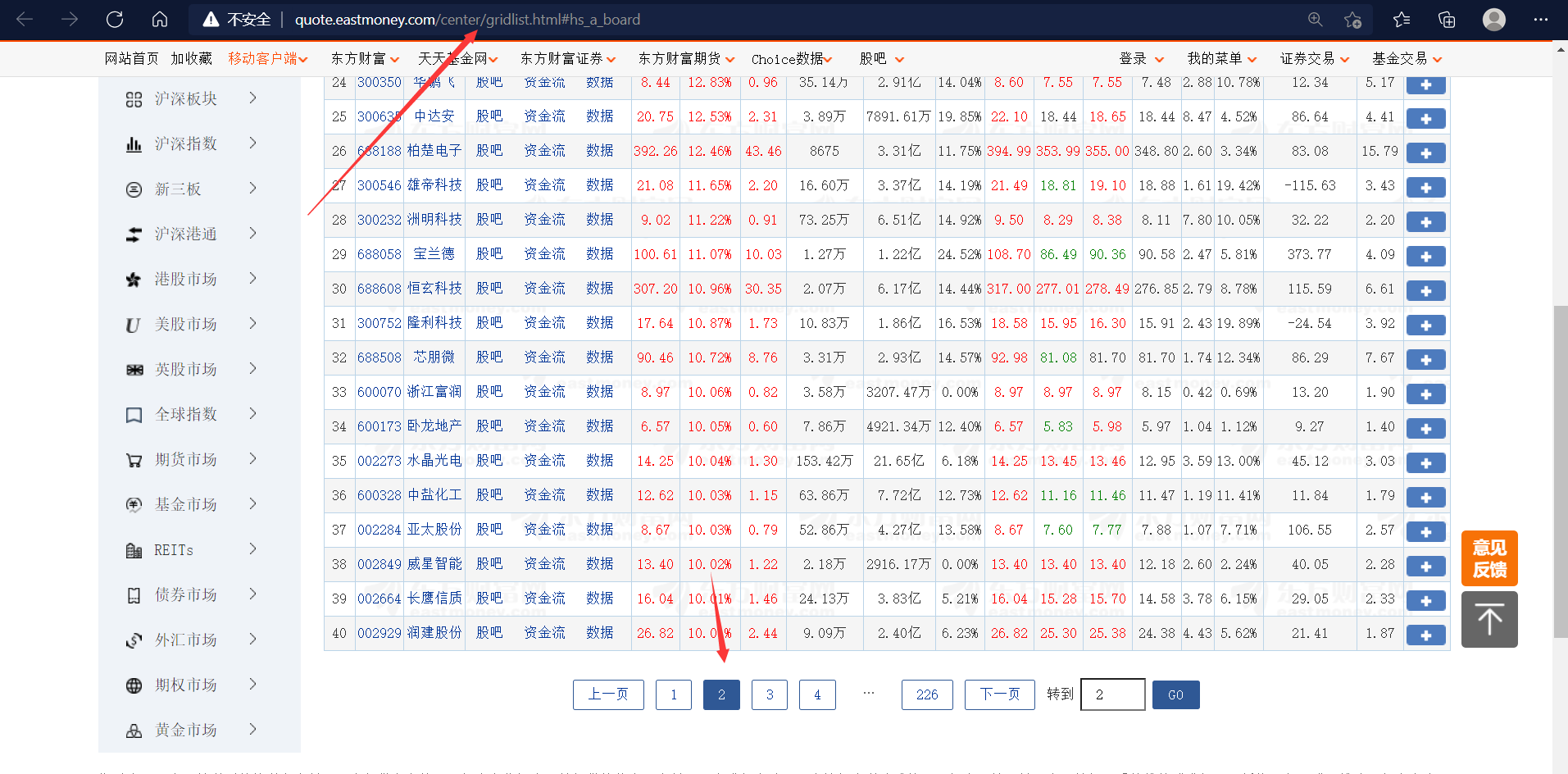
发现了吧,点翻页,链接不变
知识点:
ajax,页面异步交互
举个例子:
如果是在同步刷新的情况下,当请求正常返回时,整个页面都会进行刷新
但是在页面异步交互的情况下,只有 div1 的内容会进行一次刷新
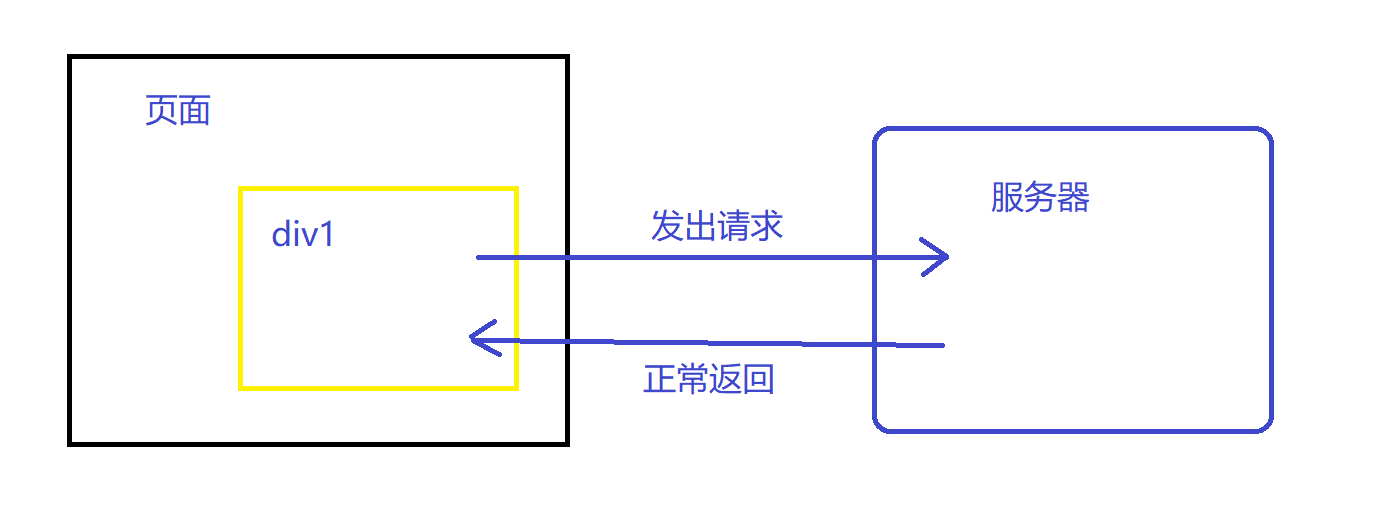
我们在对异步交互的网页爬取时,要怎么做呢?
很简单,模仿 div1 发出请求,得到返回数据
下边就来说说,div1 如何发出请求,轻轻按下F12,进入开发者模式
ps:当然要去小白鼠页面按了,在这里按屁都看不出来
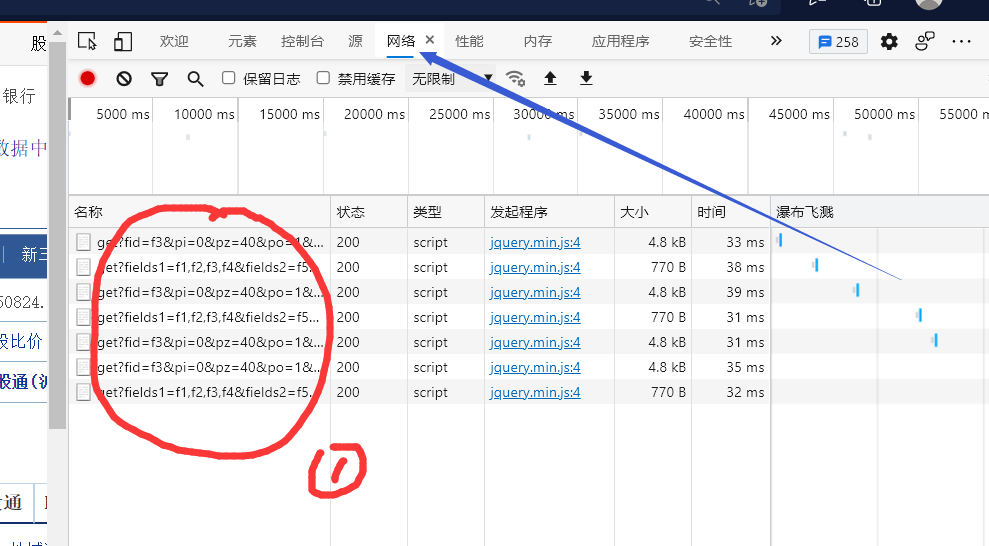
点这个网络,好像有的浏览器是英文,翻译翻译就好了。
我们可以注意到 ① 的内容,这个就是网页向服务器发送的请求信息,忘记说了,点一下左上角的红点点,不然会一直记录请求信息
随便找一个请求信息,点一下
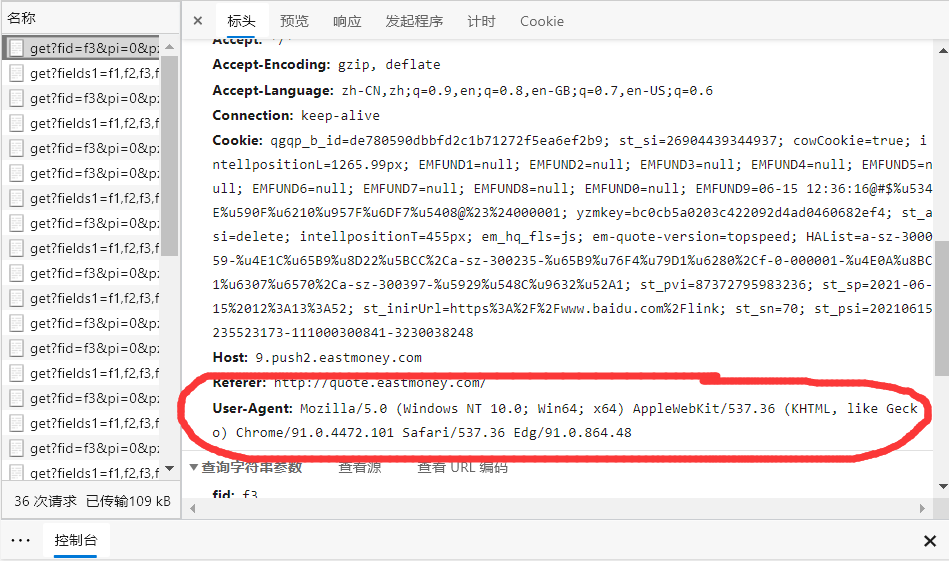
标头记录的信息就是使用者的各种信息,注意我画圈的这个地方就好了,User-Agent:… ,这条信息会告诉服务器你是什么样的浏览器,我们在模拟网页向服务器发送请求时,要设置这条,不然就会 418,也就意味着,你被人家发现你在爬虫了~~~
ps:敬告大家,少看小破站,不然所有的信息都被人家搜集走了
我们继续,敲黑板,重点来了:
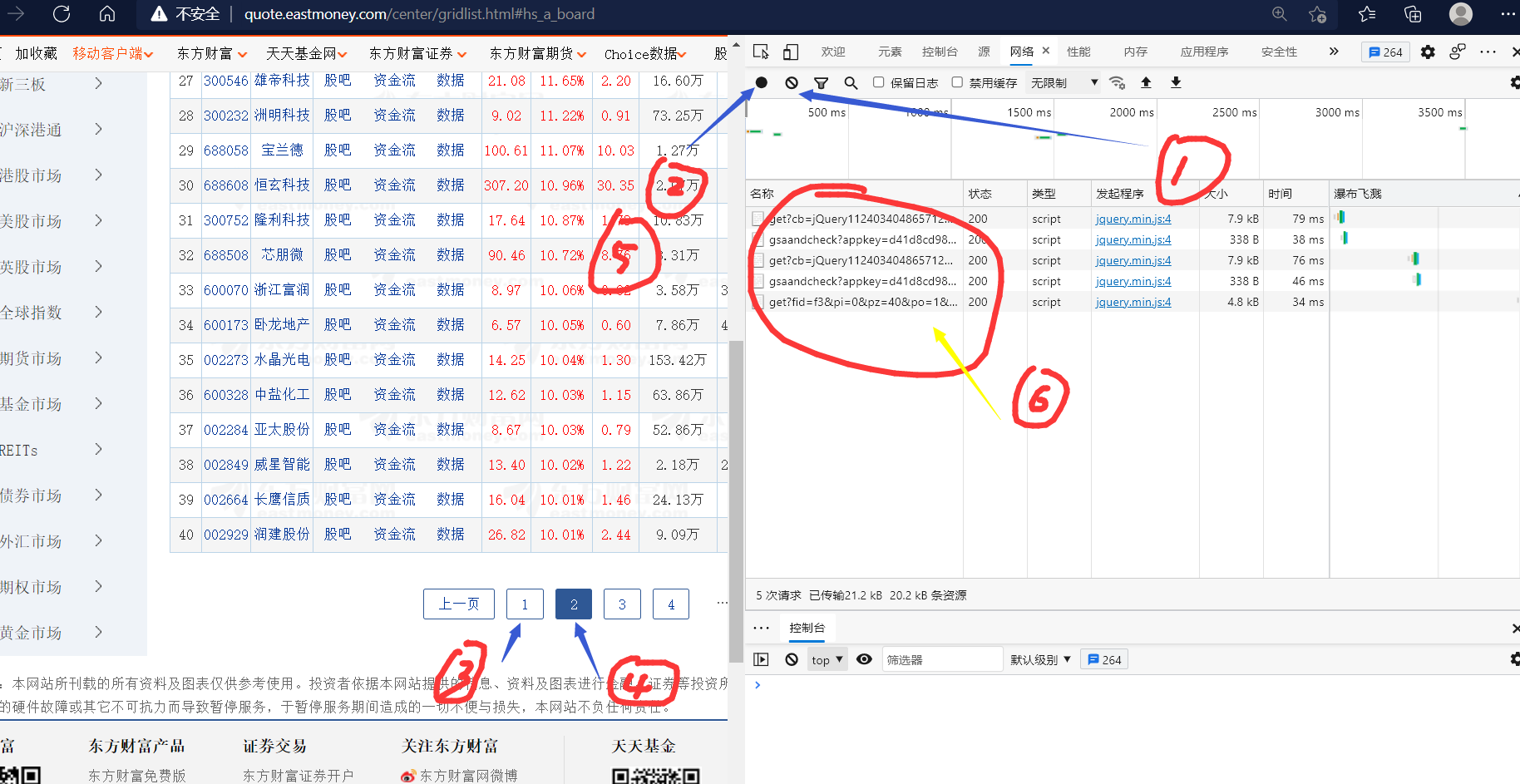
按照,1,2,3,4,5 的顺序点,你会得到图六的效果,再然后
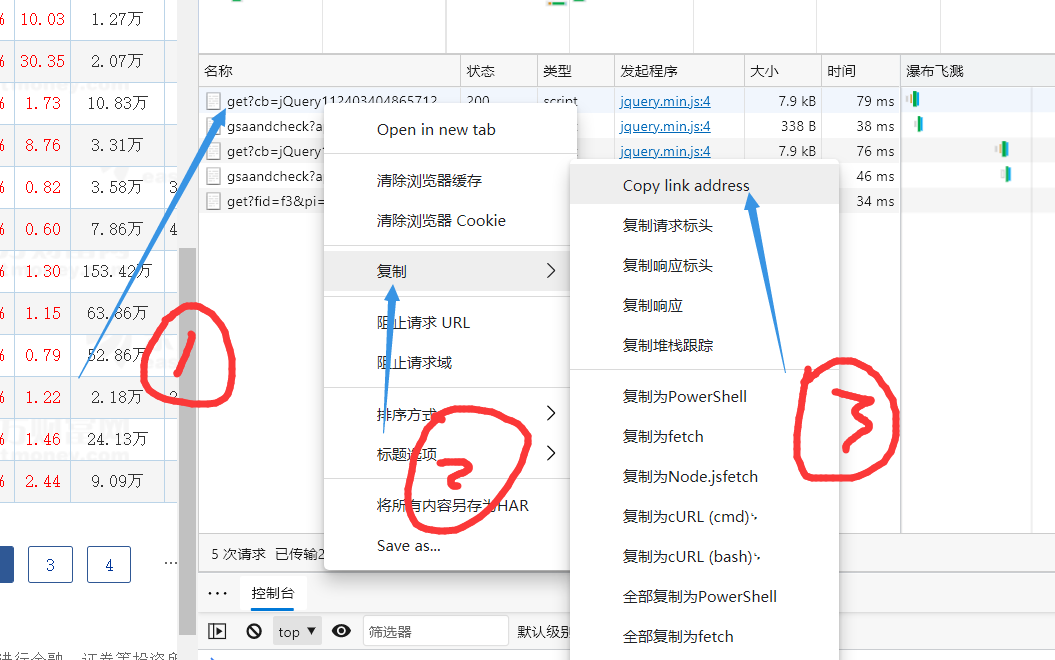
按照 1,2,3,然后 ctlr + v
就会得到这个:
http://46.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112403404865712147702_1623771689089&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1623771689370
嗯,这个就是向服务器发送请求的东东,把这个复制到另一个新的网页里,然后就是这样:
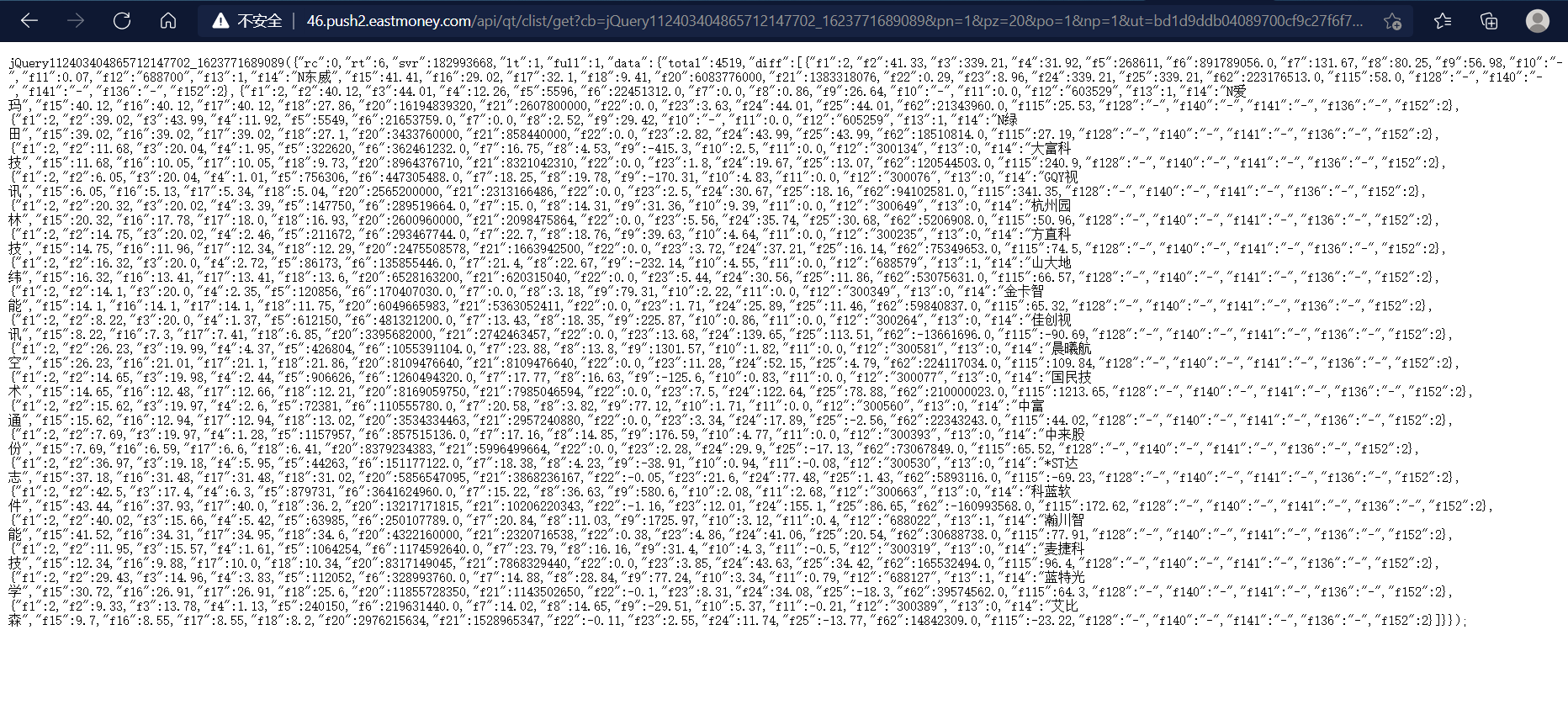
这堆代码,就是服务器返回的信息,这是一种 json语言,有兴趣的就百度一下吧~
这里我们请出一个工具:https://www.bejson.com/,可以放心打开
把,刚刚那堆东西复制过来,然后点格式化校验,然后就是
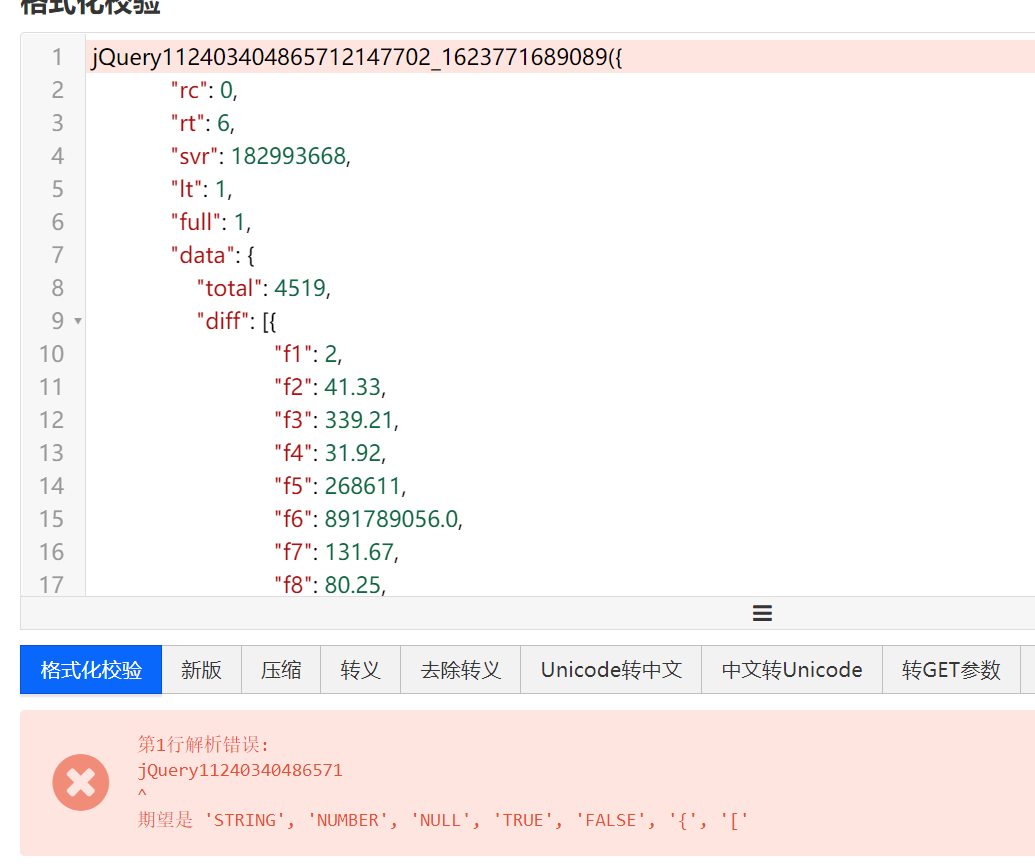
报错了,删掉画线的内容就行了~
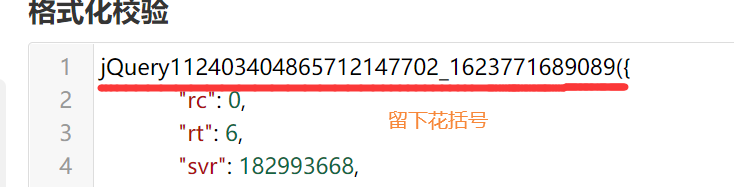
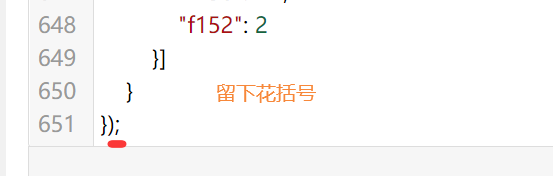
然后再点校验,他会告诉你没毛病~~
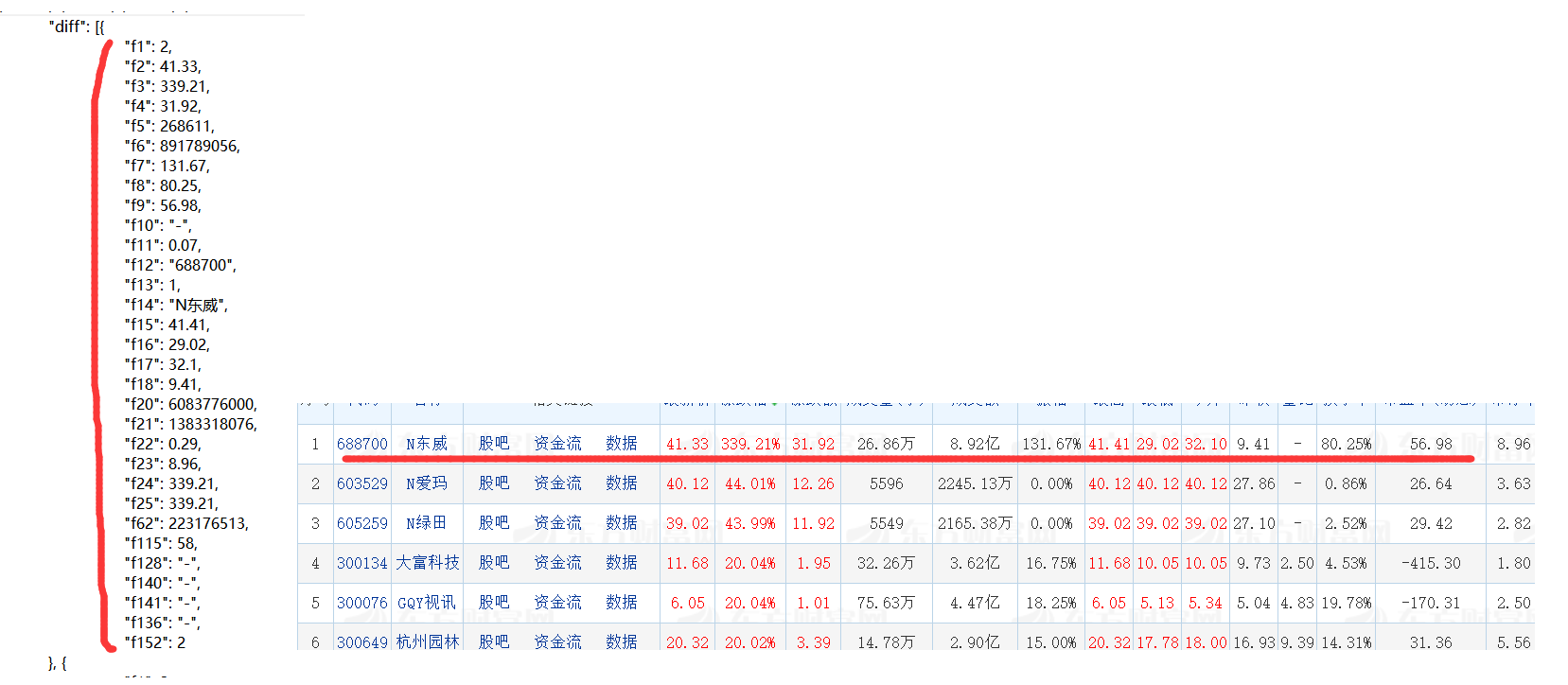
我相信你可以发现,每一对大括号对应的就是一组数据。
到这里,我们就结束了前导内容的准备
获取数据
上边的内容告诉我们,我们只需要研究
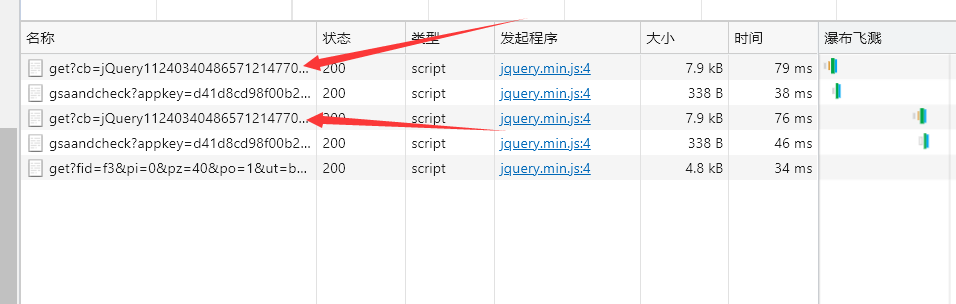
箭头指向这个东东,多复制几个链接下来


这个链接很长,共有两处不同,可以明显发现,第一处最有可能是控制页码的参数,第二处是干嘛的我也不知道没试出来
下边,我们就开始写代码,把刚刚的 json 内容给爬下来
import re
import urllib
import json
import time
import pymysql
def askURL(url):
# 这里就是一个伪装,复制上边标头处的信息即可,可以试试把这个设为空,????
#注意 User-Agent 一定不能打错,必须是这样
head = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36 Edg/91.0.864.48"
}
#这里就是利用urllib.request 来模拟信息
request = urllib.request.Request(url, headers = head)
html = ""
#注意可能会错,记得处理异常
try:
# urlopen 就是用来发送请求的,刚刚是设置请求信息
response = urllib.request.urlopen(request)
# 得到结果,并设置一下字符集,有中文
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html #返回结果
finddata = re.compile(r""diff":(.+?)}}")
def main():
#url 就是我们复制下来的链接
url = "http://31.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409351419538539436_1623731451797&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1623731452611"
res = askURL(url) #去模拟 div1 向服务器发出请求
print(res)
# 这是类似于 C 语言的写法,告诉程序从 main 函数开始执行,方便管理
if __name__ == "__main__":
main()
这部分代码的运行结果很明显,就是
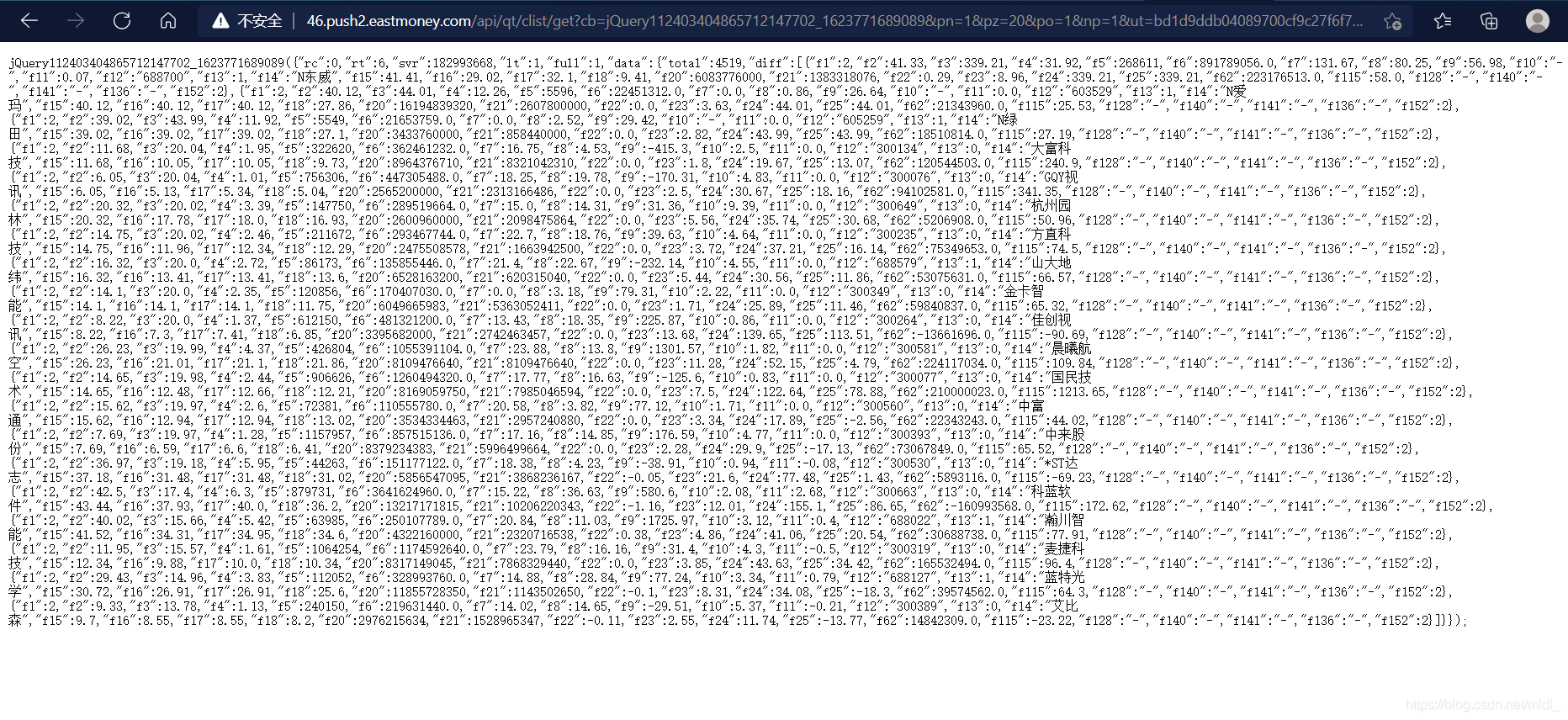
这堆没缩进的 json 代码,到这里,我们已经获取到数据源码了
ps:这个内容是 print 出来的,执行结果不会跳转到网页的
解析数据
下边就开始处理这堆乱码了,其实很简单,用 json 这个包来处理即可(python yyds ! ! !)。
不过还是需要一下正则表达式的,百度自学即可。
import re
import urllib
import json
import time
import pymysql
def askURL(url):
head = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36 Edg/91.0.864.48"
}
request = urllib.request.Request(url, headers = head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
#正则表达式
finddata = re.compile(r""diff":(.+?)}}")
def getData(url):
#得到源码信息
html = askURL(url)
#用正则表达式得到元组内的信息
data = re.findall(finddata, html)
#把源码变成python对象,也就是可以下标操作
jsonObj = json.loads(data[0])
for item in jsonObj:
print(item['f14'])
def main():
url = "http://31.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409351419538539436_1623731451797&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1623731452611"
getData(url)
if __name__ == "__main__":
main()
这里来说一下这里的正则表达式,我们需要的是第九行 [ 到
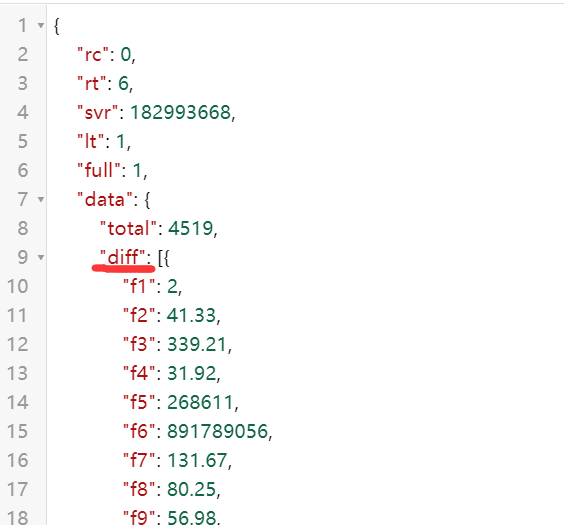
第 649 行 ] 之间的内容(保护这对方括号),故而正则表达式为:“diff”:(.+?)}},注意标记的地方,这里是固定的,所以可以通过这两部分来得到中间 [ … ] 之间的内容。
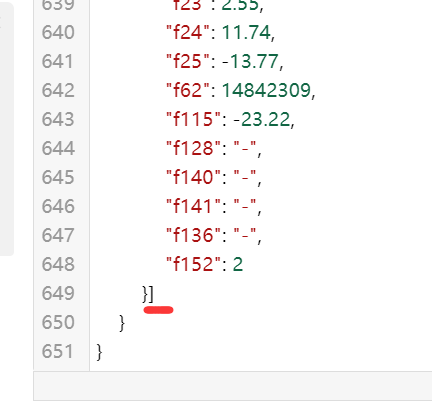
再说说,json.loads(data[0]),就是把 json 源码变成一个 pyhton 的对象,其他的百度即可。data[0] 是一因为,我们知道正则表达式的匹配结果只有一个符合的
运行结果如下:
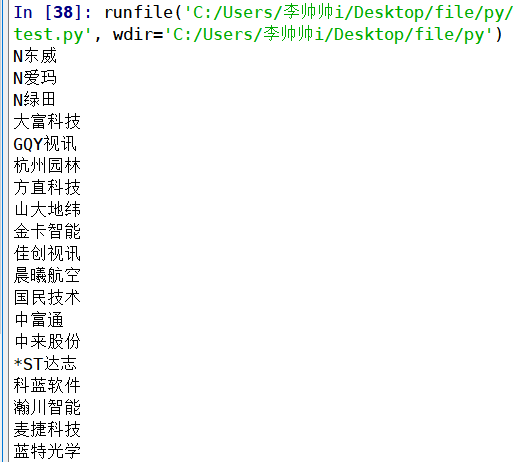
这里注意:print(item[‘f14’]),我们得到的 python对象是一个元组,
如果是其他地方,对应换即可,可以f15,f11…
到这里,我们就得到了真正的数据了
完结撒花★,°:.☆( ̄▽ ̄)/$:.°★ 。
保存数据
下边不想多解释了,下次或者其他文章再写吧,给一个带注释的代码,
ps: 这里注意一下getData() 的变化
import re
import urllib
import json
import time
import pymysql
def askURL(url):
head = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36 Edg/91.0.864.48"
}
request = urllib.request.Request(url, headers = head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
finddata = re.compile(r""diff":(.+?)}}")
def getData(baseurl1, baseurl2):
datalist = []
j = 0
for i in range(0, 1):
#这里就是计算真正的链接的地方,要翻页
url = baseurl1 + str(i+1) + baseurl2
html = askURL(url)
data = re.findall(finddata, html)
#print(data[0])
jsonObj = json.loads(data[0])
#我是把信息当作一个二维列表来存的,其他方式也行
for item in jsonObj:
datalist.append([])
for i in range(1, 21):
name = "f" + str(i)
#爬下来的数据没有 f19 这个要注意处理一下
if i == 19: datalist[j].append(" ")
else: datalist[j].append(item[name])
j = j + 1
time.sleep(1)
return datalist
# 数据库操作,写入库中,基本算是模板了,根据情况改循环和sql语句即可
def insertSQL(datalist):
db = pymysql.connect(host="localhost",user="root",password="123456",
db="test",port=3306,charset='utf8')
cursor = db.cursor()
for itme in datalist:
sql = "INSERT INTO data (id, name, now, Max, Min) VALUES (%s, %s, %s, %s, %s)"
val = (str(itme[11]), str(itme[13]), str(itme[16]), str(itme[14]), str(itme[15]))
cursor.execute(sql, val)
db.commit()
db.close()
def main():
#最最前边说过了,pn是用来表示页码的变量
baseurl1 = "http://31.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409351419538539436_1623731451797&pn="
baseurl2 = "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1623731452611"
data = getData(baseurl1, baseurl2)
insertSQL(data)
if __name__ == "__main__":
main()
最后
最后写的笼统了,要是哪里我没讲清楚,留言一下我来补充
最最后,如有错误,大佬轻喷~~
最后
以上就是危机牛排最近收集整理的关于python爬虫 | 异步加载网页的链接问题 | 小白速成篇的全部内容,更多相关python爬虫内容请搜索靠谱客的其他文章。








发表评论 取消回复