基于Python的一次职位招聘数据分析
- 1 Python数据分析常用的库和库函数
- 2 一次完整的数据分析过程
-
* * 画图- 工作地点处理
- 工资计量单位统一
- 公司类型
- 行业类型
- 参考
配套资源下载
- 职位信息分析.html
- job_info.csv
1 Python数据分析常用的库和库函数
常用库
- pandas
- numpy
- matplotlib
(ps:以下函数只是给出了函数名,函数参数还有很多灵活的选择,详情见 PandasAPI介绍
)
读取文件
- pandas.read_csv() #从csv文件读取数据
- pandas.read_xls() #从xls文件读取数据
查看数据特征,pandas
- pandas.describe()
- pandas.info()
- pandas.shape #数据形状,一般是二维(3,4)表示3行4列
数据去重,判断为空
- drop_duplicates() #删除重复值
- dropna() #删除空值
数据处理
- str # 字符化 eg:data[‘岗位名’] = data[‘岗位名’].str.strip().apply(lambda x: x.lower())
- value_counts() # 某列下不同的值计数
画图
- plt.rcParams[‘font.sans-serif’] = ‘SimHei’ #避免中文乱码
2 一次完整的数据分析过程
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
# header = None 首行为数据
# encoding = GBK 源文件编码为GBk
# index_col=0 数据第0列作为索引
data = pd.read_csv('job_info.csv',encoding='GBK',header=None,index_col=0)
data.head()
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|
| 0 | ||||||||
| 0 | 字节跳动 | rn 数据产品经理 | 北京 | 2-3.5万/月 | 09-03 | [] | [‘民营公司’] | |
| [‘10000人以上’] | [‘互联网/电子商务,计算机软件’] | |||||||
| 1 | 甲骨文(中国)软件系统有限公司 | rn 数据库管理员 | 长沙 | NaN | 09-03 | ['Oracle | ||
| Advanced Customer Service’, 'RESPONSI… | [‘外资(欧美)’] | [‘500-1000人’] |
[‘计算机软件’]
2 | 莱茵技术(上海)有限公司 TUV Rhei… | rn 莱茵学院与生命关怀部数据安全/IT安全的业务… | 上海-静安区
| NaN | 09-03 | [] | [] | [] | []
3 | 百度在线网络技术(北京)有限公司… | rn 商业分析规划部_资深数据分析师 … | 北京 | 2-4万/月 |
09-03 | [’-通过对数据的敏锐洞察以及定性和定量分析,迅速定位内部问题或发现机会’, '-负责大商业… | [‘外资(欧美)’] |
[‘500-1000人’] | [‘互联网/电子商务’]
4 | 携程旅行网业务区 | rn 数据分析经理(J18545) … | 上海-长宁区 | 1.5-2万/月 | 09-03
| [‘工作职责:’, ‘1、对数据进行筛选和整理,提高项目数据分析效率;’, '2、负责预订中… | [‘民营公司’] |
[‘10000人以上’] | [‘酒店/旅游,互联网/电子商务’]
# 为数据设置列名,并查看前5行
data.columns = ['公司名','岗位名','工作地点','工资','发布日期','工作描述','公司类型','公司规模','行业',]
data.head()
| 公司名 | 岗位名 | 工作地点 | 工资 | 发布日期 | 工作描述 | 公司类型 | 公司规模 | 行业 |
|---|---|---|---|---|---|---|---|---|
| 0 | ||||||||
| 0 | 字节跳动 | rn 数据产品经理 | 北京 | 2-3.5万/月 | 09-03 | [] | [‘民营公司’] | |
| [‘10000人以上’] | [‘互联网/电子商务,计算机软件’] | |||||||
| 1 | 甲骨文(中国)软件系统有限公司 | rn 数据库管理员 | 长沙 | NaN | 09-03 | ['Oracle | ||
| Advanced Customer Service’, 'RESPONSI… | [‘外资(欧美)’] | [‘500-1000人’] |
[‘计算机软件’]
2 | 莱茵技术(上海)有限公司 TUV Rhei… | rn 莱茵学院与生命关怀部数据安全/IT安全的业务… | 上海-静安区
| NaN | 09-03 | [] | [] | [] | []
3 | 百度在线网络技术(北京)有限公司… | rn 商业分析规划部_资深数据分析师 … | 北京 | 2-4万/月 |
09-03 | [’-通过对数据的敏锐洞察以及定性和定量分析,迅速定位内部问题或发现机会’, '-负责大商业… | [‘外资(欧美)’] |
[‘500-1000人’] | [‘互联网/电子商务’]
4 | 携程旅行网业务区 | rn 数据分析经理(J18545) … | 上海-长宁区 | 1.5-2万/月 | 09-03
| [‘工作职责:’, ‘1、对数据进行筛选和整理,提高项目数据分析效率;’, '2、负责预订中… | [‘民营公司’] |
[‘10000人以上’] | [‘酒店/旅游,互联网/电子商务’]
# 查看数据数量,共67085行,9个属性列
data.shape
(67085, 9)
# 数据去重,以公司名和岗位名为主键
data.drop_duplicates(subset=['公司名','岗位名'] ,inplace=True)
data.shape
(42040, 9)
# 去除字符串的前后空白和回车换行符
data['岗位名'] = data['岗位名'].str.strip().apply(lambda x: x.lower())
data.head()
| 公司名 | 岗位名 | 工作地点 | 工资 | 发布日期 | 工作描述 | 公司类型 | 公司规模 | 行业 |
|---|---|---|---|---|---|---|---|---|
| 0 | ||||||||
| 0 | 字节跳动 | 数据产品经理 | 北京 | 2-3.5万/月 | 09-03 | [] | [‘民营公司’] | |
| [‘10000人以上’] | [‘互联网/电子商务,计算机软件’] | |||||||
| 1 | 甲骨文(中国)软件系统有限公司 | 数据库管理员 | 长沙 | NaN | 09-03 | ['Oracle | ||
| Advanced Customer Service’, 'RESPONSI… | [‘外资(欧美)’] | [‘500-1000人’] |
[‘计算机软件’]
2 | 莱茵技术(上海)有限公司 TUV Rhei… | 莱茵学院与生命关怀部数据安全/it安全的业务拓展经理 | 上海-静安区 |
NaN | 09-03 | [] | [] | [] | []
3 | 百度在线网络技术(北京)有限公司… | 商业分析规划部_资深数据分析师 | 北京 | 2-4万/月 | 09-03 |
[’-通过对数据的敏锐洞察以及定性和定量分析,迅速定位内部问题或发现机会’, '-负责大商业… | [‘外资(欧美)’] |
[‘500-1000人’] | [‘互联网/电子商务’]
4 | 携程旅行网业务区 | 数据分析经理(j18545) | 上海-长宁区 | 1.5-2万/月 | 09-03 |
[‘工作职责:’, ‘1、对数据进行筛选和整理,提高项目数据分析效率;’, '2、负责预订中… | [‘民营公司’] |
[‘10000人以上’] | [‘酒店/旅游,互联网/电子商务’]
# 查看每个岗位有多少名额
data['岗位名'].value_counts()
算法工程师 920
大数据开发工程师 642
java开发工程师 577
图像算法工程师 397
web前端开发工程师 356
...
蓝牙安卓开发工程师 1
大数据开发工程师(中级) 1
高级/中级实施顾问 1
安全合规工程师 1
视频大数据人脸识别-业务经理 1
Name: 岗位名, Length: 22745, dtype: int64
# 统计目标岗位下有多少岗位数
target_job = ['算法', '分析', '工程师', '开发', '数据', '运营', '运维'] # 目标岗位
# 布尔索引筛选
index = [data['岗位名'].str.count(i) for i in target_job]
np.array(index).shape
(7, 42040)
# 按列求和
index = np.array(index).sum(axis=0)>0
index
array([ True, True, True, ..., True, True, True])
# 至此,筛选出包含 ['算法', '分析', '工程师', '开发', '数据', '运营', '运维'] 职位的数据
job_info = data[index]
job_info.shape
(24312, 9)
job_list = ['数据分析', '数据挖掘', '算法', '大数据',
'开发工程师', '运营', '软件工程', '前端开发',
'深度学习', 'AI', '数据库', '数据产品',
'客服', 'java', '.net', 'andriod', '人工智能', 'c++',
'数据管理']#列表形式
job_list = np.array(job_list)
job_list
array(['数据分析', '数据挖掘', '算法', '大数据', '开发工程师', '运营', '软件工程', '前端开发', '深度学习',
'AI', '数据库', '数据产品', '客服', 'java', '.net', 'andriod', '人工智能',
'c++', '数据管理'], dtype='<U7')
# 用job_list中的名字替换job_info中的岗位名
def rename_job(x=None,name_list = job_list):
index = [i in x for i in name_list]
# python 中false=0 true=1
if sum(index)>0:
return name_list[index][0]
else:
return x
job_info['岗位名'] = job_info['岗位名'].apply(rename_job)
job_info
E:CodingAnaconda3envsbigdatalibsite-packagesipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
"""Entry point for launching an IPython kernel.
| 公司名 | 岗位名 | 工作地点 | 工资 | 发布日期 | 工作描述 | 公司类型 | 公司规模 | 行业 |
|---|---|---|---|---|---|---|---|---|
| 0 | ||||||||
| 0 | 字节跳动 | 数据产品 | 北京 | 2-3.5万/月 | 09-03 | [] | [‘民营公司’] | |
| [‘10000人以上’] | [‘互联网/电子商务,计算机软件’] | |||||||
| 1 | 甲骨文(中国)软件系统有限公司 | 数据库 | 长沙 | NaN | 09-03 | ['Oracle Advanced | ||
| Customer Service’, 'RESPONSI… | [‘外资(欧美)’] | [‘500-1000人’] | [‘计算机软件’] | |||||
| 2 | 莱茵技术(上海)有限公司 TUV Rhei… | 莱茵学院与生命关怀部数据安全/it安全的业务拓展经理 | 上海-静安区 | |||||
| NaN | 09-03 | [] | [] | [] | [] | |||
| 3 | 百度在线网络技术(北京)有限公司… | 数据分析 | 北京 | 2-4万/月 | 09-03 | |||
| [’-通过对数据的敏锐洞察以及定性和定量分析,迅速定位内部问题或发现机会’, '-负责大商业… | [‘外资(欧美)’] | |||||||
| [‘500-1000人’] | [‘互联网/电子商务’] | |||||||
| 4 | 携程旅行网业务区 | 数据分析 | 上海-长宁区 | 1.5-2万/月 | 09-03 | [‘工作职责:’, | ||
| ‘1、对数据进行筛选和整理,提高项目数据分析效率;’, '2、负责预订中… | [‘民营公司’] | [‘10000人以上’] |
[‘酒店/旅游,互联网/电子商务’]
… | … | … | … | … | … | … | … | … | …
48 | 深圳市爱保护科技有限公司 | 开发工程师 | 深圳-宝安区 | 1-1.5万/月 | 09-07 | [‘职位描述:’,
‘1、参与产品需求分析,业务建模和文档制定’, ‘2、参与APP产品的设… | [‘民营公司’] | [‘50-150人’] |
[‘电子技术/半导体/集成电路,互联网/电子商务’]
49 | 圆梦共享教育科技(深圳)有限公司… | 开发工程师 | 深圳-龙华新区 | 1-1.5万/月 | 09-07 |
[’【岗位职责】’, ‘1、负责 Android 客户端业务功能规划、架构、设计及文档撰写;… | [‘民营公司’] | [‘50-150人’]
| [‘教育/培训/院校,影视/媒体/艺术/文化传播’]
48 | 上海晶确科技有限公司 | 数据科学家 | 上海-静安区 | 2-4万/月 | 09-07 |
[‘Purpose,xa0Dutiesxa0andxa0Responsibilitie… | [‘外资(非欧美)’] |
[‘50-150人’] | [‘计算机软件,专业服务(咨询、人力资源、财会)’]
46 | 广州市天尚信息技术有限公司 | 运营 | 广州-越秀区 | 0.6-1.2万/月 | 09-07 | [’【岗位职责】’,
‘1、负责公司的广告投放工作,包括产品上线和后期广告维护工作;’, '… | [‘民营公司’] | [‘50-150人’] |
[‘广告,互联网/电子商务’]
1 | 东莞市华道节能科技有限公司 | 运营 | 东莞-虎门镇 | 5-8千/月 | 09-07 | ['岗位职责: ‘, ’
1.负责店铺的日常管理’, ’ 2.根据店铺实际运营情况不定期制定… | [‘民营公司’] | [‘150-500人’] |
[‘互联网/电子商务,多元化业务集团公司’]
24312 rows × 9 columns
job_info['岗位名'].value_counts()
开发工程师 6056
算法 5353
运营 3128
大数据 2446
数据分析 1776
...
精益工程师 1
中高级运维工程师 1
金融量化分析师(偏量化交易程序开发) 1
软件开发岗(主管) 1
质量工程师(***) 1
Name: 岗位名, Length: 2714, dtype: int64
画图
a = job_info['岗位名'].value_counts()[:10]
plt.rcParams['font.sans-serif'] = 'SimHei'
a.plot(kind='bar')
plt.title('热门岗位')
plt.show()
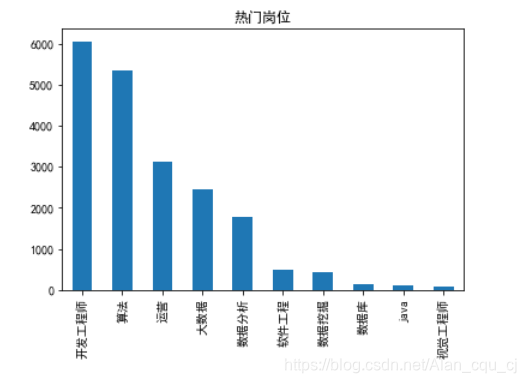
工作地点处理
job_info['工作地点'].value_counts()
深圳-南山区 1087
异地招聘 1039
广州-天河区 984
上海-浦东新区 971
上海 782
...
乐山 1
日照 1
黔南 1
渭南 1
益阳 1
Name: 工作地点, Length: 496, dtype: int64
address_list = ['北京', '上海', '广州', '深圳', '杭州', '苏州', '长沙',
'武汉', '天津', '成都', '西安', '东莞', '合肥', '佛山',
'宁波', '南京', '重庆', '长春', '郑州', '常州', '福州',
'沈阳', '济南', '宁波', '厦门', '贵州', '珠海', '青岛',
'无锡', '大连','哈尔滨','昆明','南昌']#大数据岗位常见城市名
address_list = np.array(address_list)
# 用address_list中的地点 替换job_info中的工作地点
def rename_adress(x=None,name_list = address_list):
index = [i in x for i in name_list]
# python 中false=0 true=1
if sum(index)>0:
return name_list[index][0]
else:
return x
job_info['工作地点'] = job_info['工作地点'].apply(rename_adress)
job_info['工作地点']
E:CodingAnaconda3envsbigdatalibsite-packagesipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
"""Entry point for launching an IPython kernel.
0
0 北京
1 长沙
2 上海
3 北京
4 上海
..
48 深圳
49 深圳
48 上海
46 广州
1 东莞
Name: 工作地点, Length: 24312, dtype: object
job_info['工作地点'].value_counts()
上海 3925
深圳 3389
广州 2931
北京 1719
杭州 1336
...
南阳 1
萍乡 1
邵阳 1
太仓 1
益阳 1
Name: 工作地点, Length: 183, dtype: int64
address_plot = job_info['工作地点'].value_counts()[:10]
plt.rcParams['font.sans-serif'] = 'SimHei'
address_plot.plot(kind='bar')
plt.title('热门工作地点')
plt.show()
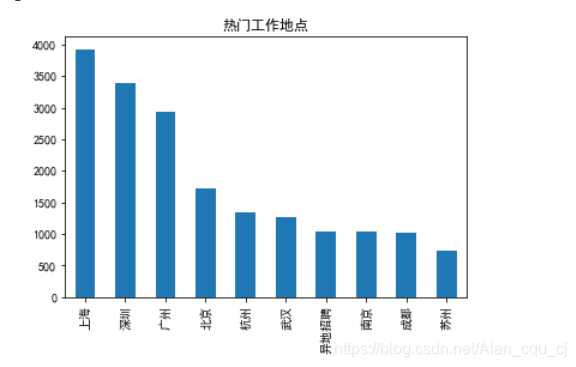
工资计量单位统一
# 查看所有工资时间单位
job_info['工资'].str[-1].value_counts()
月 22147
年 1366
天 97
时 5
Name: 工资, dtype: int64
# 查看工资单位
job_info['工资'].str[-3].value_counts()
万 18212
千 5284
元 97
下 17
/ 5
Name: 工资, dtype: int64
# 数据筛选
index1 = job_info['工资'].str[-1].apply(lambda x : x in ['年','月'])
index2 = job_info['工资'].str[-3].apply(lambda x : x in ['万','千'])
job_info = job_info[index1 & index2]
job_info.shape
(23496, 9)
# 工资标准化
def salary(x=None):
try:
if x[-3]=='万':
a = [float(i)*10000 for i in re.findall('d+.?d*',x)]
elif x[-3]=='千':
a = [float(i)*1000 for i in re.findall('d+.?d*',x)]
if x[-1]=='年':
a = [i/12 for i in a]
except:
return x
return a
# 测试
salary('1.5-2万/年')
[1250.0, 1666.6666666666667]
gongzi = job_info['工资'].apply(salary)
# 可能str[1]不存在???
job_info['最低工资'] = gongzi.str[0]
job_info['最高工资'] = gongzi.str[1]
job_info['平均工资'] = job_info[['最低工资','最高工资']].mean(axis=1)
job_info['平均工资']
0
0 27500.0
3 30000.0
4 17500.0
7 11500.0
8 5250.0
...
48 12500.0
49 12500.0
48 30000.0
46 9000.0
1 6500.0
Name: 平均工资, Length: 23496, dtype: float64
公司类型
job_info['公司类型'].value_counts()
['民营公司'] 16695
['上市公司'] 1677
['合资'] 1370
['国企'] 1176
['外资(非欧美)'] 975
['外资(欧美)'] 673
['创业公司'] 599
['事业单位'] 192
[] 86
['非营利组织'] 34
[''] 11
['外企代表处'] 6
['政府机关'] 2
Name: 公司类型, dtype: int64
ps: 去除[ ] ’ ’ 符号, 空值用None代替
index = job_info['公司类型'].apply(lambda x: len(x)<6)
# 处理缺失值
job_info.loc[index,'公司类型'] = np.nan
E:CodingAnaconda3envsbigdatalibsite-packagespandascoreindexing.py:966: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.obj[item] = s
# 去除 【】 ' '
job_info['公司类型'] = job_info['公司类型'].str[2:-2]
job_info['公司类型']
E:CodingAnaconda3envsbigdatalibsite-packagesipykernel_launcher.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
0
0 民营公司
3 外资(欧美)
4 民营公司
7 NaN
8 外资(欧美)
...
48 民营公司
49 民营公司
48 外资(非欧美)
46 民营公司
1 民营公司
Name: 公司类型, Length: 23496, dtype: object
job_info['公司类型'].value_counts()
民营公司 16695
上市公司 1677
合资 1370
国企 1176
外资(非欧美) 975
外资(欧美) 673
创业公司 599
事业单位 192
非营利组织 34
外企代表处 6
政府机关 2
Name: 公司类型, dtype: int64
行业类型
job_info['行业'].value_counts()
['计算机软件'] 2272
['互联网/电子商务'] 1363
['计算机软件,计算机服务(系统、数据服务、维修)'] 1105
['计算机软件,互联网/电子商务'] 886
['电子技术/半导体/集成电路'] 882
...
['检测,认证,学术/科研'] 1
['公关/市场推广/会展,家具/家电/玩具/礼品'] 1
['广告,批发/零售'] 1
['影视/媒体/艺术/文化传播,批发/零售'] 1
['金融/投资/证券,中介服务'] 1
Name: 行业, Length: 1121, dtype: int64
index = job_info['行业'].apply(lambda x: len(x)<6)
# 处理缺失值
job_info.loc[index,'行业'] = np.nan
job_info['行业'] = job_info['行业'].str[2:-2]
job_info['行业']
0
0 互联网/电子商务,计算机软件
3 互联网/电子商务
4 酒店/旅游,互联网/电子商务
7 NaN
8 机械/设备/重工
...
48 电子技术/半导体/集成电路,互联网/电子商务
49 教育/培训/院校,影视/媒体/艺术/文化传播
48 计算机软件,专业服务(咨询、人力资源、财会)
46 广告,互联网/电子商务
1 互联网/电子商务,多元化业务集团公司
Name: 行业, Length: 23496, dtype: object
job_info['行业'].value_counts()
计算机软件 2272
互联网/电子商务 1363
计算机软件,计算机服务(系统、数据服务、维修) 1105
计算机软件,互联网/电子商务 886
电子技术/半导体/集成电路 882
...
医疗设备/器械,建筑/建材/工程 1
批发/零售,计算机服务(系统、数据服务、维修) 1
通信/电信/网络设备,交通/运输/物流 1
快速消费品(食品、饮料、化妆品),检测,认证 1
教育/培训/院校,非营利组织 1
Name: 行业, Length: 1119, dtype: int64
job_info['行业'] = job_info['行业'].str.split(',').str[0]
job_info['行业'].value_counts()
计算机软件 5758
互联网/电子商务 4018
电子技术/半导体/集成电路 1739
计算机服务(系统、数据服务、维修) 1028
仪器仪表/工业自动化 964
通信/电信/网络设备 797
机械/设备/重工 607
贸易/进出口 578
金融/投资/证券 532
专业服务(咨询、人力资源、财会) 515
教育/培训/院校 503
汽车及零配件 486
医疗设备/器械 482
网络游戏 367
快速消费品(食品、饮料、化妆品) 360
服装/纺织/皮革 335
制药/生物工程 315
通信/电信运营、增值服务 296
多元化业务集团公司 282
建筑/建材/工程 253
计算机硬件 214
房地产 208
新能源 195
家具/家电/玩具/礼品 194
批发/零售 186
影视/媒体/艺术/文化传播 174
学术/科研 173
交通/运输/物流 160
电气/电力/水利 150
环保 135
医疗/护理/卫生 132
航天/航空 121
广告 100
石油/化工/矿产/地质 92
酒店/旅游 87
餐饮业 82
原材料和加工 79
检测,认证 72
物业管理/商业中心 70
家居/室内设计/装潢 46
印刷/包装/造纸 46
保险 45
政府/公共事业 39
外包服务 37
农/林/牧/渔 37
办公用品及设备 35
奢侈品/收藏品/工艺品/珠宝 35
美容/保健 32
中介服务 30
娱乐/休闲/体育 30
银行 26
生活服务 26
文字媒体/出版 25
公关/市场推广/会展 24
法律 17
租赁服务 15
非营利组织 8
信托/担保/拍卖/典当 6
会计/审计 6
采掘业/冶炼 4
Name: 行业, dtype: int64
a = job_info['行业'].value_counts()[:10]
plt.rcParams['font.sans-serif'] = 'SimHei'
a.plot(kind= 'bar')
#plt.subplots_adjust(bottom=0.1)
plt.xticks(rotation=45)
plt.title('热门行业')
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-
MfdM40av-1589683699657)(output_46_0.png)]](https://img-
blog.csdnimg.cn/20200517105211358.png?x-oss-
process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FsYW5fY3F1X2Nq,size_16,color_FFFFFF,t_70)
参考
- PandasAPI介绍

最后
以上就是苹果小兔子最近收集整理的关于【数据分析】基于Python的一次职位招聘数据分析(入门参考)1 Python数据分析常用的库和库函数2 一次完整的数据分析过程参考的全部内容,更多相关【数据分析】基于Python的一次职位招聘数据分析(入门参考)1内容请搜索靠谱客的其他文章。








发表评论 取消回复