
点击上方蓝色文字关注我们吧

有你想要的精彩

大家好,上篇推文介绍了爬虫方面需要注意的地方、使用vscode开发环境的时候会遇到的问题以及使用正则表达式的方式爬取页面信息,本篇内容主要是介绍BeautifulSoup模块的使用教程。
BeautifulSoup介紹
引用官方的解释:
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.
简单来说Beautiful Soup是python的一个库,是一个可以从网页抓取数据的利器。
官方文档:
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
BeautifulSoup安裝
pip install beautifulsoup4
或
pip install beautifulsoup4
-i http://pypi.douban.com/simple/
--trusted-host pypi.douban.com
顺便说一句:我使用的开发工具还是vscode,不清楚的看一下之前的推文。
BeautifulSoup解析器
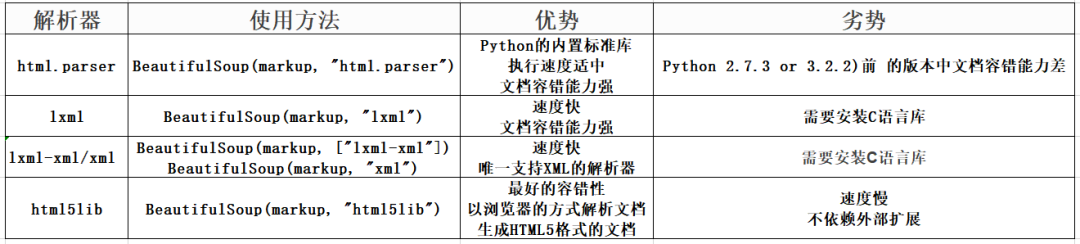
html.parse
html.parse 是内置的不需要安装的
import requestsfrom bs4 import BeautifulSoup
url='https://www.baidu.com'
response=requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())结果

lxml
lxml 是需要安装 pip install lxml
import requestsfrom bs4 import BeautifulSoup
url='https://www.baidu.com'
response=requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
print(soup)结果

lxml-xml/xml
lxml-xml/Xm是需要安装的 pip install lxml
import requestsfrom bs4 import BeautifulSoup
url='https://www.baidu.com'
response=requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'xml')
print(soup)结果
html5lib
html5lib 是需要安装的 pip install html5lib
import requestsfrom bs4 import BeautifulSoup最后
以上就是安静面包最近收集整理的关于beautifulsoup爬取网页中的表格_Python 爬虫基础教程——BeautifulSoup抓取入门的全部内容,更多相关beautifulsoup爬取网页中的表格_Python内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复