症状:系统的吞吐量比较期望的要小,并且下载器中的Request对象有时看起来比CONCURRENT_REQUESTS还要多。
示例:我们使用0.25秒的下载延迟来模仿下载1000个网页,默认的并发水平是16个,根据前面的公式,大概需要花19s的时间。我们在一个pipeline中使用crawler.engine.download()来发起一个额外的HTTP请求到 一个假的API,这个请求的响应需要1s的时间。运行一下程序:
$ time scrapy crawl speed -s SPEED_TOTAL_ITEMS=1000 -s
SPEED_T_RESPONSE=0.25 -s SPEED_API_T_RESPONSE=1 -s
SPEED_PIPELINE_API_VIA_DOWNLOADER=1
...
s/edule d/load scrape p/line done mem
968 32 32 32 0 32768
952 16 0 0 32 0
936 32 32 32 32 32768
...
real 0m55.151s上面的结果有些奇怪,不仅花费了三倍的时间程序才运行完毕,而且下载器(d/loader)中的活动的请求数目比CONCURRENT_REQUESTS还要多。下载器显然是系统的瓶颈,因为它的负载已经超出容量了。重新运行一下程序,在另一个终端用telnet连接Scrapy,并检查下载器中的哪些Request对象是活动的:
$ telnet localhost 6023
>>> engine.downloader.active
set([<POST http://web:9312/ar:1/ti:1000/rr:0.25/benchmark/api>, ... ])看来它主要在处理pipeline中额外HTTP的请求而不是在下载爬虫中的网页。
讨论:看到这里你或许会希望永远不要有人使用crawler.engine.download()函数,因为它看起来情况有点复杂,但是Scrapy本身已经再次使用了这个函数,分别是在robots.txt中间件和多媒体中间件。所以当需要访问web api时,这个函数其实也不失为一个解决办法,至少使用这个函数比使用那些阻塞的API,比如Python比较流行的requests库,而且它也比理解了Twisted编程之后再使用treq库要来得简单些。不过还是有解决方案的。这种错误很难去调试,所以在检查性能的时候要主动地扯一下下载器中的活动请求。如果在其中发现对WEB API的请求和对多媒体URL的请求,那就说明你的某些pipeline中使用了crawler.engine.download()函数来发起HTTP请求。而我们设置的CONCURRENT_REQUESTS限制对这些Request对象是无效的,这就意味着我们有可能会发现下载器中的请求比CONCURRENT_REQUESTS要多。除非下载器中的这些伪请求(即使用crawler.engine.download()函数发起的请求)的数目降低到CONCURRENT_REQUESTS以下,否则调度器不会发来新的页面请求(即爬虫中产生的请求)。
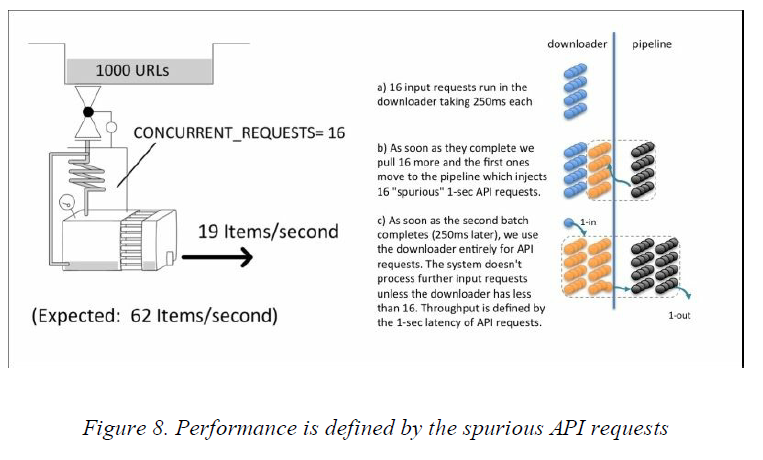
所以,系统的实际吞吐量才会与设置的延迟为1s(即访问web api的延迟)的时候的吞吐量一致。这个案例尤其令人,因为除非API访问比页面请求要慢,否则我们不会注意到性能的降低。
解决方案:可以通过使用treq库而不是crawler.engine.download()函数来解决这个问题。你会发现使用这个方法会使Scrapy的性能直线上升,在这里我会慢慢地增加CONCURRENT_REQUESTS的数目来保证不会使API服务器负载太高。
下面的程序和之前的程序是一样的功能,只不过是使用了treq:
$ time scrapy crawl speed -s SPEED_TOTAL_ITEMS=1000 -s
SPEED_T_RESPONSE=0.25 -s SPEED_API_T_RESPONSE=1 -s
SPEED_PIPELINE_API_VIA_TREQ=1
...
s/edule d/load scrape p/line done mem
936 16 48 32 0 49152
887 16 65 64 32 66560
823 16 65 52 96 66560
...
real 0m19.922s你会发现一个非常有趣的事情,pipeline中的Item比下载器中的还多。这样是很正常的,而且理解为什么这样会很有趣。
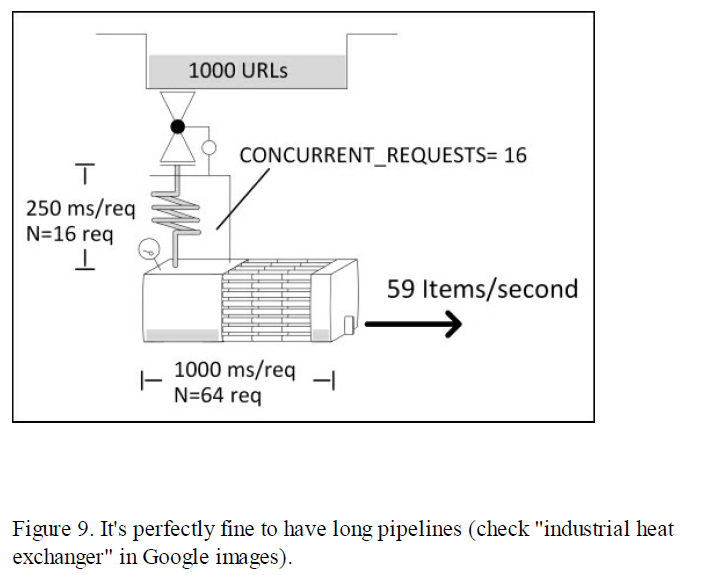
正如期望的那样,下载器被16个请求占满了,意味着系统的吞吐量是T = N/S = 16/0.25 = 64个请求/秒。我们可以通过观察done那一栏的增长来证实这一点。下载器中的一个请求会花费0.25s的时间,但是由于API访问比较慢,在pipeline中会花费1s的时间。这就是说,在pipeline(p/line)中,我们期望能看到Item的平均数是N = T * S = 64个。但这并不意味着pipeline就是瓶颈,因为我们根本就没有限制在pipeline中能够同时处理的响应的数目。只要pipeline中响应的数目不无限地增加,那就ok。
最后
以上就是清脆水蜜桃最近收集整理的关于解决Scrapy性能问题——案例三(下载器中的“垃圾”)的全部内容,更多相关解决Scrapy性能问题——案例三(下载器中内容请搜索靠谱客的其他文章。








发表评论 取消回复