描述长度增益
在这个网站有篇详细的论文介绍:Improving Chinese word segmentation with description length gain. / Kit, Chunyu; Zhao, Hai.
地址:https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.298.3906&rep=rep1&type=pdf
相关介绍如下:




翻译过来就是:
无监督分词策略必须遵循一些预定义的标准来识别单个单词。在[20]中可以发现使用互信息(MI)进行这方面的早期研究。一大把文章都使用了MI等统计方法[3,21,5,26,27]。描述长度增益(DLG),如
[9,7]测量从语料库中提取子串作为单词的压缩效果,是无监督词发现的另一个经验准则。
理论上,它源自于最小描述长度(minimum description length, MDL)参考[15,16]。本文在[8]中初步研究了该方法在检测非词汇类词汇方面的潜力。DLG是从一个语料中提取所有出现的子字符串
(也可以表示为
),得到词汇V,作为一个词被定义为:
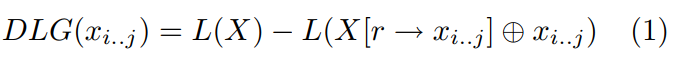
在这里代表的是用一个新的符号 r 贯穿整个X替换所有
子字符串,
代表的是两个字符串的连接。
代表的是可以用Shannon-Fano码或Huffman码估计的以比特为单位的语料库的经验描述长度,如下所示,遵循经典信息论[18,4]:
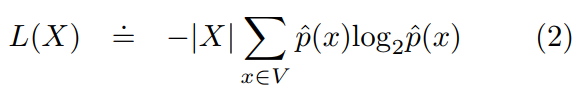
在这里 |.| 代表的是字符串的长度,![]() 是 x 在 X 中的频率。
是 x 在 X 中的频率。
使用DLG的无监督分割是为了推断出输入的DLG和最大的子串的最优序列。原则上,单词发现中不应该放弃DLG为负的子串,因为它可以是最优序列[9]之一。然而,由于将DLG集成到CWS的CRF建模中较为简单,本研究只考虑DLG值为正的子串。
到这里,DLG便介绍完了。但是由于英文水平与专业能力有限,可能会产生误解或者歧义,还望各位大佬指出谢谢!
举个栗子:X=“我爱伟大祖国” ,假设下标从0开始,则 =“伟大祖国”,
="我爱 r " ,
=“我爱 r 伟大祖国”,好像做了一件这样的事:使用字符 r 替换所有指定子字符后在末尾加上
,这样理解不知道有没有错。然后计算
,看了这里的
感觉有点像哈夫曼编码求平均编码长度,乘以 |X| = 6 得到的就可以理解为使用哈夫曼编码这句话的编码长度,V=“伟大祖国” ,x="伟"时 ,
![]() =1/6 , 类似地分别代入 x= 大、祖、国,相乘累加之后再乘以 -|X| 即为L(X) 。DLG难道就是语料哈夫曼平均编码长度 减去 替换后末尾加上子序列语料的平均编码长度?
=1/6 , 类似地分别代入 x= 大、祖、国,相乘累加之后再乘以 -|X| 即为L(X) 。DLG难道就是语料哈夫曼平均编码长度 减去 替换后末尾加上子序列语料的平均编码长度?
那么DLG的实际意义是什么呢?不妨先从信息增益开始,因为DLG也算是个增益,也许能找到一些共性。
我们知道熵是事件不确定性的度量:
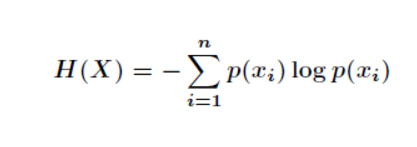
条件熵是在发生x事件的条件下发生y事件的不确定性的度量:
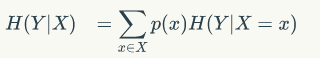
信息增益就是: 即为在一个条件下,随机变量的不确定性。如果Y是一个很有用的信息,那么条件熵就会很小,因为提供的信息很有用则不确定性很变小,则信息增益比较大。如果提供的信息很冗余,条件熵的不确定性几乎不变会比较大,则信息增益比较小。综上所述,若信息增益大的话,则提供的Y很关键,反之信息增益小提供的Y很多余。
实际意义?实际上编码长度也可以看作为信息量,然而信息熵代表的是对随机变量的不确定性,在信息论中反复强调信息熵不是信息量,其实说到底信息熵越大不确定性越大所蕴含的信息越多,即状态越混乱。在中文分词中,如果按字记忆一篇文章肯定比按词记忆要难,按字记忆的信息熵大于按词记忆的信息熵。因此我们要追求最小信息熵,一种完美的分词手法它的信息熵总是最小的。所以编码长度在这里可以理解为是信息量,我们需要寻找某种分词手法使得编码长度最小。我们把子序列字符串替换成 r ,其实我们是在把 子序列看作为一个整理词汇 r ,我们希望 r 确实是一个词,那么编码长度将会减少,描述长度增益DLG将为正值(代表将子序列字符串看作为词之后编码长度下降了)。若DLG为负值,那么则认为将 r 看作为一个词之后,总编码长度变大了。我们追求的是最小编码长度!因此此方法可以分词!至于为什么替换为 r 之后末尾还要连接子序列字符串还没有想明白,若有朋友想明白了方便的话告知一下,谢谢!
最后
以上就是痴情黑裤最近收集整理的关于描述长度增益(Description length gain)的全部内容,更多相关描述长度增益(Description内容请搜索靠谱客的其他文章。








发表评论 取消回复