那些机器学习中无法衍生的强规则变量有吗?
无论是传统的LR算法,以及XGB等机器学习算法,如果是基于机器算衍生而组合出来的变量,更多地是模型和机器反哺给模型/算法工程师的结果。
一.机器学习所衍生的各种变量维度
机器学习当然是有用的,他能通过机器学习算法的优越性找出特征的阈值和关联性。在笔者之前碰到的每天几十万个进件量的场景下,依靠审批进行每个件的批核显然已经是不现实,依靠简单的算法也衍生不出复杂的特征组合,但机器学习却可以做到,凭着机器学习可以找出更多关联的特征。
以之前某项目中运用机器学习的跑出来的特征为例,我们训练出来的机器学习的特征有以下维度:
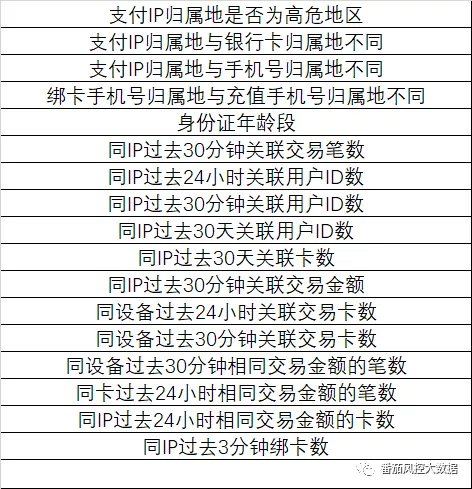
这里所罗列的特征,大都是基于行为跟设备数据衍生的变量,维度大都清晰也不难解读。另外跟设备数据相关的,我们还有用户维度和行为的组合:年龄+性别+行为数据,这一类衍生的数据在互金上也尚可接受,但部分通过机器学习衍生的变量有时却不敢恭维,如身高+血型+还款行为,这类变量上线到策略端,作为CRO,你是否敢启用此策略?
二.机器学习能否大幅度替代现有的数据分析方法
机器学习虽然在处理大数据有着传统分析方法无法媲美的优越性,但是能用机器学习代替目前传统的数据分析的方法吗?有没有一些机器学习也无法衍生的强规则变量呢?先别急着回答,我们先来看看之前根据行业经验所分析的数据维度。
比如有一个变量叫:循环信贷用卡量占所有用卡量的比例,这个变量用机器学习的方法能衍生吗。肯定能衍生,但也不一定能衍生。为什么这么说?请听我细细说来。
首先要说清楚这个问题,我们需要先看下这个变量是否是一个好变量?
a.如何判断变量是否是一个好的变量
好的变量必须具有识别度。一个有识别度的变量,前期就能通过这个变量将不同的层次的客群分级。什么意思?比如对于职业这个变量,如果它是一个好变量,首先在坏账率的表现上是有区分。假设我们认定学生和白领人士的行为模式是同质的,其坏账率表现的曲线应该是两条平行线(平行线表明学生和职业人士的坏账水平可以是不一样的,但其模式和趋势是一样的)。
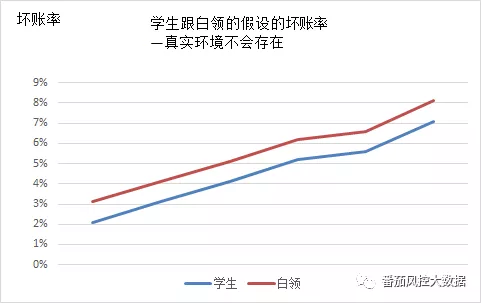
但在实际的坏账的表现上,我们却很少发现这两个职业的坏账会出现同态化,也就是类似的坏账的表现曲线。
为什么不会出现同样的表现曲线呢?
因为学生由于没有稳定收入来源,而职业人士往往有稳定收入,这两类是天然不同的客群。
所以在做模型的时候,职业是一个不错的入模维度。甚至应该做好客群分层后再开发模型。
接着我们再来看一下,开篇所提到的循环信贷用卡量占所有用卡量的这个变量。为什么说它是机器学习能衍生的变量,但却不一定能衍生的变量呢?
还是以职业这个维度说明。我们在对两类客群进行数据分析,获得其循环信贷用卡量占所有用卡量跟坏账率的关系中,会得到以下的分析图表:
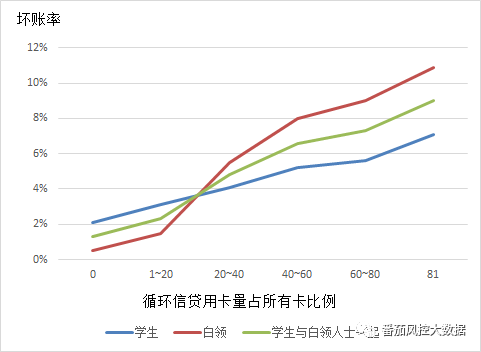
从图中我们可以发现尽管随着循环信贷比例的上升,坏账率均呈上升之势,但学生和白领人士的坏账率曲线是交叉的,学生的坏账率起点较高,但上升趋势缓慢,而白领的坏账率起点较低,但随着循环信贷比例上升而迅速上升。
原因是什么?我们刚才也提到了学生由于没有稳定收入来源,往往更多使用循环信贷,而循环信贷是需要付高额利息的,比例高是比较正常现象,并不一定表明风险程度的大幅度增加;而白领往往有稳定收入,一般不太愿意为循环信贷付高额利息,所以循环信贷比例的上升表明了风险程度的较大幅度的增加。
所以通过用循环信贷用卡量的这个变量,我们就能将不同客群的风险表现筛选,这个变量对客群的区分度绝对高,按照数据指标IV至少得在0.2以上。
b.接着咱们再来回答下为什么该变量机器学习能衍生,但也不定能衍生
机器学习我们称之为大数据分析工具,既然是工具肯定是有弊有利。杀鸡焉用牛刀,切菜我们使用菜刀。每一样工具肯定是适合某个场景或解决某样问题的。
就比如我们这里提到的这个变量循环信贷用卡量使用率的这个变量,他的计算公式非常简单,就是使用循环信贷用卡量除去总的用卡量就行了,区区一个除法公式,衍生规则非常简单,用普通的数学方法都可以完成,压根不需要机器学习算法。所以用随便的一个计算器都能造这个逻辑运用,衍生的规则真的不难。
但它也是最难的,难在哪里?在对变量的梳理上,这个反而是最难的。在原始的变量清单中,我们需要完成以下几个步骤才能识别出数据中哪个卡是属于循环卡:
1.在所有的变量中识别出哪些是属于卡的数据(除了卡的数据,还有各种贷款数据:房贷、车贷等等);
2.在1的基础上,筛选出来卡的数据后,后续我们需要弄清楚哪些卡是属于循环卡,哪些卡是属于非循环卡。这里就需要我们能辨别循环卡有哪些特征,非循环卡又有哪些特征,而这非常考验业务能力;
3.需要用到时间维度,取多长时间的切片是合适的?一个月,三个月还是半年,之后再结合时间切片计算循环卡的使用率情况;
4.最后一步才是在2跟3的基础上,结合1,进行计算。
所以你说以上4点全部完成,难吗?难也不难,不难也难。不难是建立在熟知业务的基础上才能完成轻松的取数,难是如果只有机器学习的知识远远不够,因为你只懂数,不懂业务之间的关联,算法模型落地效果肯定也不好。
所以机器学习虽好,衍生的维度也多,但如果一些真正好用的特征需要深入业务的前线去理解并衍生。而这需要有一定的深厚的行业经验,才能了解其中一些有效的维度。
最后回归到今天文章中所提到:那些机器学习中无法衍生的强规则变量有吗?目前来看还是有。
我们以中国的一句老话结束今天的文章: 大道至简,繁在人心。也有一句鸡汤文字送给所有阅读本文的读者:把多余的东西倒掉,才能把空间留给美好;把烦恼的事情放下,才能让生活惬意轻松!希望大家简单快乐过好每一天~
作者简介:专注于风控知识与技能分享,微信公号【番茄风控大数据】,欢迎关注!
最后
以上就是柔弱彩虹最近收集整理的关于那些机器学习中无法衍生的强规则变量有吗?的全部内容,更多相关那些机器学习中无法衍生内容请搜索靠谱客的其他文章。








发表评论 取消回复