我是靠谱客的博主 称心保温杯,这篇文章主要介绍机器学习 day5 & day6 分类问题实战:判断是否为羊毛党合并用户表和现金表,过滤掉没有钱包事件的用户数据探索构造模型需要的特征保存模型预测数据,现在分享给大家,希望可以做个参考。
判断是否为羊毛党
- 合并用户表和现金表,过滤掉没有钱包事件的用户
- 合并总表
- 取出有用的列
- 修正时间格式
- 将表分开成羊毛党用户(invalid)的行为和非羊毛用户(valid)的行为
- 数据探索
- 同parentID下的用户操作时间对比
- 同parentID下的子用户数
- 不同用户的操作间隔
- 不同用户的钱包金额
- 构造模型需要的特征
- 特征1,'amount' 用户钱包操作的最大金额
- 特征2,'coinType' 是否是silver
- 特征3,'isPayOneForLevelTwo' 是否为1
- 特征4,'sisters' ,同parentId下的用户数
- 特征5,'sametime_' 用户交易行为7天内,同个parentID下的交易用户数
- 将特征2与3整合成为一个'isPayOneForLevelTwo_or_coinType'
- 特征6,'max_time'
- 选取特征
- 样本均衡 下采样
- 建模
- XGB
- 保存模型
- 预测数据
合并用户表和现金表,过滤掉没有钱包事件的用户
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
cash = pd.read_csv('cash.csv')
cash.head()
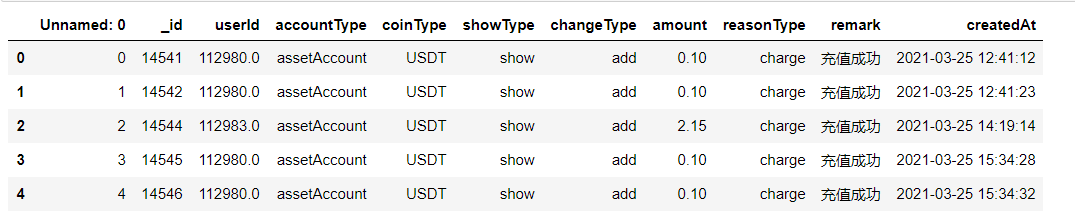
user = pd.read_csv('user.csv',encoding='gbk')
user.head()
合并总表
df = pd.merge(cash,user,left_on='userId',right_on='_id',how='inner')
取出有用的列
data = df[['userId', 'accountType', 'coinType',
'showType', 'changeType', 'amount', 'reasonType',
'createdAt_x','createdAt_y', 'phone', 'parentId',
'role', 'isPayOneForLevelTwo',
'isQuitBusinessMan', 'accessStatus', 'status',
'phoneAccessStatus', 'levelName', 'teamPower']]
修正时间格式
data['createdAt_x']=pd.to_datetime(data['createdAt_x'])
将表分开成羊毛党用户(invalid)的行为和非羊毛用户(valid)的行为
invalid = data[data['status']=='inValid']
valid = data[data['status']=='valid']
user.status.value_counts()
"""
valid 73686
inValid 23903
Name: status, dtype: int64
"""
数据探索
同parentID下的用户操作时间对比
time_diff = (invalid.groupby('parentId')['createdAt_x'].max()-invalid.groupby('parentId')['createdAt_x'].min()).dt.days
time_diff2 = (valid.groupby('parentId')['createdAt_x'].max()-valid.groupby('parentId')['createdAt_x'].min()).dt.days
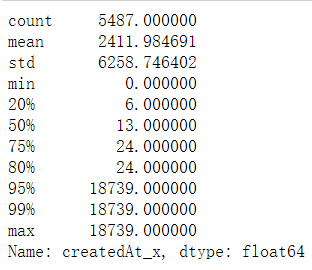
羊毛党用户,同个parentID 的账号操作时间范围。
同parentID的羊毛党多个用户的操作时间,80%都在7天内
time_diff.describe(percentiles=[0.75,0.8,0.95,0.99])

非羊毛党用户80%都在6天以上
time_diff2.describe(percentiles=[0.2,0.75,0.8,0.95,0.99])
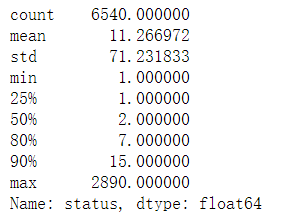
同parentID下的子用户数
非羊毛用户,同parentID 下的用户数50%在2以内
user[user['status']=='valid'].groupby('parentId')['status'].count().describe([0.25,0.5,0.8,0.9])
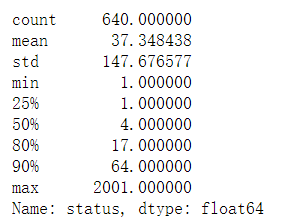
羊毛用户均值37,中位数4,说明整体分布右偏,50%都在4以上
user[user['status']=='inValid'].groupby('parentId')['status'].count().describe([0.25,0.5,0.8,0.9])
不同用户的操作间隔
80%羊毛用户操作间隔在2天内
(invalid.groupby('userId')['createdAt_x'].max()-invalid.groupby('userId')['createdAt_x'].min()).dt.days.describe()
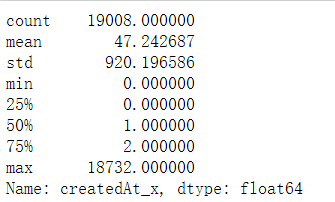
70非羊毛用户操作间隔大于2天
(valid.groupby('userId')['createdAt_x'].max()-valid.groupby('userId')['createdAt_x'].min()).dt.days.describe([0.2,0.3,0.4,0.5,0.8,0.9])

不同用户的钱包金额
非羊毛
valid.amount.describe(percentiles=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9])
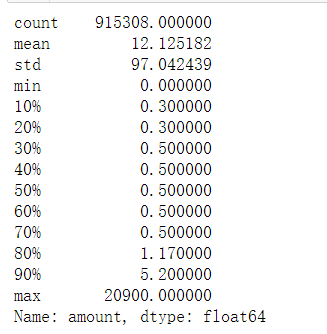
羊毛
invalid.amount.describe(percentiles=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9])
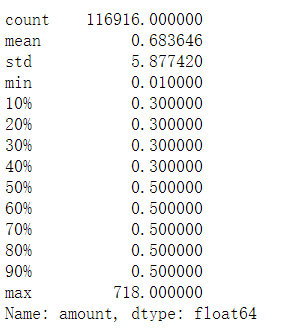
结论:
羊毛与非羊毛用户的钱包操作金额,少数非羊毛用户的钱包操作金额有高金额,
其他并无明显差距
构造模型需要的特征
clean = data[['userId','parentId','amount','coinType', 'createdAt_x','isPayOneForLevelTwo','status']]
max_time = pd.DataFrame(clean.groupby('userId')['createdAt_x'].max())
特征1,‘amount’ 用户钱包操作的最大金额
max_amount = pd.DataFrame(clean.groupby('userId')['amount'].max())
max_amount
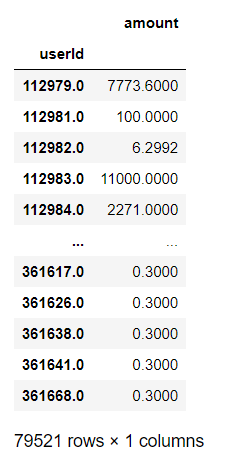
max_time['amount']=max_amount['amount']
特征2,‘coinType’ 是否是silver
silver用户一定为非羊毛用户
clean['coinType']=(clean['coinType']=='silver')*1
coin = pd.DataFrame(clean.groupby('userId')['coinType'].max())
max_time['coinType'] =coin['coinType']
max_time
特征3,‘isPayOneForLevelTwo’ 是否为1
user_ = user[['_id','parentId','isPayOneForLevelTwo','status']]
user_
特征4,‘sisters’ ,同parentId下的用户数
Child_id = pd.DataFrame(user.groupby('parentId',as_index=False)['_id'].count(),columns=['parentId','_id'])
user_C = pd.merge(user_,Child_id,on = 'parentId')
user_C.columns = ['userId','parentId','isPayOneForLevelTwo','status','sisters']
user_C
特征5,‘sametime_’ 用户交易行为7天内,同个parentID下的交易用户数
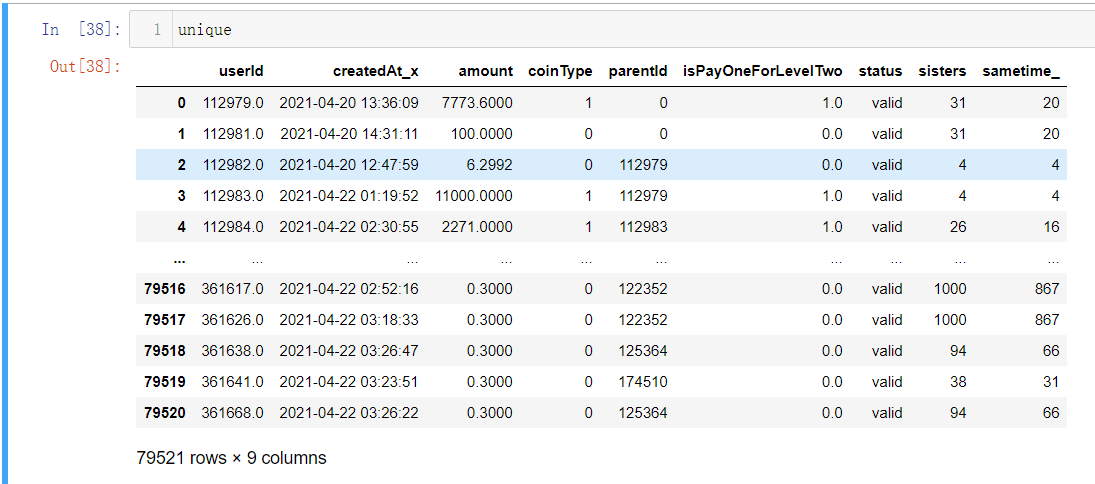
unique = max_time.reset_index()
unique = pd.merge(unique,user_C)
交易行为以及用户表合并后的表格
unique
valid = unique[unique['status']=='valid'] # 非羊毛党
invalid = unique[unique['status']=='inValid'] # 羊毛党
羊毛用户的有关联的账号数的分布
invalid.sisters.describe()
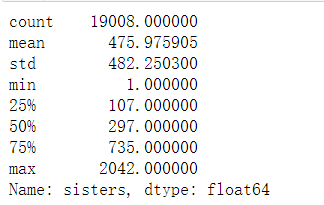
非羊毛用户的有关联的账号数的分布
valid.sisters.describe()

import datetime
data['time_min'] = data['createdAt_x']-datetime.timedelta(days=7)
data['time_max'] = data['createdAt_x']+datetime.timedelta(days=7)
"""
运行时间3hours
本次结果,已经保存.
计算每次钱包有事件发生时,7天内同parentID 下发生钱包事件的关联账号数
"""
# sametime_ = []
# for i in range(data.shape[0]):
# parent = data.loc[i,'parentId']
# sametime_users = len(data[(data['createdAt_x']<time_max[i])&(data['createdAt_x']>time_min[i])&(data['parentId']==parent)]['userId'].unique())
# sametime_.append(sametime_users)
# print(i)
#data['sametime_'] = np.array(sametime_)
# data.to_csv('cleaned_data.csv')
读取该文件
data = pd.read_csv('cleaned_data.csv')
data.head()
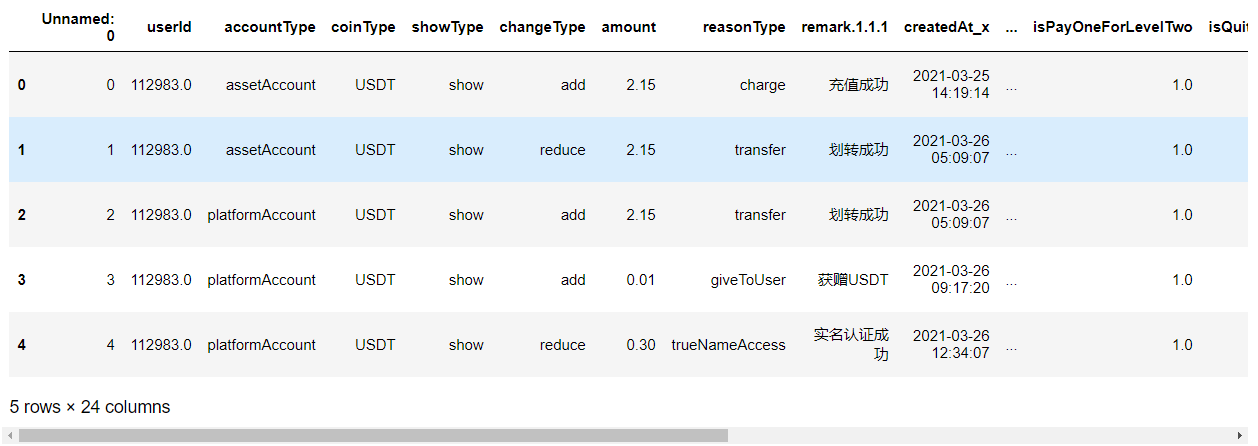
取最大的7天内在线的关联账号数
unique['sametime_'] = data.groupby('userId')['sametime_'].max().values
将特征2与3整合成为一个’isPayOneForLevelTwo_or_coinType’
unique['isPayOneForLevelTwo_or_coinType'] = ((unique['coinType']==1)|(unique['isPayOneForLevelTwo']==1))*1
data['createdAt_x']=pd.to_datetime(data['createdAt_x'])
特征6,‘max_time’
max_time = pd.DataFrame((data.groupby('userId')['createdAt_x'].max()-data.groupby('userId')['createdAt_x'].min()).dt.days)
unique.head()

unique_ =pd.merge(unique,right=max_time,left_on='userId',right_index=True)
unique_.columns
"""
Index(['userId', 'createdAt_x_x', 'amount', 'coinType', 'parentId',
'isPayOneForLevelTwo', 'status', 'sisters', 'sametime_',
'isPayOneForLevelTwo_or_coinType', 'createdAt_x_y'],
dtype='object')
"""
选取特征
final_data = unique_[['amount','isPayOneForLevelTwo_or_coinType','sisters','sametime_','createdAt_x_y','status']]
final_data.status.value_counts()
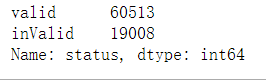
样本均衡 下采样
## 下采样
data_val = final_data[final_data.status == 'valid'].sample(n=30000)
data_inva = final_data[final_data.status == 'inValid']
data_ = pd.concat([data_val,data_inva],axis=0)
X = data_[['amount','isPayOneForLevelTwo_or_coinType','sisters','sametime_','createdAt_x_y']]
y = data_['status']
X.head()
建模
from sklearn.model_selection import train_test_split
xtrain,xtest,ytrain,ytest = train_test_split(X,y)
XGB
from xgboost import XGBClassifier
from sklearn.metrics import classification_report
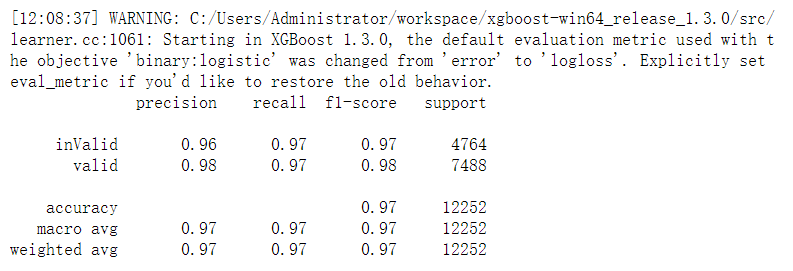
xgb = XGBClassifier().fit(xtrain,ytrain)
print(classification_report(ytest,xgb.predict(xtest)))
xgb.predict_proba(xtest)
第一列代表inValid的概率(羊毛党)
第二列代表valid的概率(非羊毛党)

[*zip(xgb.feature_importances_,data_.columns)]

保存模型
import joblib
joblib.dump(xgb,"xgboost.dat")
loaded_model = joblib.load("xgboost.dat")
预测数据
预测所有用户羊毛党的行为
final_data['userId']= unique['userId']
final_data['ProbabilityForInvalid']= xgb.predict_proba(final_data[['amount','coinType','isPayOneForLevelTwo','sisters','sametime_']])[:,0]
结果保存到本地
final_data.to_csv('羊毛党结论.csv')
最后
以上就是称心保温杯最近收集整理的关于机器学习 day5 & day6 分类问题实战:判断是否为羊毛党合并用户表和现金表,过滤掉没有钱包事件的用户数据探索构造模型需要的特征保存模型预测数据的全部内容,更多相关机器学习内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复