点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达作者丨zzq
来源丨https://zhuanlan.zhihu.com/p/68411179
编辑丨极市平台
仅作学术分享,不代表本公众号立场,侵权联系删除
CNN基本部件介绍
1. 局部感受野
在图像中局部像素之间的联系较为紧密,而距离较远的像素联系相对较弱。因此,其实每个神经元没必要对图像全局进行感知,只需要感知局部信息,然后在更高层局部信息综合起来即可得到全局信息。卷积操作即是局部感受野的实现,并且卷积操作因为能够权值共享,所以也减少了参数量。
2. 池化
池化是将输入图像进行缩小,减少像素信息,只保留重要信息,主要是为了减少计算量。主要包括最大池化和均值池化。
3. 激活函数
激活函数的用是用来加入非线性。常见的激活函数有sigmod, tanh, relu,前两者常用在全连接层,relu常见于卷积层
4. 全连接层
全连接层在整个卷积神经网络中起分类器的作用。在全连接层之前需要将之前的输出展平
经典网络结构
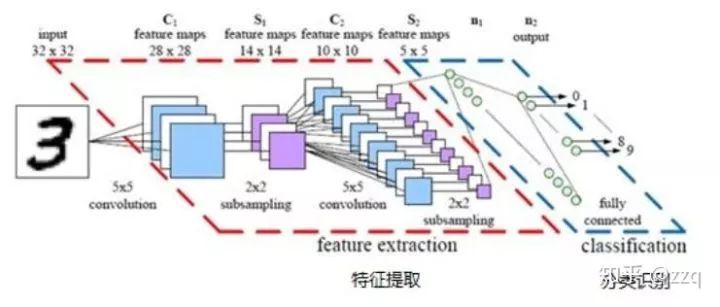
1. LeNet5
由两个卷积层,两个池化层,两个全连接层组成。卷积核都是5×5,stride=1,池化层使用maxpooling
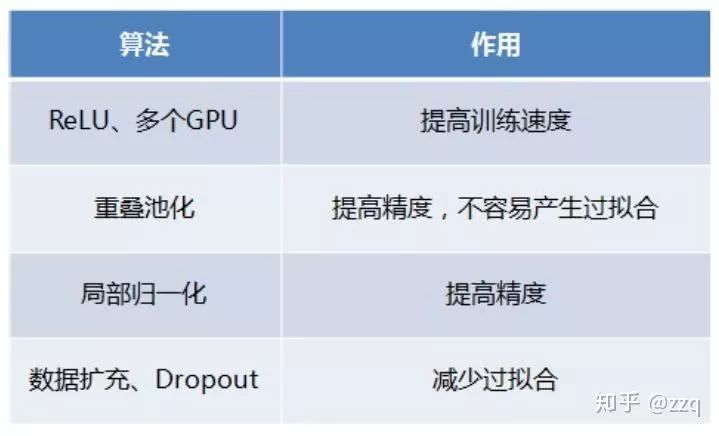
2. AlexNet
模型共八层(不算input层),包含五个卷积层、三个全连接层。最后一层使用softmax做分类输出
AlexNet使用了ReLU做激活函数;防止过拟合使用dropout和数据增强;双GPU实现;使用LRN

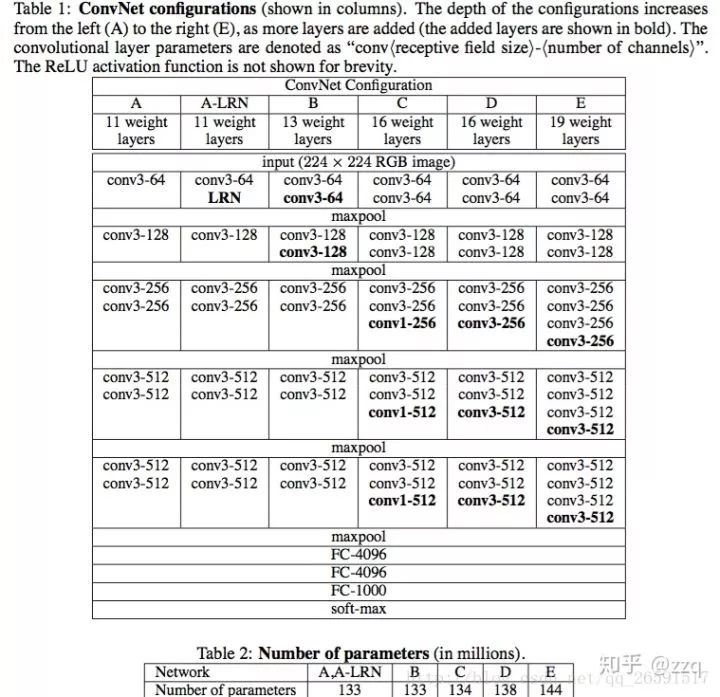
3. VGG
全部使用3×3卷积核的堆叠,来模拟更大的感受野,并且网络层数更深。VGG有五段卷积,每段卷积后接一层最大池化。卷积核数目逐渐增加。
总结:LRN作用不大;越深的网络效果越好;1×1的卷积也很有效但是没有3×3好
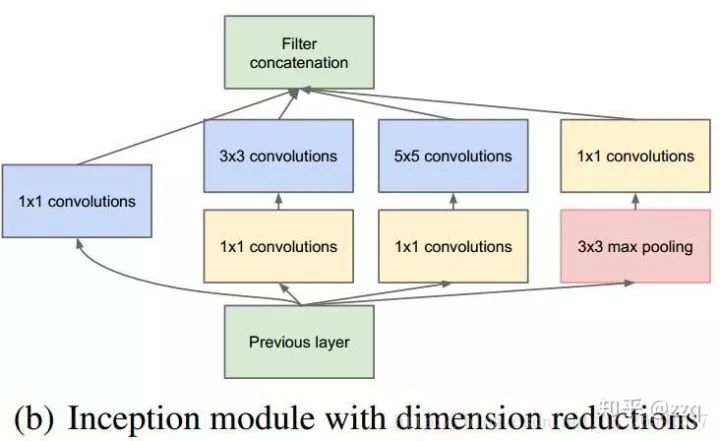
4. GoogLeNet(inception v1)
从VGG中我们了解到,网络层数越深效果越好。但是随着模型越深参数越来越多,这就导致网络比较容易过拟合,需要提供更多的训练数据;另外,复杂的网络意味更多的计算量,更大的模型存储,需要更多的资源,且速度不够快。GoogLeNet就是从减少参数的角度来设计网络结构的。
GoogLeNet通过增加网络宽度的方式来增加网络复杂度,让网络可以自己去应该如何选择卷积核。这种设计减少了参数 ,同时提高了网络对多种尺度的适应性。使用了1×1卷积可以使网络在不增加参数的情况下增加网络复杂度。
Inception-v2
在v1的基础上加入batch normalization技术,在tensorflow中,使用BN在激活函数之前效果更好;将5×5卷积替换成两个连续的3×3卷积,使网络更深,参数更少
Inception-v3
核心思想是将卷积核分解成更小的卷积,如将7×7分解成1×7和7×1两个卷积核,使网络参数减少,深度加深
Inception-v4结构
引入了ResNet,使训练加速,性能提升。但是当滤波器的数目过大(>1000)时,训练很不稳定,可以加入activate scaling因子来缓解
5. Xception
在Inception-v3的基础上提出,基本思想是通道分离式卷积,但是又有区别。模型参数稍微减少,但是精度更高。Xception先做1×1卷积再做3×3卷积,即先将通道合并,再进行空间卷积。depthwise正好相反,先进行空间3×3卷积,再进行通道1×1卷积。核心思想是遵循一个假设:卷积的时候要将通道的卷积与空间的卷积进行分离。而MobileNet-v1用的就是depthwise的顺序,并且加了BN和ReLU。Xception的参数量与Inception-v3相差不大,其增加了网络宽度,旨在提升网络准确率,而MobileNet-v1旨在减少网络参数,提高效率。
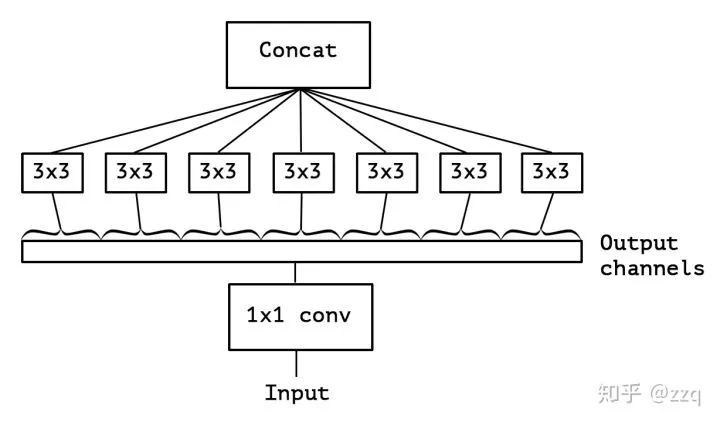
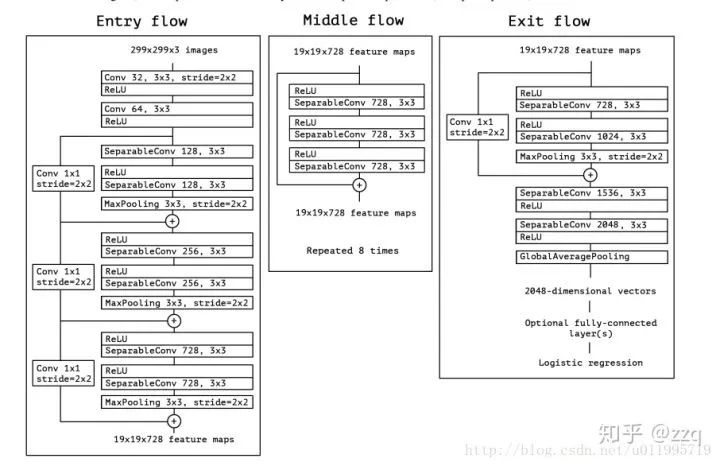
6. MobileNet系列
V1
使用depthwise separable convolutions;放弃pooling层,而使用stride=2的卷积。标准卷积的卷积核的通道数等于输入特征图的通道数;而depthwise卷积核通道数是1;还有两个参数可以控制,a控制输入输出通道数;p控制图像(特征图)分辨率。

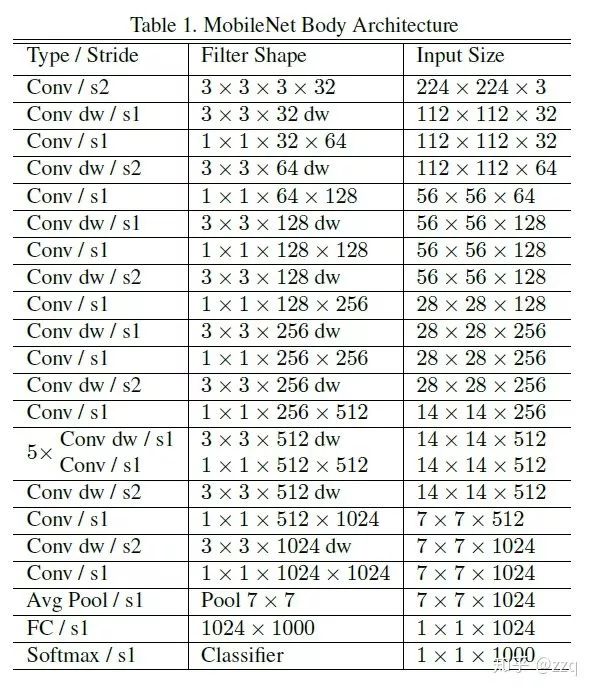
V2
相比v1有三点不同:1.引入了残差结构;2.在dw之前先进行1×1卷积增加feature map通道数,与一般的residual block是不同的;3.pointwise结束之后弃用ReLU,改为linear激活函数,来防止ReLU对特征的破环。这样做是因为dw层提取的特征受限于输入的通道数,若采用传统的residual block,先压缩那dw可提取的特征就更少了,因此一开始不压缩,反而先扩张。但是当采用扩张-卷积-压缩时,在压缩之后会碰到一个问题,ReLU会破环特征,而特征本来就已经被压缩,再经过ReLU还会损失一部分特征,应该采用linear。
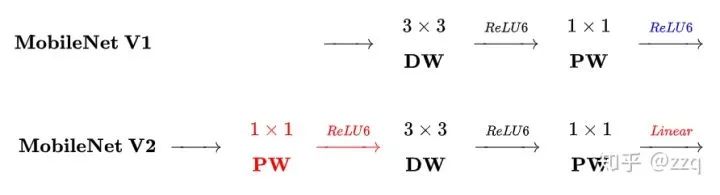
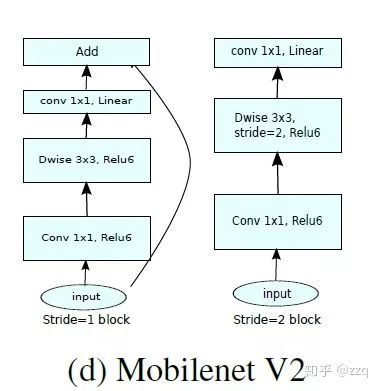
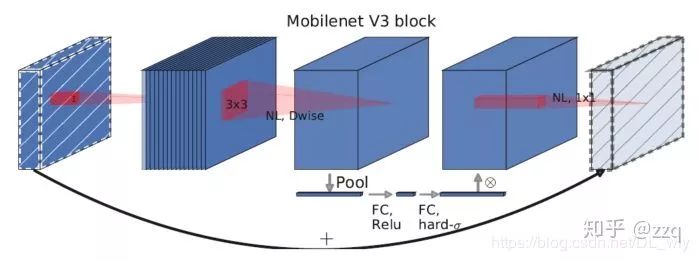
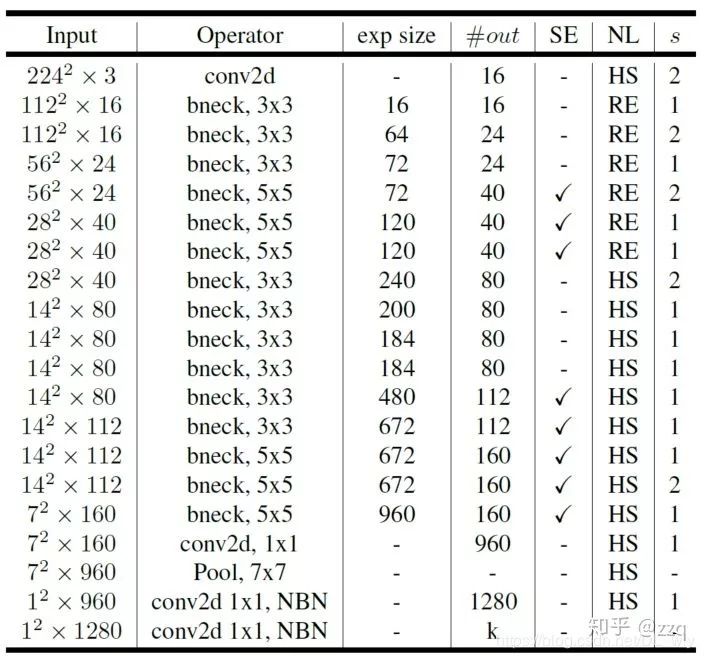
V3
互补搜索技术组合:由资源受限的NAS执行模块集搜索,NetAdapt执行局部搜索;网络结构改进:将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish激活函数,修改了开始的滤波器组。
V3综合了v1的深度可分离卷积,v2的具有线性瓶颈的反残差结构,SE结构的轻量级注意力模型。
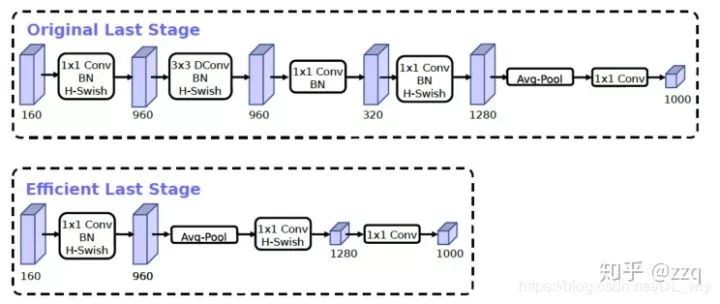
7. EffNet
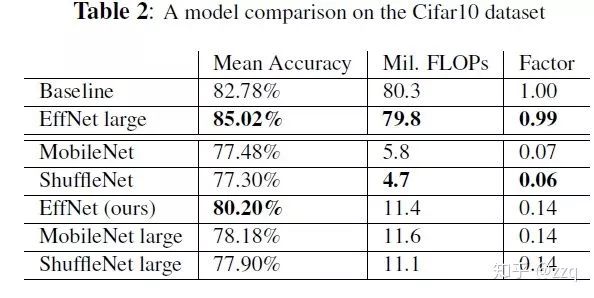
EffNet是对MobileNet-v1的改进,主要思想是:将MobileNet-1的dw层分解层两个3×1和1×3的dw层,这样 第一层之后就采用pooling,从而减少第二层的计算量。EffNet比MobileNet-v1和ShuffleNet-v1模型更小,进度更高。
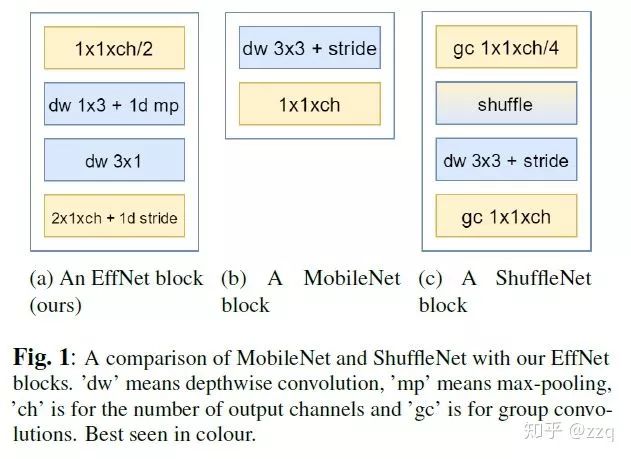
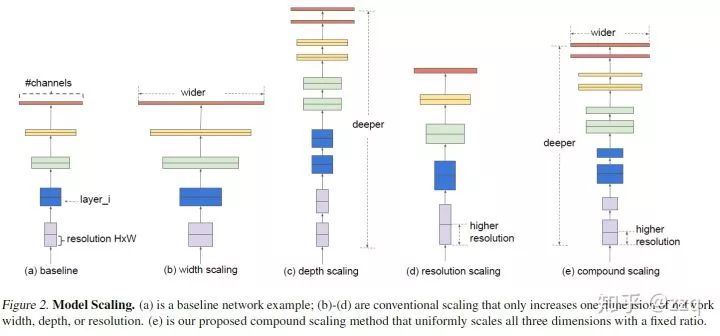
8. EfficientNet
研究网络设计时在depth, width, resolution上进行扩展的方式,以及之间的相互关系。可以取得更高的效率和准确率。
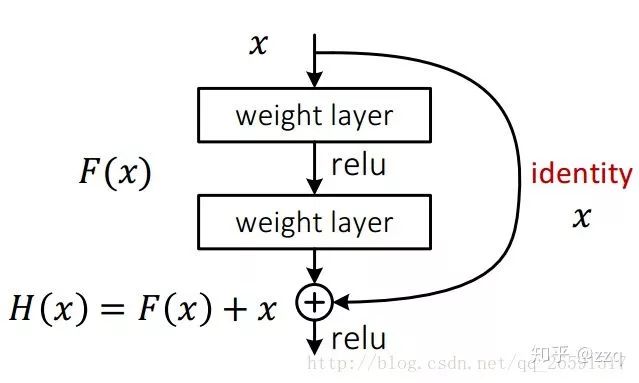
9. ResNet
VGG证明更深的网络层数是提高精度的有效手段,但是更深的网络极易导致梯度弥散,从而导致网络无法收敛。经测试,20层以上会随着层数增加收敛效果越来越差。ResNet可以很好的解决梯度消失的问题(其实是缓解,并不能真正解决),ResNet增加了shortcut连边。
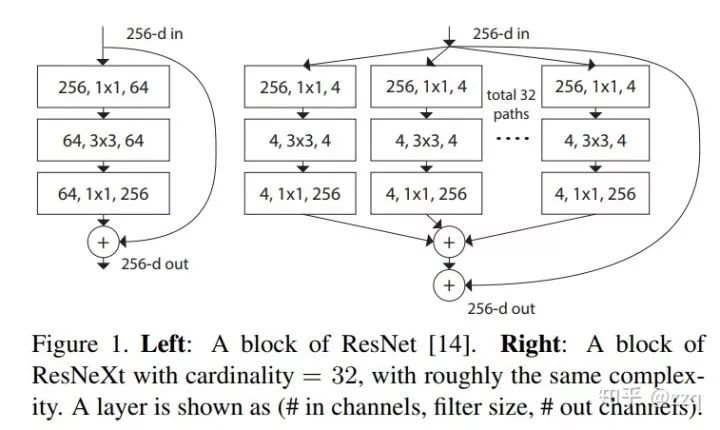
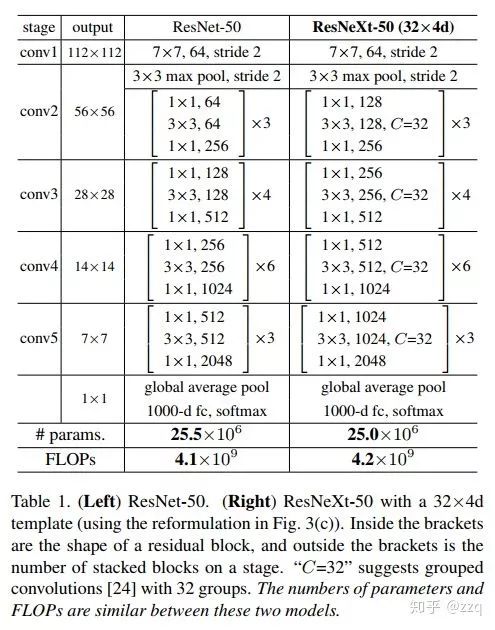
10. ResNeXt
基于ResNet和Inception的split+transform+concate结合。但效果却比ResNet、Inception、Inception-ResNet效果都要好。可以使用group convolution。一般来说增加网络表达能力的途径有三种:1.增加网络深度,如从AlexNet到ResNet,但是实验结果表明由网络深度带来的提升越来越小;2.增加网络模块的宽度,但是宽度的增加必然带来指数级的参数规模提升,也非主流CNN设计;3.改善CNN网络结构设计,如Inception系列和ResNeXt等。且实验发现增加Cardinatity即一个block中所具有的相同分支的数目可以更好的提升模型表达能力。
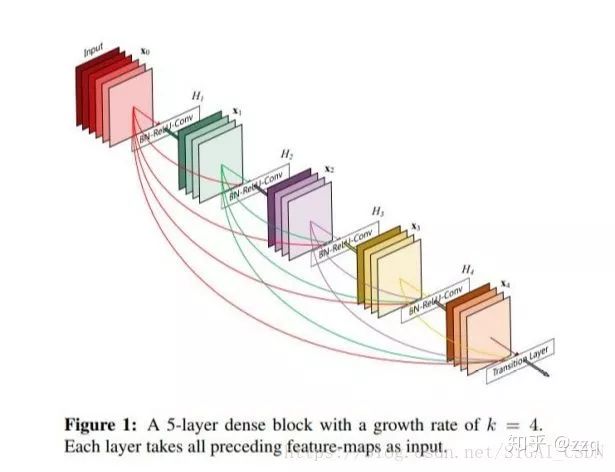
11. DenseNet
DenseNet通过特征重用来大幅减少网络的参数量,又在一定程度上缓解了梯度消失问题。
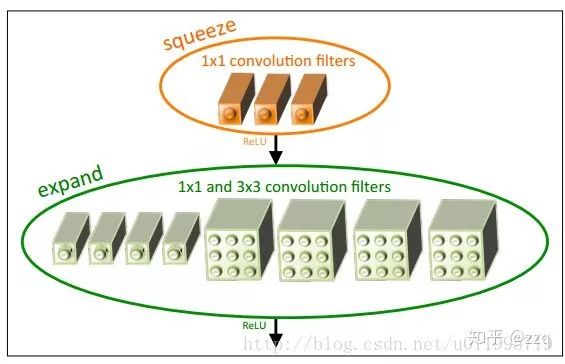
12. SqueezeNet
提出了fire-module:squeeze层+expand层。Squeeze层就是1×1卷积,expand层用1×1和3×3分别卷积,然后concatenation。squeezeNet参数是alexnet的1/50,经过压缩之后是1/510,但是准确率和alexnet相当。
13. ShuffleNet系列
V1
通过分组卷积与1×1的逐点群卷积核来降低计算量,通过重组通道来丰富各个通道的信息。Xception和ResNeXt在小型网络模型中效率较低,因为大量的1×1卷积很耗资源,因此提出逐点群卷积来降低计算复杂度,但是使用逐点群卷积会有副作用,故在此基础上提出通道shuffle来帮助信息流通。虽然dw可以减少计算量和参数量,但是在低功耗设备上,与密集的操作相比,计算、存储访问的效率更差,故shufflenet上旨在bottleneck上使用深度卷积,尽可能减少开销。
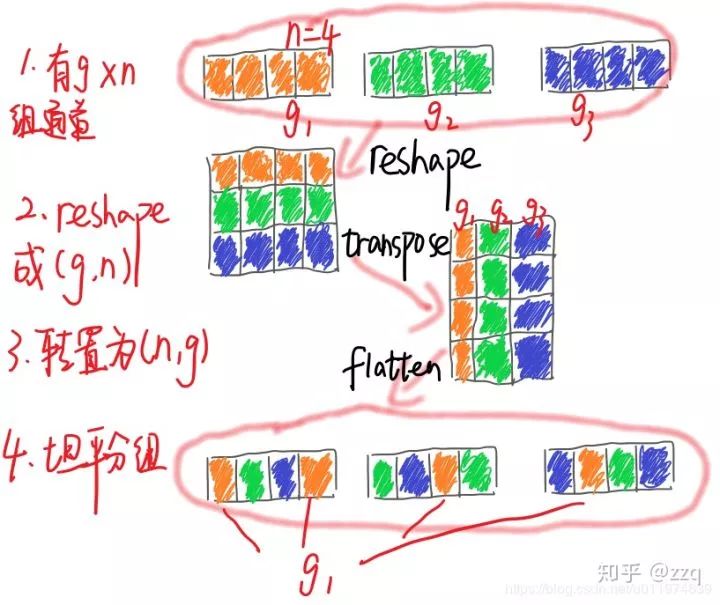
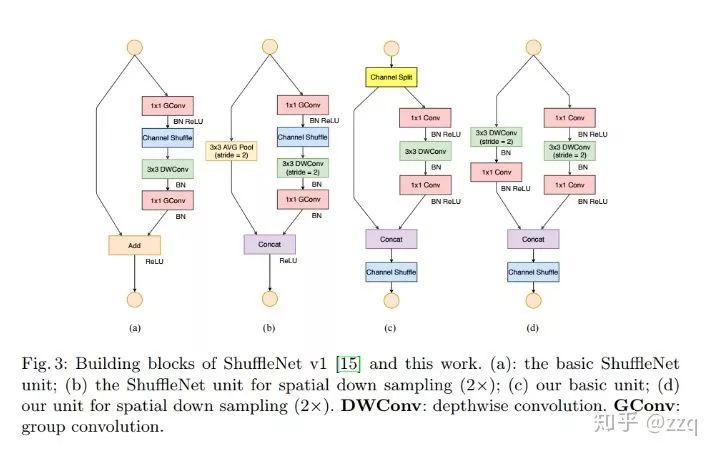
V2
使神经网络更加高效的CNN网络结构设计准则:
输入通道数与输出通道数保持相等可以最小化内存访问成本
分组卷积中使用过多的分组会增加内存访问成本
网络结构太复杂(分支和基本单元过多)会降低网络的并行程度
element-wise的操作消耗也不可忽略
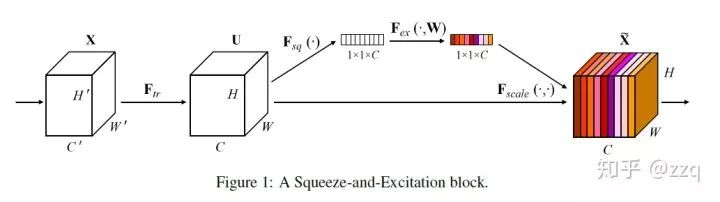
14. SENet
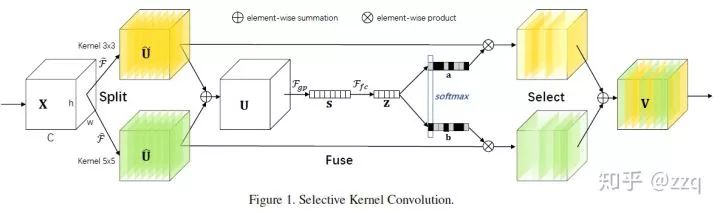
15. SKNet
好消息!
小白学视觉知识星球
开始面向外开放啦????????????

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~最后
以上就是淡定月饼最近收集整理的关于收藏 | CNN网络结构发展最全整理CNN基本部件介绍经典网络结构的全部内容,更多相关收藏内容请搜索靠谱客的其他文章。








发表评论 取消回复