统计研究可以分为实验性研究与观测性研究两类。在实验性统计研究中,数据是通过实验产生的。一项实验首先要从确定一个我们感兴趣的变量开始。然后确定并控制一个或多个其他变量,这些其他变量与我们感兴趣的变量是相关的;与此同时,收集这些变量如何影响我们感兴趣的那一个变量的数据。
在观测性研究中,我们经常是通过抽样调查,而不是控制一项实验来获取数据。一些好的设计原则仍然会得到使用,但严格控制一项实验性统计研究往往是不可能的。例如,在一项有关吸烟与肺癌之间关系的研究中,研
究人员不可能为实验性研究的对象指定其是否有吸烟嗜好。研究人员仅限于简单地观察吸烟对那些曾经吸烟的人的影响,以及不吸烟对那些已经不吸烟的人的影响。
三种类型的实验设计:完全随机化设计、随机化区组设计以及析因实验。方差分析( ANOVA)的统计方法能用于现有数据的分析。我们也可使用 ANOVA来分析通过观测性研究得到的数据。
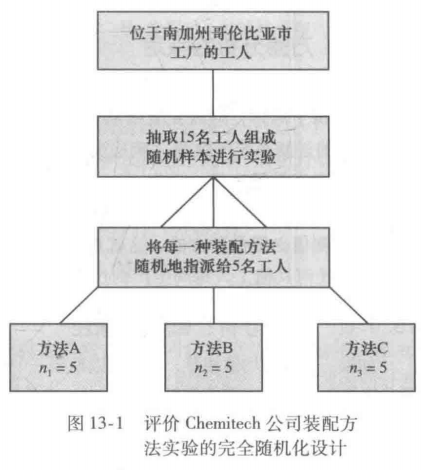
作为实验性统计研究的例子,我们考虑 Chemtech公司遇到的问题。 Chemtech公司开发了一种新的城市供水过滤系统。新过滤系统的部件需要从几家供应商处购买,然后由 Chemtech公司设在南加州哥伦比亚市的工厂装配这些部件。公司的工程部负责确定新过滤系统的最佳装配方法。考虑了各种可能的装配方法后,工程部将范围缩小至三种方法:方法A、方法B及方法C.这些方法在新过滤系统装配步骤的顺序上有所不同。 Chemtech公司的管理人员希望确定,哪种装配方法能使每周生产的过滤系统的数量最多。
在 Chemtech公司的实验中,装配方法是独立变量或因子( factor).因为对应于这个因子有三种装配方法,所以我们说这一实验有三个处理,每个处理( treatment)对应于三种装配方法中的一种。 Chemtech公司的问题是一个单因子实验( single- factor experiment)的实例,该问题只涉及一个定性因子(装配方法).更为复杂的实验可能由多个因子组成,其中有些因子可能是定性的,有些因子可能是定量的。
三种装配方法或处理确定了 Chemtech公司实验的三个总体。一个总体是使用装配方法A的全体工人,第二个总体是使用装配方法B的全体工人,第三个总体是使用装配方法C的全体工人。注意对每个总体,因变量或响应变量( response variable)是每周装配的过滤系统的数量,并且该实验的主要统计目的是,确定三个总体(三种方法)每周所生产的过滤系统的平均数量是否相同。
假设从 Chemtech公司生产车间的全体装配工人中抽取了三名工人组成一个随机样本。用实验设计的术语,三名随机抽取的工人是实验单元( experiment units).我们将在 Chemtech公司的问题中使用的实验设计被称为完全随机化设计( completely ran-domized design).这种类型的设计要求将每一种装配方法或处理随机地指派给一个实验单元或一名工人。例如,方法A可能被随机地指派给第二名工人,指派方法B给第一名工人,指派方法C给第三名工人。如同本例所解释的那样,随机化的概念是所有实验设计的一个重要原则。
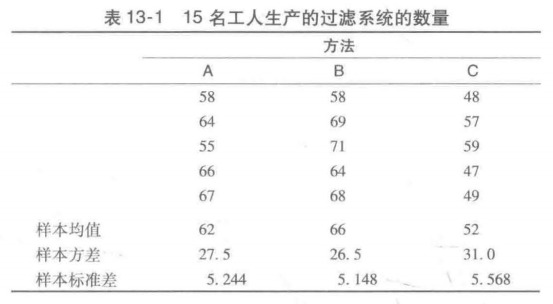
注意:这个实验对每个处理只会得到一个装配好的过滤系统的测度或数量。对于每种装配方法,为了得到更多的数据,我们必须重复或复制基本的实验过程。例如,假设我们不是只随机抽取3名工人,而是15名工人,然后对每一个处理随机地指派5名工人。因为每种装配方法都指派给5名工人,因此我们说得到了5个复制。复制的过程是实验设计的另一个重要原则。
收集数据
真正的问题是,观察到的三个样本均值之间的差异是否足够大,以致使我们能够得出结论,对应于三种装配方法的总体均值是不同的。为了用统计术语来描述这一问题,我们引入下列记号。

假设检验
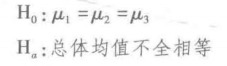
利用方差分析( ANOVA)这一统计方法可以确定,在三个样本均值之间观察到的差异是否足够大到可以拒绝H。
方差分析的假设
1.对每个总体,响应变量服从正态分布。这就意味着在 Chemtech公司的实验中,对于每一种装配方法,每周生产的过滤系统的数量(响应变量)必须服从正态分布。
2.响应变量的方差对所有总体都是相同的。这就意味着在 Chemtech公司的实验中,对于每一种装配方法,每周生产的过滤系统数量的方差必须是相同的。
3.观测值必须是独立的。这就意味着在 Chemtech公司的实验中,对于每名工人,每周生产的过滤系统的数量必须与任何其他工人每周生产的过滤系统的数量独立。
方差分析的概念性综述
三个样本的均值互相越接近,我们推断总体均值不等的证据就越缺乏说服力,即支持H0
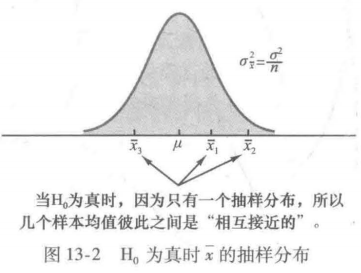
于是,如果原假设为真,我们可以把三个样本均值x1=62,x2=66,x3=52,都认为是从图13-2所示的抽样分布中随机抽取的数值。在这种情况下,三个样本均值x1、x2和x3的均值与方差可以用来估计该抽样
分布的均值与方差。在 Chemtech公司实验的例子中,x抽样分布的均值的一个估计值是(62+66+52)/3=60。我们称该估计值为总样本均值。
均值抽样分布的方差可以由三个样本均值的方差给出

该值被称为总体方差的处理间估计
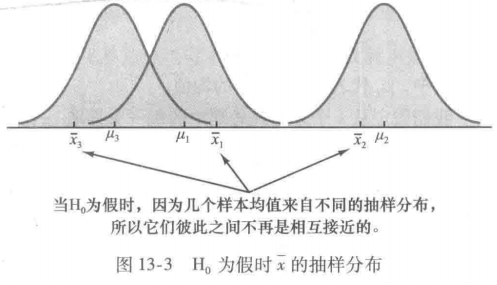
总体方差的处理间估计的根据是原假设为真。在这种情形下,每个样本都来自同一个总体,并且样本均值只有一个抽样分布。为了说明H0为假时发生了什么,假定总体均值全不相同。注意,由于三个样本分别来自均值不同的三个正态分布,因此将导致有三个不同的抽样分布。图13-3
表明在这种情形下,样本均值彼此之间不再像H0为真时那样接近了。于是,样本均值的方差将会变得比较大,从而使得总体方差的处理间估计也变得比较大。一般地,当总体均值不相等时,处理间估计将会高估总体方差。
每个样本内部的变异也会对我们得到的方差分析的结论产生影响。当我们从每一个总体中抽取一个随机样本时,每个样本方差都给出了总体方差的一个无偏估计。因此,我们可以将总体方差的个别估计组合或合并成一个总的估计。
用这种方法得到的总体方差的估计称为总体方差的合并估计或处理内估计。因为每个样本方差给出的总体方差的估计仅以每个样本内部的变异为依据,因此,总体方差的处理内估计不受总体均值是否相等的影响。当样本容量相等时,总体方差的处理内估计可以通过计算个别样本方差的算术平均值得到。对于 Chemtech公司实验的例子,我们有:
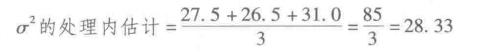
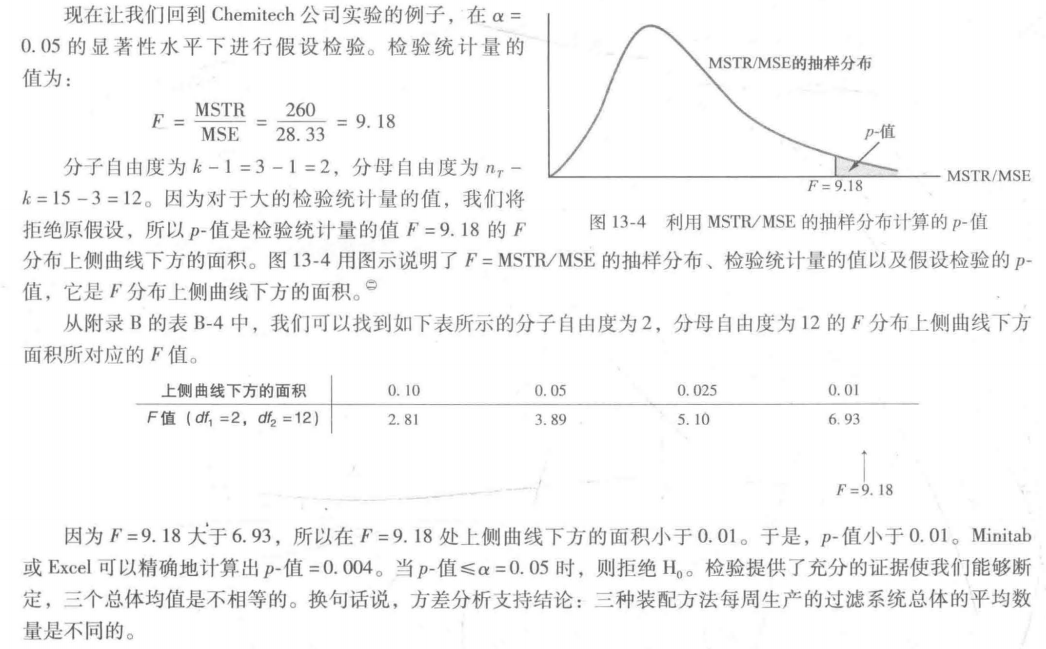
在 Chemtech公司实验的例子中,总体方差的处理间估计(260)远大于总体方差的处理内估计(28.33)。事实上,这两个估计量的比值为260/28.33=9.18。但是,我们回想起只有当原假设为真时,处理间估计方法才是总体方差的一个好的估计量;如果原假设为假,处理间估计方法将高估总体方差。不过在这两种情形下,处理内估计都是总体方差的一个好的估计量。
因此,如果原假设为真,则两个估计量应该很接近,并且它们的比值接近于1。如果原假设为假,则处理间估计将大于处理内估计,并且它们的比值也将是大的。在下一节我们将说明,为了拒绝H0,这个比值必须达到多大。
总的说来, ANOVA背后的逻辑以共同总体方差的两个独立的估计量为基础。总体方差的一个估计量是以样本均值之间的变异性为依据,总体方差的另一个估计量是以每个样本内部数据的变异性为依据。通过比较总体方差的这两个估计量,我们就能够确定总体均值是否相等。
方差分析和完全随机化实验设计

总样本均值的计算


总体方差的处理间估计
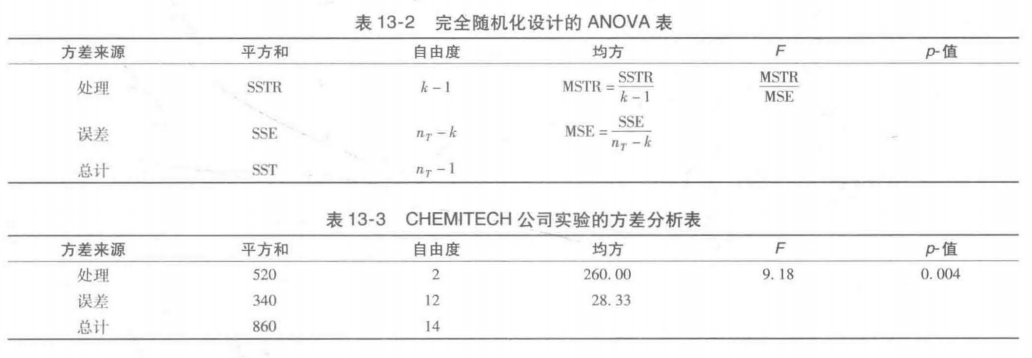
我们称总体方差的这个估计量为均方处理( mean square due to treatments,MSTR)。
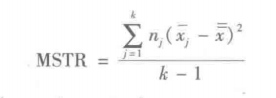
分子被称为处理平方和( sum of squares due to treatments,SsTR)。分母k-1表示与STR相联系的自由度。因此,均方处理也可以按以下公式计算。


总体方差的处理内估计
在上一节,我们介绍了总体方差的处理内估计的概念,并且说明了当样本容量相等时如何计算处理内估计。我们称a2的这个估计量为均方误差( mean square due to error,MsE)。MSE的一般公式为:

注意到MSE以每个处理内部的变异性为依据,不受原假设是否为真的影响。因此,MSE永远给出总体方差的一个无偏估计

方差估计量的比较:F检验


总结:

ANOVA表

多重比较方法
当我们应用方差分析方法检验k个总体均值是否相等时,拒绝原假设只能让我们得出k个总体的均值不全相等的结论。在某些情况下,我们希望再向前迈进一步,并确定在k个均值中到底哪几个均值之间存在差异。本节的目的是说明如何使用多重比较方法( multiple comparison procedures)在成对的总体均值之间进行统计比较。
Fisher的LSD方法



许多有实际经验的专业人员发现,通过判断样本均值之差的大小而决定是否拒绝H0更容易些。


注意,当样本容量相等时,只能计算出一个LSD的值。在这种情形下,我们可以简单地将任何两个样本均值之差的大小与LSD的值做比较。例如,总体1(方法A)与总体3(方法C)的样本均值之差为62-52=10,因为该差值比7.34大,这就意味着我们能够拒绝方法A与方法C每周生产的过滤系统总体的平均数量相等的原假设。类似地,由于总体2与总体3的样本均值之差为66-52=14>7.34,所以我们也能够拒绝方法B与方法C每周生产的过滤系统总体的平均数量相等的原假设。实际上,我们的结论是,方法A和方法B这两种装配方法每周生产的过滤系统总体的平均数量与方法C每周生产的过滤系统总体的平均数量均不相同。


第一类错误的概率
在每一种情形下,我们都使用α=0.05的显著性水平。因此,对每个检验,如果原假设为真,则犯第I类错误的概率为α=0.05,不犯第Ⅰ类错误的概率就是1-0.05=0.95.在讨论多重比较方法时,我们把这个第I类错误的概率(a=0.05)称为比较方式的第I类错误概率( comparisonwise Type I error rate).比较方式的第I类错误概率表示了与单个两两比较相联系的显著性水平。
现在我们考虑一个略为不同的问题。在进行三次成对的两两比较时,三次检验中至少有一次犯第I类错误的概率是多少?为回答这个问题,我们注意到三次检验都不犯第I类错误的概率为0.95×0.95×0.95=0.8574.因此,至少有一次犯第I类错误的概率为1-0.8574=0.1426.这样当我们用 Fisher的LSD方法进行三次成对的两两比较时,对应的犯第I类错误概率已经不是0.05,其实是0.1426.我们将这个错误概率称为总的或实验方式的第Ⅰ类错误概率( experimentwise Type I error rate).为避免混淆,我们将实验方式的第I类错误概率记。
对于总体个数较多的问题,犯实验方式第Ⅰ类错误的概率就会变得比较大,例如对于有5个总体,10个可能成对的两两比较的问题。比较方式的第Ⅰ类错误概率为α=0.05时,如果我们利用 Fisher的LSD方法检验所有可能成对的两两比较,则犯实验方式第I类错误的概率将是1-(1-0.05)=0.40.在这种情形下,有实际经验的专业人员将会寻求其他方法,以更好地控制犯实验方式第I类错误的概率。
控制总的犯实验方式错误概率的一种方法被称为 Bonferroni修正方法,该方法在每一次检验中都使用一个较小的比较方式错误概率。例如,如果我们想要检验C个成对的两两比较,并希望总的犯实验方式第I类错误的最大概率为αew,那么我们只要简单地将犯比较方式错误的概率等于αew/C即可。
在 Chemtech公司实验的例子中,如果我们想要使用 Fisher的ISD方法检验所有三个成对的两两比较,并且希望犯实验方式错误的最大概率为αew=0.05,那么我们只要设比较方式的错误概率为α=0.05/3=0.017即可。
随机化区组设计
在完全随机化设计中,
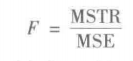
每当外部因素(实验中没有考虑到的因素)引起的差异使得上式中的分母MSE变大时,将会出现一个问题。在这种情况下,F值将会变小。于是,给我们发出的信号是处理均值之间不存在差异,而这样的差异事实上却是存在的。
使用随机化区组设计( randomized block design)的实验设计。这种实验设计方法通过消除MSE项中来自外部的变异,以达到控制变异外部来源的目的。该设计方法为真实的误差方差给出了一个更好的估计,并且在查明处理均值之间差异的能力方面,得到了一个更加有效的假设检验方法。
例子:
项测试空中交通管理员的疲劳程度与工作压力的研究得到的结果是,建议改造并重新设计管理员工作站。考虑了工作站的若干设计方案后,三种最有可能减轻管理员工作压力的工作站具体方案被选出。关键问题是三种方案对管理员工作压力的影响程度有多大差异。为了回答这个问题,我们需要设计一个实验,它能在每种工作站
方案下给出空中交通管理员工作压力的测度。
在完全随机化实验中,管理员的随机样本被指派给每种工作站方案。但是,管理员们认为在应对有压力的局面时,他们的能力是大不相同的。一名管理员认为是高压力,而对于另一名管理员来说可能是中等压力,甚至是
低压力。因此,当考虑变异的组内来源(MSE)时,我们必须意识到该变异既包括随机误差,又包括管理员个人差异导致的误差。事实上,管理者期望空中交通管理员个人的变异性是MSE项的一个主要贡献者。
将个人差异的影响分离出来的一种办法是使用随机化区组设计。这样的设计能识别出源自管理员个人差异的变异性,并将其从MSE项中剔除。随机化区组需要管理员的一个单样本,样本中每个管理员要分别在三种工作站
方案下接受检验。用实验设计的术语,工作站是影响因子,管理员是区组.与工作站因子有关的三个处理或三
个总体对应三种工作站方案。为简化起见,我们称工作站为系统A、系统B和系统C。
随机化区组设计中的随机化是指,处理(系统)指派给管理员的顺序是随机的。如果每个管理员按照同样的顺序测试三个系统,任何观测到的系统间差异都可能归因于测试的顺序,而不是真正的系统差异。

随机化区组设计的 ANOVA方法要求我们将总平方和(SST)分解成三个部分:处理平方和(SSTR)、区组平方和(SSBL)和误差平方和(SSE)。
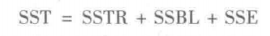

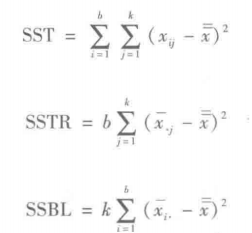

析因实验(factorial experiment)
迄今为止,我们所讨论的实验设计使我们能够得出有关一个因子的一些统计结论。然而,在有些实验中,我们希望得到有关一个以上变量或因子的统计结论。析因实验( factorial experiment)是一种实验设计,该实验设计允许我们同时得到有关两个或两个以上因子同时存在的一些统计结论。之所以使用术语“析因”,是因为
实验条件包括了所有可能的因子组合。例如,如果有因子A的a个水平,因子B的b个水平,那么实验将涉及收集ab个处理组合的数据。
作为两因子析因实验的一个例子,我们将考虑与管理类研究生入学考试( Graduate Management Admissions Test,GMAT)有关的一项研究。
例子:
1.3小时复习课,内容覆盖了GMAT常考的题型。
2.1天的课程,内容覆盖了相关的考试内容,还要进行一次模拟考试并评定分数。
3.10周强化班,内容涉及发现每个考生的薄弱环节并设立个性化的提高课程。
因此,这项研究的一个因子就是GMAT辅导课程,该课程有三个处理:3小时复习课、1天的课程和10周强化班。在选择采取哪种辅导课程之前,我们将进行进一步研究以判断这三种被推荐的辅导课程是如何影响GMAT
数的。
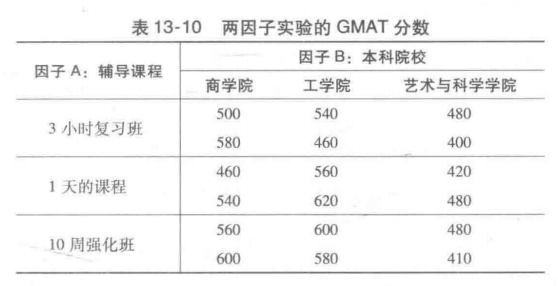
主影响(因子A):辅导课程的不同对GMAT的成绩有影响吗
主影响(因子B):本科院校的不同对GMAT的成绩有影响吗?
交互影响(因子A和B):一些本科院校的学生参加某种类型的辅导课程得到较好的GMAT成绩,而另一些本科院校的学生参加另一种类型的辅导课程得到较好的GMAT成绩吗?
两因子析因实验的 ANOvA方法要求我们将总平方和(ST)分解为四个部分:因子A的平方和(SSA)、因子B的平方和(SB)、交互作用的平方和(SSAB)和误差平方和(SSE)。
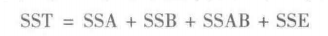

a代表因子A的水平数;b代表因子B的水平数;r代表复制的个数;nr代表实验中观测值的总数;nr=abr。
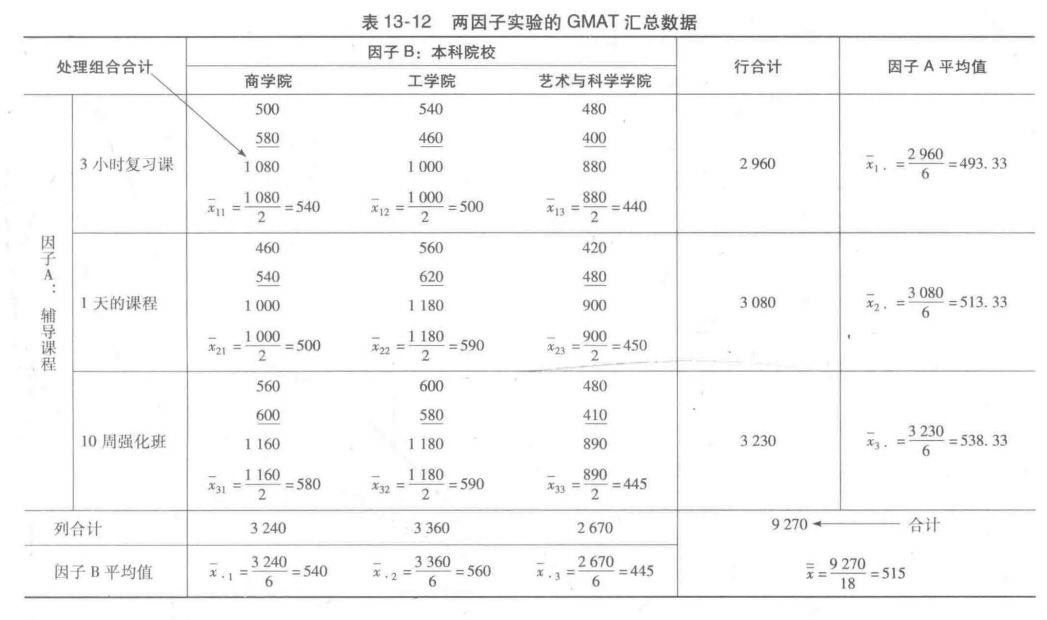
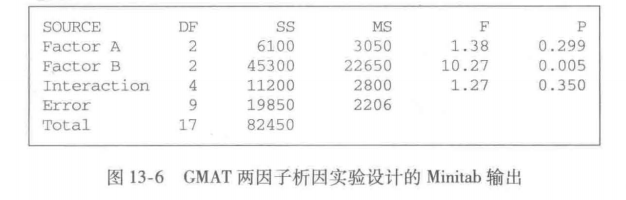
在α=0.05的显著性水平下,对两因子的GMAT研究进行假设检验。用于检验三种辅导课程(因子A)之间显著差异的p值是0.299。因为p-值=0.299,大于α=0.05,所以对于三种辅导课程,GMAT平均考试成绩不存在显著差异。但是,对于本科院校的影响,P-值=0.005,小于α=0.05;于是,对于三种类型的本科院校,GMAT平均考试成绩存在显著差异。
最后,因为交互作用影响的p-值=0.350,大于α=0.05,所以不存在显著的交互作用影响。综上所述,这项研究没有理由让我们相信对于来自不同本科院校准备参加GMAT考试的学生,三种辅导课程在提高他们的GMAT成绩方面是不同的。
最后
以上就是虚拟柜子最近收集整理的关于数据分析统计学原理第十三章:实验设计与方差分析 | 我的统计学原理复习日记的全部内容,更多相关数据分析统计学原理第十三章:实验设计与方差分析内容请搜索靠谱客的其他文章。








发表评论 取消回复