文章目录
- 1 简介
- 1 背景
- 2 恶意软件加密流量介绍
- 2.1 恶意软件分类
- 2.2 恶意软件加密通信方式
- 3 加密HTTPS流量解析
- 3.1 Https简介
- 4 流量解析
- 4.1 流量解析日志生成
- 4.2 流量解析日志中的数据关联
- 4.3 流量解析的证书日志
- 5 机器学习特征分类
- 5.1 构建4元组
- 5.2 特征提取
- 5.2.1 连接特征
- 5.2.2 SSL特征
- 5.2.3 证书特征
- 6 分类及预测效果
- 7 构建实时系统
- 8 关键代码
- 9 最后
1 简介
???? Hi,大家好,这里是丹成学长的毕设系列文章!
???? 对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
???? 基于机器学习的恶意流量识别检测
????学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
???? 选题指导, 项目分享:
https://gitee.com/yaa-dc/BJH/blob/master/gg/cc/README.md
1 背景
近年来随着HTTPS的全面普及,为了确保通信安全和隐私,越来越多的网络流量开始采用HTTPS加密,截止今日,超过65%的网络流量已使用https加密。
HTTPS的的推出,主要是为了应对各种窃听和中间人攻击,以在不安全的网络上建立唯一安全的信道,并加入数据包加密和服务器证书验证。但是随着所有互联网中加密网络流量的增加,恶意软件也开始使用HTTPS来保护自己的通信。
这种情况对安全分析人员构成了挑战,因为流量是加密的,而且大多数情况下看起来像正常的流量。 检测企业内部HTTPS流量的一种常见的解决方案是安装HTTPS拦截代理。 这些硬件服务器可以通过在其计算机中安装特殊证书来打开和检查员工的HTTPS流量。 HTTPS拦截器位于客户端和服务器之间,其中加密流量被解密,扫描恶意软件后,再次加密并发送到目标IP。 此方法允许使用经典检测方法来检测未加密的恶意软件流量。 使用拦截器的问题在于它昂贵,计算要求高,同时造成网络性能下降,而且它不尊重HTTPS的原始想法,即拥有私密和安全的通信。
学长将为大家介绍一种在不解密流量的情况,可以高精度地检测恶意软件HTTPS流量的技术。
2 恶意软件加密流量介绍
2.1 恶意软件分类
目前使用加密通信的恶意软件家族超过200种,使用加密通信的恶意软件占比超过40%,使用加密通信的恶意软件几乎覆盖了所有常见类型,如:特洛伊木马、勒索软件、感染式、蠕虫病毒、下载器等,其中特洛伊木马和下载器类的恶意软件家族占比较高。
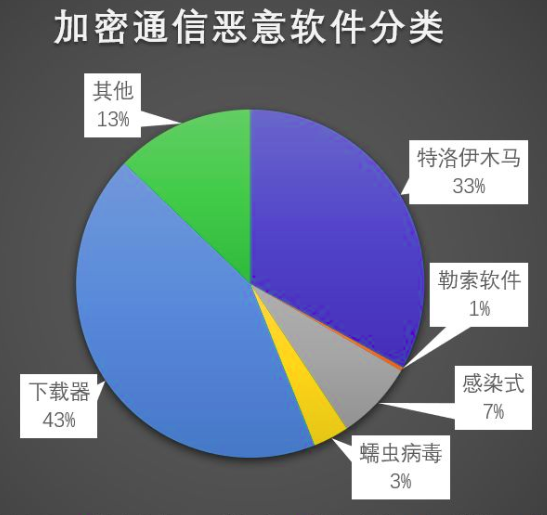
2.2 恶意软件加密通信方式
恶意软件产生的加密流量,根据用途可以分为以下六类:C&C直连、检测主机联网环境、母体正常通信、白站隐蔽中转、蠕虫传播通信、其它。
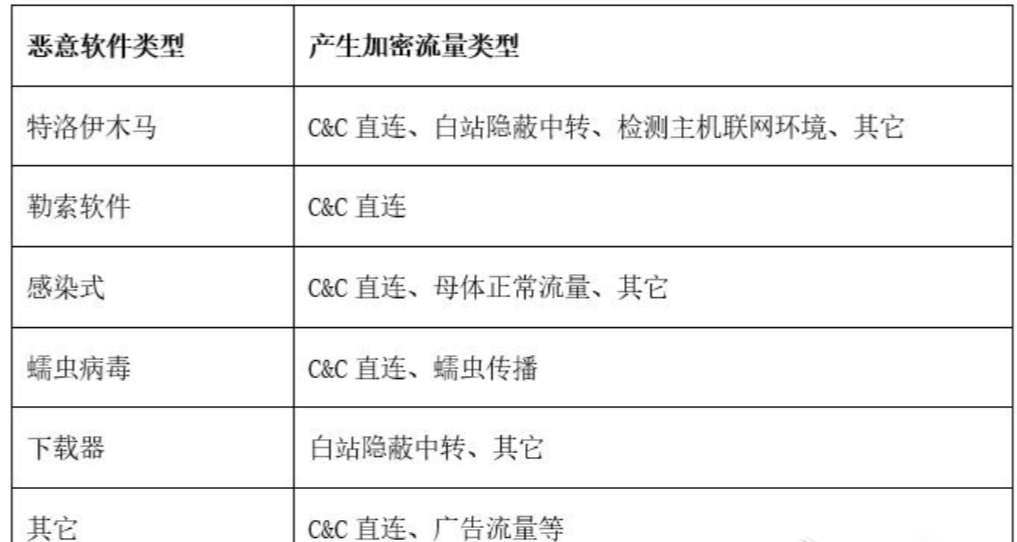
C&C直连 – 恶意软件在受害主机执行后,通过TLS等加密协议连接C&C(攻击者控制端),这是最常见的直连通讯方式。
检测主机联网环境 – 部分恶意软件在连接C&C服务器之前,会通过直接访问互联网网站的方式来检测主机联网情况,这些操作也会产生TLS加密流量。通过统计发现:使用查询IP类的站点最多,约占39%;使用访问搜索引擎站点约占30%,其它类型站点约占31%。
母体程序正常通信 – 感染式病毒是将恶意代码嵌入在可执行文件中,恶意代码在运行母体程序时被触发。母体被感染后产生的流量有母体应用本身联网流量和恶意软件产生的流量两类。由于可被感染的母体程序类别较多,其加密通信流量与恶意样本本身特性基本无关,本文就不做详细阐述。
白站隐蔽中转 – 白站是指相对于C&C服务器,可信度较高的站点。攻击者将控制命令或攻击载荷隐藏在白站中,恶意软件运行后,通过SSL协议访问白站获取相关恶意代码或信息。通过统计发现,最常利用的白站包括Amazonaws、Github、Twitter等。
蠕虫传播通信 – 蠕虫具有自我复制、自我传播的功能,一般利用漏洞、电子邮件等途径进行传播。监测显示近几年活跃的邮件蠕虫已经开始采用TLS协议发送邮件传播,如Dridex家族就含基于TLS协议的邮件蠕虫模块。
其他通信 – 除以上几类、还有一些如广告软件、漏洞利用等产生的恶意加密流量。
3 加密HTTPS流量解析
3.1 Https简介
HTTPS协议也称为SSL上的HTTP安全或超文本传输协议,是以安全为目标的 HTTP 通道,通过传输加密和身份认证保证了传输过程的安全性 。 如果没有加密,任何设法查看客户端和服务器之间的数据包的人都可以读取通信。
Http:在通讯的过程中,以明文的形式进行传输,采用wireshark抓包的效果如下:

Https:所有的请求信息都采用了TLS加密,采用wireshark抓包的效果如下:
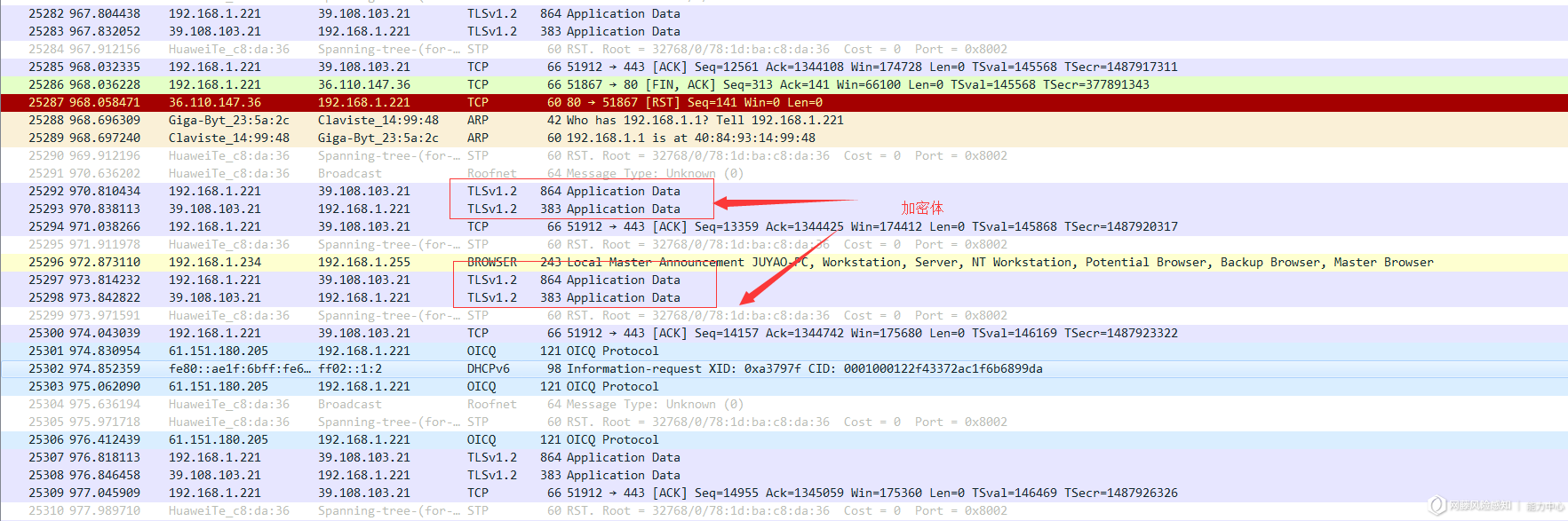
4 流量解析
4.1 流量解析日志生成
使用流量包深度解析方式提取HTTPS流量中的足够信息日志,包括连接通信日志、SSL协议日志、证书日志三部分。
从3个日志中可以获得以下信息:
(1)连接记录
每一行聚合一组数据包,并描述两个端点之间的连接。连接记录包含IP地址、端口、协议、连接状态、数据包数量、标签等信息。
(2)SSL记录
它们描述了SSL/TLS握手和加密连接建立过程。有SSL/TLS版本、使用的密码、服务器名称、证书路径、主题、证书发行者等等。
(3)证书记录
在日志中的每一行都是一个证书记录,描述证书信息,如证书序列号、常用名称、时间有效性、主题、签名算法、以位为单位的密钥长度等。
4.2 流量解析日志中的数据关联
流量包深度解析后生成日志数据,任何日志中的每一行都有唯一的键,用于链接其他日志中的行。
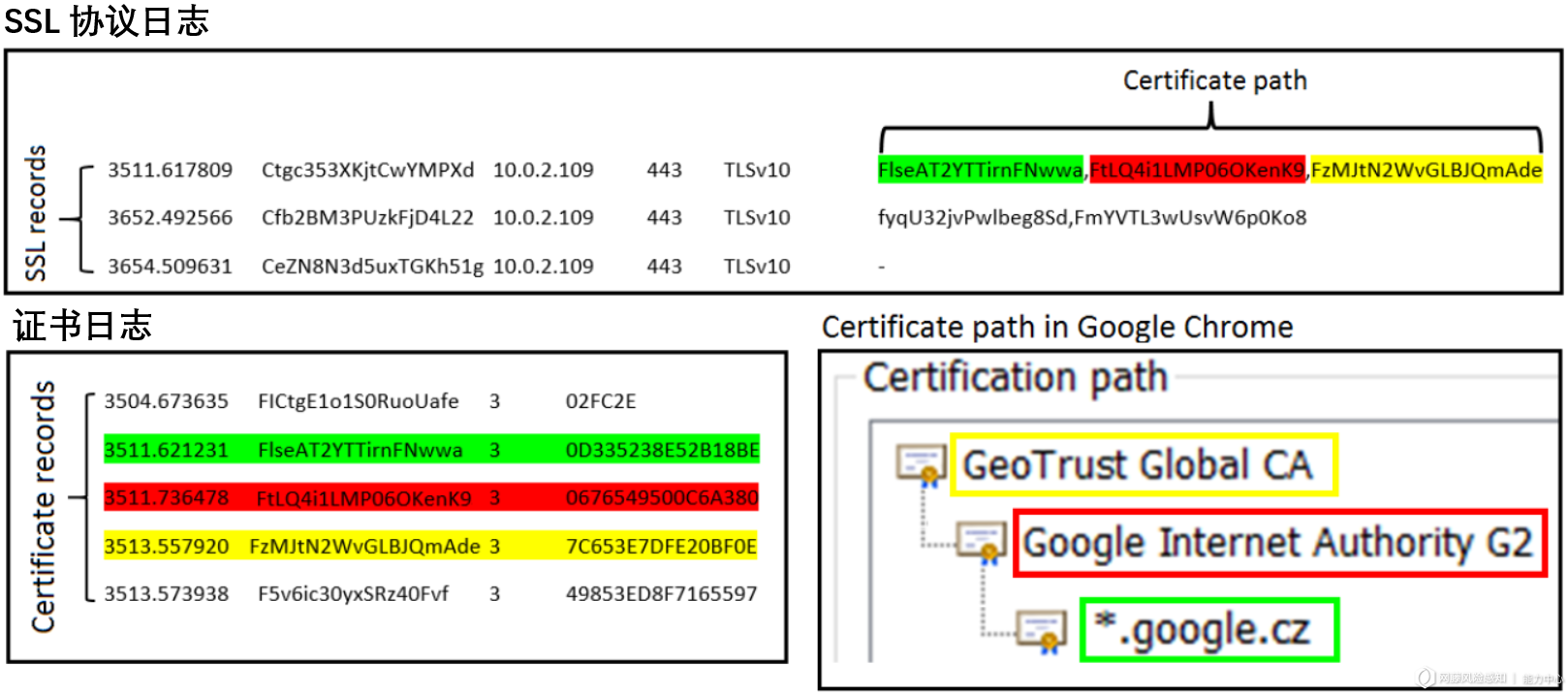
– 通过连接日志记录中的唯一键,可以和SSL协议日志中的唯一键进行2个记录的关联。
– 通过协议日志中一列使用逗号拼接成的id键值,可以在证书日志中找到每个id对应的证书记录。
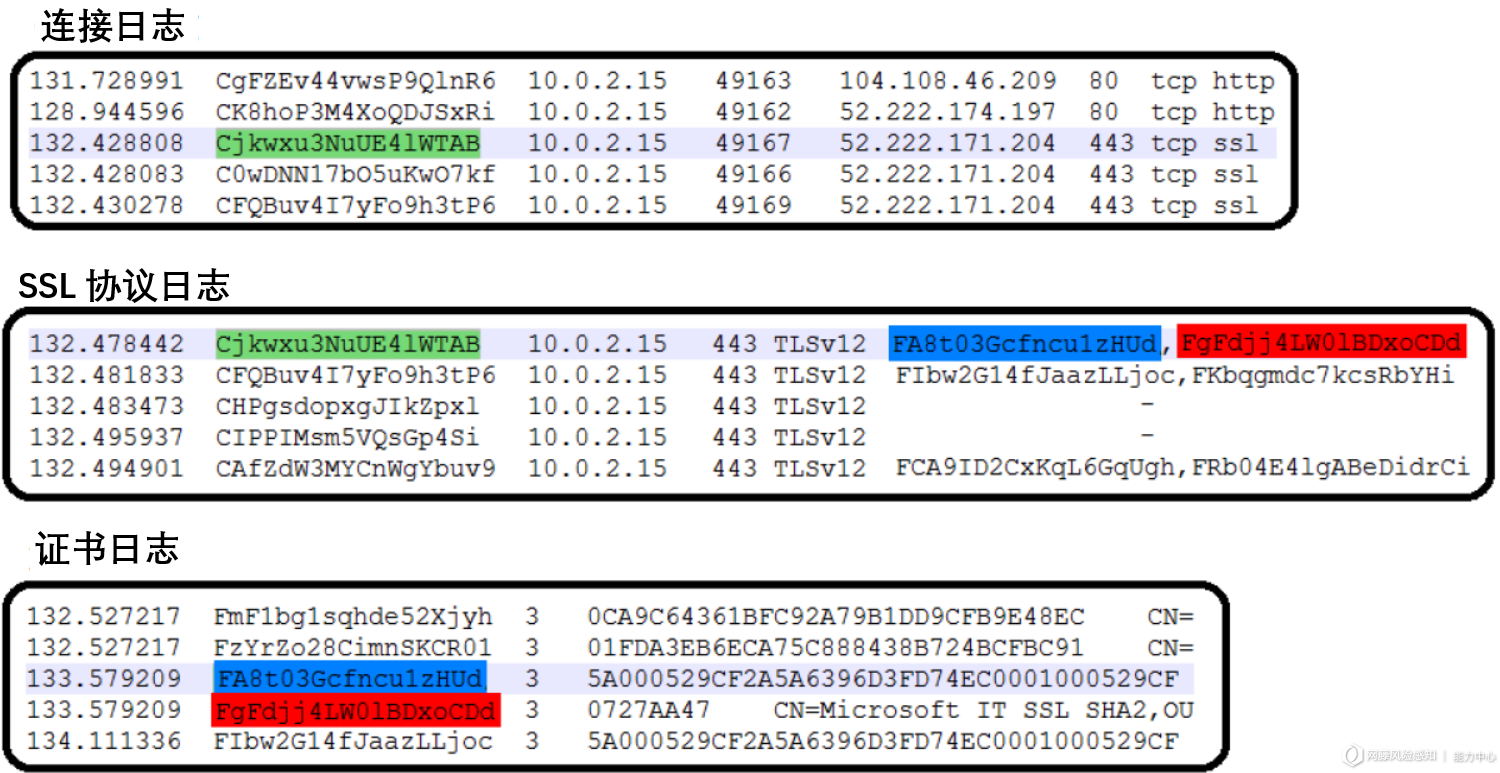
4.3 流量解析的证书日志
5 机器学习特征分类
基于构建4元组进行特征提取,通过来自连接日志、SSL协议日志、证书日志中的数据创建连接4元组,并提取特征用于机器学习模型训练。
5.1 构建4元组
根据连接日志中的id、SSL协议日志中的id进行连接,再根据得到的conn_ssl.log中的证书路径,取第一个key,和证书日志中的id进行再次关联,在得到的关联结果中,根据连接4元组(源IP、目标IP、目标端口和协议)相同的数据,进行group聚合操作,然后对于得到的每个连接4元组,根据聚合结果进行特征提取。

5.2 特征提取
对于每个连接4元组,我们提取了37个特征,大部分是基于我们对该领域的专业知识和对我们的恶意软件数据的彻底分析而创建的。对于这些特征,我们将它们分为3组:连接特征、SSL特征、证书特征。
– 连接特征是来自连接记录的特征,描述与证书和加密无关的通信流的常见行为。
– SSL特征是来自SSL记录的特征,描述了SSL握手和加密通信的信息。
– 证书特征是来自证书记录的特性,描述了web服务人员在SSL握手期间提供给我们的证书的信息。每个特性都是某个浮点值,如果由于缺少信息而无法计算该特征,则值为-1。
5.2.1 连接特征
连接特征共包含12个,部分举例如下:
(1)聚合和连接记录的数量。每个连接4元组包含的SSL聚合和连接记录数量和。
(2)持续时间均值。每个连接4元组的连接参数duration的均值。
(3)持续时间标准差。每个连接4元组的连接参数duration的标准差。
(4)超出标准差范围的持续时间占比。每个连接4元组的所有持续时间值中有多少百分比超出了范围。这个范围有两个极限,上限是均值+标准偏差,下限是均值-标准偏差。
(5)总发送包大小。每个连接4元组的所有连接记录发送的有效负载字节数。
5.2.2 SSL特征
SSL特征共包含10个,部分举例如下:
(1)连接记录中ssl连接的占比。连接4元组中非ssl连接和ssl连接的个数比值。
(2)TLS与SSL的比值。连接4元组中tls版本分布占比。
(3)SNI占比。连接4元组中server_name不为空的比例。
(4)SNI is IP。连接4元组中server_name为ip地址的比例。
5.2.3 证书特征
证书特征共包含15个,部分举例如下:
(1)公钥均值。连接4元组中全部证书exponent的均值。
(2)证书有效期的平均值。连接4元组中全部证书的有效天数的均值。
(3)证书有效期的标准差。连接4元组中全部证书的有效天数的标准差。
(4)捕获期间证书周期的有效性。连接4元组的全部证书中没有过期的占比。
6 分类及预测效果
数据集选择,对于负样本,使用https://www.stratosphereips.org/datasets-malware 网站下公开的恶意软件捕获结果集,目前已有349个恶意样本集。同时,使用一批最新的恶意软件10w个,通过沙箱捕获恶意软件产生的流量。对于正样本,一部分使用日常办公网中正常流量,同时使用爬虫爬取alexa中访问最多的top10000网站,采集产生的流量作为另一部分数据集。
经过数据清洗和过滤后,最终得到正样本46949条,负样本45121条。
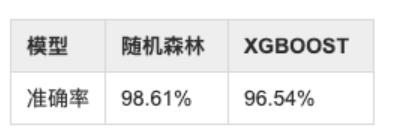
使用多种机器学习模型,进行训练,选择其中效果较好的模型,随机森林模型和XGBOOST,准确率如下:
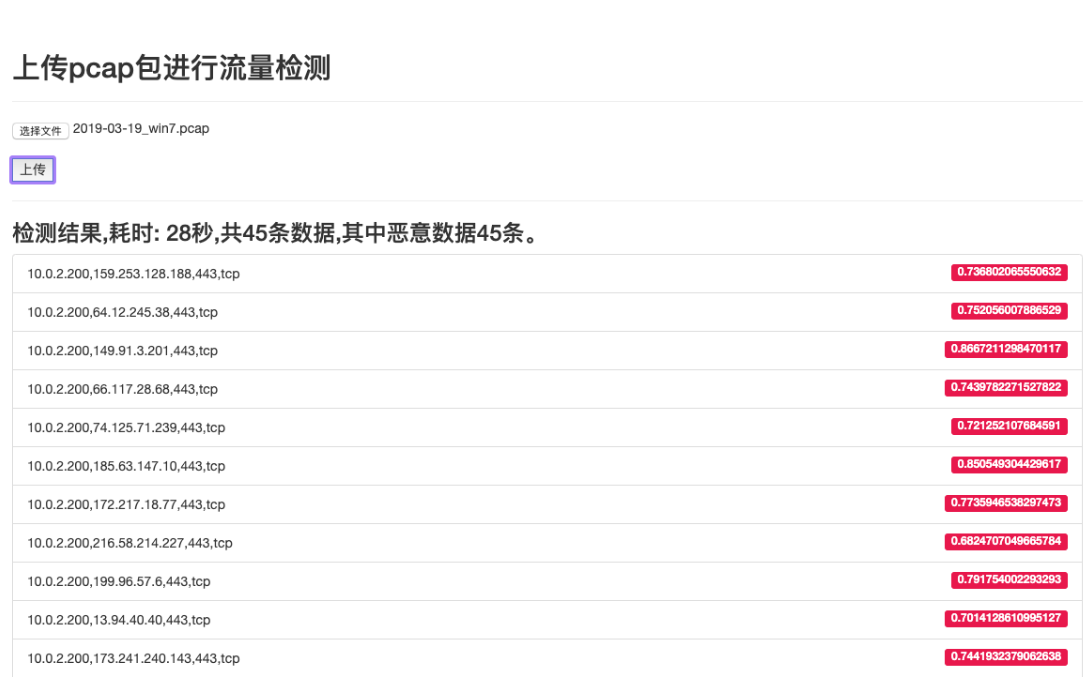
最后,为了便于测试模型效果,使用Flask开发了一个web在线检测页面,可以上传pcap进行检测恶意流量,收集20个最新的恶意软件进行测试,最后检出20个。
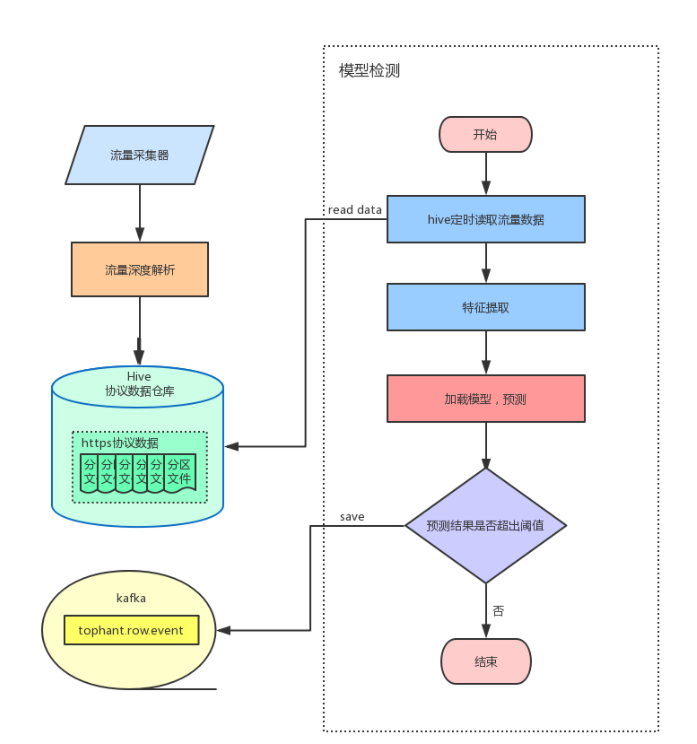
7 构建实时系统
技术选型选择Spark,因为每日流量数据很大,如果采用使用Spark Streaming在线实时检测会特别消耗机器性能,所以采用离线检测方式,流量深度包解析后的数据存储到Hive中,定时从Hive中读取数据,加载模型,进行检测。
8 关键代码
Deep Log分类识别方法
import torch
import math
import torch.optim as optim
import pandas as pd
from torch import nn
from sklearn.metrics import accuracy_score, f1_score, recall_score, precision_score
from collections import defaultdict
class DeepLog(nn.Module):
def __init__(self, num_labels, hidden_size=100, num_directions=2, topk=9, device="cpu"):
super(DeepLog, self).__init__()
self.hidden_size = hidden_size
self.num_directions = num_directions
self.topk = topk
self.device = self.set_device(device)
self.rnn = nn.LSTM(input_size=1, hidden_size=self.hidden_size, batch_first=True, bidirectional=(self.num_directions==2))
self.criterion = nn.CrossEntropyLoss()
self.prediction_layer = nn.Linear(self.hidden_size * self.num_directions, num_labels + 1)
def forward(self, input_dict):
y = input_dict["window_y"].long().view(-1).to(self.device)
self.batch_size = y.size()[0]
x = input_dict["x"].view(self.batch_size, -1, 1).to(self.device)
outputs, hidden = self.rnn(x.float(), self.init_hidden())
logits = self.prediction_layer(outputs[:,-1,:])
y_pred = logits.softmax(dim=-1)
loss = self.criterion(logits, y)
return_dict = {'loss': loss, 'y_pred': y_pred}
return return_dict
def set_device(self, gpu=-1):
if gpu != -1 and torch.cuda.is_available():
device = torch.device('cuda: ' + str(gpu))
else:
device = torch.device('cpu')
return device
def init_hidden(self):
h0 = torch.zeros(self.num_directions, self.batch_size, self.hidden_size).to(self.device)
c0 = torch.zeros(self.num_directions, self.batch_size, self.hidden_size).to(self.device)
return (h0, c0)
def fit(self, train_loader, epoches=10):
self.to(self.device)
model = self.train()
optimizer = optim.Adam(model.parameters())
for epoch in range(epoches):
batch_cnt = 0
epoch_loss = 0
for batch_input in train_loader:
loss = model.forward(batch_input)["loss"]
loss.backward()
optimizer.step()
optimizer.zero_grad()
epoch_loss += loss.item()
batch_cnt += 1
epoch_loss = epoch_loss / batch_cnt
print("Epoch {}/{}, training loss: {:.5f}".format(epoch+1, epoches, epoch_loss))
def evaluate(self, test_loader):
self.eval() # set to evaluation mode
with torch.no_grad():
y_pred = []
store_dict = defaultdict(list)
for batch_input in test_loader:
return_dict = self.forward(batch_input)
y_pred = return_dict["y_pred"]
store_dict["SessionId"].extend(batch_input["SessionId"].data.cpu().numpy().reshape(-1))
store_dict["y"].extend(batch_input["y"].data.cpu().numpy().reshape(-1))
store_dict["window_y"].extend(batch_input["window_y"].data.cpu().numpy().reshape(-1))
window_prob, window_pred = torch.max(y_pred, 1)
store_dict["window_pred"].extend(window_pred.data.cpu().numpy().reshape(-1))
store_dict["window_prob"].extend(window_prob.data.cpu().numpy().reshape(-1))
top_indice = torch.topk(y_pred, self.topk)[1] # b x topk
store_dict["topk_indice"].extend(top_indice.data.cpu().numpy())
window_pred = store_dict["window_pred"]
window_y = store_dict["window_y"]
store_df = pd.DataFrame(store_dict)
store_df["anomaly"] = store_df.apply(lambda x: x["window_y"] not in x["topk_indice"], axis=1).astype(int)
store_df.drop(["window_pred", "window_y"], axis=1)
store_df = store_df.groupby('SessionId', as_index=False).sum()
store_df["anomaly"] = (store_df["anomaly"] > 0).astype(int)
store_df["y"] = (store_df["y"] > 0).astype(int)
y_pred = store_df["anomaly"]
y_true = store_df["y"]
metrics = {"window_acc" : accuracy_score(window_y, window_pred),
"session_acc" : accuracy_score(y_true, y_pred),
"f1" : f1_score(y_true, y_pred),
"recall" : recall_score(y_true, y_pred),
"precision" : precision_score(y_true, y_pred)}
print([(k, round(v, 5))for k,v in metrics.items()])
return metrics
决策树分类方法
import numpy as np
from sklearn import tree
from ..utils import metrics
class DecisionTree(object):
def __init__(self, criterion='gini', max_depth=None, max_features=None, class_weight=None):
""" The Invariants Mining model for anomaly detection
Arguments
---------
See DecisionTreeClassifier API: https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html
Attributes
----------
classifier: object, the classifier for anomaly detection
"""
self.classifier = tree.DecisionTreeClassifier(criterion=criterion, max_depth=max_depth,
max_features=max_features, class_weight=class_weight)
def fit(self, X, y):
"""
Arguments
---------
X: ndarray, the event count matrix of shape num_instances-by-num_events
"""
print('====== Model summary ======')
self.classifier.fit(X, y)
def predict(self, X):
""" Predict anomalies with mined invariants
Arguments
---------
X: the input event count matrix
Returns
-------
y_pred: ndarray, the predicted label vector of shape (num_instances,)
"""
y_pred = self.classifier.predict(X)
return y_pred
def evaluate(self, X, y_true):
print('====== Evaluation summary ======')
y_pred = self.predict(X)
precision, recall, f1 = metrics(y_pred, y_true)
print('Precision: {:.3f}, recall: {:.3f}, F1-measure: {:.3f}n'.format(precision, recall, f1))
return precision, recall, f1
9 最后
最后
以上就是感性盼望最近收集整理的关于【毕业设计】机器学习恶意流量识别检测(异常检测) - 网络安全 信息安全1 简介1 背景2 恶意软件加密流量介绍3 加密HTTPS流量解析4 流量解析5 机器学习特征分类6 分类及预测效果7 构建实时系统8 关键代码9 最后的全部内容,更多相关【毕业设计】机器学习恶意流量识别检测(异常检测)内容请搜索靠谱客的其他文章。








发表评论 取消回复