引言:
之前了解了TF2.0的基础函数,如怎么创建一个tensor:tf.constant,将numpy数组转换为tensor tf.convert_to_tensor,全为0 tf.zero,全为1 tf.ones ,全为指定数字 tf.fill,正态分布的随机数 tf.random.normal,截断式正态分布随机 tf.random.trucated_normal,均匀分布随机数 tf.random.uniform,怎么标记变量允许被训练用来在反向传播时候记录梯度值 tf.Variable,强转换tensor的数据类型 tf.cast ,计算tensor维度上的最小值tf.reduce_min,最大值tf.reduce_max,数学运算tf.add ,tf.square等 , 构建数据集用生成输入特征/标签对的tf.data.Dataset.from_tensor_slices ,更新梯度做记录的 tf.GradientTape,独热编码 tf.one_hot,激活函数softman tf.nn.softmax ,返回最大值索引的tf.argmax。
【基础函数脑图和代码见原文链接:kl8w】
本次实践将运用这些基础函数,构建一个只有一层的神经网络采用softmax激活函数,手动实现梯度下降更新这一层网络的参数w1和b1,实现三分类鸢尾花数据集的分类,计算loss和acc查看分类效果,loss采用MSE计算来得到梯度进行更新。
目录:
iris数据集的获取和表格化——分析数据组成
搭建简单神经网络进行分类
-
步骤一:准备数据
步骤二:搭建网络
步骤三:参数优化
步骤四:测试效果
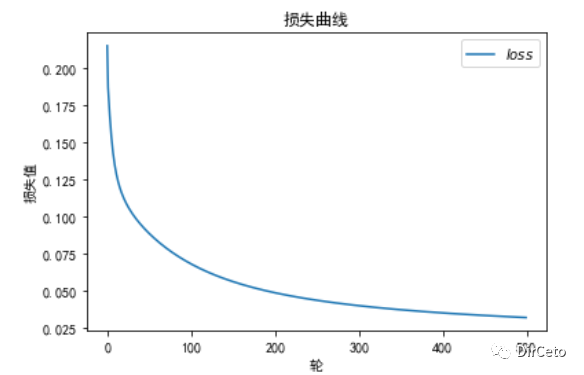
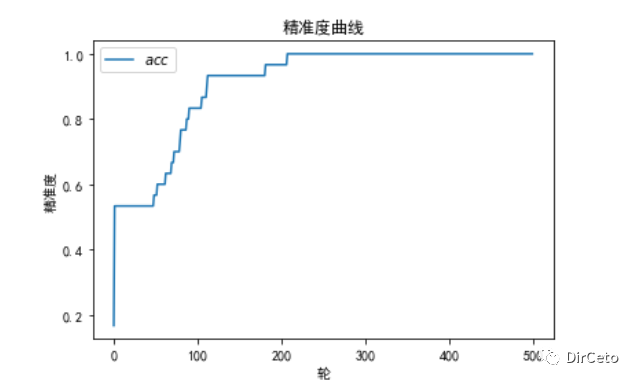
实验结果:loss 和 acc
iris 数据集分析
鸢尾花数据集(iris)
目标:多(三)分类
数据集:150个样本
特征:花萼长,花萼宽,花瓣长,花瓣宽【4个输入特征】
类别:Setosa Iris(狗尾草鸢尾)—— 0
Versicolour Iris(杂色鸢尾)——1
Virginica Iris(弗吉尼亚鸢尾)——2
三种分别用0,1,2表示
加载数据集:(我们从sklearn上导入)
给每一列添加中文标签。
表格展示
导包:
from sklearn.datasets import load_irisfrom pandas import DataFrameimport pandas as pd返回iris数据集的所有数据data(即特征)和目标值target(即分类)
x_data = load_iris().datay_data = load_iris().data# 下面为x_data 和y_data的值 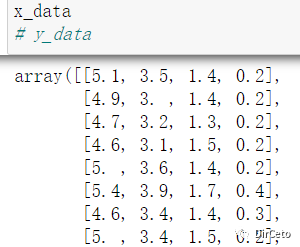

为了使数据更具可视化——DataFrame表格化
x_data = DataFrame(x_data,columns=['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']) x_data['类别'] = y_data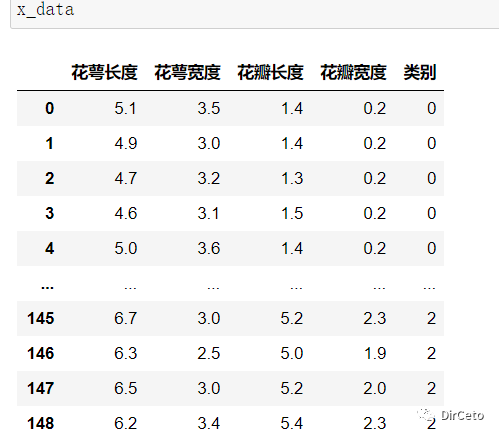
从加载的iris数据集我们看出:
该数据集共有150个样本
数据集是3*50的均衡样本
按顺序排列的,我们处理的时候要进行数据集打乱
(实际上,我们拿到的数据集,大部分要打乱之后再学习)
搭建一个只有一层的手写神经网络
——手动实现神经网络(梯度下降更新参数)
步骤
步骤一:准备数据
①数据集读入
②数据集乱序
③拆分训练集和测试集(split_train_test)
④配成(输入特征,标签)对,每次读入一小撮(batch)
步骤二:搭建网络
⑤定义神经网络中所有可训练参
步骤三:参数优化——通过loss
⑥嵌套循环迭代,with结构更新参数、
(在with结构中求得损失函数Loss对每个可训练参数的偏导数),
⑦显示当前loss
步骤四:测试效果——通过acc
⑧每遍历一次数据集,计算当前参数前向传播准确率,显示当前acc
⑨acc/loss可视化
以下代码中,神经网络均为手写。用到TF2.0的tensor的常用函数。 推荐先了解TF2.0的常用函数再看后面部分。
【点击原文链接获取高清的TF2.0常用函数图和本文代码】
步骤一:准备数据
①数据集读入import tensorflow as tffrom sklearn.datasets import load_irisimport numpy as npx_data = load_iris().datay_data = load_iris().target②数据集乱序
函数: np.random.seed():设置随机数种子,每次设置仅一次有效!
np.random.shuffle():打乱顺序
# 数据集乱序:使用相同的种子,使得特征和标签一一对应# 喂入神经网络的数据集也需要打乱顺序np.random.seed(116)np.random.shuffle(x_data)np.random.seed(116)np.random.shuffle(y_data)tf.random.set_seed(116)③数据集拆分成训练集和测试集(120:30)
函数: tf.cast(数据集,类型):tensor的强制类型转换
方法一:手动分离
x_train = x_data[:-30]y_train = y_data[:-30]x_test = x_data[-30:]y_test = y_data[-30:]# 因为矩阵相乘的时候要求数据类型要一致,将x的数据类型转换为f32x_train = tf.cast(x_train, tf.float32)x_test = tf.cast(x_test,tf.float32)方法二:sklearn中的 train_test_split
【一定要注意该方法的返回顺序,先是x,后是y ,先测试集后训练集】
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x_data,y_data, test_size = 0.2, random_state = 43)④将打乱后的x和y配对,打包batch,训练的时候一次一次喂入一个batch,拆成4个batch,每32组输入特征和标签对作为一个batch。
函数: tf.data.Dataset.from_tensor_slices((特征,标签)).batch(大小):
from_tensor_slices():生成输入特征/标签对,构建数据集
参数必须是元组(x_trian,y_train)
batch(数量):打包分组
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
步骤二:搭建神经网络
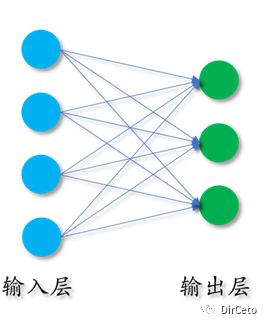
④定义神经网络中是所有可训练参数
函数: tf.Variable():生成“可训练”参数,可以在反向传播时记录梯度。
(常用来生成w和b)
tf.random.truncated_normal([维度],stddev,mean):
截断式正态分布的随机数,生成的数在mean±2*stddev内
w1 = tf.Variable(tf.random.truncated_normal([4,3],stddev=0.1))# 4行3列的张量b1 = tf.Variable(tf.random.truncated_normal([3],stddev=0.1))# b1对应3其余要用到的——学习率,存acc和loss的列表等
lr = 0.1# 记录每一轮的losstrain_loss_results = []# 记录每一轮的acctest_acc_results = []# 循环500轮epoch = 500# 每轮分成4个step loss_all 记录四个step生成的4个Loss的和loss_all = 0步骤三和步骤四:
参数优化—嵌套循环迭代,with结构更新参数得loss
对测试集进行测试,得到acc
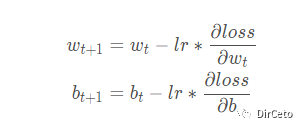
# 训练# 第一层for循环:针对整个数据集进行循环——epoch表示for epoch in range(epoch): # 第二层for循环:针对每一小撮batch ,用step表示 for step,(x_train, y_trian) in enumerate(trian_db): # with结构记录梯度信息,在其中计算预测的y值,得到loss with tf.GradientTape() as tape: # y = x*w1 + b1 y = tf.matmul(x,w1) + b1 # 多分类 ,使用softmax得到对应概率 y = tf.softmax(y) # 将标签值转独热,用于计算loss y_ = tf.one_hot(y_train,depth=3) # loss用MSE计算 loss = tf.reduce_mean(y_ -y) # 每个step的loss累加求平均更精准 loss_all += loss.numpy() # 计算对应的w1与b1的梯度,用以更新 grads = tape.gradient(loss,[w1,b1]) # 更新w1和b1 w1.assign_sub(lr*grads[0]) b1.assign_sub(lr*grads[1]) # 每一个epoch,打印loss,四个step,求均值更准 print("轮数:{},损失:{}".format(epoch,loss_all/4) # 记录损失 train_loss_results.append(loss_all/4) #每个epoch后 loss_all清零,记录下一个epoch的loss loss_all = 0 # 测试部分 # total_correct:记录预测争取的样本个数 # total_number:记录总的测试的样本个数 total_correct , total_number = 0, 0 #遍历测试集中所有数据 for x_test,y_test in test_db: # 预测y y = tf.matmul(x_test,w1)+b1 y = nn.softmax(y) # 通过softmax得到概率,选出概率值最大的,即为预测的类别 pred = tf.argmax(y) # 判断预测出来的pred是否与y_test一致。 correct = tf.cast(tf.equal(pred,y_test),dtype = tf.int32) # 上面的到的布尔值转换为0或1 ,correct自加就可以统计正确的个数 correct = tf.reduce_sum(correct) # 将所有的Batch中的correct求和 total_correct += int(correct) # 统计测试样本的总数,即x_test的行数,shape[0]指行 total_number += x_test.shape[0] # 计算准确率acc acc = total_correct /total_number test_acc_results.append(acc)画图:
#绘制loss曲线import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签plt.rcParams['axes.unicode_minus']=Falseplt.title('损失曲线')plt.xlabel('轮')plt.ylabel('损失值')plt.plot(train_loss_results,label='$loss$')plt.legend()plt.show()#测试集acc曲线plt.title('精准度曲线')plt.xlabel('轮')plt.ylabel('精准度')plt.plot(test_acc_results,label='$acc$')plt.legend()plt.show()结果:
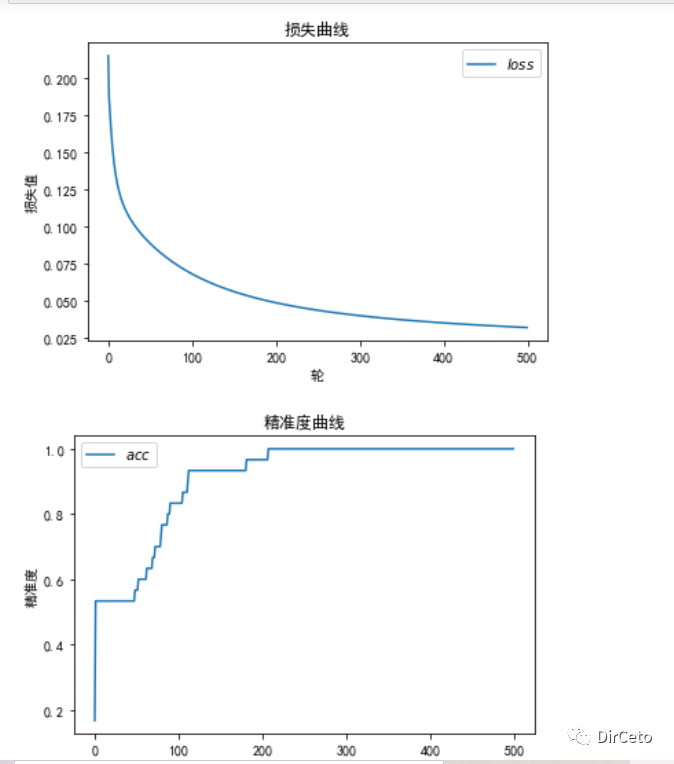
最后
以上就是机灵太阳最近收集整理的关于argmax函数_TF2.0鸢尾花数据集三分类【tf2.0底层API函数手动搭建单层简单神经网络】...的全部内容,更多相关argmax函数_TF2内容请搜索靠谱客的其他文章。








发表评论 取消回复