GitHub地址:https://github.com/leoluopy/paper_discussing/blob/master/body/MVF-Net/mvfNet.md
looking for papers for MVF-Net
contributer : leoluopy
- 欢迎提issue.欢迎watch ,star.
- 微信号:leoluopy,如有疑问,欢迎交流,得文时浅,或有纰漏,请不吝指教。
Overview
- 人脸三维建模是一个长期研究的课题,人脸三维数据稀少,并采集成本高,人脸三维重建的监督学习发展遇到不小瓶颈, 本文提出了一个人脸三维重建的半监督学习方法,并超越了不少同时期其他state-of-art方法。

在数据集MICC上和其他方法的对比,均有不同程度的提升。
实现效果的另一侧面说明,由此也可以发现实现最终精度误差大约在1cm左右。

模型叙述

- 本文提出了一种使用多角度人脸相互投影并且对投影误差进行不断优化,这样得出了一种半监督学习的人脸三维建模方法。投影思路 见上图

-
- 本文使用的模型结构如上图所示,输入为三幅人脸图像 A/B/C 分别如图所示,两个侧脸和一个正脸
- 收到人脸使用相同权重提取特征,这里使用的VGG 【上图左边黄色部分】 ,可以是其他特征提取模型例如EfficientNet
- 提取到三个人脸的特征concat在一块儿,随后几层全连接层回归3DMM参数。
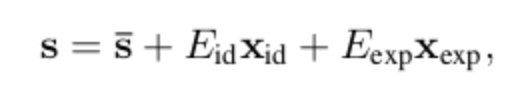
- s上横线 【markdown 没办法打】 : 表示BFM模型建立时那群高加索模特的3D模型的平均基础值
- Eid : 表示人脸ID向量的basis
- Eexp : 表示人脸表情向量的basis
- Xid : 表示被回归得到的人脸ID向量[199维]
- Xexp : 表示被回归得到的人脸表情向量[29维]
- 提取到三个人脸的特征不concat一块作为另一个分支,使用共享全连接权重,回归人脸位姿 (Pose A, Pose B, Pose C)
- f : 表示投影参数,投影方程见后文
- α,β,γ : 表示投影所需的欧拉角,转投影矩阵使用
- tx,ty : 表示投影平面上x,y的basis
- 上图中还有提到比如PhotoLoss,AlignLoss 是对训练Loss设计在整个架构的示意。下文介绍
训练方法
监督训练和无监督训练向结合,首先监督学习快速下降loss,而非直接进行无监督学习,从而避免进入局部最优点;监督学习 训练若干个epoch或者收敛(原文没有说明),之后进行无监督学习,其思想是:使用三个角度人脸,正面,左侧,右侧人脸进行 相交部分的相互投影(相交部分由关键点并过滤得来),投影之后相交部分【非遮挡部分】应该在纹理颜色,还有光流特征,以及人脸关键点部分 具有极高相似度,对此部分进行loss优化即是本文方法的最核心点。
投影描述
- 查上文中模型描述,有回归得到的以上的模型参数,这个模型参数会在下面的投影方程中使用。
- R 是有欧拉角转换得到 3x3 的投影矩阵
- v 是三维空间中 [x,y,z] 的坐标转置
- t 是basis
- 综合看维度= [2x3][3x3][3x1] + [2x1] = [2x1] 得到投影二维平面坐标
- u表示A图二维上面的纹理颜色特征
- PB 是B视图投影参数,PA 是A视图投影参数
- Pr 和 Pr-1 分别表示投影和反向投影,三维二维之间的纹理转换。
X 参数是3DMM模型回归得到的 【199维形状参数,29维表情参数】
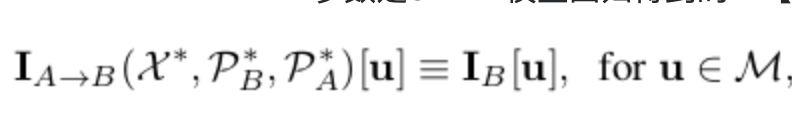 式子的另一种表达形式,也就是说任意像素u,从A视图投影到B视图,纹理特征相同。
式子的另一种表达形式,也就是说任意像素u,从A视图投影到B视图,纹理特征相同。- 整式子表达的意思: 从视图A 获取纹理特征,也就是二维图片,使用A视图投影参数和3DMM模型参数恢复得到空间三维点,这些点并带有纹理特征和空间坐标, 最后使用B视图投影参数投影至B视图,这时和原有B视图纹理特征应该相似。【关键点过滤后的非遮挡部分】
监督训练Loss
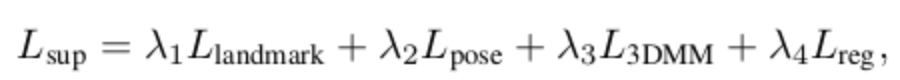
- 为了使模型训练能够更快收敛和不至于进入局部优化,本文作者采用了首先使用监督训练, 随后对半成品模型再进行无监督训练。其监督训练loss如上图所示,组成分别为位置坐标loss 位姿loss,3DMM模型参数loss,再加L2正则化。
无监督训练Loss
- 关于无监督训练的loss设计,首先无监督训练的基本原理是:利用三个视角的相互投影一定具有三维空间和纹理的不变性,不断的向这个方向进行优化即可以 达到优化整个模型的目的。
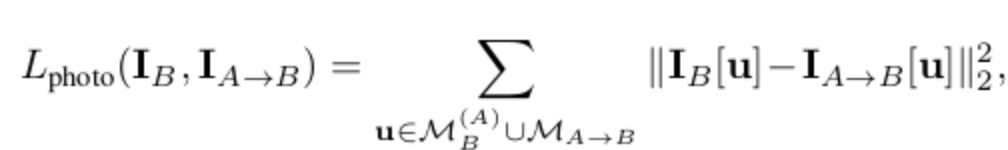
- 以上公式意义:A视图投影至B视图应该与原来B视图的纹理特征无限趋近,即是模型优化方向。 同时取二范数的平方,二范数在统计上更趋近于取得真实值,降低误差。取平方增大在loss中权重。
+训练过程中会发现如果仅仅使用photoLoss,确实能使得投影的像素从纹理数值上是接近的,但是训练 得到的结果根本不是人脸或者人脸变形。为了解决这个问题加入了光流loss和关键点loss如下图所示。

光流法简要介绍:利用关键点区块在另一时间序列的最优可能走向确认图像对应关系的算法,这种对应关系就是光流法: 举例:取上一幅图的一个图像区块,在下一幅图中对应位置的周围取搜索并相减,哪个位置相减最小,那么这个位置就是光流的走向,在本文loss的 设计中光流的流向应是原点,也就是光流趋近于不动。
最后
以上就是矮小煎蛋最近收集整理的关于MVF-Net 核心点解析Overview模型叙述训练方法投影描述的全部内容,更多相关MVF-Net内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复