python虽然具备很多高级模块,也是自带电池的编程语言,但是要想做一个合格的程序员,基本的算法还是需要掌握,本文主要介绍列表的一些排序算法
递归是算法中一个比较核心的概念,有三个特点,1 调用自身 2 具有结束条件 3 代码规模逐渐减少
举例:以下四个函数只有两个为递归

func3和func4 但是输出是不同的比如func3(5)输出为5,4,3,2,1func4(5)输出为1,2,3,4,5,有一个递归层级在里面。
两个概念:时间复杂度和空间复杂度
时间复杂度:用于体现算法执行时间的快慢,用O表示。一般常用的有:几次循环就为O(n几次方) 循环减半的O(logn)
空间复杂度:用来评估算法内存占用大小的一个式子,通常情况下会选择使用空间换时间
e.g 列表查找:从列表中查找指定元素
输入:列表、待查找元素
输出:元素下标或未查找到元素
version 1 顺序查找:从列表中的第一个元素开始,顺序进行搜索,直到找到为止,复杂度为O(n)
version 2 二分查找:从有序列表中,通过待查值与中间值比较,以减半的方式进行查找,复杂度为O(logn)
代码如下:
list = [1,2,3,4,5,6,7,8,9] element = 7 def ord_sear(list,element): for i in range(0,len(list)): if list[i] == element: print('list[{0}]={1}'.format(i,element)) return i else: print('not found') def bin_sear(list,element): low = 0 high = len(list)-1 while low<=high: mid = (low+high)//2 if element == list[mid]: print('list[{0}]={1}'.format(mid,element)) return mid elif element > list[mid]: low =mid +1 else: high =mid -1 return None i = bin_sear(list,element) j = ord_sear(list,element)
二分查找虽然在时间复杂度上优于顺序查找,但是有比较苛刻的条件,即列表必须为有序的。下面将介绍列表排序:
列表排序是编程中一个最基本的方法,应用场景非常广泛,比如各大音乐、阅读、电影、应用榜单等,虽然python为我们提供了许多排序的函数,但我们那排序来作为算法的练习再好不过。
首先介绍的是最简单的三种排序方式:1 冒泡排序 2 选择排序 3 插入排序
冒泡排序:列表中每相邻两个如果顺序不是我们预期的大小排列,则交换。时间复杂度O(n^2)
def bubble(list): high = len(list)-1 #指定一个最高位 while high>0: for i in range(0,high): if list[i]>list[i+1]: #如果比下一位大 list[i],list[i+1] = list[i+1],list[i] #交换位置 high -=1 #最高位减1 return list #返回列表 print(bubble(list))
优化一下:
list = [3,1,5,7,8,6,2,0,4,9] def bubble(list): high = len(list)-1 #定一个最高位 for j in range(high,0,-1): exchange = False #交换的标志,如果提前排好序可在完整遍历前结束 for i in range(0,j): if list[i]>list[i+1]: #如果比下一位大 list[i],list[i+1] = list[i+1],list[i] #交换位置 exchange = True #设置交换标志 if exchange == False: return list # return list #返回列表 print(bubble(list))
选择排序:一趟遍历选择最小的数放在第一位,再进行下一次遍历直到最后一个元素。复杂度依然为O(n^2)
list = [3, 1, 5, 7, 8, 6, 2, 0, 4, 9] def choice(list): for i in range(0,len(list)): min_loc = i for j in range(i+1,len(list)): if list[min_loc]>list[j]: #最小值遍历比较 min_loc = j list[i],list[min_loc] = list[min_loc],list[i] return list print(choice(list))
插入排序:将列表分为有序区和无序区,最开始的有序区只有一个元素,每次从无序区选择一个元素按大小插到有序区中
list = [3,1,5,7,8,6,2,0,4,9] def cut(list): for i in range(1,len(list)): temp = list[i] for j in range(i-1,-1,-1): #从有序区最大值开始遍历 if list[j]>temp: #如果待插入值小于有序区的值 list[j+1] = list[j] #向后挪一位 list[j] = temp #将temp放进去 return list print(cut(list))
这三种排序方式时间复杂度都是O(n^2),不太高效,所以下面介绍几种更高效的排序方式
1 快速排序:好写的排序里最快的,快的排序里最好写的。步骤为1 提取 2 左右分开 3 递归调用
list = [3,1,5,7,8,6,2,0,4,9] def partition(left=0,right=len(list)-1,list): temp = list[left] while left < right: while left<right and list[right]>temp: #当右边值较大时,值不动 right -=1 list[left]=list[right] #否则移动到左边 while left<right and list[left]<temp: left +=1 list[right]=list[left] list[left]=temp return left #返回leftright都可以,值是一样的 def quick_sort(left,right,list): while left<right: #迭代中断 mid = partition(left,right,list) #获取中间位置 quick_sort(left,mid-1,list) #小序列进一步迭代 quick_sort(mid+1,right,list) #大序列进一步迭代 return list #返回列表 print(quick_sort(left,right,list))
快排的时间复杂度最佳情况是O(nlogn),最差情况是O(n^2)
下面要介绍堆排序了。在介绍堆排序之前先简单提一下树的概念:
树是一种数据结构(比如目录),树是一种可以递归的数据结构,相关的概念有根节点、叶子节点,树的深度(高度),树的度(最多的节点),孩子节点/父节点,子树等。
在树中最特殊的就是二叉树(度不超过2的树),二叉树又分为满二叉树和完全二叉树,见下图:
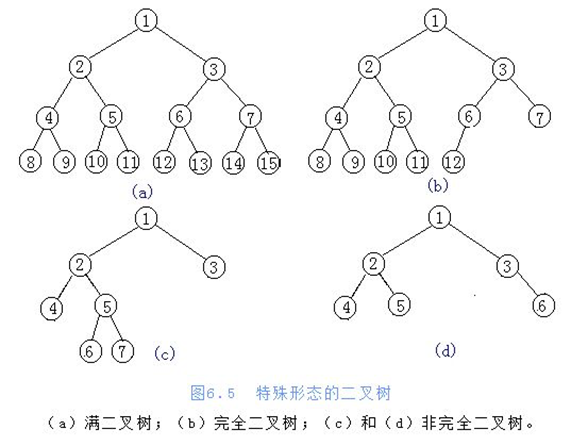
二叉树的储存方式有:1 链式储存 2 顺序储存(列表)
父节点和左孩子节点的编号下表的关系为 i --> 2i+1,右孩子则是i --> 2i+2 最后一个父节点为(len(list)//2-1) 由此可以通过父亲找到孩子或相反。
知道了树就可以说说堆了,堆分为大根堆和小根堆,分别的定义为:一棵完全二叉树,满足任一节点都比其孩子节点大或者小。
堆排序的过程:
-
- 建立堆
- 得到堆顶元素,为最值
- 去掉堆顶,将最后一个元素放到堆顶,进行再一次堆排序(迭代)
- 第二次的堆顶为第二最值
- 重复3,4直到堆为空
代码为:
list = [3, 1, 5, 7, 8, 6, 2, 0, 4, 9] def sift(low, high, list):#low为父节点,high为最后的节点编号 i = low j = 2 * i + 1 #子节点位置 temp = list[i] #存放临时变量 while j <= high: #遍历子节点到最后一个 if j < high and list[j] < list[j + 1]:#如果第二子节点大于第一子节点 j += 1 if temp < list[j]: #如果父节点小于子节点的值 list[i] = list[j] #父子交换位置 i = j #进行下一次编号 j = 2 * i + 1 else: break #遍历完毕退出 list[i] = temp #归还临时变量 def heap_sort(list): n = len(list) for i in range(n // 2 - 1, -1, -1): #从最后一个父节点开始 sift(i, n-1, list)#完成堆排序 for i in range(n - 1, -1, -1):#开始排出数据 list[0], list[i] = list[i], list[0]#首尾交换 sift(0, i - 1, list) #进行新一轮堆排序 return list print(heap_sort(list))
归并排序:假设列表中可以被分成两个有序的子列表,如何将这两个子列表合成为一个有序的列表成为归并。
原理如下图:
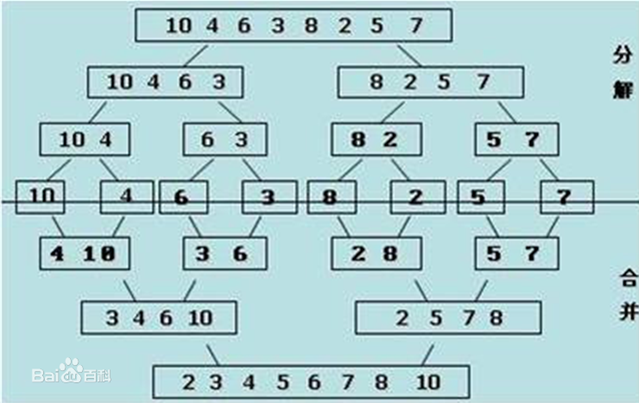
代码如下:
def merg(low,high,mid,list): i = low j = mid +1 list_temp = [] #定义临时列表 while i <=mid and j <=high: if list[i]<=list[j]: #分别比较有序子列表元素的大小 list_temp.append(list[i]) #添加进临时列表中 i +=1 else: list_temp.append(list[j]) j +=1 while i <= mid: list_temp.append(list[i]) i +=1 while j <= high: list_temp.append(list[j]) j +=1 list[low:high+1]=list_temp #将已完成排序的列表赋值给原列表相应位置 def merge_sort(low,high,list): if low < high: mid = (low+high)//2 #二分法 merge_sort(low,mid,list) merge_sort(mid+1,high,list)#递归调用, merg(low,high,mid,list) return list list = [3,1,5,7,8,6,2,0,4,9] print(merge_sort(0,len(list)-1,list))
version2 代码量更少:
def MergeSort(lists): if len(lists) <= 1: return lists num = int(len(lists) / 2) left = MergeSort(lists[:num]) right = MergeSort(lists[num:]) return Merge(left, right) def Merge(left, right): r, l = 0, 0 result = [] while l < len(left) and r < len(right): if left[l] < right[r]: result.append(left[l]) l += 1 else: result.append(right[r]) r += 1 result += right[r:] result += left[l:] return result print(MergeSort(list))
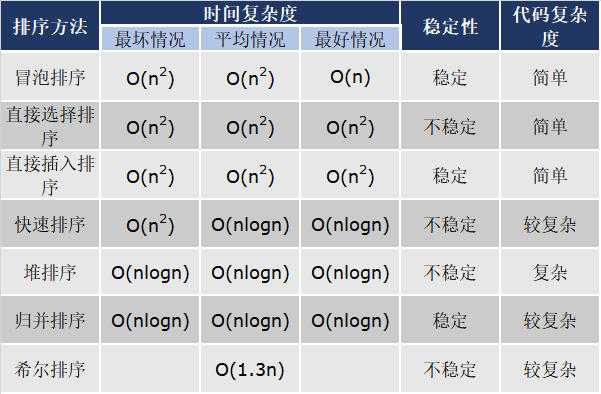
快排,堆排,归并的总结:
- 时间复杂度都是O(nlogn)
- 快排<归并<堆排(一般情况)
- 快排的缺点:极端情况效率较低,可到O(n^2),归并则是需要额外的开销,堆排则在排序算法中相对较慢
转载于:https://www.cnblogs.com/BigJ/p/python_algorithem.html
最后
以上就是执着皮皮虾最近收集整理的关于python 常见算法的全部内容,更多相关python内容请搜索靠谱客的其他文章。








发表评论 取消回复