

本文来自旷视研究院,作者:闫东。AI 科技评论获授权转载。如需转载,请联系旷视研究院。
目录
导语
3D人脸基础知识
初识3D人脸
相机模型
3D相机
3D人脸数据
3D人脸相关任务
常见Pipeline
3D人脸识别
3D人脸重建
总结
导语
随着深度学习技术的推进,人脸相关任务研究也跃升为学界和业界的热点。人们所熟知的人脸任务一般包括人脸检测,人脸身份识别,人脸表情识别等,它们多是采用 2D RGB 人脸(一般包括一些纹理信息)作为输入;而 3D 扫描成像技术的出现与发展,使得人脸相关任务有了一条新的探索路线——3D 人脸。
相较于许许多多的 2D 人脸相关任务入门文献/综述文章,3D 人脸的入门知识却乏善可陈。本文将梳理和介绍 3D 人脸相关基础知识,同时总结一些 3D 人脸识别和重建的基础入门文献。
3D人脸基础知识
初识3D人脸
2D/2.5D/3D 人脸
一般所讲的 RGB、灰度、红外人脸图像即为 2D 人脸,它们多为某一视角下表征颜色或纹理的图像,没有空间信息。深度学习用于训练的图像一般为 2D。
2.5D 是在某一个视角下拍摄得到的人脸深度数据,但由于角度问题,它所展示的曲面并不连续,即,当你尝试旋转人脸时,会有一些沟壑似的空洞区域。这是由于拍摄时,没有捕捉到被遮挡部分的深度数据。
那么 3D 人脸呢?它一般由多张不同角度的深度图像合成,完整展示人脸的曲面形状,并且人脸以密集点云的方式呈现在空间中,具有一定的深度信息。

这里有一个问题,经常谈及的 RGB-D 属于什么维度的人脸呢(注意维度与纹理和颜色无关)?
相机模型
了解 3D 人脸相关任务之前,有一个基础且非常重要的“知识点”,就是相机模型,不了解它,就无法入门 3D。关于相机模型,推荐参考《视觉SLAM十四讲》(链接:https://github.com/gaoxiang12/slambook)或者《SlAM入门》(链接:https://www.cnblogs.com/wangguchangqing/p/8126333.html)。本文先用最短时间让大家初步了解相机模型。
相机模型包括 4 种坐标系:像素坐标、图像坐标、相机坐标、世界坐标(脑袋中有没有闪现高中物理老师讲参考系的画面),相机成像过程即是真实三维空间中的三维点映射到成像平面(二维空间)的过程,也称之为射影变换。
相机坐标→图像坐标
相机坐标系到图像坐标系的过程可用小孔成像解释,本文借助相似原理可清楚描述相机坐标系中点  到像平面点
到像平面点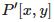 的过程,其中 f 为相机焦距。
的过程,其中 f 为相机焦距。
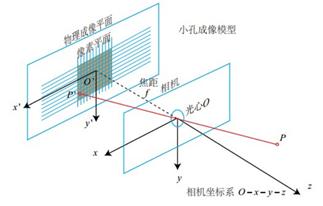
相机小孔成像图示(https://www.cnblogs.com/wangguchangqing/p/8126333.html)
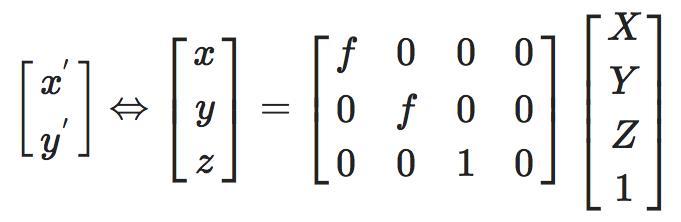
相机坐标到图像坐标的齐次表示
图像坐标→像素坐标
一般使用像素值表示 2D 图像,坐标原点通常是图像的左上角,因此像素坐标和成像平面坐标之间,相差了一个缩放和原点的平移。
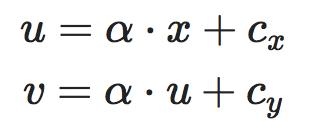
通过用相机坐标表示图像坐标,可以得到像素坐标与相机坐标的关系:
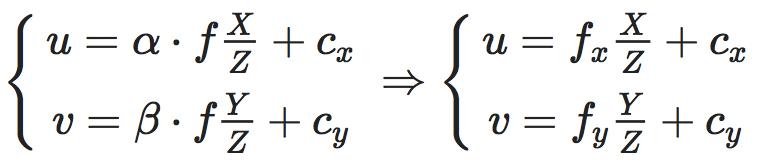
为保证齐次性(一般很多变换矩阵有这个特性),这里稍作改写:
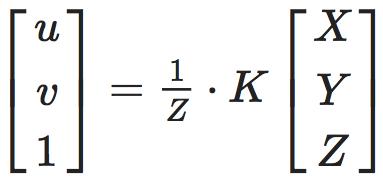
其中
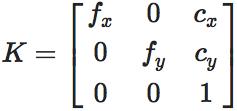
即经常说的相机内参矩阵(Camera Intrinsics),K 有 4 个未知数和相机的构造相关,f_x,f_y 和相机焦距、像素大小有关,c_x,c_y 是平移的距离,和相机成像平面的大小有关。
世界坐标→相机坐标
其实,相机坐标系并不是一个特别“稳定”的坐标系,因为相机会随着自身移动而改变坐标的原点以及各个坐标轴的方向,这时就需要一个更稳定的坐标系来更好地表示射影变换,而我们通常采用的恒定不变的坐标系为世界坐标系。
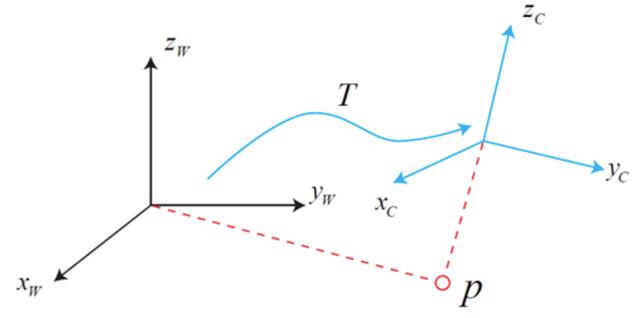
相机坐标系与世界坐标系之间相差一个旋转矩阵和平移向量(引自《视觉SLAM十四讲》)
 同样为了保证齐次性,其改写形式如下:
同样为了保证齐次性,其改写形式如下:
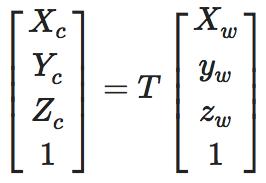
其中变换矩阵
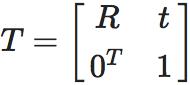
即常说的相机外参(Camera Extrinsics)。
从世界坐标系到像素坐标系相当于一个弱投影过程,总结一下就是从相机坐标系变换到像素坐标系需要相机内参,从相机坐标系变换到世界坐标系下需要相机外参,写成变换式如下:
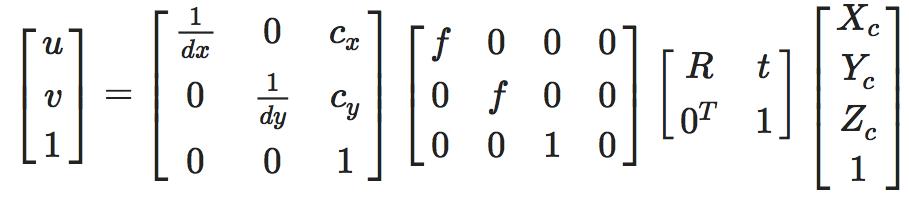
3D相机
按照相机工作方式可将其分为单目相机(Monocular)、双目相机(Stereo)和深度相机(RGB-D),而相机的本质也是通过二维形式反映三维世界。
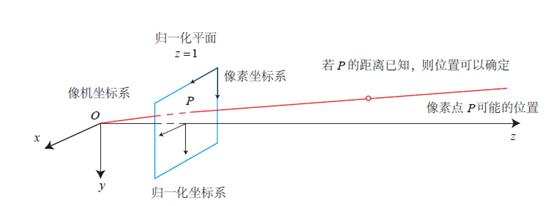
单目相机即单个摄像头的相机,由于其在同一时刻只能拍摄某一视角的图像,从而会丢失场景深度。比如,若已知某个像点 P 在成像平面上,由于不知道具体距离,则投影的像素点可以在相机原点与 P 连线上的任意位置,所以出游或者毕业时,可以拍出一张用手托人的错位效果图。
(引自《视觉SLAM十四讲》)
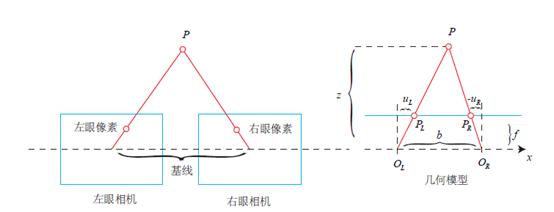
那么如何拍摄一张有深度信息的照片呢?一种方法是通过双目相机获取深度。双目相机顾名思义为“两只眼睛”,左眼相机和右眼相机的光圈中心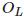 和
和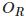 构成基线,空间中一点 P 会在分别投影在双目相机像平面上的
构成基线,空间中一点 P 会在分别投影在双目相机像平面上的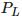 和
和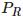 ,这样通过相似原理可以求解 P 到基线的距离即 P 点的深度(见下 方 公式)。在实际应用中,一般物体纹理丰富的地方比较容易计算视差,而且考虑到计算量,双目深度估计一般采用 GPU 或 FPGA 进行计算。
,这样通过相似原理可以求解 P 到基线的距离即 P 点的深度(见下 方 公式)。在实际应用中,一般物体纹理丰富的地方比较容易计算视差,而且考虑到计算量,双目深度估计一般采用 GPU 或 FPGA 进行计算。
(引自《视觉SLAM十四讲》)
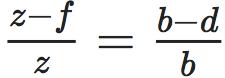
,其中
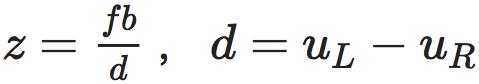
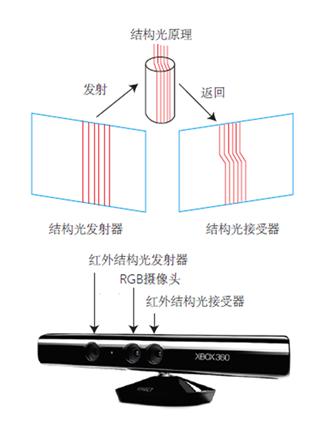
随着技术不断演进,深度相机的出现使我们可以更加便捷地获取图像的深度。其中一种深度相机为基于结构光的 RGB-D 相机,以人脸为例,扫描仪会对目标人脸发射光图案(如光栅格),根据其形变计算曲面形状,从而计算人脸的深度信息。
(引自《视觉SLAM十四讲》)
图中还有一个 RGB 摄像头,那么如何实现深度与 RGB 一一对应呢?测量深度之后,RGB-D 相机通常会按照生产时的各个相机摆放位置,完成深度与彩色图像素之间的配对,输出一一对应的彩色图和深度图。我们可以在同一个图像位置,读取到色彩信息和距离信息,计算像素的 3D 相机坐标,生成点云(Point Cloud)。
深度相机中还有一种基于飞行时间原理(Time of Flight,ToF),ToF 相机会向目标发射脉冲光,然后根据发送到返回之间的光束飞行时间,确定物体离自身的距离。ToF 相机与激光传感器不同,可以在发射脉冲光的过程中获取整个图像的像素深度,而激光一般通过逐点扫描获取深度信息。
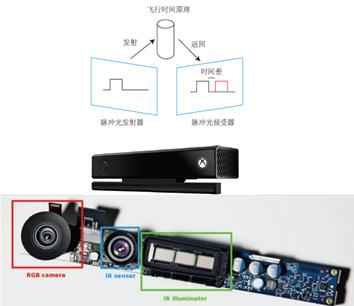
(引自《视觉SLAM十四讲》)
总结一下,3D 人脸任务一般采用深度相机获取人脸的深度信息,深度相机一般包括双目相机,基于红外结构光原理的 RGB-D 相机(如 Kinect 1 代)或者基于基于光飞行时间原理的 ToF 相机(如 Kinect 2 代)。
3D 人脸数据
3D 人脸相关任务一般有 3 种表征数据的方式:点云,网格图和深度图。

点云(Point cloud)
在三维点云中,每一个点都对应一个三维坐标 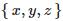 。许多三维扫描设备使用这种数据格式存储采集到的三维人脸信息。有时,人脸的纹理属性也可以拼接到形状信息上,这时点的表达就成了
。许多三维扫描设备使用这种数据格式存储采集到的三维人脸信息。有时,人脸的纹理属性也可以拼接到形状信息上,这时点的表达就成了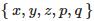 ,其中 p,q 是稀疏坐标。
,其中 p,q 是稀疏坐标。
点云表示的缺点是每一个点的邻域信息不好获取,因为点的存储一般是无序的。一般情况下,点云数据会用来拟合一个平滑的曲面,以减少噪声的影响。
网格(Mesh)
三维网格使用在三维曲面上预计算好并索引的信息进行表示,相比于点云数据,它需要更多的内存和存储空间,但是由于三维网格的灵活性,更适合用来做一些三维变换,例如仿射变换、旋转和缩放。每一个三维网格数据,由以下元素构成:点、线、三角面。二维纹理的坐标信息也可以存储在点信息中,有利于重建更精确的三维模型。
深度(Depth/Range)
深度图像也称之为 2.5D 或者 Range 图像。三维人脸的 z 轴数值被投影至二维平面,效果类似一个平滑的三维曲面。由于这是一种二维表示方式,所以很多现存的二维图像的处理方法可以直接应用。这种数据可以直接以灰度图的方式展示出来,也可以使用三角剖分原则转换成三维网格。
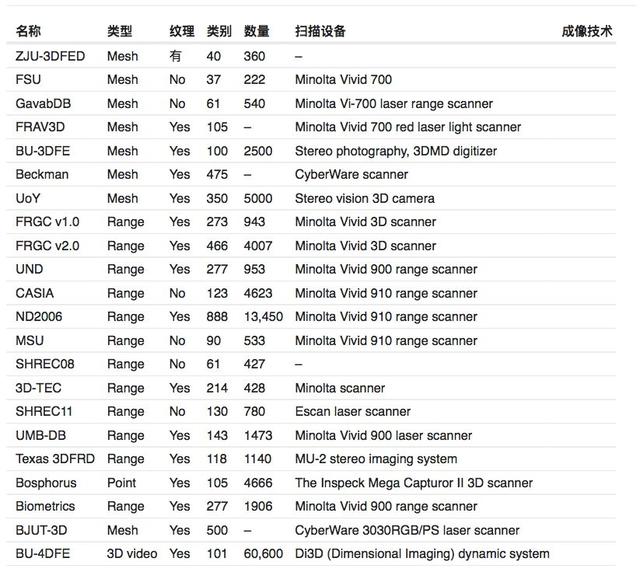
做 3D 人脸首先必不可少的就是 3D 数据,然而现状却是公开数据少,远少于 2D 人脸图片,3D 高精度人脸只能靠昂贵的设备采集,过程繁琐,本文梳理了现有公开常用的 3D 或 2.5D 人脸数据集,关于数据库和 3D 人脸任务的介绍推荐参考《三维人脸研究》(链接:http://blog.csdn.net/alec1987/article/details/7469501)。
3D人脸相关任务
常用Pipeline
2D 人脸相关任务的 Pipeline 一般分为数据预处理、特征提取、特征分析等过程,那么 3D 人脸的 Pipeline 呢?这里本文引用《3D Face Analysis: Advances and Perspectives》(链接:https://link.springer.com/chapter/10.1007/978-3-319-12484-1_1)中的图片进行讲解。
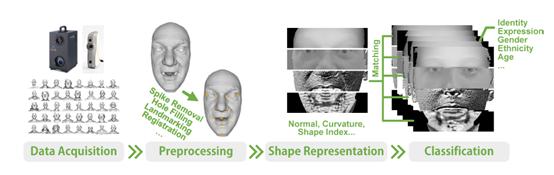
一个通用的 3D/2.5D 人脸分析框架如上图所示。我们通过设备获取人脸的 3D/2.5D 表示(Mesh、Point Cloud、Depth),经过一些预处理操作如球形剪裁,噪点去除,深度缺失修复,点云配准等进一步获取可用的 3D/2.5D 人脸。
接下来对预处理后的人脸进行表征,表征的方式有很多,比如采用表面法向,曲率,UV-Map 或常用的 CNN 方法;在提取一个特征之后就可以进行各种人脸任务,比如识别、表情分析、性别分类、年龄分类等。
鉴于本文的目的是梳理 3D 人脸入门相关知识,这里先为大家简单介绍一下关于 3D 人脸重建和识别的相关工作,包括发展过程和一些比较容易上手的论文。
3D人脸识别
3D 人脸识别的前几十年,都是采用手工设计的特征和分类或度量方法,进行人脸验证和识别。近几年,随着深度学习方法的兴起,逐渐有一些工作采用数据为驱动,进行 3D 人脸识别模型的训练,本文简单总结了一下 3D 人脸识别方法,如下:
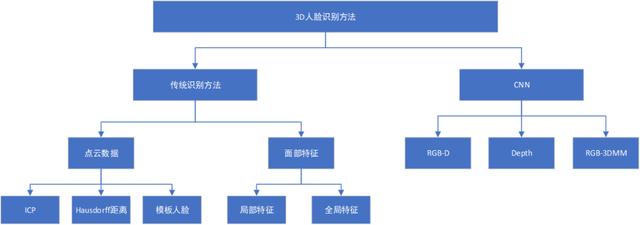
1、传统识别方法
基于点云数据的3D人脸识别
这类方法通常不考虑三维空间中的人脸特征,直接采用三维点云进行匹配。常见方法有 ICP (Iterative Closest Point,链接:https://en.wikipedia.org/wiki/Iterative_closest_point) 和 Hausdorff 距离(链接:https://en.wikipedia.org/wiki/Hausdorff_distance)。
ICP 作为一种刚性匹配算法,可以修正三维点云本身存在的平移和旋转变换,但是对于由表情和遮挡引起的曲面凹凸变化不够鲁棒,并且时间开销比较大。
ICP 使用人脸表面采样的法向量进行匹配,由于法向信息具有更好的判别性,在这里简单介绍一下 ICP 的算法,ICP 为一种迭代最近点的方法,可实现两堆点云的配准,这类比于 2D 人脸的关键点对齐。
假设有两组点云:
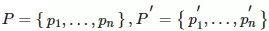
,通过迭代的方法找到一组
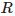
和
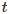
,满足
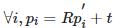
,即求解
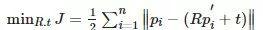
。具体的求解过程大家可以参考《视觉slam十四讲》第七章(链接:https://github.com/gaoxiang12/slambook)。
Hausdorff 距离通过计算两张人脸的三维点云之间的最近点对之间的最大值,去评估空间中不同真子集之间的距离。但是,该算法依然存在对表情和遮挡不鲁棒的问题,改进的 Hausdorff 距离算法使用三维人脸的轮廓线来筛选数据库中的对象。
模板人脸的方法利用三维人脸上的种子点进行形变,拟合到待测试人脸上,利用拟合参数进行人脸识别,并可通过密集的三维人脸点云对齐方法生成特定的可形变人脸模型。
基于面部特征的3D人脸识别
基于面部特征的3D人脸识别可以分为局部特征和全局特征两个方面来讲,具体也可参考《3D Face Analysis: Advances and Perspectives》(链接:https://link.springer.com/chapter/10.1007/978-3-319-12484-1_1)、《3D face recognition: a survey》(链接:https://www.researchgate.net/publication/329202680_3D_face_recognition_a_survey)。
局部特征有两个方面,一是基于面部区域部件信息的特征,例如鼻子、眼睛、嘴巴区域,这类特征可大致分为,基于面部关键点、曲率、块的特征提取方法;二是基于局部描述子算法提取的特征,比如在深度图像上提取小波特征、SIFT、2D-LBP、MRF、LSP,也有在三维数据上进行特征提取的算子,比如 3D-LBP。全局特征即对整张人脸进行变换并提取特征,人脸数据可能以不同的方式存储,比如点云、图像、Mesh 类型的三维人脸数据,比如将三维人脸模型表征为球面谐波特征(SHF),或者将三维人脸曲面同胚映射到二维网格中,用以稀疏表示,使用稀疏系数作为特征。
2、深度学习识别方法
CNN 在 2D 的人脸识别上取得了比较大的进展,然而 2D 人脸容易受到妆容、姿态、光照和表情等影响,3D 人脸本身包含人脸的空间形状信息,受外界因素影响较小。相较于 2D 人脸,3D 人脸数据携带的信息量更多。但由于 3D 人脸数据获取比较难且有些人脸数据精度不够,导致 3D 人脸识别的发展并不是很火热。
基于深度图的人脸识别
深度图的人脸识别常用方法包括提取 LBP 等特征,多帧深度图融合,深度图归一化等,这里简单介绍两篇深度图相关的人脸识别论文。
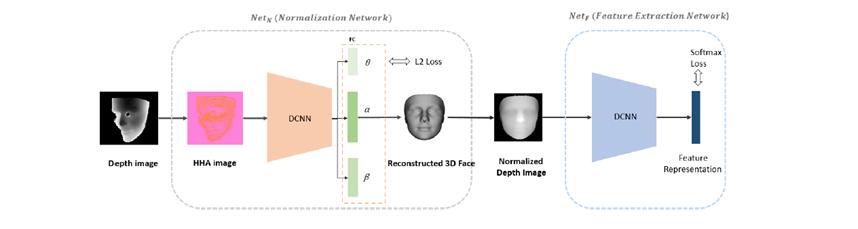
《Robust Face Recognition with Deeply Normalized Depth Images 》
该论文算是一个比较常见的深度图人脸识别 Pipeline,分为两个网络:归一化网络和特征提取网络。归一化网络负责将输入的深度图转为 HHA图像(链接:https://blog.csdn.net/WillWinston/article/details/78723507),并通过一个 CNN 网络回归 3DMM 的参数(下文 3D 重建会提到),在重构了 3D 点云后即可投影成归一化的深度图;特征提取网络和普通的 2D 人脸识别网络基本类似,得到一个表征深度图人脸的特征向量。
《Led3D: A Lightweight and Efficient Deep Approach to Recognizing Low-quality 3D Faces 》
该论文为 CVPR 2019 一篇低质量深度图人脸识别文章,文中一些针对深度图人脸的预处理以及数据增强操作值得参考。本文采用球形剪裁后的深度人脸的法向作为网络输入,实验表明可以更好地表征深度人脸,同时,作者也精心设计了轻量级的识别网络(主要为多层特征融合以及注意力机制),可以参考。
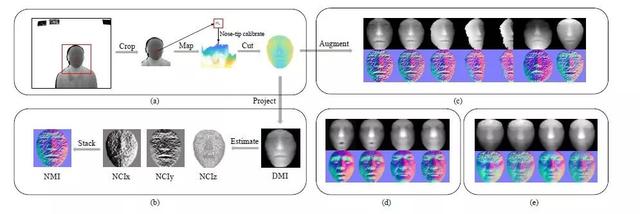
基于RGB-D的人脸识别
基于 RGB-D 的人脸识别基本上以 2D 人脸识别方法为主,将与 RGB 对齐的深度图作为一个通道送入 CNN 网络,RGB-D 一个优势是增加了人脸的空间形状信息。针对 RGB-D 图像的人脸识别论文还有很多,但基本思想是在特征层融合或是在像素层融合。
《Accurate and robust face recognition from RGB-D images with a deep learning approach 》
该论文 2016 年提出一种基于深度学习的 RGB-D 图像人脸识别算法,论文通过 RGB 图像和多帧融合后的深度图像分别进行预训练与迁移学习,并在特征层进行融合,从而提升识别率。
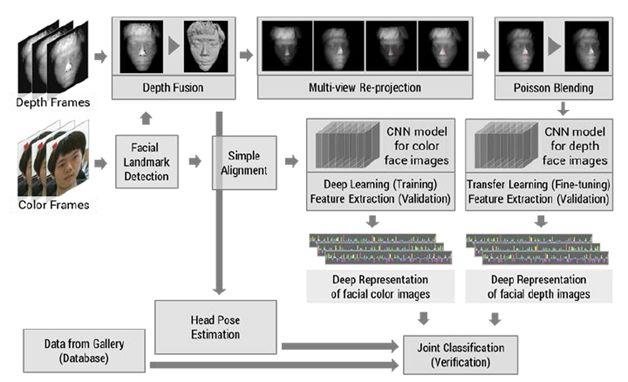
基于 Depth/RGB-3DMM 的人脸识别
最近两年开始出现采用 3DMM 对深度图或 RGB 图进行人脸模型回归,并应用于识别任务的工作。这类工作的一般思想是通过回归 3DMM 的参数(expression、pose、shape),实现 3D 人脸数据的扩增,并应用于 CNN 的训练,比较有代表性的工作如 FR3DNet(链接:https://arxiv.org/abs/1711.05942),3D Face Identification(链接:https://arxiv.org/abs/1703.10714)。
《Deep 3D Face Identification》
该论文算是第一批把深度神经网络应用于 3D 人脸识别任务的方法,主要思想为通过 3DMM+BFM 拟合深度图成为带表情的 3D 人脸模型,从而实现深度数据扩增,同时也做了如随机遮挡和姿态变换等数据增强,最终送入一个 2D 人脸识别网络进行 Finetune。

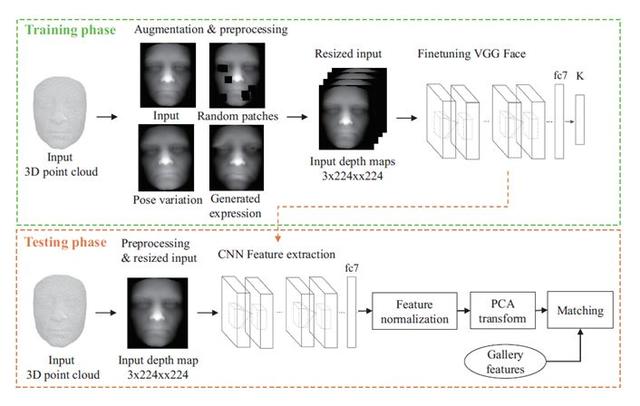
《Learning from Millions of 3D Scans for Large-scale 3D Face Recognition》
该论文是 3D 人脸识别的一篇名作,真正实现了创造百万级别的 3D 人脸数据并提出一个 3D 人脸识别网络 FR3DNet,最终在现有公开数据集上进行测试,效果很好(数据驱动的方式,基本为刷满的状态)。该论文创造新 ID 的方式是在作者的私有数据集中找到两个弯曲能量差异最大的 3D 人脸,通过加和得到一个新的 3D 人脸(详情请参考原文);同时提出了在人脸 3D 点云的识别网络中,采用大卷积核有利于更好地感受点云的形状信息。
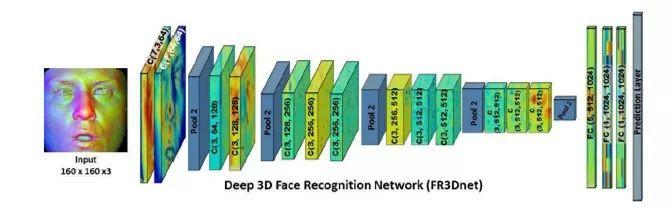
还有众多基于数据驱动的 3D 人脸识别如 3DMMCNN(链接:https://arxiv.org/abs/1612.04904),总结起来基于深度学习的 3D 人脸识别方法受限于数据不足,且现有数据精度不够,研究者的首要任务都是先做大量的数据增强或者生成大量的虚拟 3D 人脸,不过这些方法是否真的具有很强的泛化性能还值得商榷,也许属于 3D 人脸识别的时代还没到来。
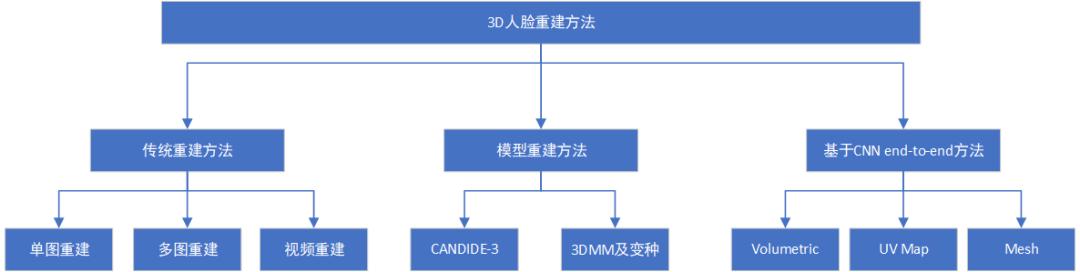
3D人脸重建
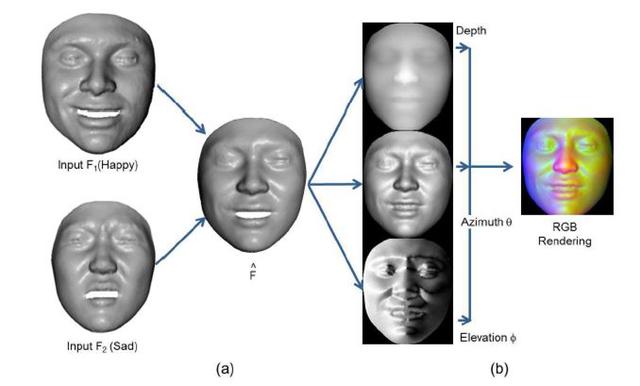
3D 人脸研究中另一个比较受关注的方向是 3D 人脸重建,即通过一张或多张 RGB 的人脸图像重建出人脸的 3D 模型,它的应用场景很多,比如 Face Animation,dense Face Alignment,Face Attribute Manipulation 等。其实 RGB 到 3D 的人脸重建是一个病态问题,因为 RGB 图像其实表征的是纹理特征而并没有空间信息,但考虑到实际的应用价值,这些年也陆续提出一些 3D 重建方法。
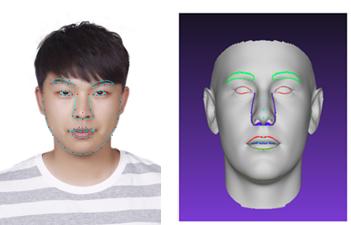
本文将介绍几种比较流行的人脸 3D 重建方法,供入门的小伙伴们参考,更多关于 3D 人脸重建总结推荐参考《3D人脸重建总结》(链接:https://blog.csdn.net/u011681952/article/details/82623328),这里先给出一个 3D 人脸重建的实例(取自PRNet)。

基于传统方法的人脸重建
传统 3D 人脸重建方法一般通过图像本身表达的信息完成 3D 人脸重建,如图像的视差、相对高度等,比较常见的如通过双目视觉实现 3D 重建,难点在于如何匹配不同视角下对应的特征点,关于这类文章大家可参考《A Survey of Different 3D Face Reconstruction Methods》(链接:https://pdfs.semanticscholar.org/d4b8/8be6ce77164f5eea1ed2b16b985c0670463a.pdf)。
基于模型的人脸重建
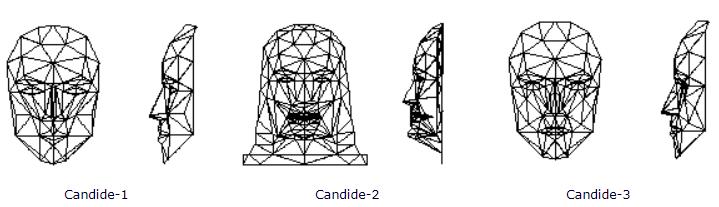
3D 人脸重建中有两个比较常用的模型,其中一个为通用模型 CANDIDE,另一个为 3DMM。
众多通用模型中,CANDIDE-3 可谓名气最大,由 113 个顶点和 168 个面组成。简单来讲,通过修改这些顶点和面,使得其特征与待重建的图像相匹配。通过整体调整,使五官等面部关键点尽量对齐;通过局部性调整,使人脸的局部细节更加精细,在这之后进行顶点插值,即可以获得重建后的人脸。
该模型的优缺点显而易见,模板的顶点数量过少,重建速度快,但重建的精度严重不足,面部细节特征重建欠佳。
入门 3D 人脸一定会接触的算法是 3D Morphable Model (3DMM),这是 1999 年由 Volker Blanz 在《A Morphable Model For The Synthesis Of 3D Faces》一文中提出的一种人脸模型的线性表示,可以将一张 2D 的人脸图片生成其对应的 3D 人脸模型,表示方法为:
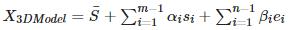
其中
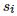
和
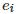
那么如何从二维重建三维呢?首先要了解三维模型是如何投影到二维平面的,上文最开始讲的相机模型,把三维模型投影到二维平面可以表示为:
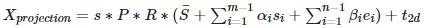
利用一个人脸数据库构造一个平均人脸形变模型,在给出新的人脸图像后,将人脸图像与模型进行匹配结合,修改模型相应的参数,将模型进行形变,直到模型与人脸图像的差异减到最小,这时对纹理进行优化调整,即可完成人脸建模。
一般 2D 到 3D 重建过程所采用的监督方式为 2D 人脸关键点与 3D 顶点对应的正交投影上的关键点。
基于 CNN 端到端的人脸重建
有了 3DMM 模型,即可进行单张 2D 人脸的 3D 重构,但一个现实问题是,传统 3DMM 重建是迭代拟合的过程,该过程效率比较低,因此并不适用于实时的三维人脸重建。分析 3DMM 原理可知,需要调整的就是 3DMM 的 199 维参数(这个不同的基不一样哦),为什么不用CNN 回归基的参数呢?这样我们可以通过网络去预测参数,实现 3DMM 的快速重建。
但是有一个问题,我们如何获得训练数据?为此,大多数论文选择利用 3DMM 线下拟合大量人脸图片作为 ground-truth,然后送入神经网络去训练。虽然是个病态问题,但效果还不错。本文将介绍几篇通俗易懂的基于 CNN 端到端的 3D 人脸重建方法。
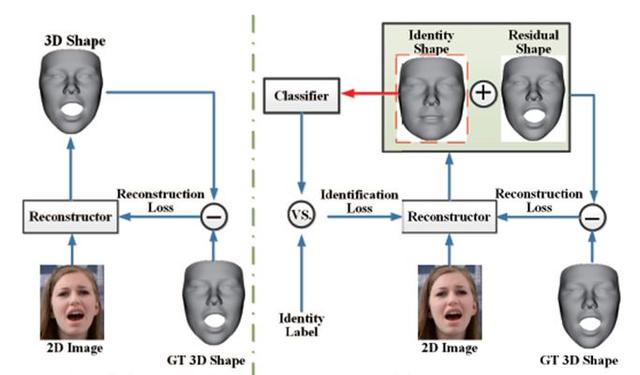
《Disentangling Features in 3D Face Shapes for Joint Face Reconstruction and Recognition 》
该论文通过 CNN 回归 Identity Shape 和 Residual Shape 参数,表达式和 3DMM 类似,不同之处在于除了普通的 reconstruction loss(一般为 element-wise L2 loss),还增加了一个 Identification loss,以保证重建的人脸 ID 特征不变。
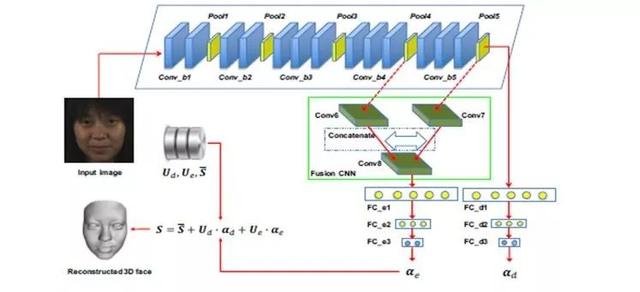
《End-to-end 3D face reconstruction with deep neural networks》
该论文的思想也是回归 3DMM 参数,作者认为高层的语义特征可以表示 ID 信息,而中间层的特征可以表示表情特征,因此可从不同的层级回归相应的参数,从而实现 3D 人脸重建任务。
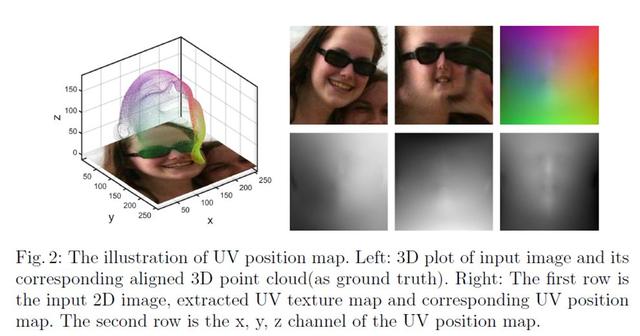
《Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network 》
另一种比较常见的端到端 3D 人脸重建方法为 Position Regression Network(PRN),强推!(附开源代码 PRN:https://github.com/YadiraF/PRNet)。
该论文提出一种端到端 Position Regression Network,以完成 3D 人脸重建和稠密人脸对齐。
作者引入 UV Position Map,可以实现通过 2D 图像来存储人脸 3D 点云坐标,假设一个包含 65536 个点的 3D 点云,通过 UV Position Map 可以表示成一个 256*2563 的 2D 图像,每一个像素点存储的是点云的空间坐标,因此可以通过一个 encoder-decoder 网络回归原始图像的 UV Position Map,实现 3D 人脸重建。
作者通过设计一个不同区域不同权重的 Loss Function,最终实现了较高精度的人脸重建和稠密关键点对齐。


《3D Dense Face Alignment via Graph Convolution Networks》
通过上述回归 UV Position Map 的方式有一个问题,最终 UV 图像映射到 3D 人脸 mesh 的图像时,会出现一些条纹。在最近的一些 3D 人脸重建工作中,还有一种通过多级回归 3D 人脸 mesh 的方法取得了不错的重建效果。
该论文作者通过逐级增加回归的 mesh 顶点,从而在多个监督的任务下完成最终 mesh 的回归,同时采用图卷积的形式可以更加本质地进行点与点之间的构图关系,最终取得了不错的重建效果。

3D 人脸重建是近年的一个热门话题,每年各种会议也有许许多多的文章提出各种各样的 3D 人脸重建方案,但从入门角度考虑,掌握上述几种常见方法会对之后的研究会打下不错的基础。
总结
本文介绍了 3D 人脸技术的入门知识,包括 3D 基础知识如相机模型、3D 相机工作原理、3D 人脸数据处理等,同时也总结了 3D 人脸识别/重建的相关方法,希望抛砖引玉,并对入门 3D 人脸起到帮助。由于时间原因,有些总结可能并不完善,恳请大家及时斧正。
最后推荐一个适合入门 3D 人脸技术的开源项目:face3d (链接:https://github.com/YadiraF/face3d),项目作者即前文提及的 PRNet 作者。
传送门
欢迎各位同学关注旷视研究院人脸识别组(及知乎专栏:https://zhuanlan.zhihu.com/r-facerec),简历可以投递给 FaceRecognition 组(fr-wants-you@megvii.com)。

最后
以上就是斯文跳跳糖最近收集整理的关于双目相机定位3d python_3D人脸技术漫游指南3D人脸相关任务总结的全部内容,更多相关双目相机定位3d内容请搜索靠谱客的其他文章。








发表评论 取消回复